 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PL-EVIO: Robust Monocular Event-based Visual Inertial Odometry with Point and Line Features
Sep 25, 2022
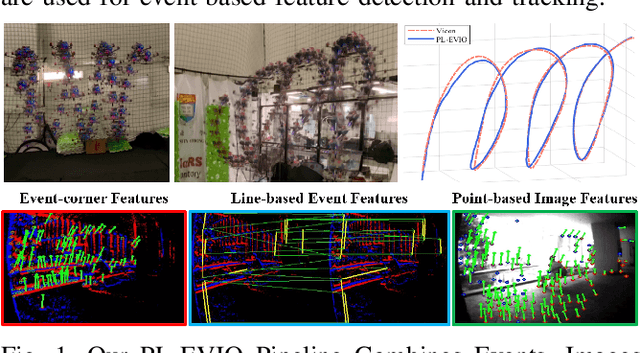
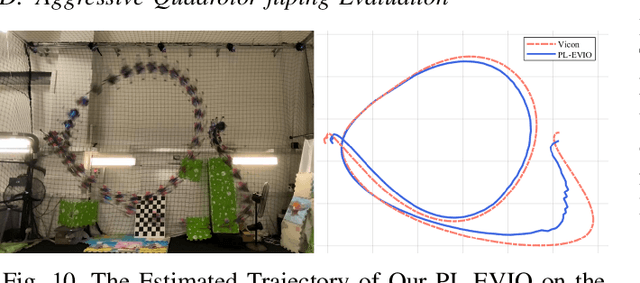
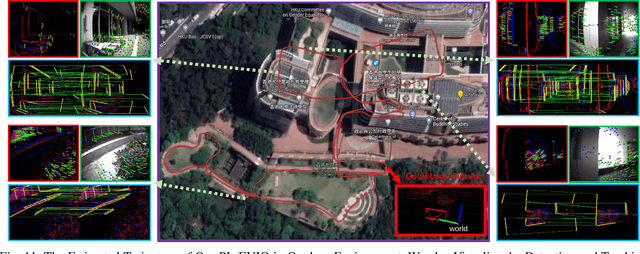
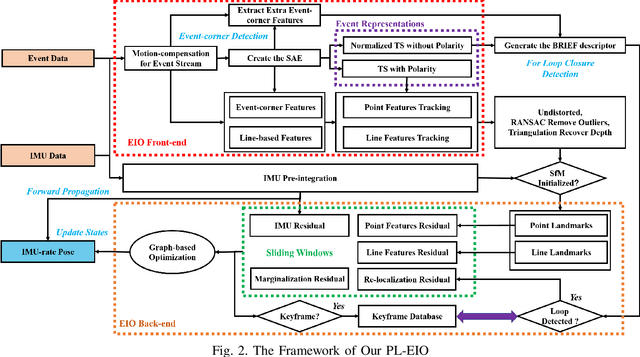
Event cameras are motion-activated sensors that capture pixel-level illumination changes instead of the intensity image with a fixed frame rate. Compared with the standard cameras, it can provide reliable visual perception during high-speed motions and in high dynamic range scenarios. However, event cameras output only a little information or even noise when the relative motion between the camera and the scene is limited, such as in a still state. While standard cameras can provide rich perception information in most scenarios, especially in good lighting conditions. These two cameras are exactly complementary. In this paper, we proposed a robust, high-accurate, and real-time optimization-based monocular event-based visual-inertial odometry (VIO) method with event-corner features, line-based event features, and point-based image features. The proposed method offers to leverage the point-based features in the nature scene and line-based features in the human-made scene to provide more additional structure or constraints information through well-design feature management. Experiments in the public benchmark datasets show that our method can achieve superior performance compared with the state-of-the-art image-based or event-based VIO. Finally, we used our method to demonstrate an onboard closed-loop autonomous quadrotor flight and large-scale outdoor experiments. Videos of the evaluations are presented on our project website: https://b23.tv/OE3QM6j
Non-Linguistic Supervision for Contrastive Learning of Sentence Embeddings
Sep 20, 2022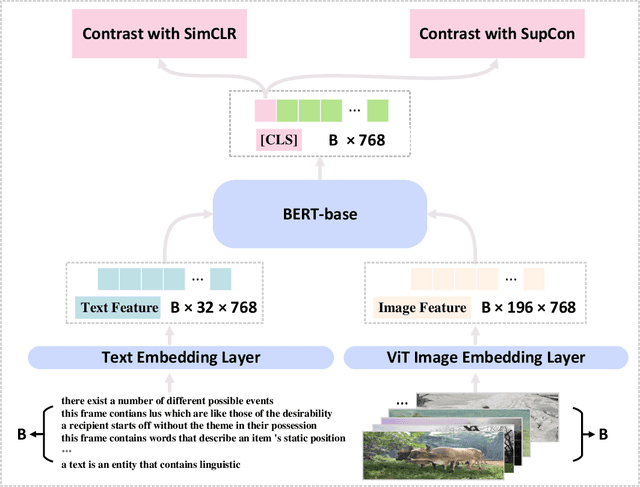
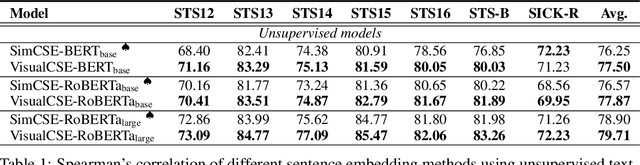
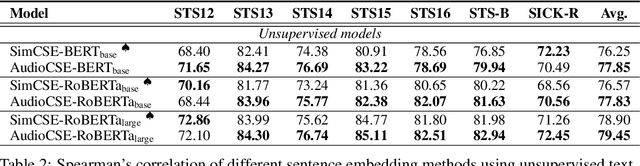

