 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Near-Optimal Best-of-Both-Worlds Algorithm for Online Learning with Feedback Graphs
Jun 01, 2022
We consider online learning with feedback graphs, a sequential decision-making framework where the learner's feedback is determined by a directed graph over the action set. We present a computationally efficient algorithm for learning in this framework that simultaneously achieves near-optimal regret bounds in both stochastic and adversarial environments. The bound against oblivious adversaries is $\tilde{O} (\sqrt{\alpha T})$, where $T$ is the time horizon and $\alpha$ is the independence number of the feedback graph. The bound against stochastic environments is $O\big( (\ln T)^2 \max_{S\in \mathcal I(G)} \sum_{i \in S} \Delta_i^{-1}\big)$ where $\mathcal I(G)$ is the family of all independent sets in a suitably defined undirected version of the graph and $\Delta_i$ are the suboptimality gaps. The algorithm combines ideas from the EXP3++ algorithm for stochastic and adversarial bandits and the EXP3.G algorithm for feedback graphs with a novel exploration scheme. The scheme, which exploits the structure of the graph to reduce exploration, is key to obtain best-of-both-worlds guarantees with feedback graphs. We also extend our algorithm and results to a setting where the feedback graphs are allowed to change over time.
FETA: Fairness Enforced Verifying, Training, and Predicting Algorithms for Neural Networks
Jun 01, 2022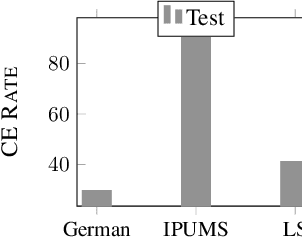
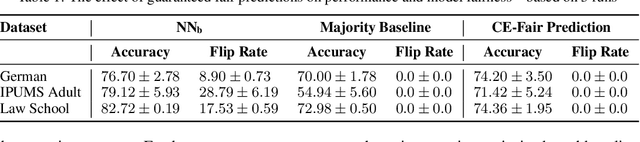
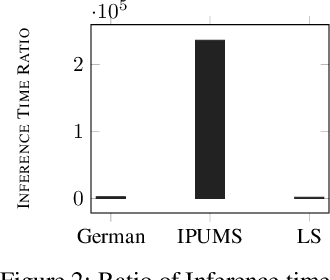

Algorithmic decision making driven by neural networks has become very prominent in applications that directly affect people's quality of life. In this paper, we study the problem of verifying, training, and guaranteeing individual fairness of neural network models. A popular approach for enforcing fairness is to translate a fairness notion into constraints over the parameters of the model. However, such a translation does not always guarantee fair predictions of the trained neural network model. To address this challenge, we develop a counterexample-guided post-processing technique to provably enforce fairness constraints at prediction time. Contrary to prior work that enforces fairness only on points around test or train data, we are able to enforce and guarantee fairness on all points in the input domain. Additionally, we propose an in-processing technique to use fairness as an inductive bias by iteratively incorporating fairness counterexamples in the learning process. We have implemented these techniques in a tool called FETA. Empirical evaluation on real-world datasets indicates that FETA is not only able to guarantee fairness on-the-fly at prediction time but also is able to train accurate models exhibiting a much higher degree of individual fairness.
