 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Fairness Improvement Based on Causality Analysis
Sep 15, 2022

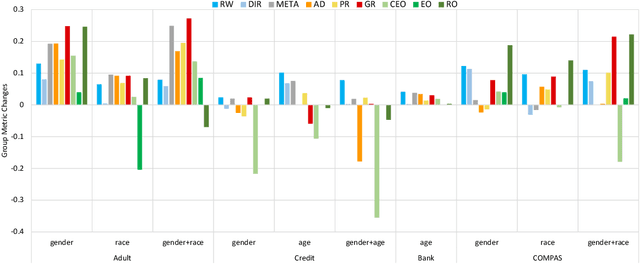
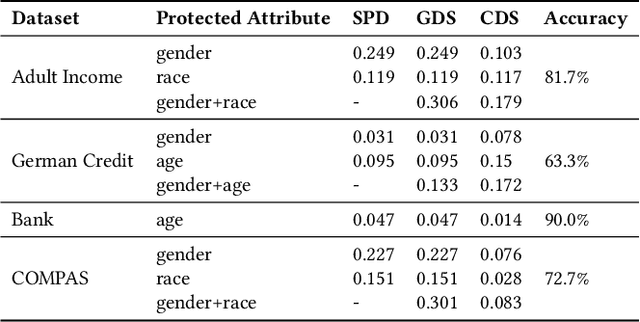
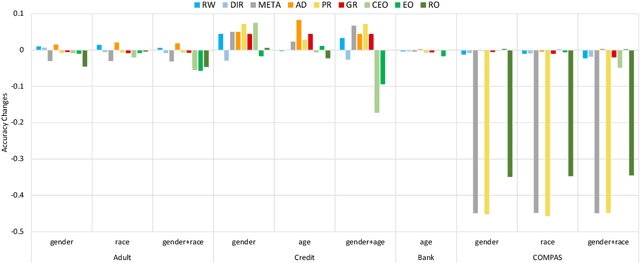
Given a discriminating neural network, the problem of fairness improvement is to systematically reduce discrimination without significantly scarifies its performance (i.e., accuracy). Multiple categories of fairness improving methods have been proposed for neural networks, including pre-processing, in-processing and post-processing. Our empirical study however shows that these methods are not always effective (e.g., they may improve fairness by paying the price of huge accuracy drop) or even not helpful (e.g., they may even worsen both fairness and accuracy). In this work, we propose an approach which adaptively chooses the fairness improving method based on causality analysis. That is, we choose the method based on how the neurons and attributes responsible for unfairness are distributed among the input attributes and the hidden neurons. Our experimental evaluation shows that our approach is effective (i.e., always identify the best fairness improving method) and efficient (i.e., with an average time overhead of 5 minutes).
MSGNN: A Spectral Graph Neural Network Based on a Novel Magnetic Signed Laplacian
Sep 18, 2022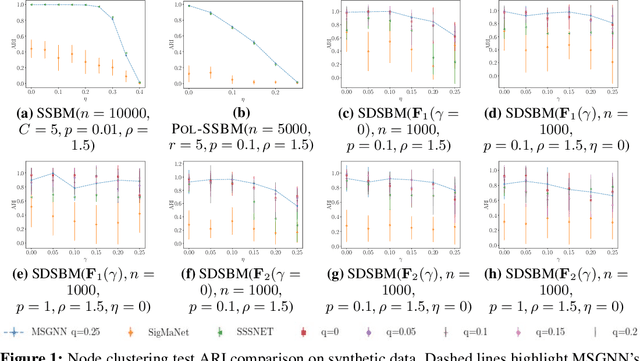
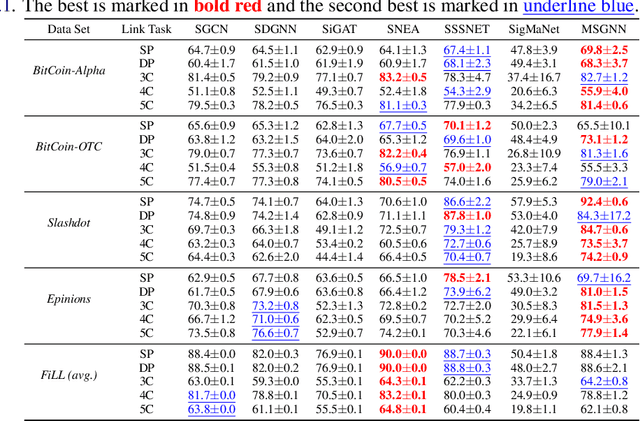
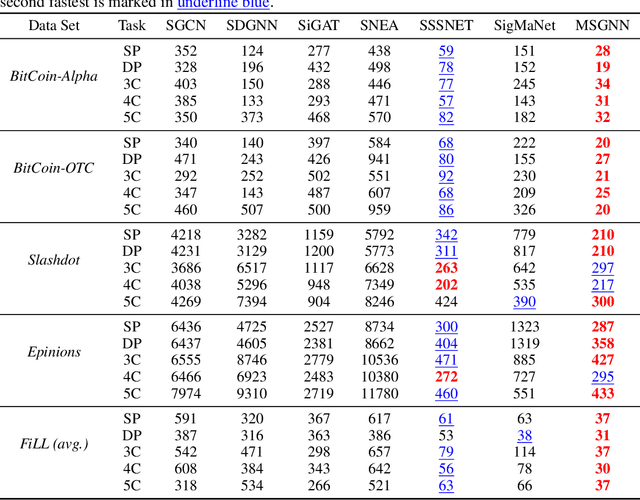
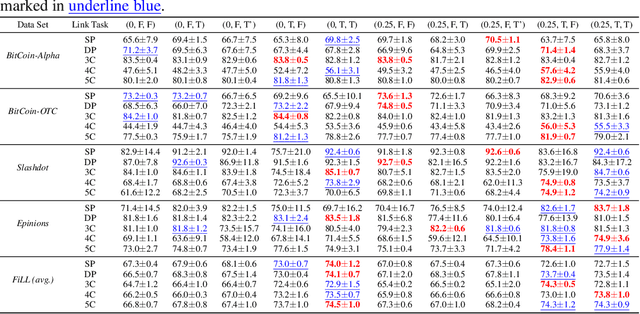
Signed and directed networks are ubiquitous in real-world applications. However, there has been relatively little work proposing spectral graph neural networks (GNNs) for such networks. Here we introduce a signed directed Laplacian matrix, which we call the magnetic signed Laplacian, as a natural generalization of both the signed Laplacian on signed graphs and the magnetic Laplacian on directed graphs. We then use this matrix to construct a novel efficient spectral