Semantic representation learning for sentences is an important and well-studied problem in NLP. The current trend for this task involves training a Transformer-based sentence encoder through a contrastive objective with text, i.e., clustering sentences with semantically similar meanings and scattering others. In this work, we find the performance of Transformer models as sentence encoders can be improved by training with multi-modal multi-task losses, using unpaired examples from another modality (e.g., sentences and unrelated image/audio data). In particular, besides learning by the contrastive loss on text, our model clusters examples from a non-linguistic domain (e.g., visual/audio) with a similar contrastive loss at the same time. The reliance of our framework on unpaired non-linguistic data makes it language-agnostic, enabling it to be widely applicable beyond English NLP. Experiments on 7 semantic textual similarity benchmarks reveal that models trained with the additional non-linguistic (images/audio) contrastive objective lead to higher quality sentence embeddings. This indicates that Transformer models are able to generalize better by doing a similar task (i.e., clustering) with unpaired examples from different modalities in a multi-task fashion.
The Role of Voice Persona in Expressive Communication:An Argument for Relevance in Speech Synthesis Design
Sep 06, 2022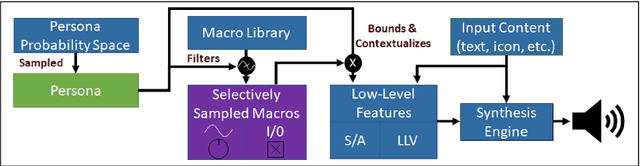
We present an approach to imbuing expressivity in a synthesized voice by acquiring a thematic analysis of 10 interviews with vocal studies and performance experts to inform the design framework for a real-time, interactive vocal persona that would generate compelling and appropriate contextually-dependent expression. The resultant tone of voice is defined as a point existing within a continuous, contextually-dependent probability space. The inclusion of voice persona in synthesized voice can be significant in a broad range of applications. Of particular interest is the potential impact in augmentative and assistive communication (AAC) community. Finally, we conclude with an introduction to our ongoing research investigating the themes of vocal persona and how they may continue to inform proposed expressive speech synthesis design frameworks.
