 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding How Blind Users Handle Object Recognition Errors: Strategies and Challenges
Aug 06, 2024



Object recognition technologies hold the potential to support blind and low-vision people in navigating the world around them. However, the gap between benchmark performances and practical usability remains a significant challenge. This paper presents a study aimed at understanding blind users' interaction with object recognition systems for identifying and avoiding errors. Leveraging a pre-existing object recognition system, URCam, fine-tuned for our experiment, we conducted a user study involving 12 blind and low-vision participants. Through in-depth interviews and hands-on error identification tasks, we gained insights into users' experiences, challenges, and strategies for identifying errors in camera-based assistive technologies and object recognition systems. During interviews, many participants preferred independent error review, while expressing apprehension toward misrecognitions. In the error identification task, participants varied viewpoints, backgrounds, and object sizes in their images to avoid and overcome errors. Even after repeating the task, participants identified only half of the errors, and the proportion of errors identified did not significantly differ from their first attempts. Based on these insights, we offer implications for designing accessible interfaces tailored to the needs of blind and low-vision users in identifying object recognition errors.
Blind Users Accessing Their Training Images in Teachable Object Recognizers
Aug 16, 2022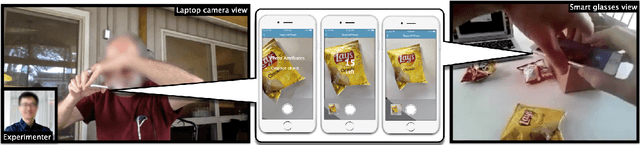
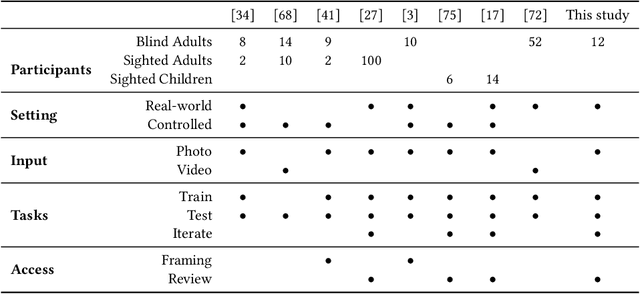
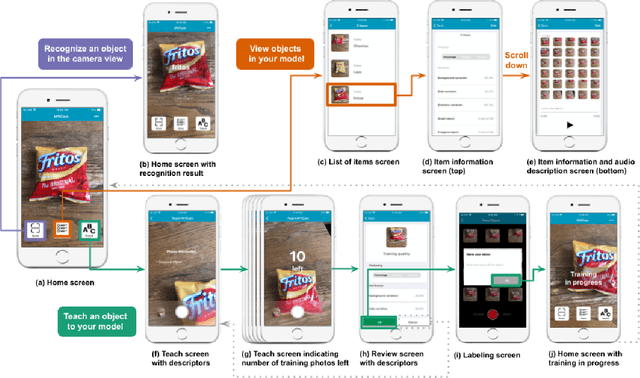

Iteration of training and evaluating a machine learning model is an important process to improve its performance. However, while teachable interfaces enable blind users to train and test an object recognizer with photos taken in their distinctive environment, accessibility of training iteration and evaluation steps has received little attention. Iteration assumes visual inspection of the training photos, which is inaccessible for blind users. We explore this challenge through MyCam, a mobile app that incorporates automatically estimated descriptors for non-visual access to the photos in the users' training sets. We explore how blind participants (N=12) interact with MyCam and the descriptors through an evaluation study in their homes. We demonstrate that the real-time photo-level descriptors enabled blind users to reduce photos with cropped objects, and that participants could add more variations by iterating through and accessing the quality of their training sets. Also, Participants found the app simple to use indicating that they could effectively train it and that the descriptors were useful. However, subjective responses were not reflected in the performance of their models, partially due to little variation in training and cluttered backgrounds.
Crowdsourcing the Perception of Machine Teaching
Feb 05, 2020
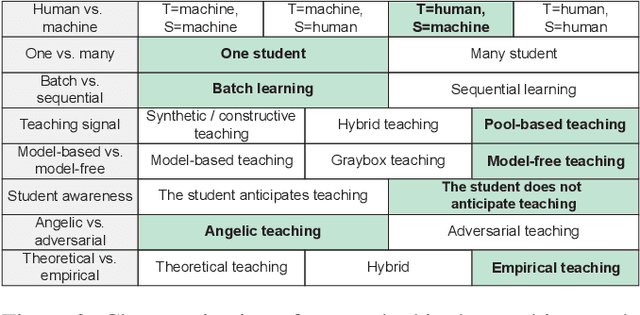
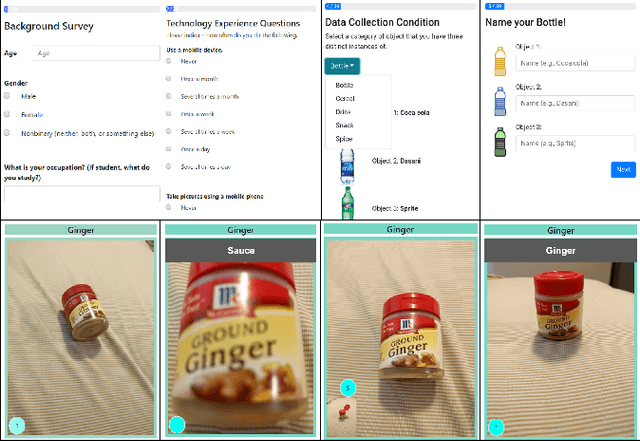
Teachable interfaces can empower end-users to attune machine learning systems to their idiosyncratic characteristics and environment by explicitly providing pertinent training examples. While facilitating control, their effectiveness can be hindered by the lack of expertise or misconceptions. We investigate how users may conceptualize, experience, and reflect on their engagement in machine teaching by deploying a mobile teachable testbed in Amazon Mechanical Turk. Using a performance-based payment scheme, Mechanical Turkers (N = 100) are called to train, test, and re-train a robust recognition model in real-time with a few snapshots taken in their environment. We find that participants incorporate diversity in their examples drawing from parallels to how humans recognize objects independent of size, viewpoint, location, and illumination. Many of their misconceptions relate to consistency and model capabilities for reasoning. With limited variation and edge cases in testing, the majority of them do not change strategies on a second training attempt.
* 10 pages, 8 figures, 5 tables, CHI2020 conference