Quantile-based fuzzy clustering of multivariate time series in the frequency domain
Sep 08, 2021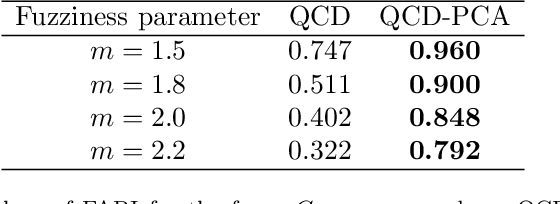
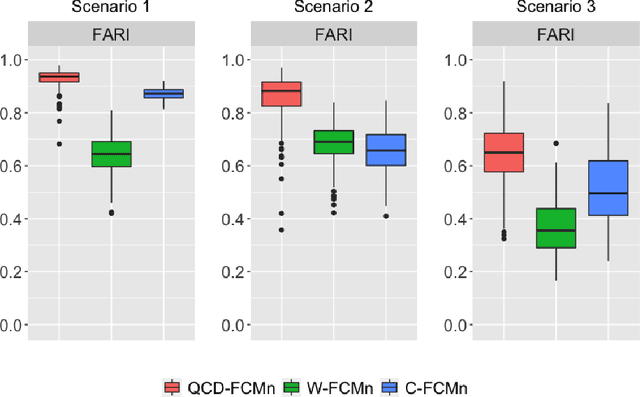
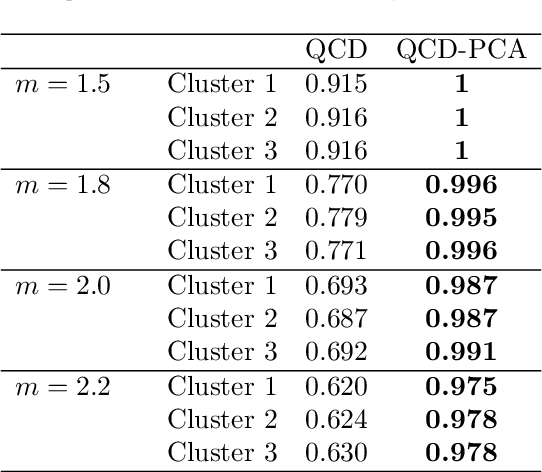
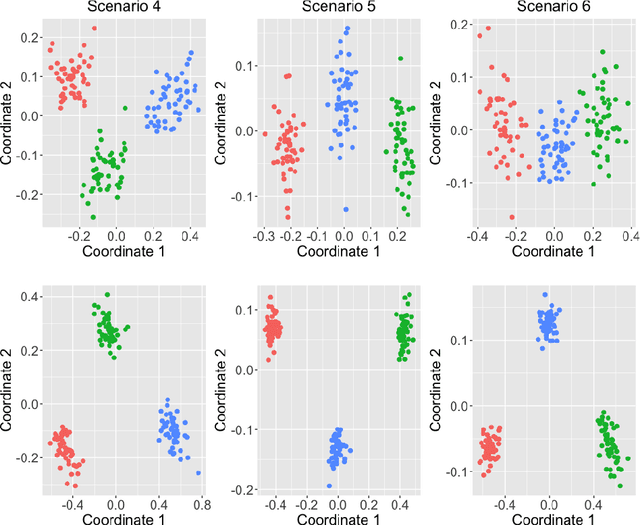
A novel procedure to perform fuzzy clustering of multivariate time series generated from different dependence models is proposed. Different amounts of dissimilarity between the generating models or changes on the dynamic behaviours over time are some arguments justifying a fuzzy approach, where each series is associated to all the clusters with specific membership levels. Our procedure considers quantile-based cross-spectral features and consists of three stages: (i) each element is characterized by a vector of proper estimates of the quantile cross-spectral densities, (ii) principal component analysis is carried out to capture the main differences reducing the effects of the noise, and (iii) the squared Euclidean distance between the first retained principal components is used to perform clustering through the standard fuzzy C-means and fuzzy C-medoids algorithms. The performance of the proposed approach is evaluated in a broad simulation study where several types of generating processes are considered, including linear, nonlinear and dynamic conditional correlation models. Assessment is done in two different ways: by directly measuring the quality of the resulting fuzzy partition and by taking into account the ability of the technique to determine the overlapping nature of series located equidistant from well-defined clusters. The procedure is compared with the few alternatives suggested in the literature, substantially outperforming all of them whatever the underlying process and the evaluation scheme. Two specific applications involving air quality and financial databases illustrate the usefulness of our approach.
