 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
High-quality Task Division for Large-scale Entity Alignment
Aug 22, 2022
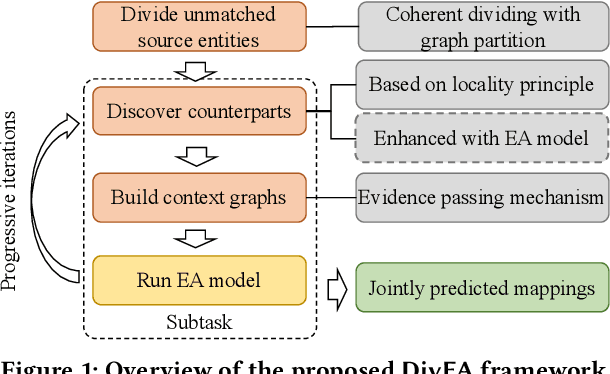

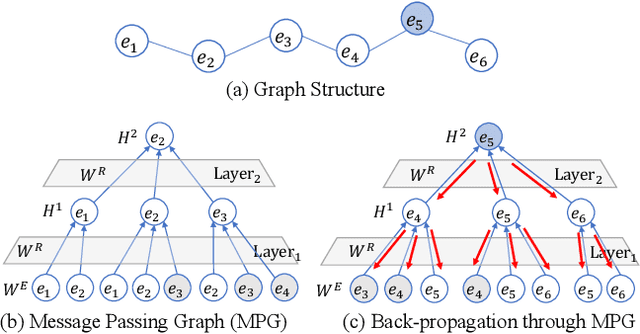

Entity Alignment (EA) aims to match equivalent entities that refer to the same real-world objects and is a key step for Knowledge Graph (KG) fusion. Most neural EA models cannot be applied to large-scale real-life KGs due to their excessive consumption of GPU memory and time. One promising solution is to divide a large EA task into several subtasks such that each subtask only needs to match two small subgraphs of the original KGs. However, it is challenging to divide the EA task without losing effectiveness. Existing methods display low coverage of potential mappings, insufficient evidence in context graphs, and largely differing subtask sizes. In this work, we design the DivEA framework for large-scale EA with high-quality task division. To include in the EA subtasks a high proportion of the potential mappings originally present in the large EA task, we devise a counterpart discovery method that exploits the locality principle of the EA task and the power of trained EA models. Unique to our counterpart discovery method is the explicit modelling of the chance of a potential mapping. We also introduce an evidence passing mechanism to quantify the informativeness of context entities and find the most informative context graphs with flexible control of the subtask size. Extensive experiments show that DivEA achieves higher EA performance than alternative state-of-the-art solutions.
Self-Supervised Contrastive Representation Learning for 3D Mesh Segmentation
Aug 08, 2022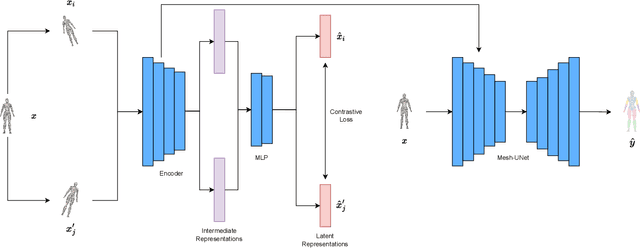
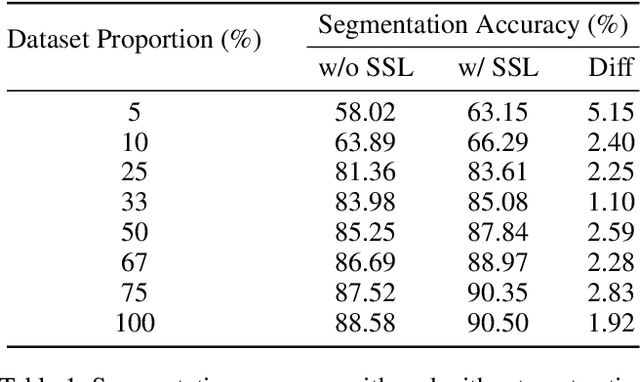