GNN architecture and conduct extensive experiments on both node clustering and link prediction tasks. In these experiments, we consider tasks related to signed information, tasks related to directional information, and tasks related to both signed and directional information. We demonstrate that our proposed spectral GNN is effective for incorporating both signed and directional information, and attains leading performance on a wide range of data sets. Additionally, we provide a novel synthetic network model, which we refer to as the signed directed stochastic block model, and a number of novel real-world data sets based on lead-lag relationships in financial time series.
D-InLoc++: Indoor Localization in Dynamic Environments
Sep 21, 2022



Most state-of-the-art localization algorithms rely on robust relative pose estimation and geometry verification to obtain moving object agnostic camera poses in complex indoor environments. However, this approach is prone to mistakes if a scene contains repetitive structures, e.g., desks, tables, boxes, or moving people. We show that the movable objects incorporate non-negligible localization error and present a new straightforward method to predict the six-degree-of-freedom (6DoF) pose more robustly. We equipped the localization pipeline InLoc with real-time instance segmentation network YOLACT++. The masks of dynamic objects are employed in the relative pose estimation step and in the final sorting of camera pose proposal. At first, we filter out the matches laying on masks of the dynamic objects. Second, we skip the comparison of query and synthetic images on the area related to the moving object. This procedure leads to a more robust localization. Lastly, we describe and improve the mistakes caused by gradient-based comparison between synthetic and query images and publish a new pipeline for simulation of environments with movable objects from the Matterport scans. All the codes are available on github.com/dubenma/D-InLocpp .