Asynchronous Distributed Bayesian Optimization at HPC Scale
Jul 04, 2022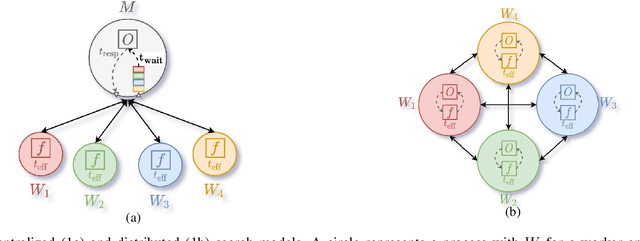
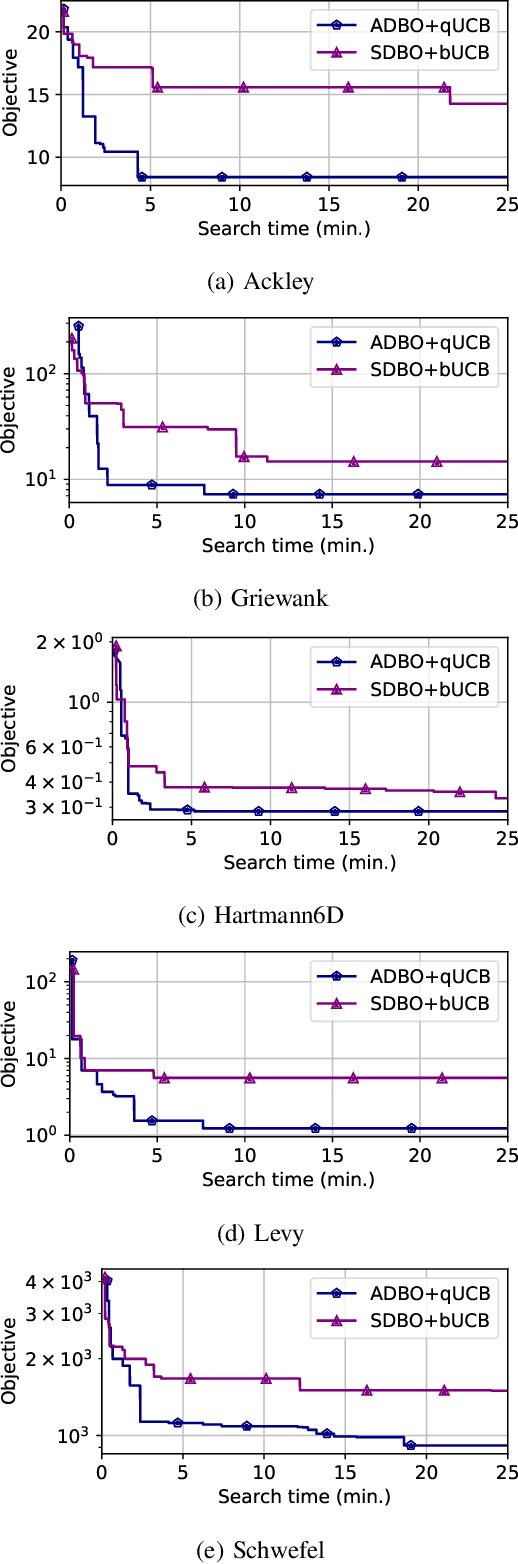
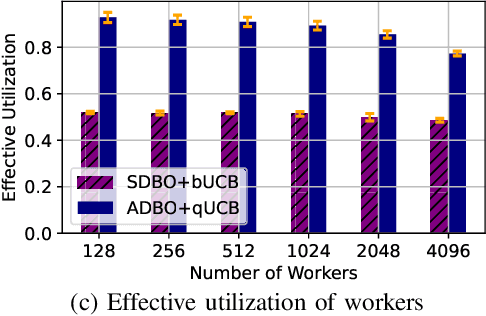

Bayesian optimization (BO) is a widely used approach for computationally expensive black-box optimization such as simulator calibration and hyperparameter optimization of deep learning methods. In BO, a dynamically updated computationally cheap surrogate model is employed to learn the input-output relationship of the black-box function; this surrogate model is used to explore and exploit the promising regions of the input space. Multipoint BO methods adopt a single manager/multiple workers strategy to achieve high-quality solutions in shorter time. However, the computational overhead in multipoint generation schemes is a major bottleneck in designing BO methods that can scale to thousands of workers. We present an asynchronous-distributed BO (ADBO) method wherein each worker runs a search and asynchronously communicates the input-output values of black-box evaluations from all other workers without the manager. We scale our method up to 4,096 workers and demonstrate improvement in the quality of the solution and faster convergence. We demonstrate the effectiveness of our approach for tuning the hyperparameters of neural networks from the Exascale computing project CANDLE benchmarks.
Attention mechanisms for physiological signal deep learning: which attention should we take?