Predicting Code Review Completion Time in Modern Code Review
Sep 30, 2021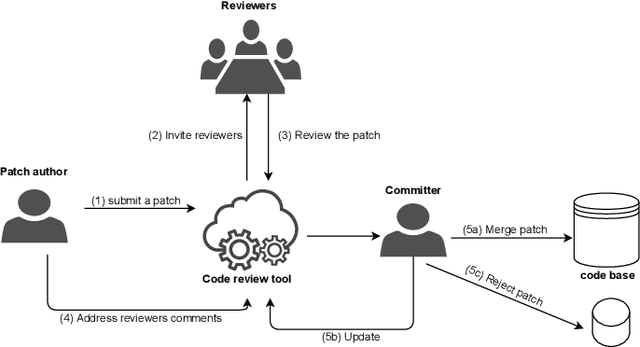
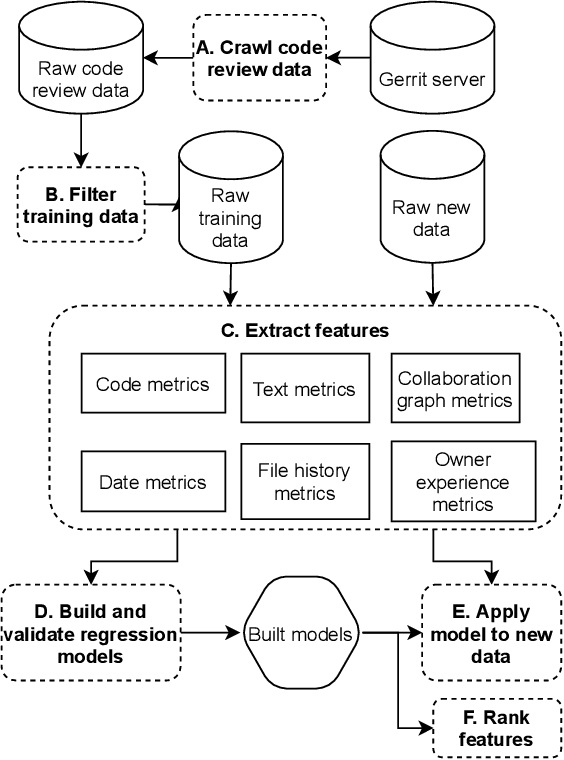
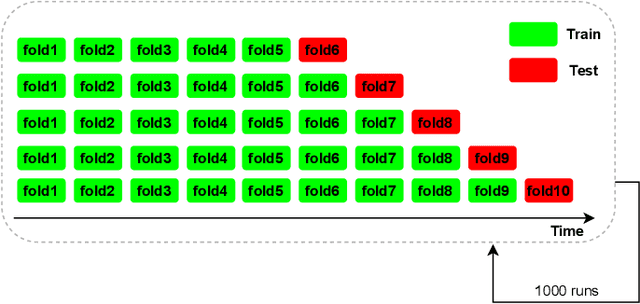
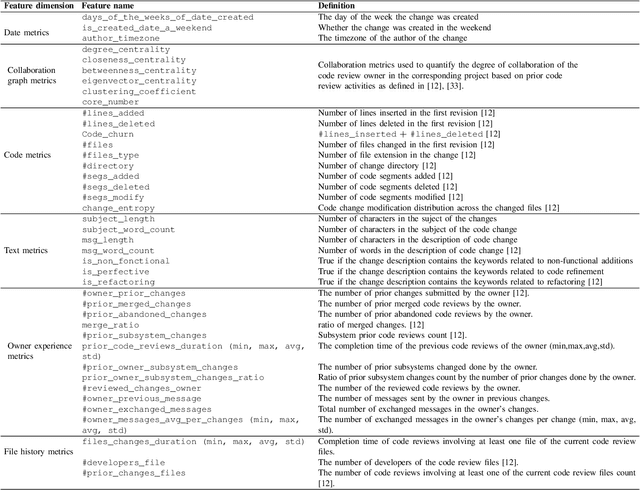
Context. Modern Code Review (MCR) is being adopted in both open source and commercial projects as a common practice. MCR is a widely acknowledged quality assurance practice that allows early detection of defects as well as poor coding practices. It also brings several other benefits such as knowledge sharing, team awareness, and collaboration. Problem. In practice, code reviews can experience significant delays to be completed due to various socio-technical factors which can affect the project quality and cost. For a successful review process, peer reviewers should perform their review tasks in a timely manner while providing relevant feedback about the code change being reviewed. However, there is a lack of tool support to help developers estimating the time required to complete a code review prior to accepting or declining a review request. Objective. Our objective is to build and validate an effective approach to predict the code review completion time in the context of MCR and help developers better manage and prioritize their code review tasks. Method. We formulate the prediction of the code review completion time as a learning problem. In particular, we propose a framework based on regression models to (i) effectively estimate the code review completion time, and (ii) understand the main factors influencing code review completion time.