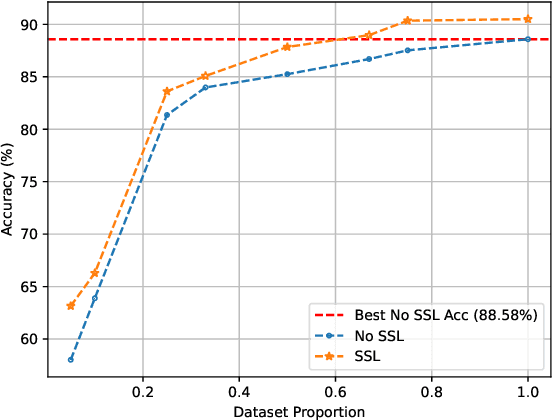
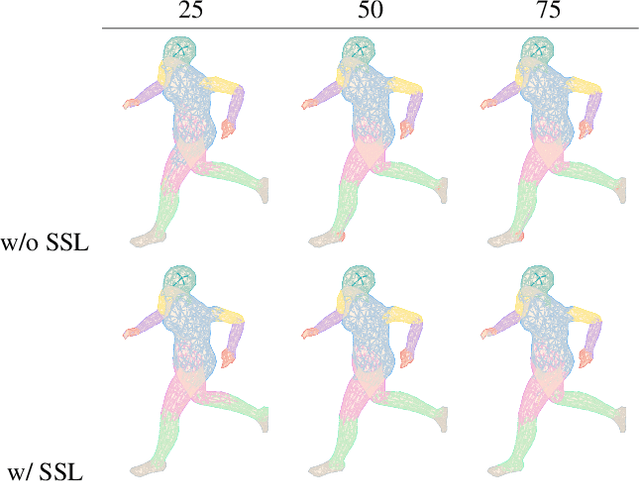
3D deep learning is a growing field of interest due to the vast amount of information stored in 3D formats. Triangular meshes are an efficient representation for irregular, non-uniform 3D objects. However, meshes are often challenging to annotate due to their high geometrical complexity. Specifically, creating segmentation masks for meshes is tedious and time-consuming. Therefore, it is desirable to train segmentation networks with limited-labeled data. Self-supervised learning (SSL), a form of unsupervised representation learning, is a growing alternative to fully-supervised learning which can decrease the burden of supervision for training. We propose SSL-MeshCNN, a self-supervised contrastive learning method for pre-training CNNs for mesh segmentation. We take inspiration from traditional contrastive learning frameworks to design a novel contrastive learning algorithm specifically for meshes. Our preliminary experiments show promising results in reducing the heavy labeled data requirement needed for mesh segmentation by at least 33%.
ART-SLAM: Accurate Real-Time 6DoF LiDAR SLAM
Sep 12, 2021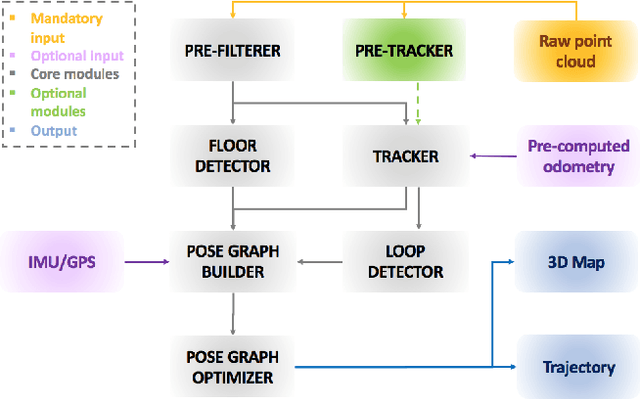
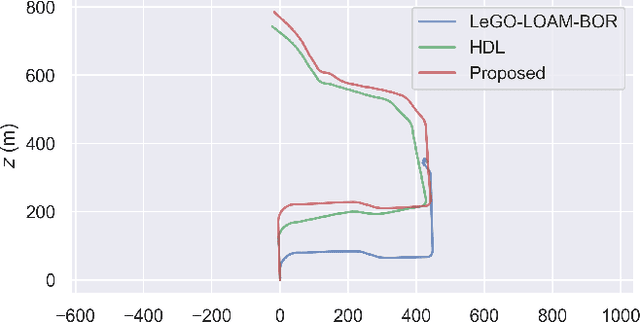
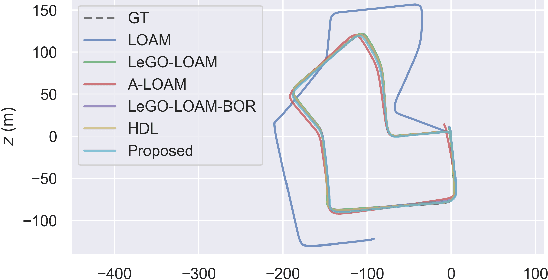
Real-time six degree-of-freedom pose estimation with ground vehicles represents a relevant and well studied topic in robotics, due to its many applications, such as autonomous driving and 3D mapping. Although some systems exist already, they are either not accurate or they struggle in real-time setting. In this paper, we propose a fast, accurate and modular LiDAR SLAM system for both batch and online estimation. We first apply downsampling and outlier removal, to filter out noise and reduce the size of