Jul 04, 2022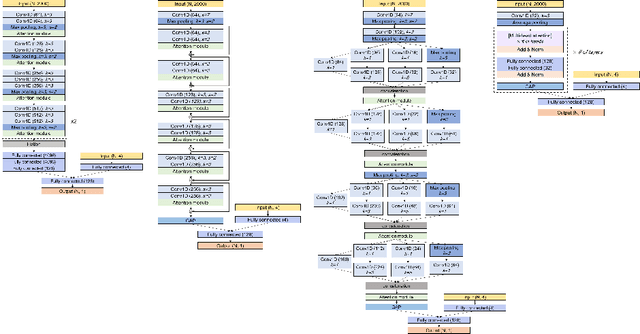
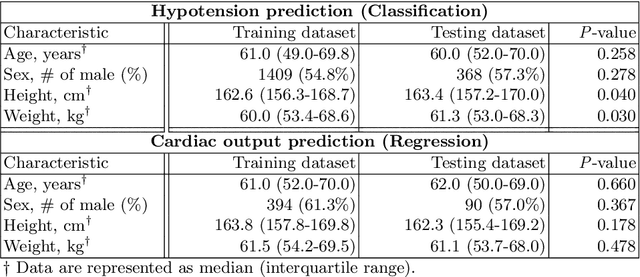
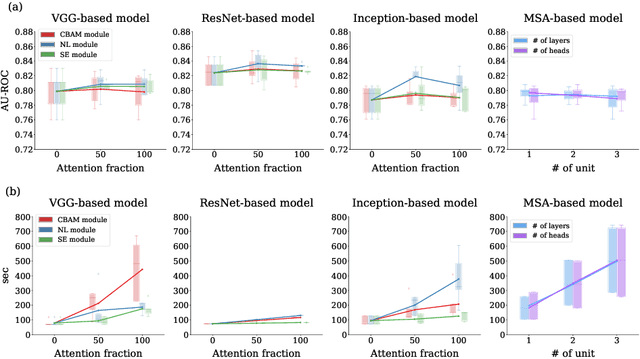
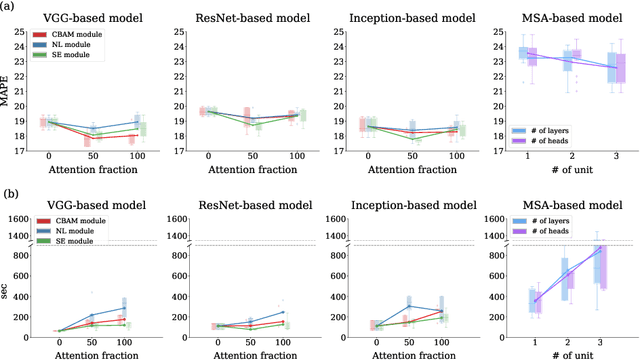
Attention mechanisms are widely used to dramatically improve deep learning model performance in various fields. However, their general ability to improve the performance of physiological signal deep learning model is immature. In this study, we experimentally analyze four attention mechanisms (e.g., squeeze-and-excitation, non-local, convolutional block attention module, and multi-head self-attention) and three convolutional neural network (CNN) architectures (e.g., VGG, ResNet, and Inception) for two representative physiological signal prediction tasks: the classification for predicting hypotension and the regression for predicting cardiac output (CO). We evaluated multiple combinations for performance and convergence of physiological signal deep learning model. Accordingly, the CNN models with the spatial attention mechanism showed the best performance in the classification problem, whereas the channel attention mechanism achieved the lowest error in the regression problem. Moreover, the performance and convergence of the CNN models with attention mechanisms were better than stand-alone self-attention models in both problems. Hence, we verified that convolutional operation and attention mechanisms are complementary and provide faster convergence time, despite the stand-alone self-attention models requiring fewer parameters.
