 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAAMA 2.0: An Integrated System that Answers Boolean and Extractive Questions
Paper and Code
Jun 21, 2022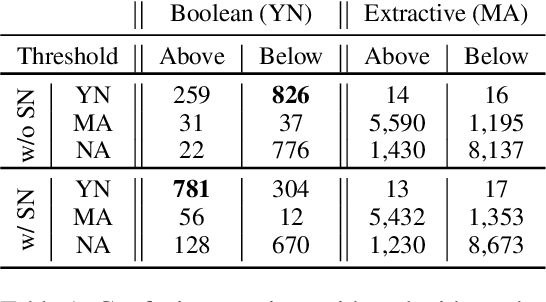
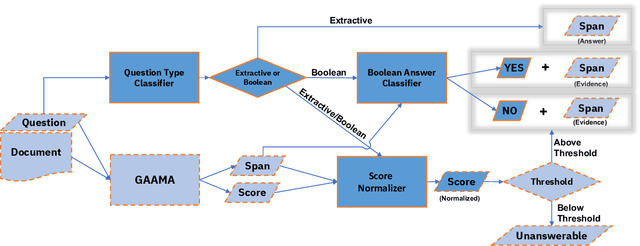


Recent machine reading comprehension datasets include extractive and boolean questions but current approaches do not offer integrated support for answering both question types. We present a multilingual machine reading comprehension system and front-end demo that handles boolean questions by providing both a YES/NO answer and highlighting supporting evidence, and handles extractive questions by highlighting the answer in the passage. Our system, GAAMA 2.0, is ranked first on the Tydi QA leaderboard at the time of this writing. We contrast two different implementations of our approach. The first includes several independent stacks of transformers allowing easy deployment of each component. The second is a single stack of transformers utilizing adapters to reduce GPU memory footprint in a resource-constrained environment.