 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Novel Data Augmentation Technique for Out-of-Distribution Sample Detection using Compounded Corruptions
Jul 28, 2022
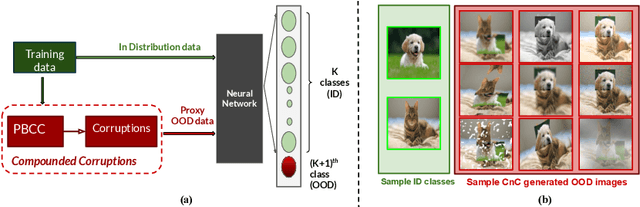
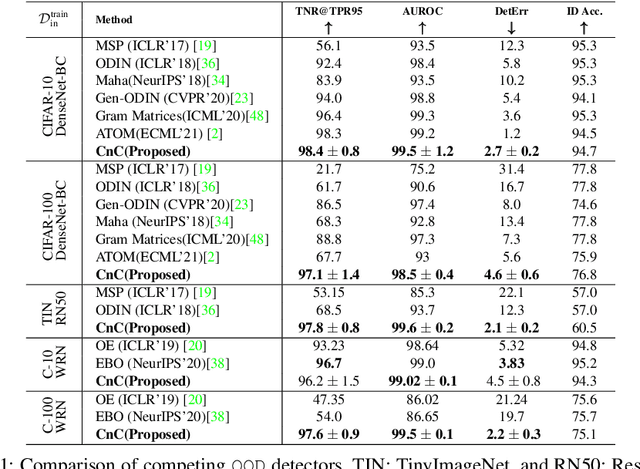
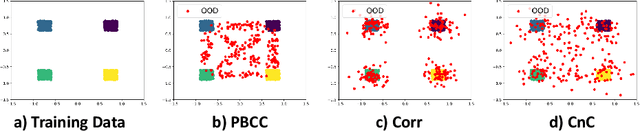
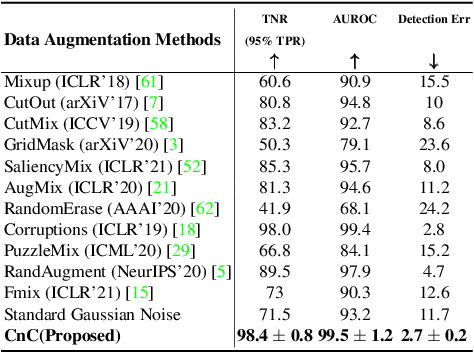
Modern deep neural network models are known to erroneously classify out-of-distribution (OOD) test data into one of the in-distribution (ID) training classes with high confidence. This can have disastrous consequences for safety-critical applications. A popular mitigation strategy is to train a separate classifier that can detect such OOD samples at the test time. In most practical settings OOD examples are not known at the train time, and hence a key question is: how to augment the ID data with synthetic OOD samples for training such an OOD detector? In this paper, we propose a novel Compounded Corruption technique for the OOD data augmentation termed CnC. One of the major advantages of CnC is that it does not require any hold-out data apart from the training set. Further, unlike current state-of-the-art (SOTA) techniques, CnC does not require backpropagation or ensembling at the test time, making our method much faster at inference. Our extensive comparison with 20 methods from the major conferences in last 4 years show that a model trained using CnC based data augmentation, significantly outperforms SOTA, both in terms of OOD detection accuracy as well as inference time. We include a detailed post-hoc analysis to investigate the reasons for the success of our method and identify higher relative entropy and diversity of CnC samples as probable causes. We also provide theoretical insights via a piece-wise decomposition analysis on a two-dimensional dataset to reveal (visually and quantitatively) that our approach leads to a tighter boundary around ID classes, leading to better detection of OOD samples. Source code link: https://github.com/cnc-ood