the input point clouds. Filtered clouds are then used for pose tracking and floor detection, to ground-optimize the estimated trajectory. The availability of a pre-tracker, working in parallel with the filtering process, allows to obtain pre-computed odometries, to be used as aids when performing tracking. Efficient loop closure and pose optimization, achieved through a g2o pose graph, are the last steps of the proposed SLAM pipeline. We compare the performance of our system with state-of-the-art point cloud based methods, LOAM, LeGO-LOAM, A-LOAM, LeGO-LOAM-BOR and HDL, and show that the proposed system achieves equal or better accuracy and can easily handle even cases without loops. The comparison is done evaluating the estimated trajectory displacement using the KITTI and RADIATE datasets.
Online Game Level Generation from Music
Jul 12, 2022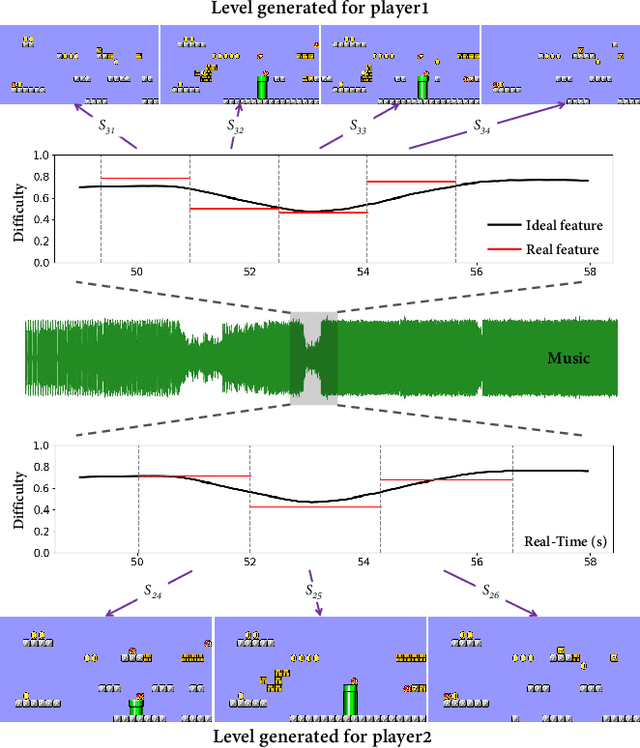
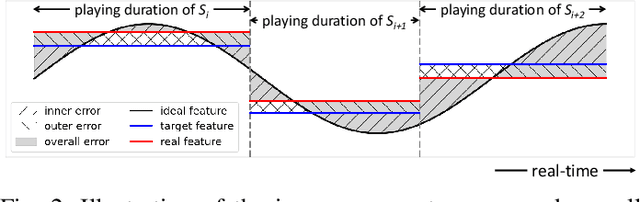
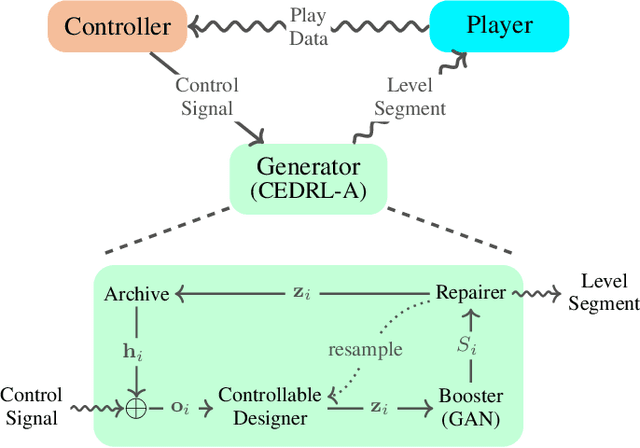
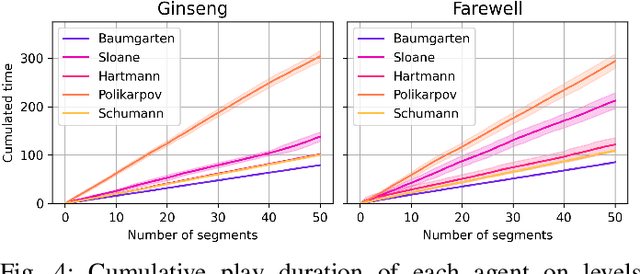
Game consists of multiple types of content, while the harmony of different content types play an essential role in game design. However, most works on procedural content generation consider only one type of content at a time. In this paper, we propose and formulate online level generation from music, in a way of matching a level feature to a music feature in real-time, while adapting to players' play speed. A generic framework named online player-adaptive procedural content generation via reinforcement learning, OPARL for short, is built upon the experience-driven reinforcement learning and controllable reinforcement learning, to enable online level generation from music. Furthermore, a novel control policy based on local search and k-nearest neighbours is proposed and