Symbolic Knowledge Extraction from Opaque Predictors Applied to Cosmic-Ray Data Gathered with LISA Pathfinder
Sep 10, 2022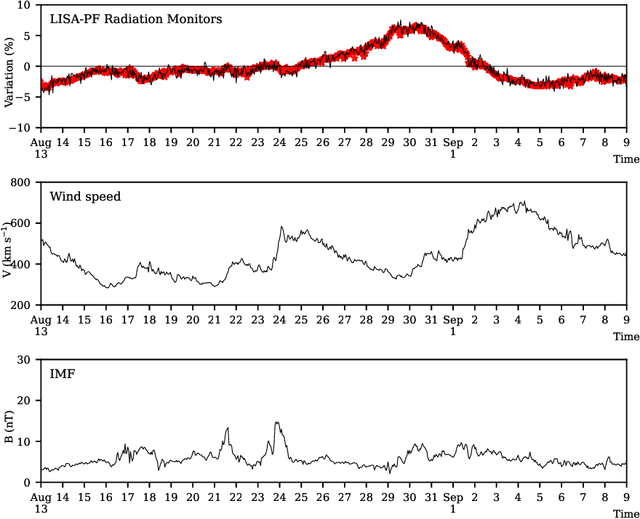
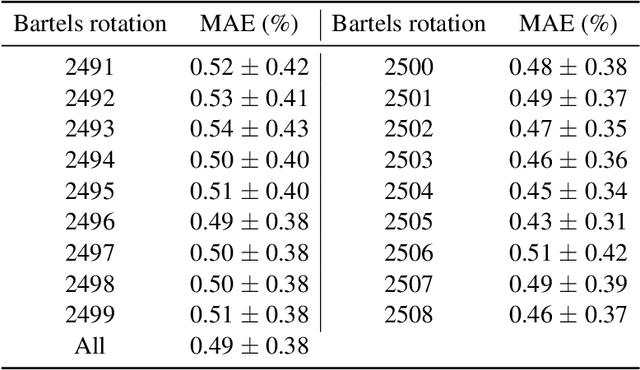
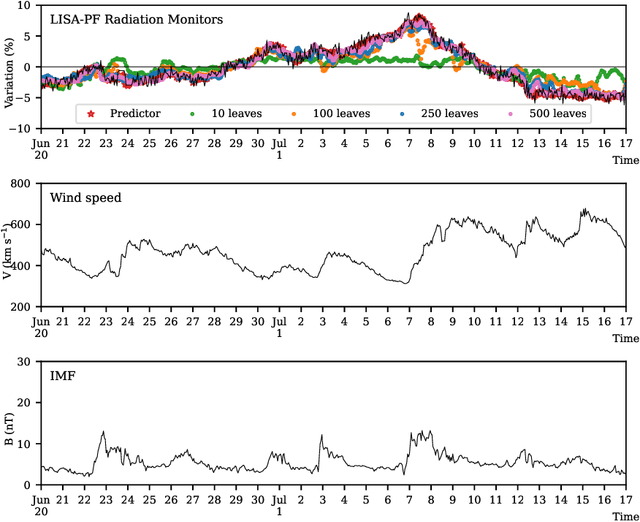
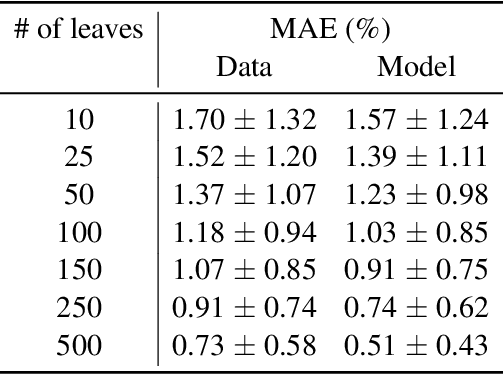
Machine learning models are nowadays ubiquitous in space missions, performing a wide variety of tasks ranging from the prediction of multivariate time series through the detection of specific patterns in the input data. Adopted models are usually deep neural networks or other complex machine learning algorithms providing predictions that are opaque, i.e., human users are not allowed to understand the rationale behind the provided predictions. Several techniques exist in the literature to combine the impressive predictive performance of opaque machine learning models with human-intelligible prediction explanations, as for instance the application of symbolic knowledge extraction procedures. In this paper are reported the results of different knowledge extractors applied to an ensemble predictor capable of reproducing cosmic-ray data gathered on board the LISA Pathfinder space mission. A discussion about the readability/fidelity trade-off of the extracted knowledge is also presented.