Real-time detection of anomalies in large-scale transient surveys
Oct 29, 2021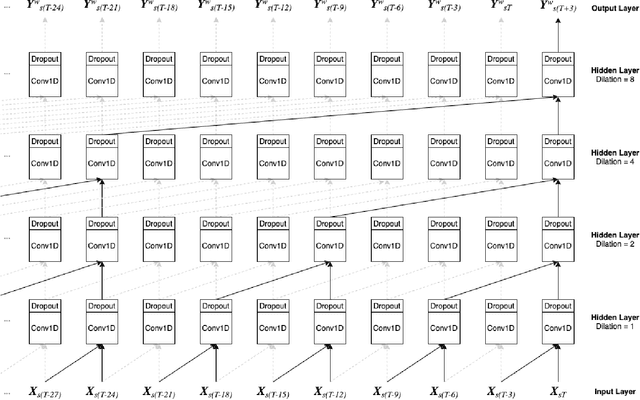

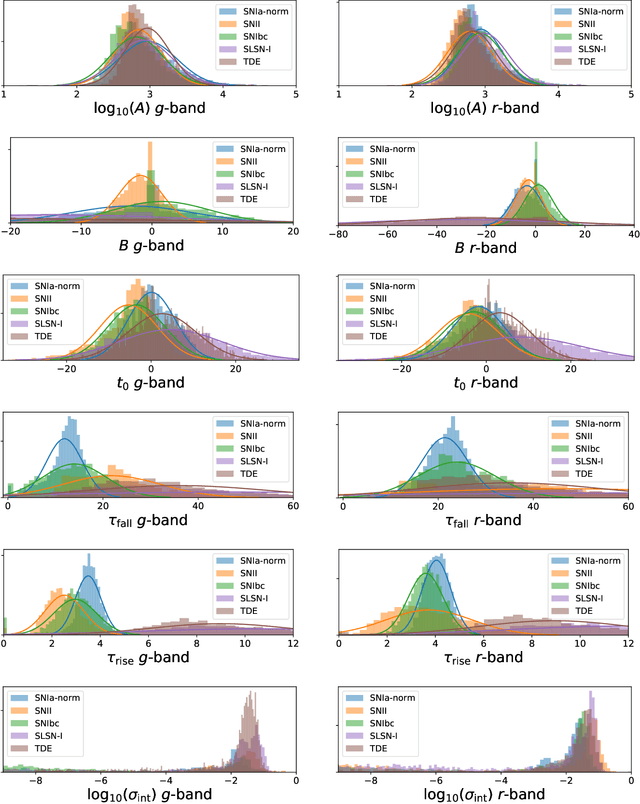
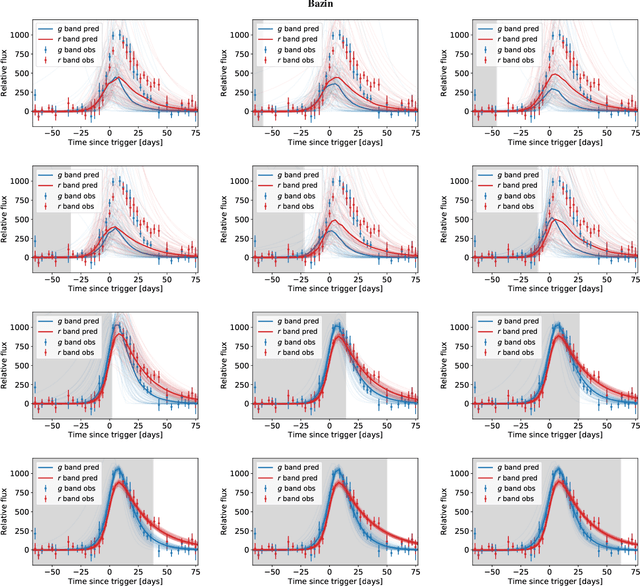
New time-domain surveys, such as the Rubin Observatory Legacy Survey of Space and Time (LSST), will observe millions of transient alerts each night, making standard approaches of visually identifying new and interesting transients infeasible. We present two novel methods of automatically detecting anomalous transient light curves in real-time. Both methods are based on the simple idea that if the light curves from a known population of transients can be accurately modelled, any deviations from model predictions are likely anomalies. The first modelling approach is a probabilistic neural network built using Temporal Convolutional Networks (TCNs) and the second is an interpretable Bayesian parametric model of a transient. We demonstrate our methods' ability to provide anomaly scores as a function of time on light curves from the Zwicky Transient Facility. We show that the flexibility of neural networks, the attribute that makes them such a powerful tool for many regression tasks, is what makes them less suitable for anomaly detection when compared with our parametric model. The parametric model is able to identify anomalies with respect to common supernova classes with low false anomaly rates and high true anomaly rates achieving Area Under the Receive Operating Characteristic (ROC) Curve (AUC) scores above 0.8 for most rare classes such as kilonovae, tidal disruption events, intermediate luminosity transients, and pair-instability supernovae. Our ability to identify anomalies improves over the lifetime of the light curves. Our framework, used in conjunction with transient classifiers, will enable fast and prioritised follow-up of unusual transients from new large-scale surveys.