integrated into OPARL to control the level generator considering the play data collected online. Results of simulation-based experiments show that our implementation of OPARL is competent to generate playable levels with difficulty degree matched to the ``energy'' dynamic of music for different artificial players in an online fashion.
COPE: End-to-end trainable Constant Runtime Object Pose Estimation
Aug 22, 2022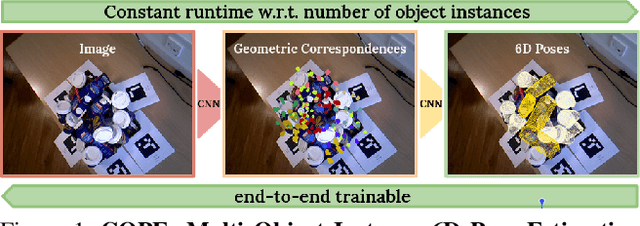
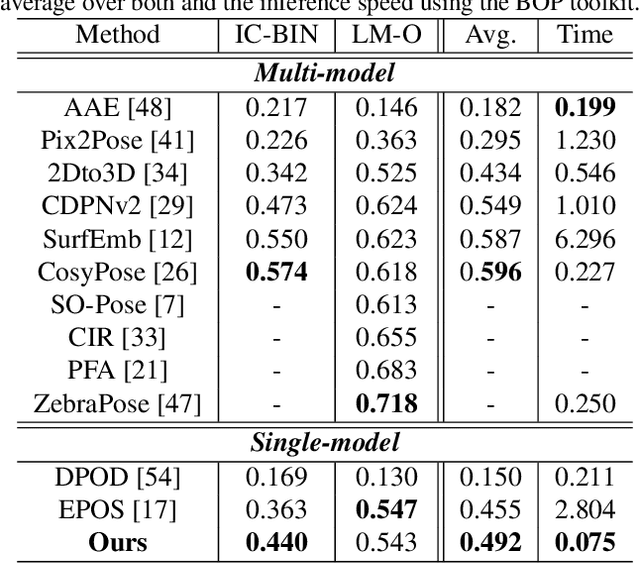
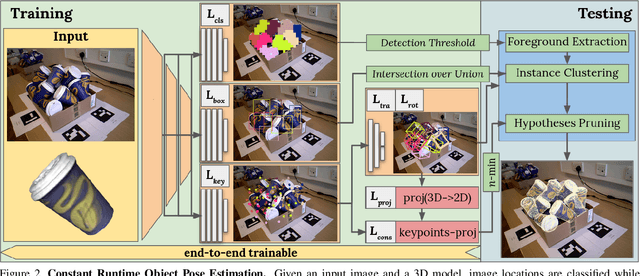
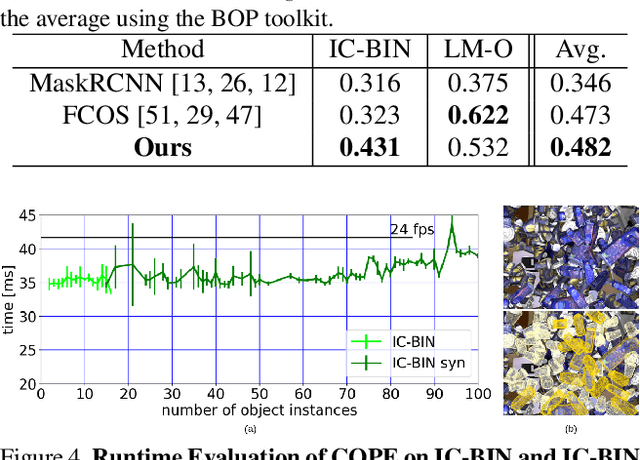
State-of-the-art object pose estimation handles multiple instances in a test image by using multi-model formulations: detection as a first stage and then separately trained networks per object for 2D-3D geometric correspondence prediction as a second stage. Poses are subsequently estimated using the Perspective-n-Points algorithm at runtime. Unfortunately, multi-model formulations are slow and do not scale well with the number of object instances involved. Recent approaches show that direct 6D object pose estimation is feasible when derived from the aforementioned geometric correspondences. We present an approach that learns an intermediate geometric representation of multiple objects to directly regress 6D poses of all instances in a test image. The inherent end-to-end trainability overcomes the requirement of separately processing individual object instances. By calculating the mutual Intersection-over-Unions, pose hypotheses are clustered into distinct instances, which achieves negligible runtime overhead with respect to the number of object instances. Results on multiple challenging standard datasets show that the pose estimation performance is superior to single-model state-of-the-art approaches despite