Sparse Representation Learning with Modified q-VAE towards Minimal Realization of World Model
Aug 08, 2022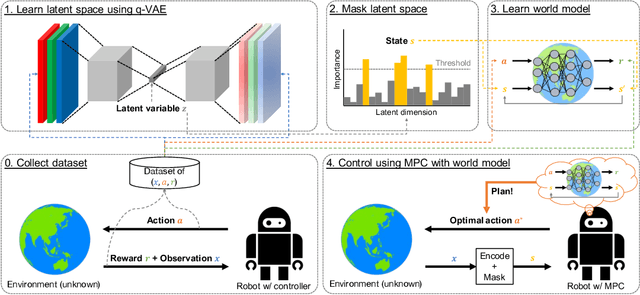
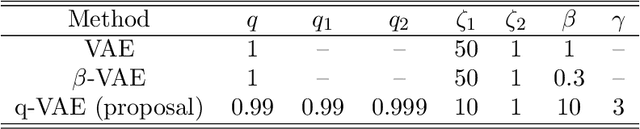
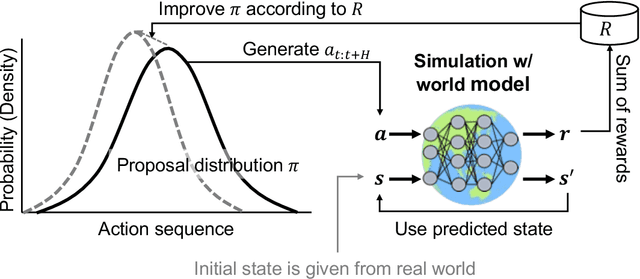

Extraction of low-dimensional latent space from high-dimensional observation data is essential to construct a real-time robot controller with a world model on the extracted latent space. However, there is no established method for tuning the dimension size of the latent space automatically, suffering from finding the necessary and sufficient dimension size, i.e. the minimal realization of the world model. In this study, we analyze and improve Tsallis-based variational autoencoder (q-VAE), and reveal that, under an appropriate configuration, it always facilitates making the latent space sparse. Even if the dimension size of the pre-specified latent space is redundant compared to the minimal realization, this sparsification collapses unnecessary dimensions, allowing for easy removal of them. We experimentally verified the benefits of the sparsification by the proposed method that it can easily find the necessary and sufficient six dimensions for a reaching task with a mobile manipulator that requires a six-dimensional state space. Moreover, by planning with such a minimal-realization world model learned in the extracted dimensions, the proposed method was able to exert a more optimal action sequence in real-time, reducing the reaching accomplishment time by around 20 %. The attached video is uploaded on youtube: https://youtu.be/-QjITrnxaRs
RNGDet++: Road Network Graph Detection by Transformer with Instance Segmentation and Multi-scale Features Enhancement
Sep 21, 2022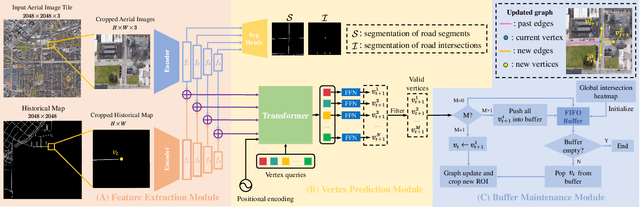
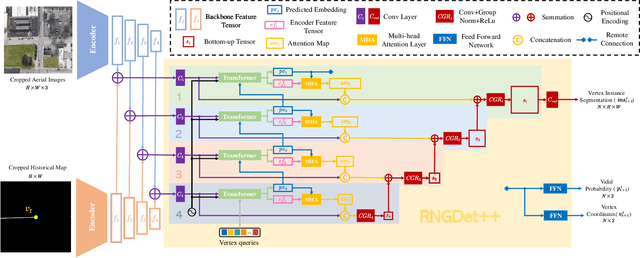
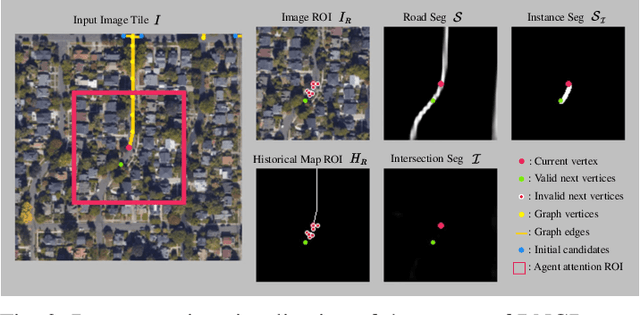
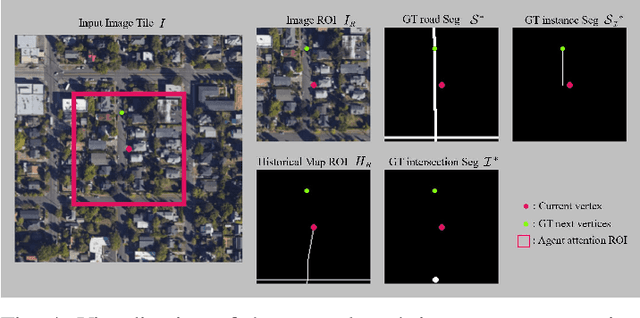
The graph structure of road networks is critical for downstream tasks of autonomous driving systems, such as global planning, motion prediction and control. In the past, the road network graph is usually manually annotated by human experts, which is time-consuming and labor-intensive. To obtain the road network graph with better effectiveness and