Inverse-free Online Independent Vector Analysis with Flexible Iterative Source Steering
Sep 02, 2022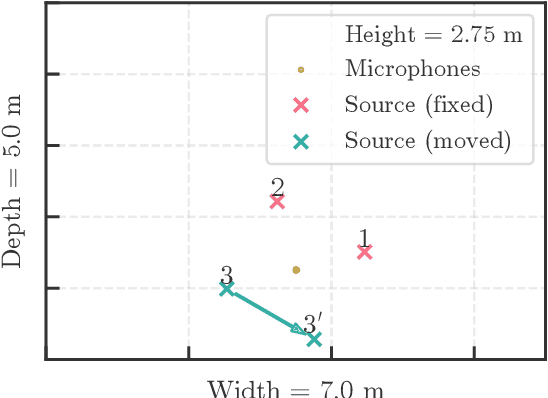
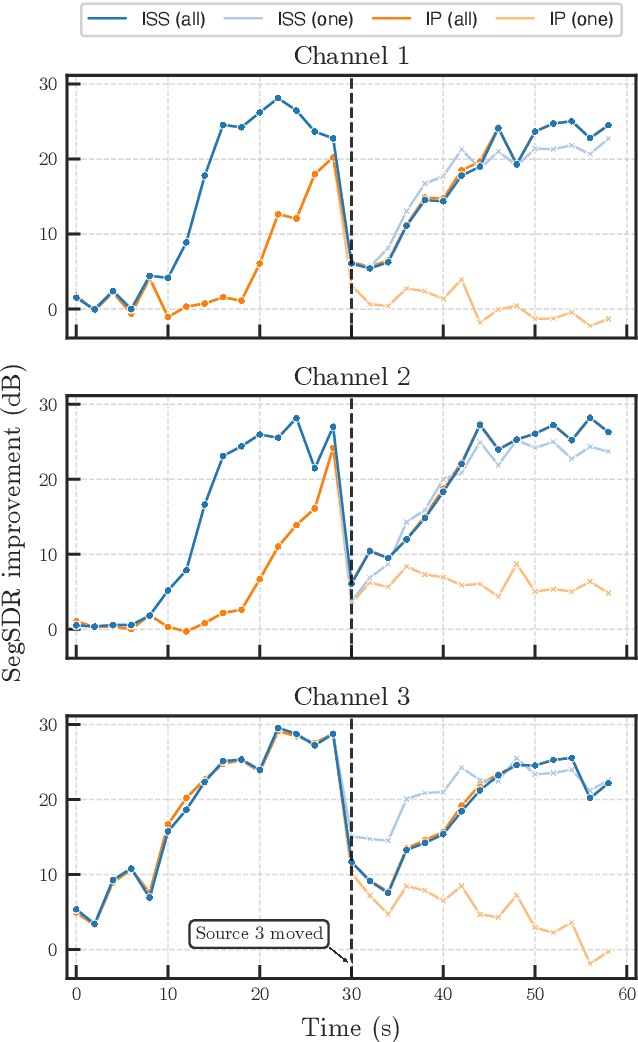
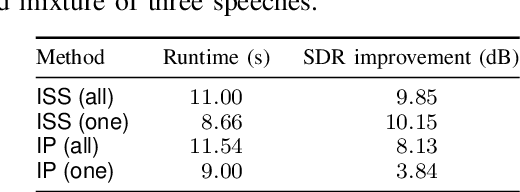
In this paper, we propose a new online independent vector analysis (IVA) algorithm for real-time blind source separation (BSS). In many BSS algorithms, the iterative projection (IP) has been used for updating the demixing matrix, a parameter to be estimated in BSS. However, it requires matrix inversion, which can be costly, particularly in online processing. To improve this situation, we introduce iterative source steering (ISS) to online IVA. ISS does not require any matrix inversions, and thus its computational complexity is less than that of IP. Furthermore, when only part of the sources are moving, ISS enables us to update the demixing matrix flexibly and effectively so that the steering vectors of only the moving sources are updated. Numerical experiments under a dynamic condition confirm the efficacy of the proposed method.