being more than ~35 times faster. We additionally provide an analysis showing real-time applicability (>24 fps) for images where more than 90 object instances are present. Further results show the advantage of supervising geometric-correspondence-based object pose estimation with the 6D pose.
Tiny-HR: Towards an interpretable machine learning pipeline for heart rate estimation on edge devices
Aug 16, 2022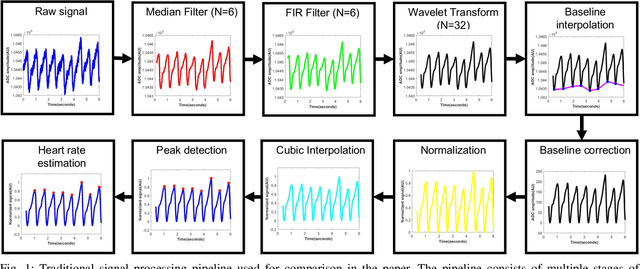

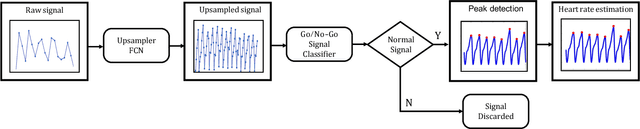
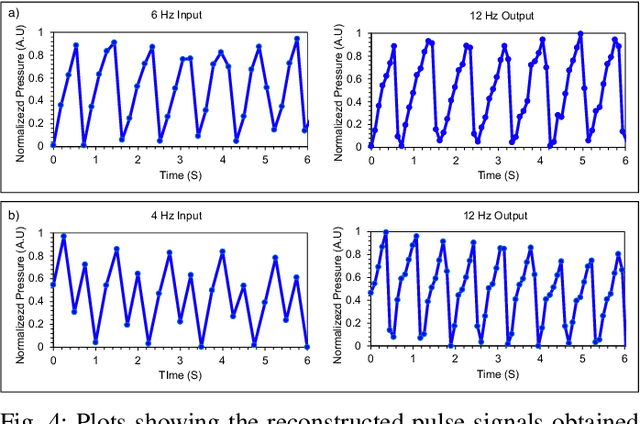
The focus of this paper is a proof of concept, machine learning (ML) pipeline that extracts heart rate from pressure sensor data acquired on low-power edge devices. The ML pipeline consists an upsampler neural network, a signal quality classifier, and a 1D-convolutional neural network optimized for efficient and accurate heart rate estimation. The models were designed so the pipeline was less than 40 kB. Further, a hybrid pipeline consisting of the upsampler and classifier, followed by a peak detection algorithm was developed. The pipelines were deployed on ESP32 edge device and benchmarked against signal processing to determine the energy usage, and inference times. The results indicate that the proposed ML and hybrid pipeline reduces energy and time per inference by 82% and 28% compared to traditional algorithms. The main trade-off for ML pipeline was accuracy, with a mean absolute error (MAE) of 3.28, compared to 2.39 and 1.17 for the hybrid and signal processing pipelines. The ML models thus show promise for deployment in energy and computationally constrained devices. Further, the lower sampling rate and computational requirements for the ML pipeline could enable custom hardware solutions to reduce the cost and energy needs of wearable devices.