Low Power Neuromorphic EMG Gesture Classification
Jun 04, 2022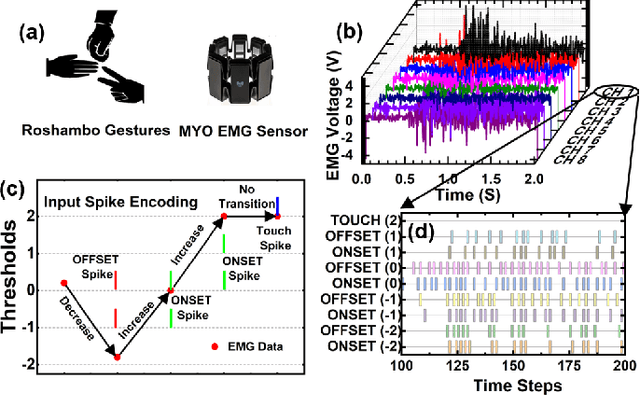
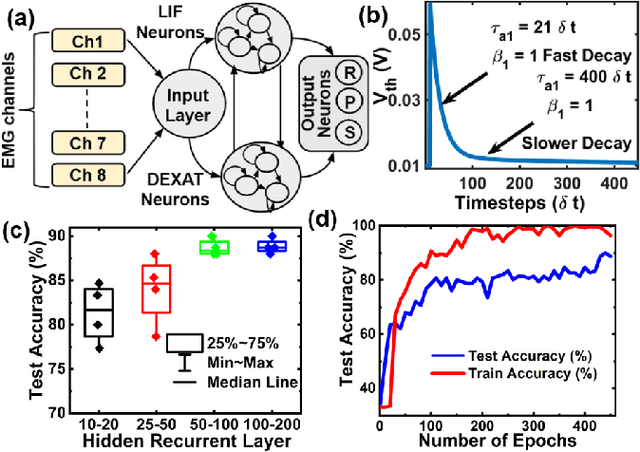
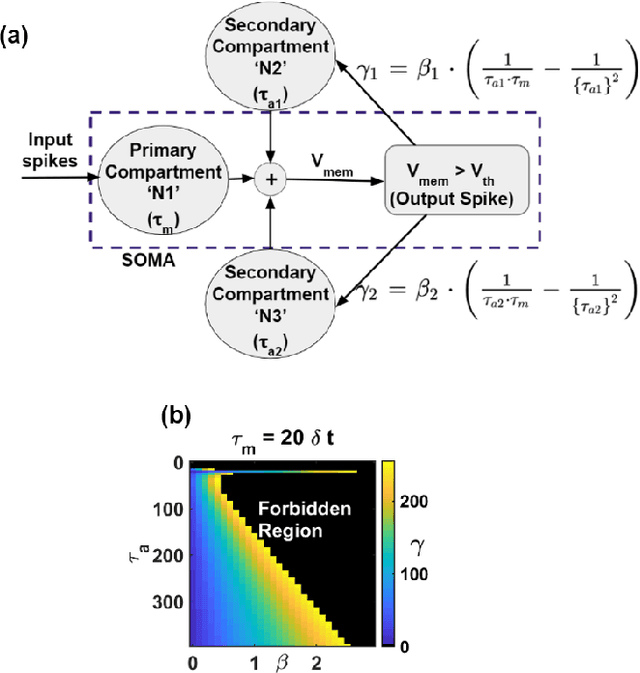
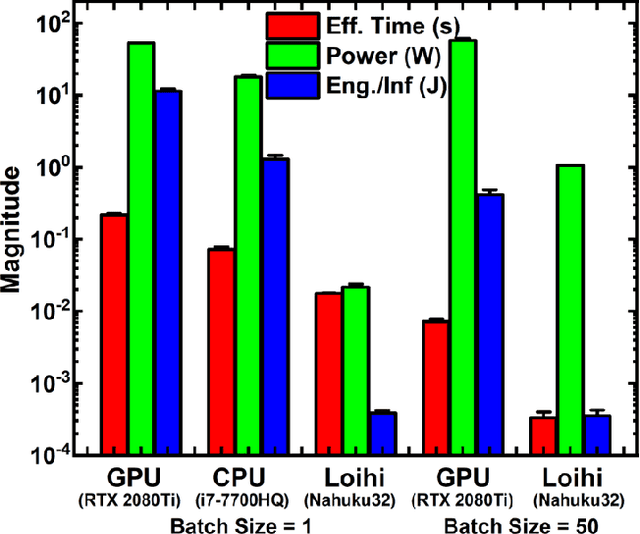
EMG (Electromyograph) signal based gesture recognition can prove vital for applications such as smart wearables and bio-medical neuro-prosthetic control. Spiking Neural Networks (SNNs) are promising for low-power, real-time EMG gesture recognition, owing to their inherent spike/event driven spatio-temporal dynamics. In literature, there are limited demonstrations of neuromorphic hardware implementation (at full chip/board/system scale) for EMG gesture classification. Moreover, most literature attempts exploit primitive SNNs based on LIF (Leaky Integrate and Fire) neurons. In this work, we address the aforementioned gaps with following key contributions: (1) Low-power, high accuracy demonstration of EMG-signal based gesture recognition using neuromorphic Recurrent Spiking Neural Networks (RSNN). In particular, we propose a multi-time scale recurrent neuromorphic system based on special double-exponential adaptive threshold (DEXAT) neurons. Our network achieves state-of-the-art classification accuracy (90%) while using ~53% lesser neurons than best reported prior art on Roshambo EMG dataset. (2) A new multi-channel spike encoder scheme for efficient processing of real-valued EMG data on neuromorphic systems. (3) Unique multi-compartment methodology to implement complex adaptive neurons on Intel's dedicated neuromorphic Loihi chip is shown. (4) RSNN implementation on Loihi (Nahuku 32) achieves significant energy/latency benefits of ~983X/19X compared to GPU for batch size as 50.