Impact analysis of recovery cases due to COVID19 using LSTM deep learning model
Sep 06, 2022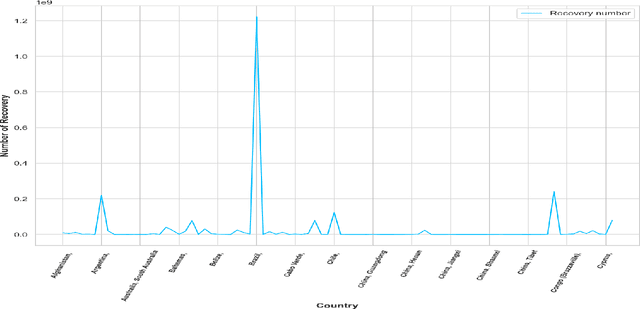



The present world is badly affected by novel coronavirus (COVID-19). Using medical kits to identify the coronavirus affected persons are very slow. What happens in the next, nobody knows. The world is facing erratic problem and do not know what will happen in near future. This paper is trying to make prognosis of the coronavirus recovery cases using LSTM (Long Short Term Memory). This work exploited data of 258 regions, their latitude and longitude and the number of death of 403 days ranging from 22-01-2020 to 27-02-2021. Specifically, advanced deep learning-based algorithms known as the LSTM, play a great effect on extracting highly essential features for time series data (TSD) analysis.There are lots of methods which already use to analyze propagation prediction. The main task of this paper culminates in analyzing the spreading of Coronavirus across worldwide recovery cases using LSTM deep learning-based architectures.
Fast Bayesian Optimization of Needle-in-a-Haystack Problems using Zooming Memory-Based Initialization
Aug 26, 2022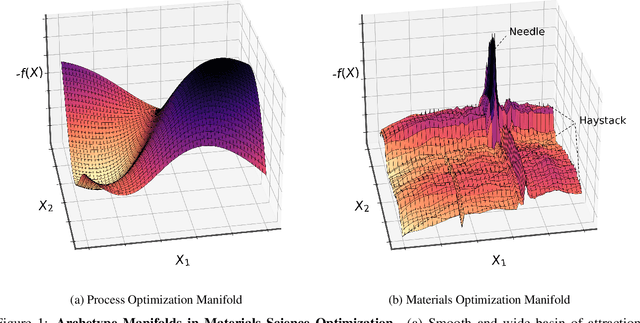
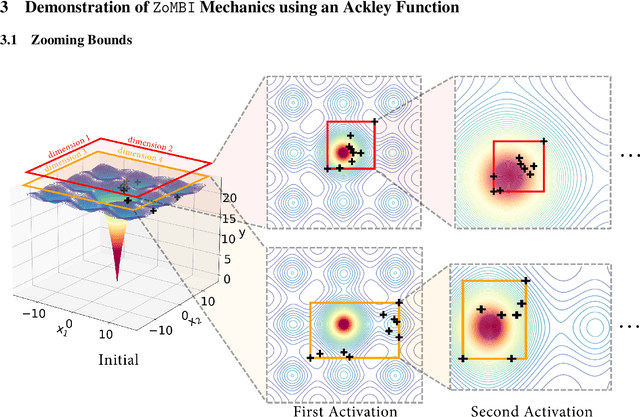
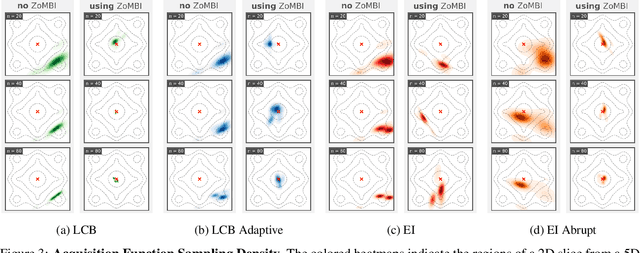
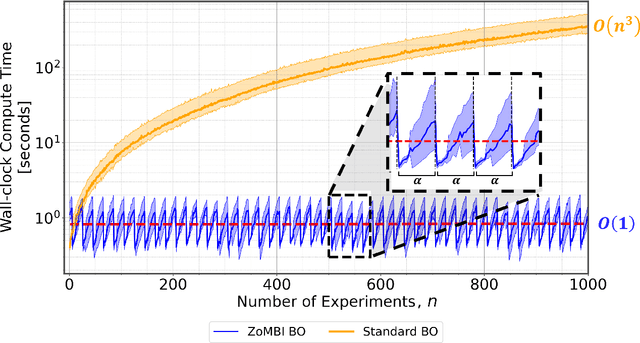
Needle-in-a-Haystack problems exist across a wide range of applications including rare disease prediction, ecological resource management, fraud detection, and material property optimization. A Needle-in-a-Haystack problem arises when there is an extreme imbalance of optimum conditions relative to the size of the dataset. For example, only 0.82% out of 146k total materials in the open-access Materials Project database have a negative Poisson's ratio. However, current state-of-the-art optimization algorithms are not designed with the capabilities to find solutions to these challenging multidimensional Needle-in-a-Haystack problems, resulting in slow convergence to a global optimum or pigeonholing into a local minimum. In this paper, we present a Zooming Memory-Based Initialization algorithm, entitled ZoMBI, that builds on conventional Bayesian optimization principles to