PoseBERT: A Generic Transformer Module for Temporal 3D Human Modeling
Aug 22, 2022
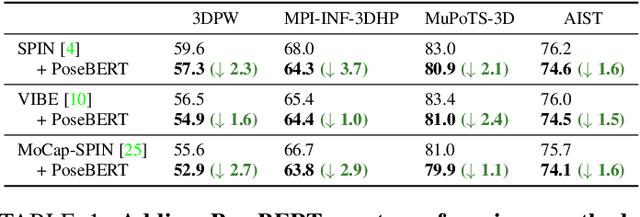
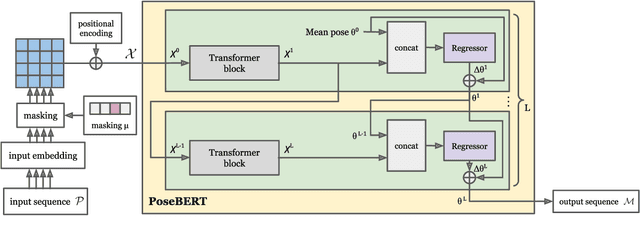
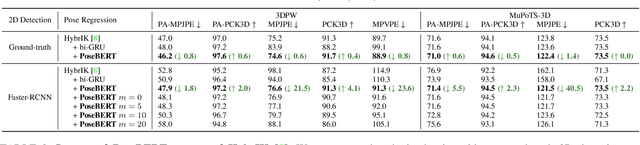
Training state-of-the-art models for human pose estimation in videos requires datasets with annotations that are really hard and expensive to obtain. Although transformers have been recently utilized for body pose sequence modeling, related methods rely on pseudo-ground truth to augment the currently limited training data available for learning such models. In this paper, we introduce PoseBERT, a transformer module that is fully trained on 3D Motion Capture (MoCap) data via masked modeling. It is simple, generic and versatile, as it can be plugged on top of any image-based model to transform it in a video-based model leveraging temporal information. We showcase variants of PoseBERT with different inputs varying from 3D skeleton keypoints to rotations of a 3D parametric model for either the full body (SMPL) or just the hands (MANO). Since PoseBERT training is task agnostic, the model can be applied to several tasks such as pose refinement, future pose prediction or motion completion without finetuning. Our experimental results validate that adding PoseBERT on top of various state-of-the-art pose estimation methods consistently improves their performances, while its low computational cost allows us to use it in a real-time demo for smoothly animating a robotic hand via a webcam. Test code and models are available at https://github.com/naver/posebert.
Trustworthy Visual Analytics in Clinical Gait Analysis: A Case Study for Patients with Cerebral Palsy
Aug 10, 2022
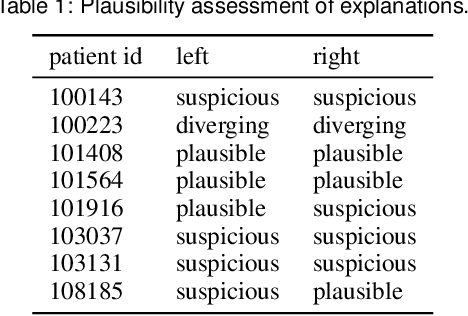
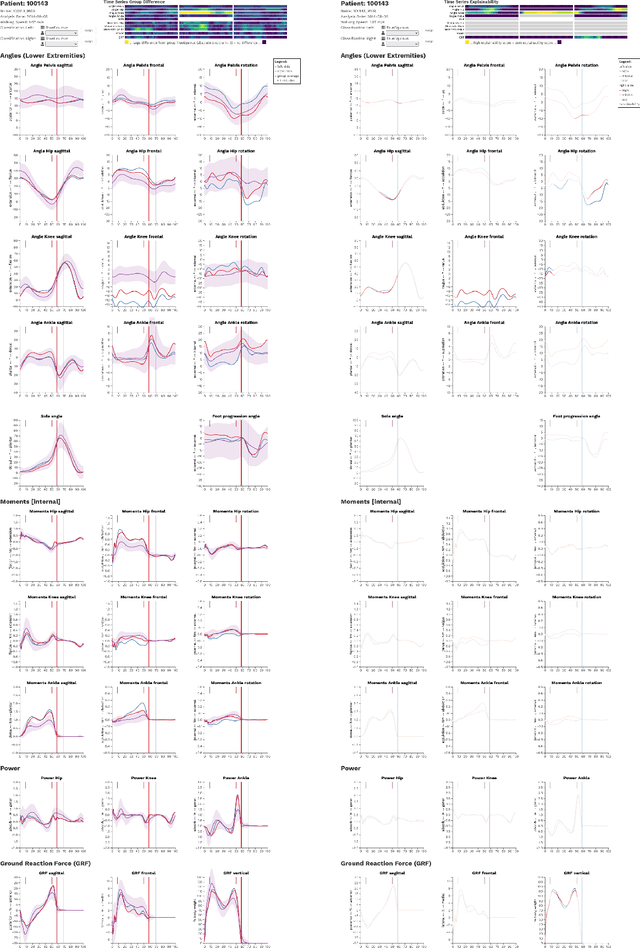
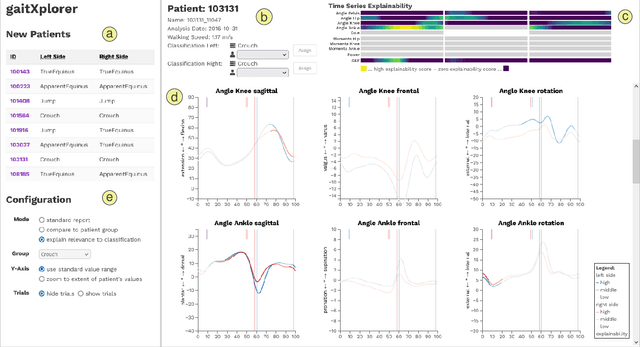
Three-dimensional clinical gait analysis is essential for selecting optimal treatment interventions for patients with cerebral palsy (CP), but generates a large amount of time series data. For the automated analysis of these data, machine learning approaches yield promising results. However, due to their black-box nature, such approaches are often mistrusted by clinicians. We propose gaitXplorer, a visual