Proactive Distributed Constraint Optimization of Heterogeneous Incident Vehicle Teams
Jul 16, 2022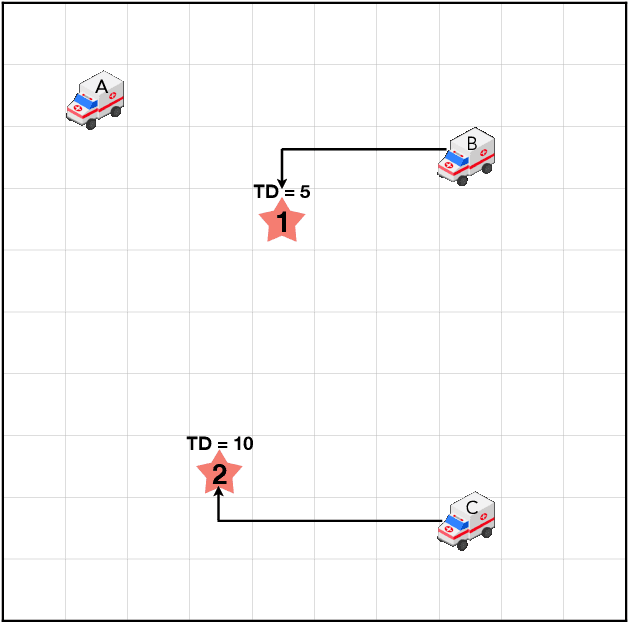

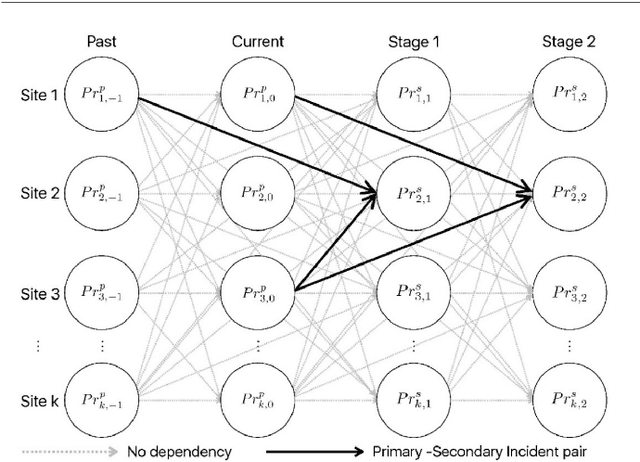
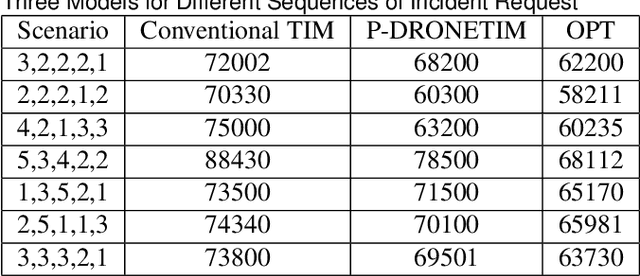
Traditionally, traffic incident management (TIM) programs coordinate the deployment of emergency resources to immediate incident requests without accommodating the interdependencies on incident evolutions in the environment. However, ignoring inherent interdependencies on the evolution of incidents in the environment while making current deployment decisions is shortsighted, and the resulting naive deployment strategy can significantly worsen the overall incident delay impact on the network. The interdependencies on incident evolution in the environment, including those between incident occurrences, and those between resource availability in near-future requests and the anticipated duration of the immediate incident request, should be considered through a look-ahead model when making current-stage deployment decisions. This study develops a new proactive framework based on the distributed constraint optimization problem (DCOP) to address the above limitations, overcoming conventional TIM models that cannot accommodate the dependencies in the TIM problem. Furthermore, the optimization objective is formulated to incorporate Unmanned Aerial Vehicles (UAVs). The UAVs' role in TIM includes exploring uncertain traffic conditions, detecting unexpected events, and augmenting information from roadway traffic sensors. Robustness analysis of our model for multiple TIM scenarios shows satisfactory performance using local search exploration heuristics. Overall, our model reports a significant reduction in total incident delay compared to conventional TIM models. With UAV support, we demonstrate a further decrease in the overall incident delay through the shorter response time of emergency vehicles, and a reduction in uncertainties associated with the estimated incident delay impact.