quickly and efficiently optimize Needle-in-a-Haystack problems in both less time and fewer experiments by addressing the common convergence and pigeonholing issues. ZoMBI actively extracts knowledge from the previously best-performing evaluated experiments to iteratively zoom in the sampling search bounds towards the global optimum "needle" and then prunes the memory of low-performing historical experiments to accelerate compute times. We validate the algorithm's performance on two real-world 5-dimensional Needle-in-a-Haystack material property optimization datasets: discovery of auxetic Poisson's ratio materials and discovery of high thermoelectric figure of merit materials. The ZoMBI algorithm demonstrates compute time speed-ups of 400x compared to traditional Bayesian optimization as well as efficiently discovering materials in under 100 experiments that are up to 3x more highly optimized than those discovered by current state-of-the-art algorithms.
Real-to-Sim: Deep Learning with Auto-Tuning to Predict Residual Errors using Sparse Data
Sep 07, 2022
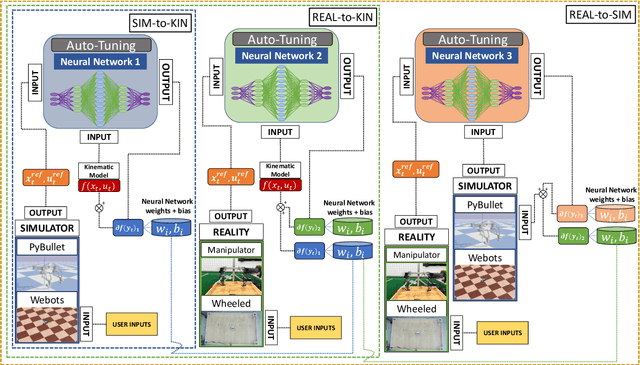
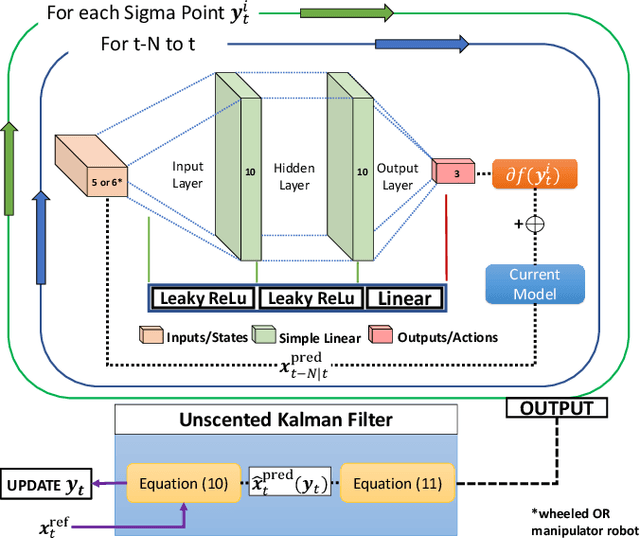

Achieving highly accurate kinematic or simulator models that are close to the real robot can facilitate model-based controls (e.g., model predictive control or linear-quadradic regulators), model-based trajectory planning (e.g., trajectory optimization), and decrease the amount of learning time necessary for reinforcement learning methods. Thus, the objective of this work is to learn the residual errors between a kinematic and/or simulator model and the real robot. This is achieved using auto-tuning and neural networks, where the parameters of a neural network are updated using an auto-tuning method that applies equations from an Unscented Kalman Filter (UKF) formulation. Using this method, we model these residual errors with only small amounts of data - a necessity as we improve the simulator/kinematic model by learning directly from hardware operation. We demonstrate our method on robotic hardware (e.g., manipulator arm), and show that with the learned residual errors, we can further close the reality gap between kinematic models, simulations, and the real robot.