analytics approach for the classification of CP-related gait patterns that integrates Grad-CAM, a well-established explainable artificial intelligence algorithm, for explanations of machine learning classifications. Regions of high relevance for classification are highlighted in the interactive visual interface. The approach is evaluated in a case study with two clinical gait experts. They inspected the explanations for a sample of eight patients using the visual interface and expressed which relevance scores they found trustworthy and which they found suspicious. Overall, the clinicians gave positive feedback on the approach as it allowed them a better understanding of which regions in the data were relevant for the classification.
Blind Users Accessing Their Training Images in Teachable Object Recognizers
Aug 16, 2022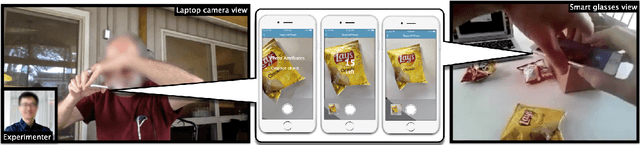
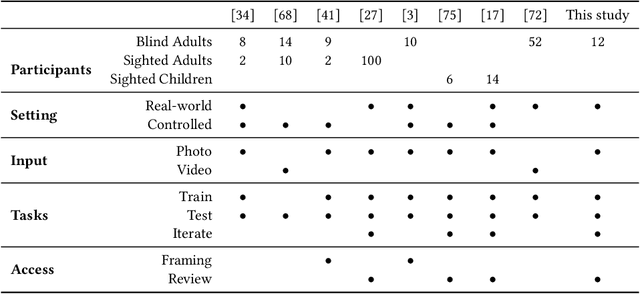
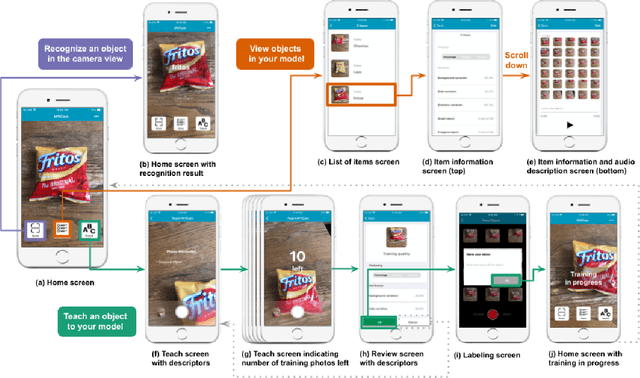

Iteration of training and evaluating a machine learning model is an important process to improve its performance. However, while teachable interfaces enable blind users to train and test an object recognizer with photos taken in their distinctive environment, accessibility of training iteration and evaluation steps has received little attention. Iteration assumes visual inspection of the training photos, which is inaccessible for blind users. We explore this challenge through MyCam, a mobile app that incorporates automatically estimated descriptors for non-visual access to the photos in the users' training sets. We explore how blind participants (N=12) interact with MyCam and the descriptors through an evaluation study in their homes. We demonstrate that the real-time photo-level descriptors enabled blind users to reduce photos with cropped objects, and that participants could add more variations by iterating through and accessing the quality of their training sets. Also, Participants found the app simple to use indicating that they could effectively train it and that the descriptors were useful. However, subjective responses were not reflected in the performance of their models, partially due to little variation in training and cluttered backgrounds.