efficiency, automatic approaches for road network graph detection are required. Previous works either post-process semantic segmentation maps or propose graph-based algorithms to directly predict the road network graph. However, previous works suffer from hard-coded heuristic processing algorithms and inferior final performance. To enhance the previous SOTA (State-of-the-Art) approach RNGDet, we add an instance segmentation head to better supervise the model training, and enable the model to leverage multi-scale features of the backbone network. Since the new proposed approach is improved from RNGDet, it is named RNGDet++. All approaches are evaluated on a large publicly available dataset. RNGDet++ outperforms baseline models on almost all metrics scores. It improves the topology correctness APLS (Average Path Length Similarity) by around 3\%. The demo video and supplementary materials are available on our project page \url{https://tonyxuqaq.github.io/projects/RNGDetPlusPlus/}.
Uconv-Conformer: High Reduction of Input Sequence Length for End-to-End Speech Recognition
Aug 16, 2022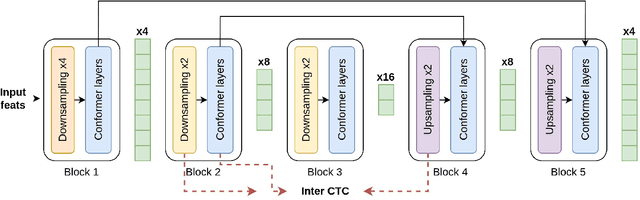
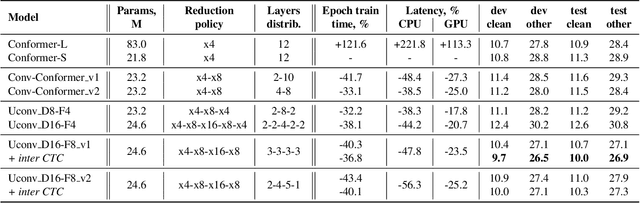
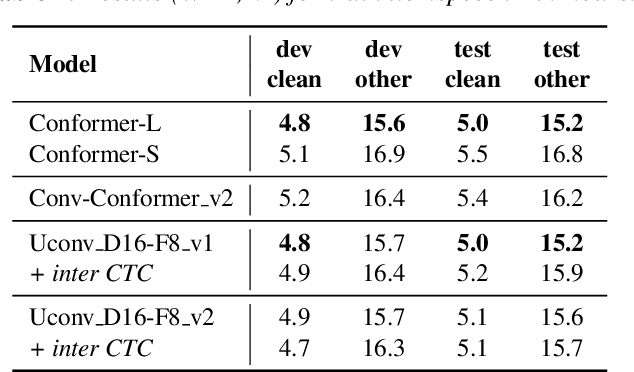
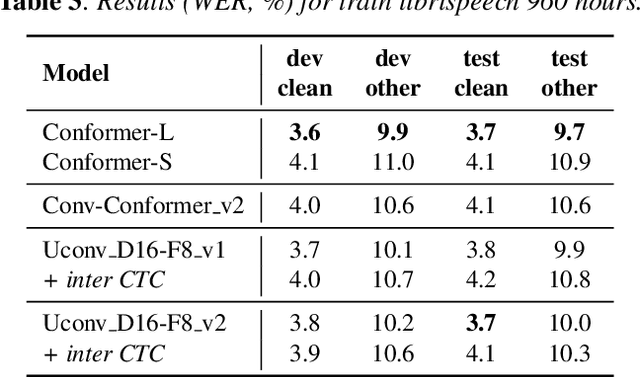
Optimization of modern ASR architectures is among the highest priority tasks since it saves many computational resources for model training and inference. The work proposes a new Uconv-Conformer architecture based on the standard Conformer model that consistently reduces the input sequence length by 16 times, which results in speeding up the work of the intermediate layers. To solve the convergence problem with such a significant reduction of the time dimension, we use upsampling blocks similar to the U-Net architecture to ensure the correct CTC loss calculation and stabilize network training. The Uconv-Conformer architecture appears to be not only faster in terms of training and inference but also shows better WER compared to the baseline Conformer. Our best Uconv-Conformer model showed 40.3% epoch training time reduction, 47.8%, and 23.5% inference acceleration on the CPU and GPU, respectively. Relative WER on Librispeech test_clean and test_other decreased by 7.3% and 9.2%.