Latent Neural Stochastic Differential Equations for Change Point Detection
Aug 22, 2022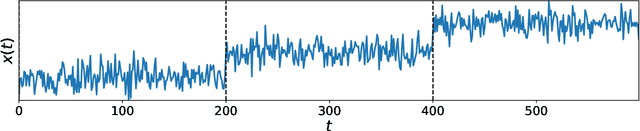
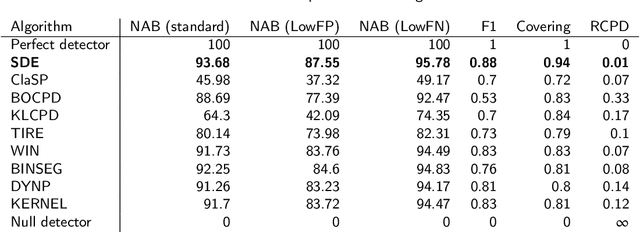
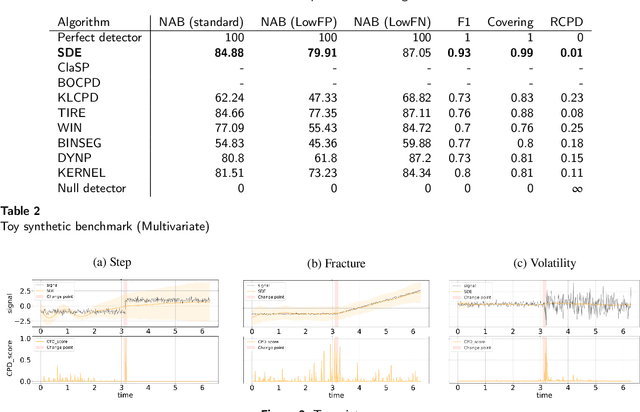
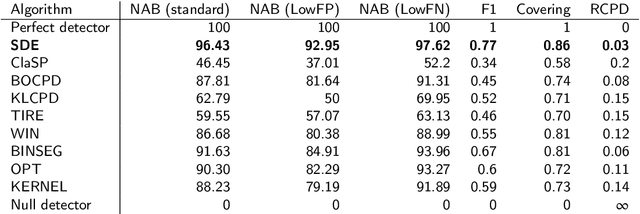
The purpose of change point detection algorithms is to locate an abrupt change in the time evolution of a process. In this paper, we introduce an application of latent neural stochastic differential equations for change point detection problem. We demonstrate the detection capabilities and performance of our model on a range of synthetic and real-world datasets and benchmarks. Most of the studied scenarios show that the proposed algorithm outperforms the state-of-the-art algorithms. We also discuss the strengths and limitations of this approach and indicate directions for further improvements.
MEMO: Test Time Robustness via Adaptation and Augmentation
Oct 18, 2021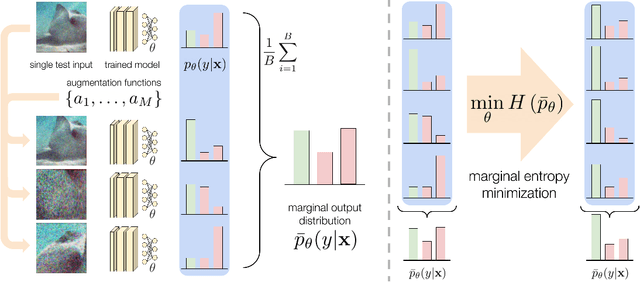


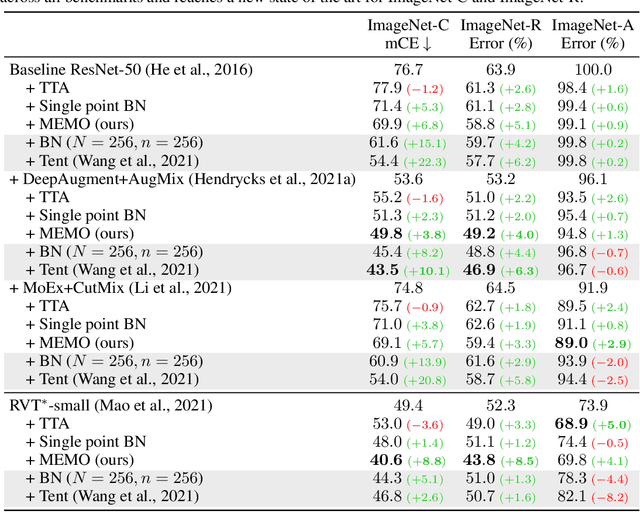
While deep neural networks can attain good accuracy on in-distribution test points, many applications require robustness even in the face of unexpected perturbations in the input, changes in the domain, or other sources of distribution shift. We study the problem of test time robustification, i.e., using the test input to improve model robustness. Recent prior works have proposed methods for test time adaptation, however, they each introduce additional assumptions, such as access to multiple test points, that prevent widespread adoption. In this work, we aim to study and devise methods that make no assumptions about the model training process and are broadly applicable at test time. We propose a simple approach that can be used in any test setting where the model is probabilistic and adaptable: when presented with a test example, perform different data augmentations on the data point, and then adapt (all of) the model parameters by minimizing the entropy of the model's average, or marginal, output distribution across the augmentations. Intuitively, this objective encourages the model to make the same prediction