Parallel Reinforcement Learning Simulation for Visual Quadrotor Navigation
Sep 22, 2022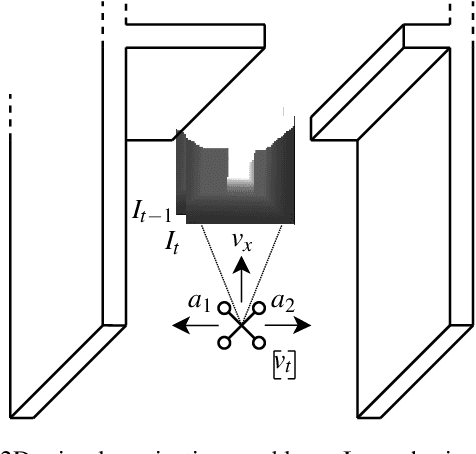
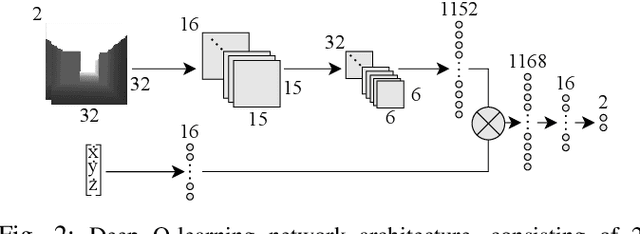

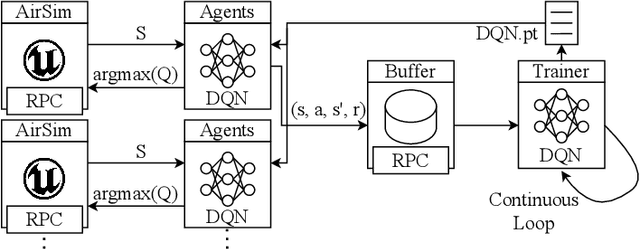
Reinforcement learning (RL) is an agent-based approach for teaching robots to navigate within the physical world. Gathering data for RL is known to be a laborious task, and real-world experiments can be risky. Simulators facilitate the collection of training data in a quicker and more cost-effective manner. However, RL frequently requires a significant number of simulation steps for an agent to become skilful at simple tasks. This is a prevalent issue within the field of RL-based visual quadrotor navigation where state dimensions are typically very large and dynamic models are complex. Furthermore, rendering images and obtaining physical properties of the agent can be computationally expensive. To solve this, we present a simulation framework, built on AirSim, which provides efficient parallel training. Building on this framework, Ape-X is modified to incorporate decentralised training of AirSim environments to make use of numerous networked computers. Through experiments we were able to achieve a reduction in training time from 3.9 hours to 11 minutes using the aforementioned framework and a total of 74 agents and two networked computers. Further details including a github repo and videos about our project, PRL4AirSim, can be found at https://sites.google.com/view/prl4airsim/home
Survey of Machine Learning Techniques To Predict Heartbeat Arrhythmias
Aug 22, 2022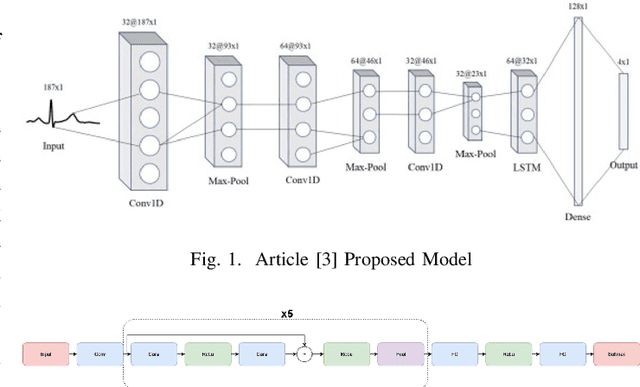
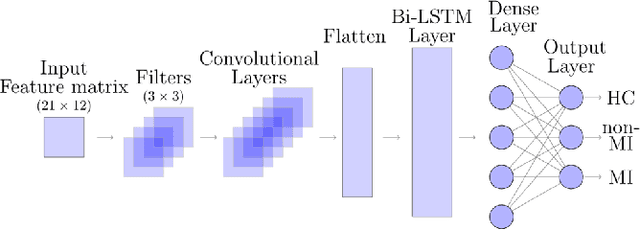
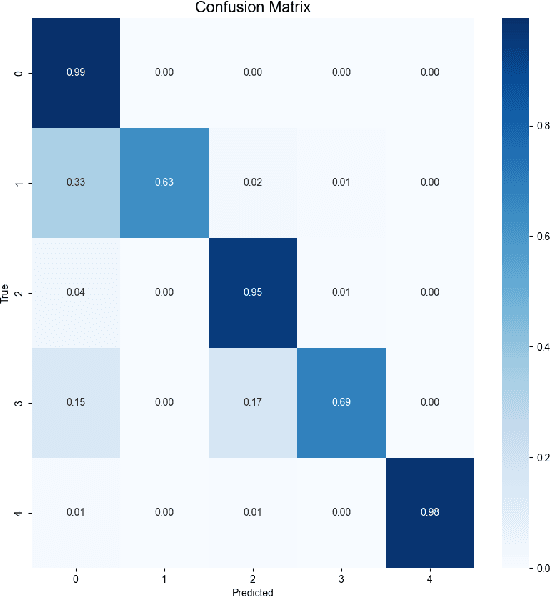
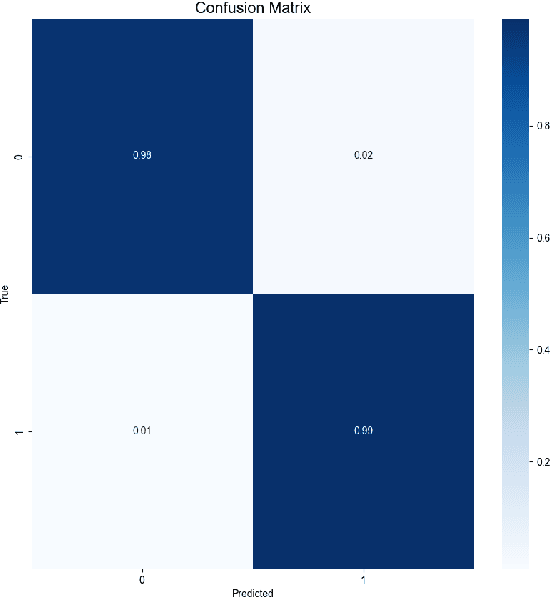