A Non-parametric Skill Representation with Soft Null Space Projectors for Fast Generalization
Sep 18, 2022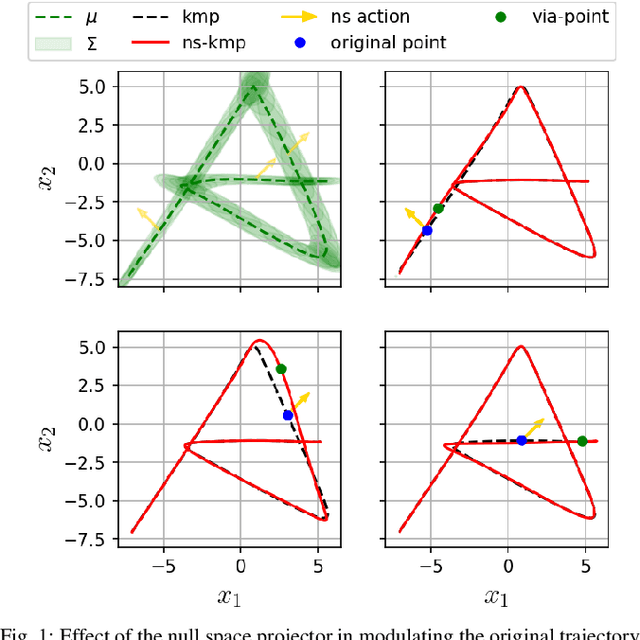
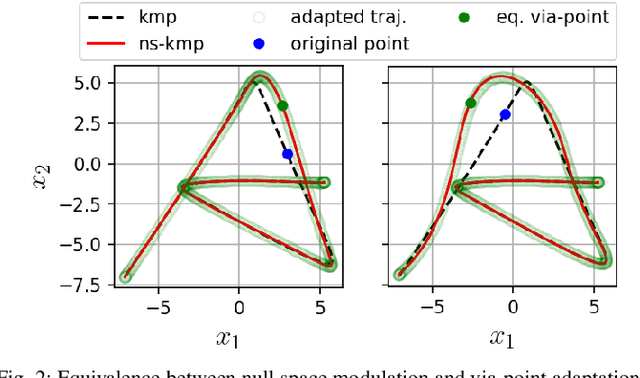
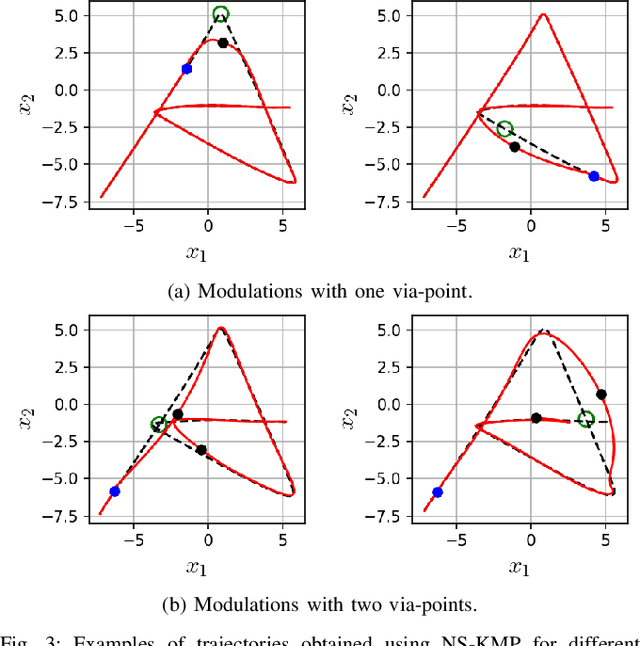
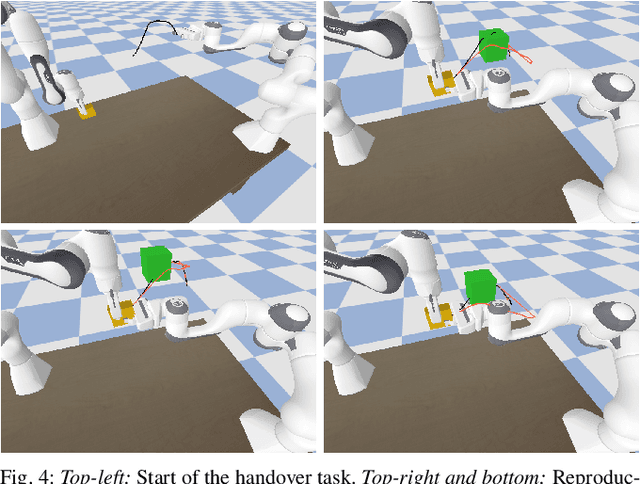
Over the last two decades, the robotics community witnessed the emergence of various motion representations that have been used extensively, particularly in behavorial cloning, to compactly encode and generalize skills. Among these, probabilistic approaches have earned a relevant place, owing to their encoding of variations, correlations and adaptability to new task conditions. Modulating such primitives, however, is often cumbersome due to the need for parameter re-optimization which frequently entails computationally costly operations. In this paper we derive a non-parametric movement primitive formulation that contains a null space projector. We show that such formulation allows for fast and efficient motion generation with computational complexity O(n2) without involving matrix inversions, whose complexity is O(n3). This is achieved by using the null space to track secondary targets, with a precision determined by the training dataset. Using a 2D example associated with time input we show that our non-parametric solution compares favourably with a state-of-the-art parametric approach. For demonstrated skills with high-dimensional inputs we show that it permits on-the-fly adaptation as well.