GAAMA 2.0: An Integrated System that Answers Boolean and Extractive Questions
Jun 21, 2022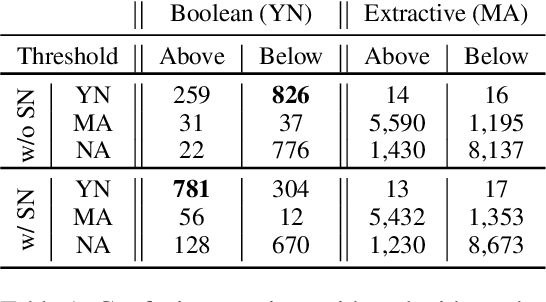
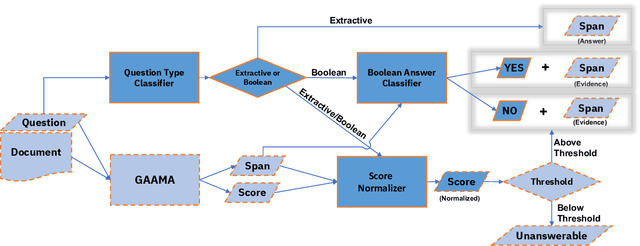


Recent machine reading comprehension datasets include extractive and boolean questions but current approaches do not offer integrated support for answering both question types. We present a multilingual machine reading comprehension system and front-end demo that handles boolean questions by providing both a YES/NO answer and highlighting supporting evidence, and handles extractive questions by highlighting the answer in the passage. Our system, GAAMA 2.0, is ranked first on the Tydi QA leaderboard at the time of this writing. We contrast two different implementations of our approach. The first includes several independent stacks of transformers allowing easy deployment of each component. The second is a single stack of transformers utilizing adapters to reduce GPU memory footprint in a resource-constrained environment.
Multi-task Envisioning Transformer-based Autoencoder for Corporate Credit Rating Migration Early Prediction
Jul 10, 2022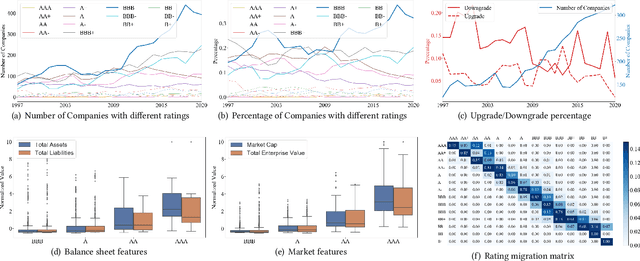

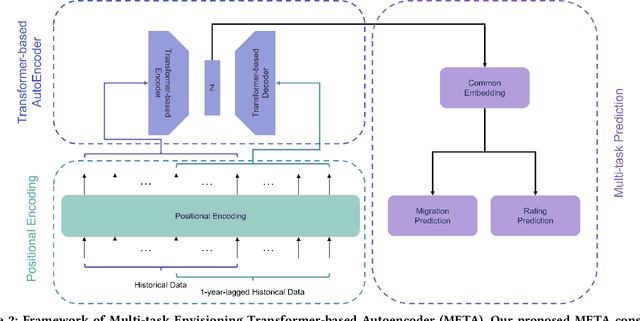
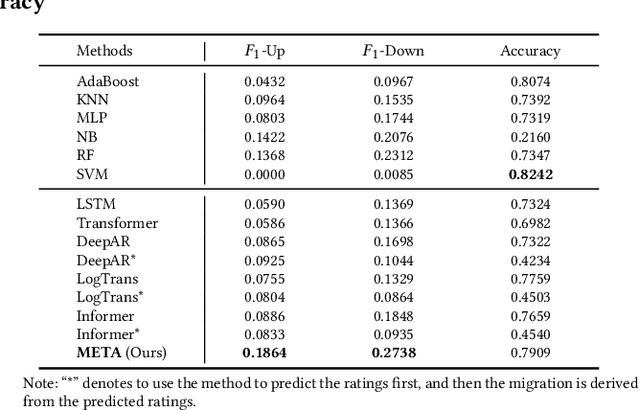
Corporate credit ratings issued by third-party rating agencies are quantified assessments of a company's creditworthiness. Credit Ratings highly correlate to the likelihood of a company defaulting on its debt obligations. These ratings play critical roles in investment decision-making as one of the key risk factors. They are also central to the regulatory framework such as BASEL II in calculating necessary capital for financial institutions. Being able to predict rating changes will greatly benefit both investors and regulators alike. In this paper, we consider the corporate credit rating migration early prediction problem, which predicts the credit rating of an issuer will be upgraded, unchanged, or downgraded after 12 months based on its latest financial reporting information at the time. We investigate the effectiveness of different standard machine learning algorithms and conclude these models deliver inferior performance. As part of our contribution, we propose a new Multi-task Envisioning Transformer-based Autoencoder (META) model to tackle this challenging problem. META consists of Positional Encoding, Transformer-based Autoencoder, and Multi-task Prediction to learn effective representations for both migration prediction and rating prediction. This enables META to better explore the historical data in the training stage for one-year later prediction. Experimental results show that META outperforms all baseline models.