Many works in biomedical computer science research use machine learning techniques to give accurate results. However, these techniques may not be feasible for real-time analysis of data pulled from live hospital feeds. In this project, different machine learning techniques are compared from various sources to find one that provides not only high accuracy but also low latency and memory overhead to be used in real-world health care systems.
Data-Driven Outage Restoration Time Prediction via Transfer Learning with Cluster Ensembles
Dec 21, 2021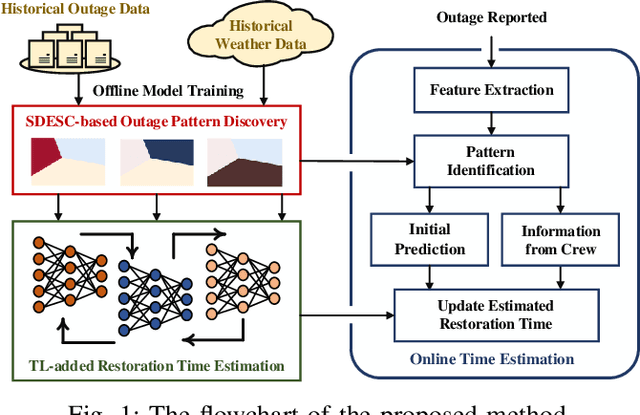
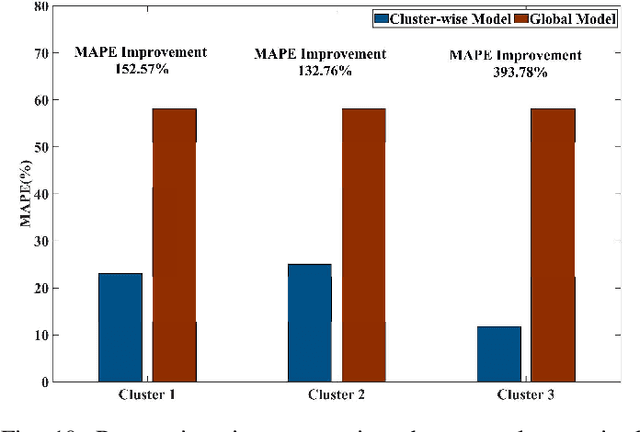
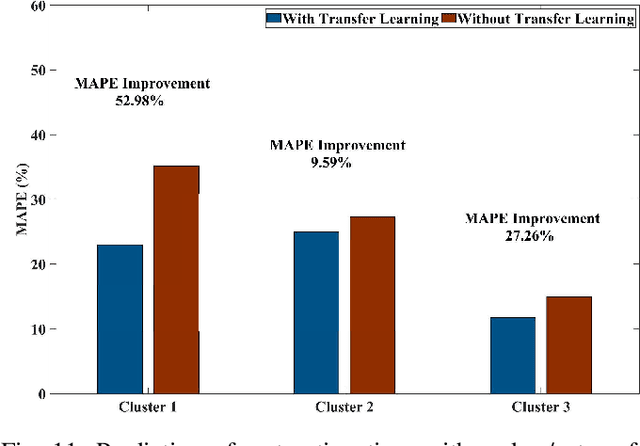
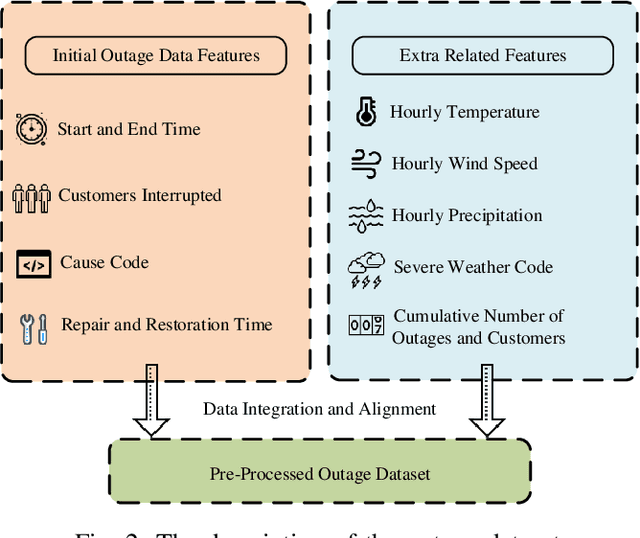
This paper develops a data-driven approach to accurately predict the restoration time of outages under different scales and factors. To achieve the goal, the proposed method consists of three stages. First, given the unprecedented amount of data collected by utilities, a sparse dictionary-based ensemble spectral clustering (SDESC) method is proposed to decompose historical outage datasets, which enjoys good computational efficiency and scalability. Specifically, each outage sample is represented by a linear combination of a small number of selected dictionary samples using a density-based method. Then, the dictionary-based representation is utilized to perform the spectral analysis to group the data samples with similar features into the same subsets. In the second stage, a knowledge-transfer-added restoration time prediction model is trained for each subset by combining weather information and outage-related features. The transfer learning technology is introduced with the aim of dealing with the underestimation problem caused by