Experimental validation of machine-learning based spectral-spatial power evolution shaping using Raman amplifiers
Sep 26, 2022

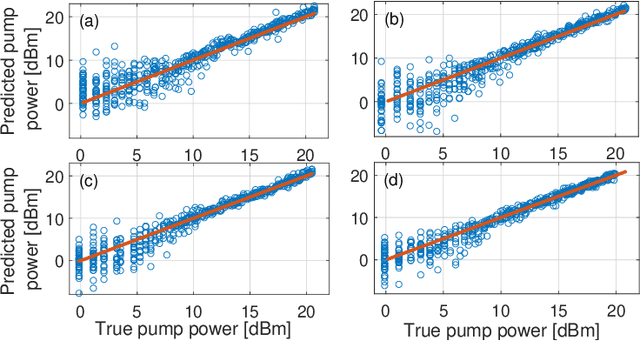

We experimentally validate a real-time machine learning framework, capable of controlling the pump power values of Raman amplifiers to shape the signal power evolution in two-dimensions (2D): frequency and fiber distance. In our setup, power values of four first-order counter-propagating pumps are optimized to achieve the desired 2D power profile. The pump power optimization framework includes a convolutional neural network (CNN) followed by differential evolution (DE) technique, applied online to the amplifier setup to automatically achieve the target 2D power profiles. The results on achievable 2D profiles show that the framework is able to guarantee very low maximum absolute error (MAE) (<0.5 dB) between the obtained and the target 2D profiles. Moreover, the framework is tested in a multi-objective design scenario where the goal is to achieve the 2D profiles with flat gain levels at the end of the span, jointly with minimum spectral excursion over the entire fiber length. In this case, the experimental results assert that for 2D profiles with the target flat gain levels, the DE obtains less than 1 dB maximum gain deviation, when the setup is not physically limited in the pump power values. The simulation results also prove that with enough pump power available, better gain deviation (less than 0.6 dB) for higher target gain levels is achievable.
