 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime series Forecasting to detect anomalous behaviours in Multiphase Flow Meters
Dec 30, 2022An Anomaly Detection (AD) System for Self-diagnosis has been developed for Multiphase Flow Meter (MPFM). The system relies on machine learning algorithms for time series forecasting, historical data have been used to train a model and to predict the behavior of a sensor and, thus, to detect anomalies.
Active Learning-based Isolation Forest (ALIF): Enhancing Anomaly Detection in Decision Support Systems
Jul 08, 2022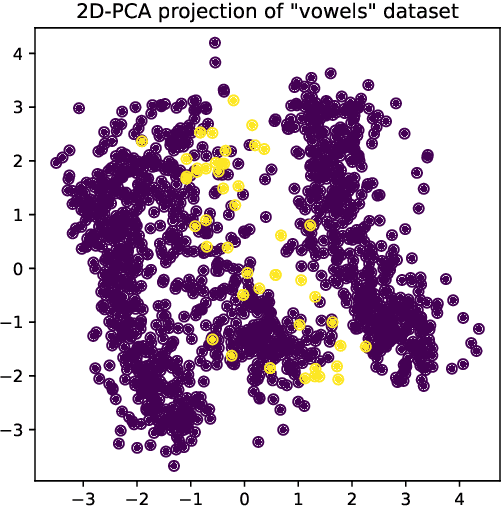

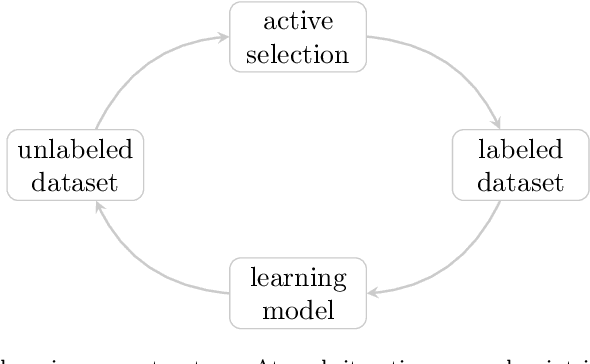
The detection of anomalous behaviours is an emerging need in many applications, particularly in contexts where security and reliability are critical aspects. While the definition of anomaly strictly depends on the domain framework, it is often impractical or too time consuming to obtain a fully labelled dataset. The use of unsupervised models to overcome the lack of labels often fails to catch domain specific anomalies as they rely on general definitions of outlier. This paper suggests a new active learning based approach, ALIF, to solve this problem by reducing the number of required labels and tuning the detector towards the definition of anomaly provided by the user. The proposed approach is particularly appealing in the presence of a Decision Support System (DSS), a case that is increasingly popular in real-world scenarios. While it is common that DSS embedded with anomaly detection capabilities rely on unsupervised models, they don't have a way to improve their performance: ALIF is able to enhance the capabilities of DSS by exploiting the user feedback during common operations. ALIF is a lightweight modification of the popular Isolation Forest that proved superior performances with respect to other state-of-art algorithms in a multitude of real anomaly detection datasets.
TiWS-iForest: Isolation Forest in Weakly Supervised and Tiny ML scenarios
Nov 30, 2021
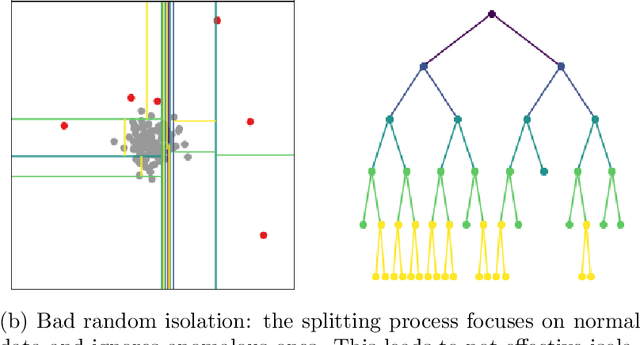
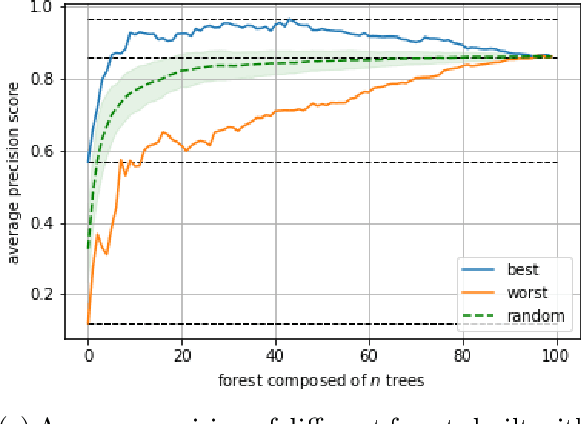
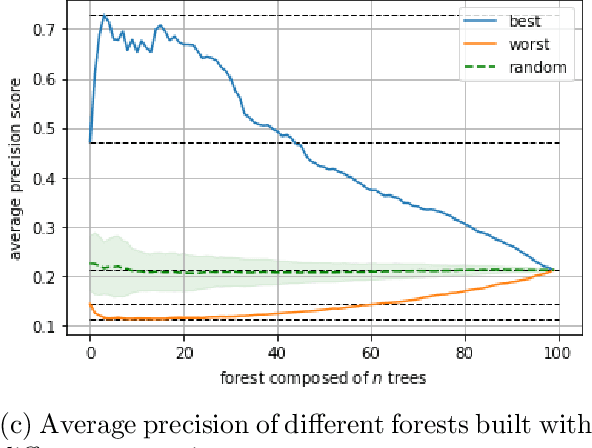
Unsupervised anomaly detection tackles the problem of finding anomalies inside datasets without the labels availability; since data tagging is typically hard or expensive to obtain, such approaches have seen huge applicability in recent years. In this context, Isolation Forest is a popular algorithm able to define an anomaly score by means of an ensemble of peculiar trees called isolation trees. These are built using a random partitioning procedure that is extremely fast and cheap to train. However, we find that the standard algorithm might be improved in terms of memory requirements, latency and performances; this is of particular importance in low resources scenarios and in TinyML implementations on ultra-constrained microprocessors. Moreover, Anomaly Detection approaches currently do not take advantage of weak supervisions: being typically consumed in Decision Support Systems, feedback from the users, even if rare, can be a valuable source of information that is currently unexplored. Beside showing iForest training limitations, we propose here TiWS-iForest, an approach that, by leveraging weak supervision is able to reduce Isolation Forest complexity and to enhance detection performances. We showed the effectiveness of TiWS-iForest on real word datasets and we share the code in a public repository to enhance reproducibility.