data imbalance in different subsets, thus improving the model performance. Furthermore, to connect unseen outages with the learned outage subsets, a t-distributed stochastic neighbor embedding-based strategy is applied. The proposed method fully builds on and is also tested on a large real-world outage dataset from a utility provider with a time span of six consecutive years. The numerical results validate that our method has high prediction accuracy while showing good stability against real-world data limitations.
NEURAL MARIONETTE: A Transformer-based Multi-action Human Motion Synthesis System
Sep 27, 2022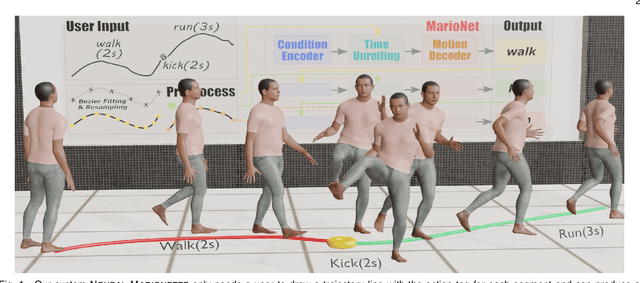
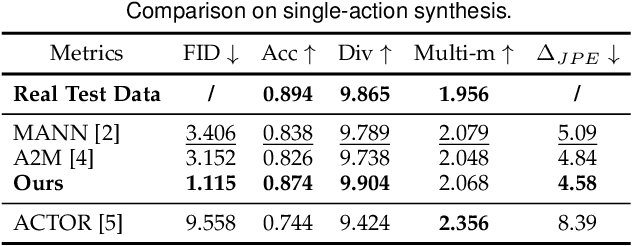

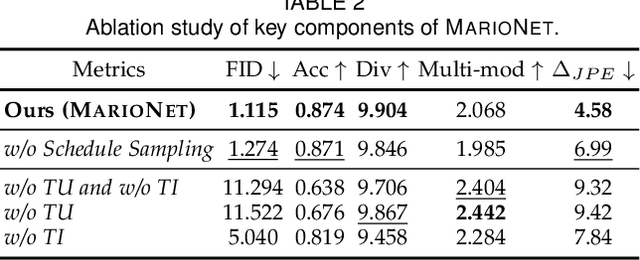
We present a neural network-based system for long-term, multi-action human motion synthesis. The system, dubbed as NEURAL MARIONETTE, can produce high-quality and meaningful motions with smooth transitions from simple user input, including a sequence of action tags with expected action duration, and optionally a hand-drawn moving trajectory if the user specifies. The core of our system is a novel Transformer-based motion generation model, namely MARIONET, which can generate diverse motions given action tags. Different from existing motion generation models, MARIONET utilizes contextual information from the past motion clip and future action tag, dedicated to generating actions that can smoothly blend historical and future actions. Specifically, MARIONET first encodes target action tag and contextual information into an action-level latent code. The code is unfolded into frame-level control signals via a time unrolling module, which could be then combined with other frame-level control signals like the target