Simulating Personal Food Consumption Patterns using a Modified Markov Chain
Aug 13, 2022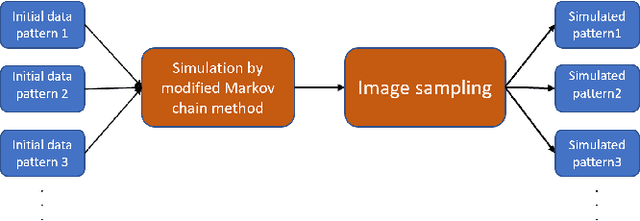
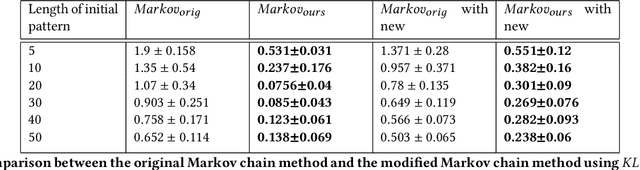
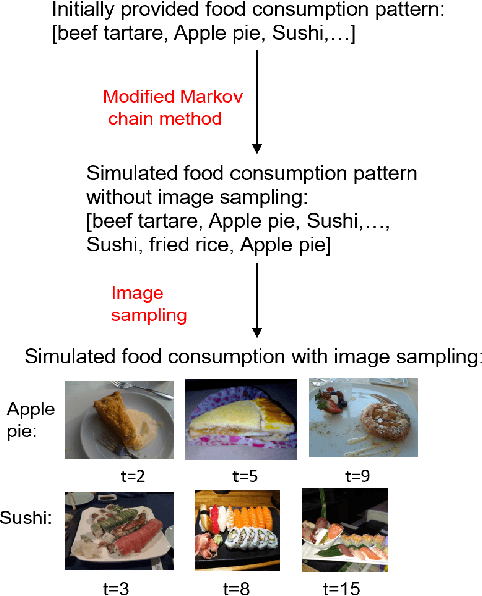
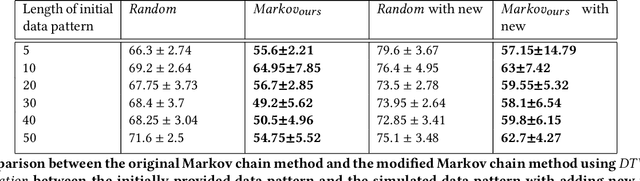
Food image classification serves as the foundation of image-based dietary assessment to predict food categories. Since there are many different food classes in real life, conventional models cannot achieve sufficiently high accuracy. Personalized classifiers aim to largely improve the accuracy of food image classification for each individual. However, a lack of public personal food consumption data proves to be a challenge for training such models. To address this issue, we propose a novel framework to simulate personal food consumption data patterns, leveraging the use of a modified Markov chain model and self-supervised learning. Our method is capable of creating an accurate future data pattern from a limited amount of initial data, and our simulated data patterns can be closely correlated with the initial data pattern. Furthermore, we use Dynamic Time Warping distance and Kullback-Leibler divergence as metrics to evaluate the effectiveness of our method on the public Food-101 dataset. Our experimental results demonstrate promising performance compared with random simulation and the original Markov chain method.