across different augmentations, thus enforcing the invariances encoded in these augmentations, while also maintaining confidence in its predictions. In our experiments, we demonstrate that this approach consistently improves robust ResNet and vision transformer models, achieving accuracy gains of 1-8% over standard model evaluation and also generally outperforming prior augmentation and adaptation strategies. We achieve state-of-the-art results for test shifts caused by image corruptions (ImageNet-C), renditions of common objects (ImageNet-R), and, among ResNet-50 models, adversarially chosen natural examples (ImageNet-A).
What You See is What You Grasp: User-Friendly Grasping Guided by Near-eye-tracking
Sep 13, 2022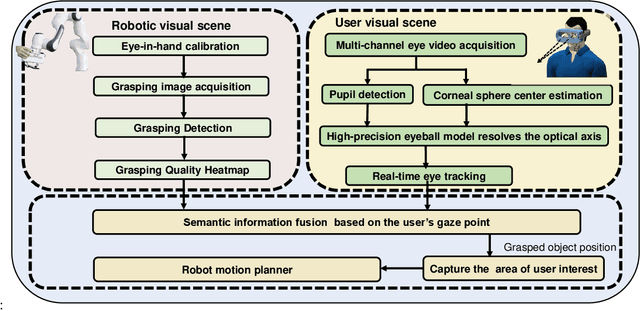

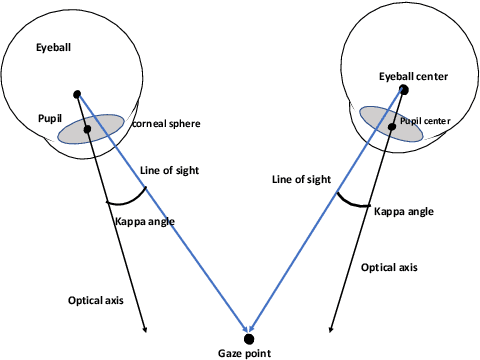
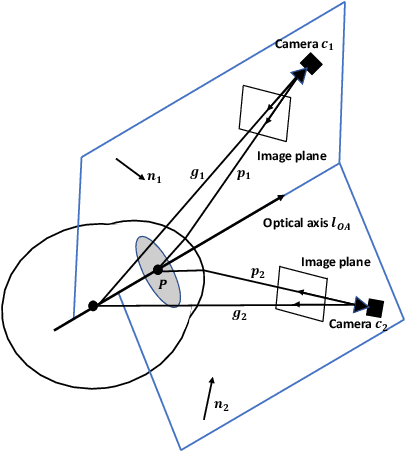
This work presents a next-generation human-robot interface that can infer and realize the user's manipulation intention via sight only. Specifically, we develop a system that integrates near-eye-tracking and robotic manipulation to enable user-specified actions (e.g., grasp, pick-and-place, etc), where visual information is merged with human attention to create a mapping for desired robot actions. To enable sight guided manipulation, a head-mounted near-eye-tracking device is developed to track the eyeball movements in real-time, so that the user's visual attention can be identified. To improve the grasping performance, a transformer based grasp model is then developed. Stacked transformer blocks are used to extract hierarchical features where the volumes of channels are expanded at each stage while squeezing the resolution of feature maps. Experimental validation demonstrates that the eye-tracking system yields low gaze estimation error and the grasping system yields promising results on multiple grasping datasets. This work is a proof of concept for gaze interaction-based assistive robot, which holds great promise to help the elder or upper limb disabilities in their daily lives. A demo video is available at \url{https://www.youtube.com/watch?v=yuZ1hukYUrM}.