trajectory. Motion frames are then generated in an auto-regressive way. By sequentially applying MARIONET, the system NEURAL MARIONETTE can robustly generate long-term, multi-action motions with the help of two simple schemes, namely "Shadow Start" and "Action Revision". Along with the novel system, we also present a new dataset dedicated to the multi-action motion synthesis task, which contains both action tags and their contextual information. Extensive experiments are conducted to study the action accuracy, naturalism, and transition smoothness of the motions generated by our system.
Placing Human Animations into 3D Scenes by Learning Interaction- and Geometry-Driven Keyframes
Sep 13, 2022
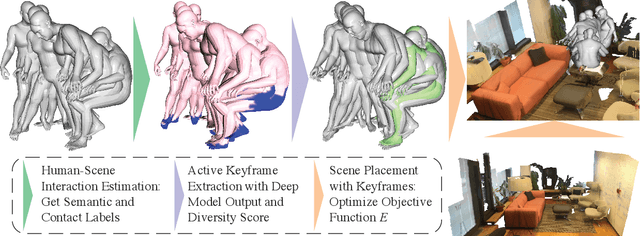
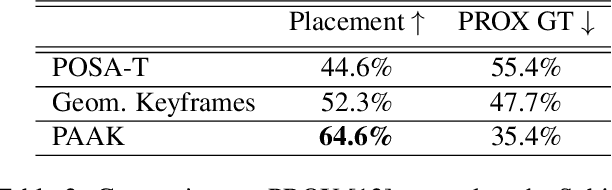
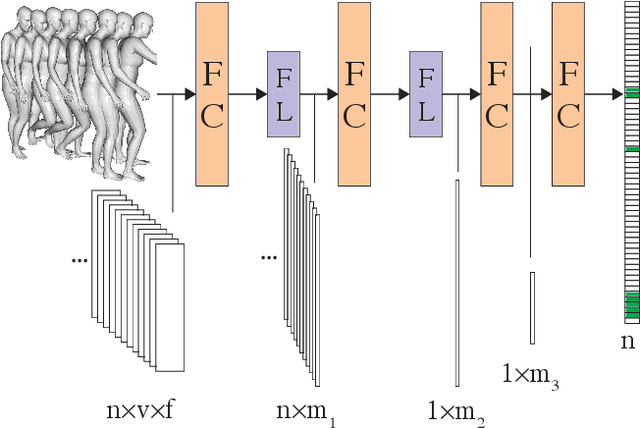
We present a novel method for placing a 3D human animation into a 3D scene while maintaining any human-scene interactions in the animation. We use the notion of computing the most important meshes in the animation for the interaction with the scene, which we call "keyframes." These keyframes allow us to better optimize the placement of the animation into the scene such that interactions in the animations (standing, laying, sitting, etc.) match the affordances of the scene (e.g., standing on the floor or laying in a bed). We compare our method, which we call PAAK, with prior approaches, including POSA, PROX ground truth, and a motion synthesis method, and highlight the benefits of our method with a perceptual study. Human raters preferred our PAAK method over the PROX ground truth data 64.6\% of the time. Additionally, in direct comparisons, the raters preferred PAAK over competing methods including 61.5\% compared to POSA.