The Role of Symmetry in Constructing Geometric Flat Outputs for Free-Flying Robotic Systems
Sep 23, 2022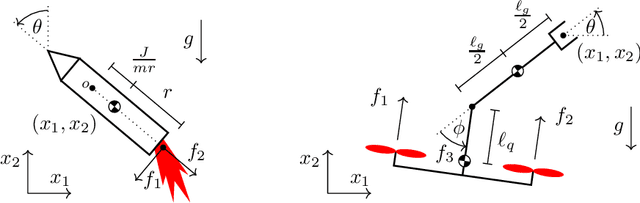
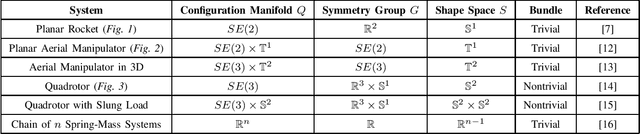
Mechanical systems naturally evolve on principal bundles describing their inherent symmetries. The ensuing factorization of the configuration manifold into a symmetry group and an internal shape space has provided deep insights into the locomotion of many robotic and biological systems. On the other hand, the property of differential flatness has enabled efficient, effective planning and control algorithms for various robotic systems. Yet, a practical means of finding a flat output for an arbitrary robotic system remains an open question. In this work, we demonstrate surprising new connections between these two domains, for the first time employing symmetry directly to construct a flat output. We provide sufficient conditions for the existence of a trivialization of the bundle in which the group variables themselves are a flat output. We call this a geometric flat output, since it is equivariant (i.e. maintains the symmetry) and is often global or almost-global, properties not typically enjoyed by other flat outputs. In such a trivialization, the motion planning problem is easily solved, since a given trajectory for the group variables will fully determine the trajectory for the shape variables that exactly achieves this motion. We provide a partial catalog of robotic systems with geometric flat outputs and worked examples for the planar rocket, planar aerial manipulator, and quadrotor.
CSSAM: U-net Network for Application and Segmentation of Welding Engineering Drawings
Sep 28, 2022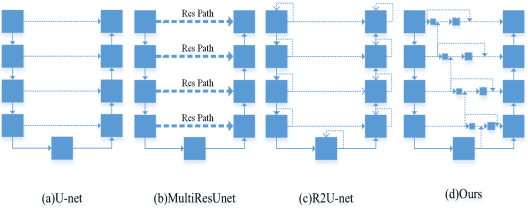
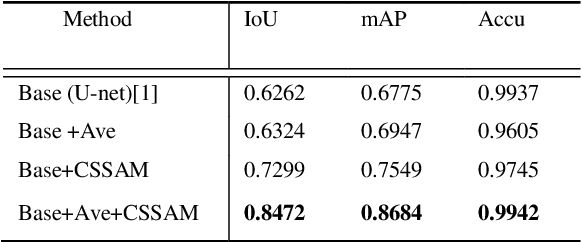
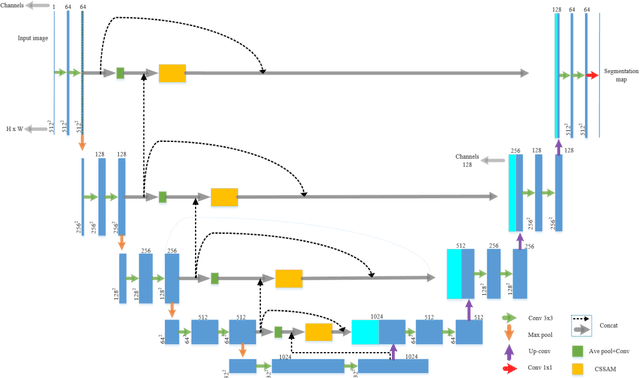

Heavy equipment manufacturing splits specific contours in drawings and cuts sheet metal to scale for welding. Currently, most of the segmentation and extraction of weld map contours is achieved manually. Its efficiency is greatly reduced. Therefore, we propose a U-net-based contour segmentation and extraction method for welding engineering drawings. The contours of the parts required for engineering drawings can be automatically divided and blanked, which significantly improves manufacturing efficiency. U-net includes an encoder-decoder, which implements end-to-end mapping through semantic differences and spatial location feature information between the encoder and decoder. While U-net excels at segmenting medical images, our extensive experiments on the Welding Structural Diagram dataset show that the classic U-Net architecture falls short in segmenting welding engineering drawings. Therefore, we design a novel Channel Spatial Sequence Attention Module (CSSAM) and improve on the classic U-net. At the same time, vertical max pooling and average horizontal pooling are proposed. Pass the pooling operation through two equal convolutions into the CSSAM module. The output and the features before pooling are fused by semantic clustering, which replaces the traditional jump structure and effectively narrows the semantic gap between the encoder and the decoder, thereby improving the segmentation performance of welding engineering drawings. We use vgg16 as the backbone network. Compared with the classic U-net, our network has good performance in engineering drawing dataset segmentation.