Improving Spiking Neural Network Accuracy Using Time-based Neurons
Jan 05, 2022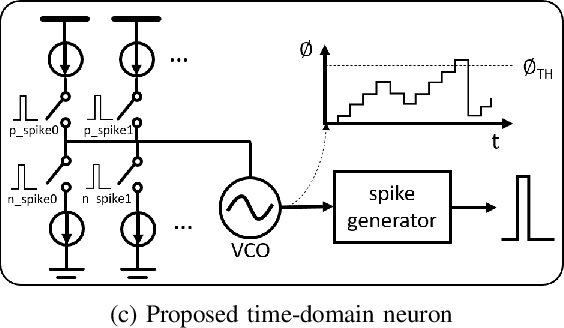
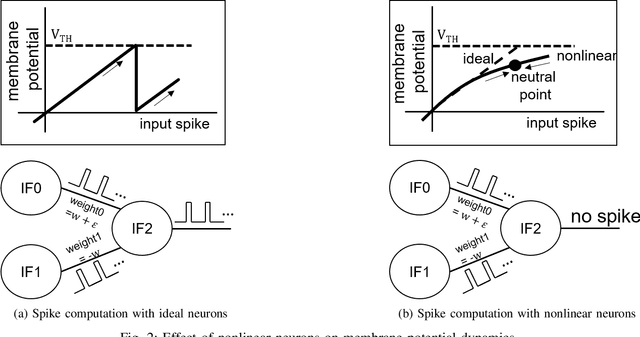
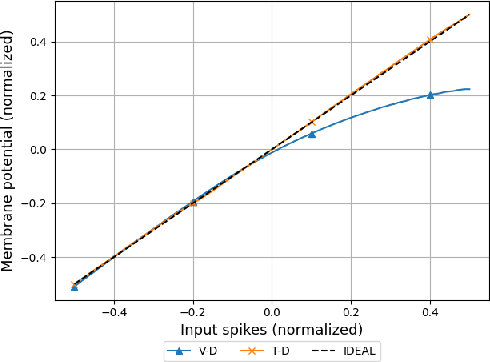
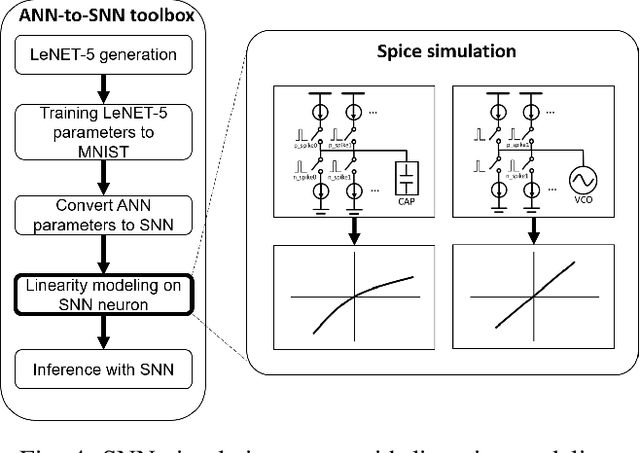
Due to the fundamental limit to reducing power consumption of running deep learning models on von-Neumann architecture, research on neuromorphic computing systems based on low-power spiking neural networks using analog neurons is in the spotlight. In order to integrate a large number of neurons, neurons need to be designed to occupy a small area, but as technology scales down, analog neurons are difficult to scale, and they suffer from reduced voltage headroom/dynamic range and circuit nonlinearities. In light of this, this paper first models the nonlinear behavior of existing current-mirror-based voltage-domain neurons designed in a 28nm process, and show SNN inference accuracy can be severely degraded by the effect of neuron's nonlinearity. Then, to mitigate this problem, we propose a novel neuron, which processes incoming spikes in the time domain and greatly improves the linearity, thereby improving the inference accuracy compared to the existing voltage-domain neuron. Tested on the MNIST dataset, the inference error rate of the proposed neuron differs by less than 0.1% from that of the ideal neuron.