Hyperparameter Optimization with Neural Network Pruning
May 18, 2022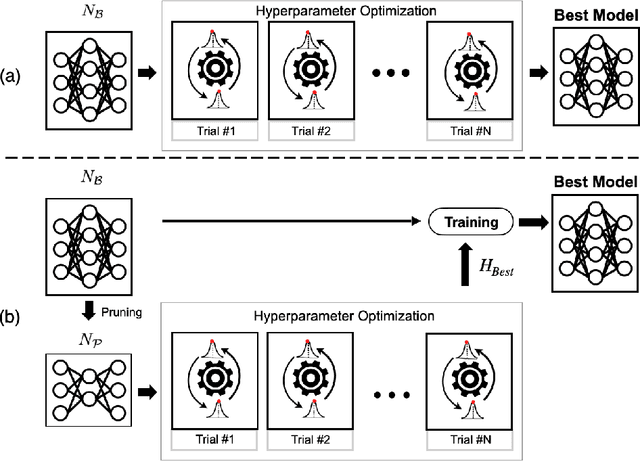
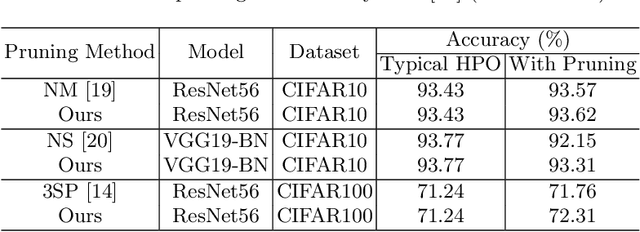

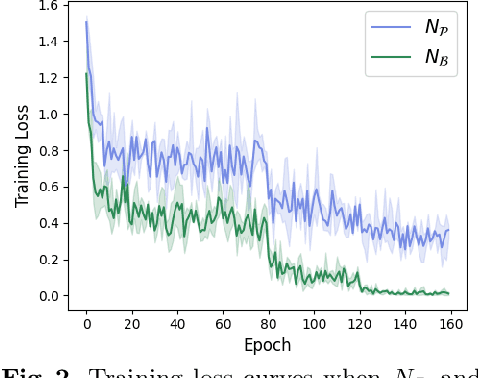
Since the deep learning model is highly dependent on hyperparameters, hyperparameter optimization is essential in developing deep learning model-based applications, even if it takes a long time. As service development using deep learning models has gradually become competitive, many developers highly demand rapid hyperparameter optimization algorithms. In order to keep pace with the needs of faster hyperparameter optimization algorithms, researchers are focusing on improving the speed of hyperparameter optimization algorithm. However, the huge time consumption of hyperparameter optimization due to the high computational cost of the deep learning model itself has not been dealt with in-depth. Like using surrogate model in Bayesian optimization, to solve this problem, it is necessary to consider proxy model for a neural network (N_B) to be used for hyperparameter optimization. Inspired by the main goal of neural network pruning, i.e., high computational cost reduction and performance preservation, we presumed that the neural network (N_P) obtained through neural network pruning would be a good proxy model of N_B. In order to verify our idea, we performed extensive experiments by using CIFAR10, CFIAR100, and TinyImageNet datasets and three generally-used neural networks and three representative hyperparameter optmization methods. Through these experiments, we verified that N_P can be a good proxy model of N_B for rapid hyperparameter optimization. The proposed hyperparameter optimization framework can reduce the amount of time up to 37%.