 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Over-the-air Adversarial Perturbations for Digital Communications using Deep Neural Networks
Feb 20, 2022
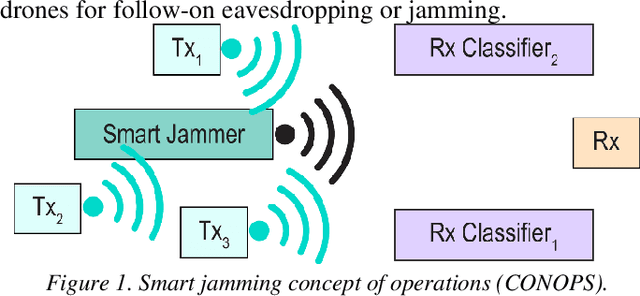
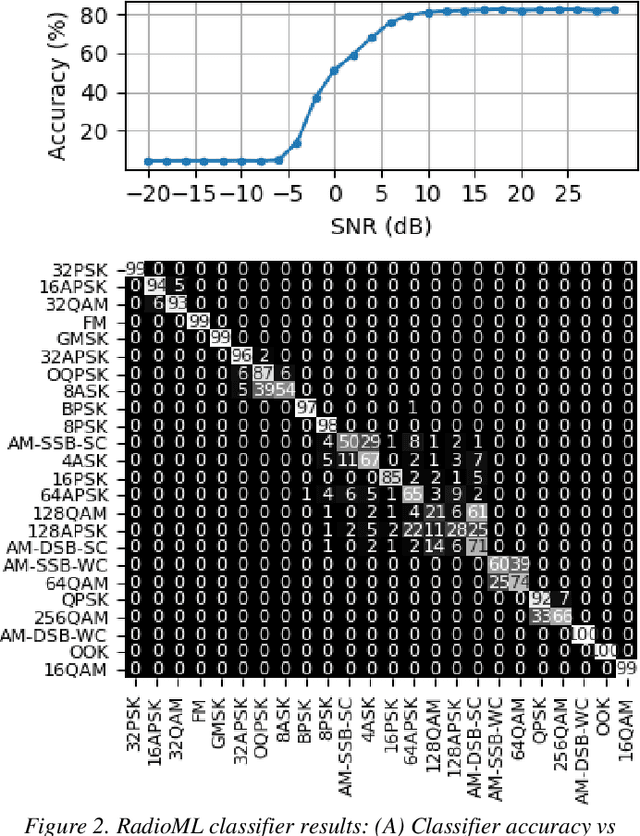
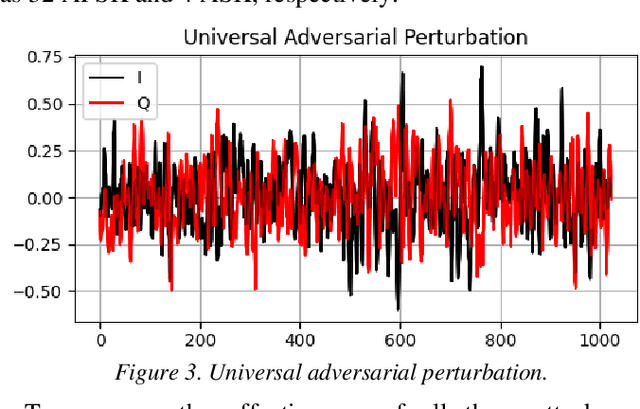
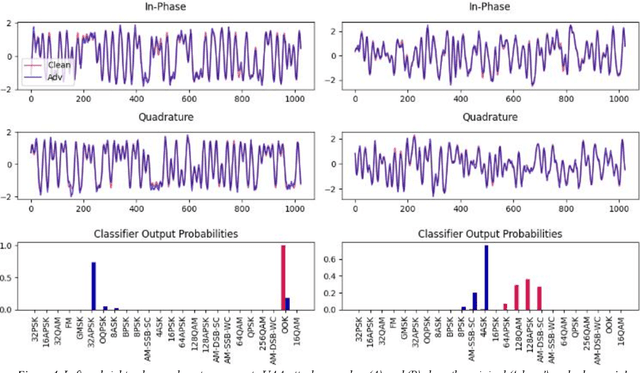
Deep neural networks (DNNs) are increasingly being used in a variety of traditional radiofrequency (RF) problems. Previous work has shown that while DNN classifiers are typically more accurate than traditional signal processing algorithms, they are vulnerable to intentionally crafted adversarial perturbations which can deceive the DNN classifiers and significantly reduce their accuracy. Such intentional adversarial perturbations can be used by RF communications systems to avoid reactive-jammers and interception systems which rely on DNN classifiers to identify their target modulation scheme. While previous research on RF adversarial perturbations has established the theoretical feasibility of such attacks using simulation studies, critical questions concerning real-world implementation and viability remain unanswered. This work attempts to bridge this gap by defining class-specific and sample-independent adversarial perturbations which are shown to be effective yet computationally feasible in real-time and time-invariant. We demonstrate the effectiveness of these attacks over-the-air across a physical channel using software-defined radios (SDRs). Finally, we demonstrate that these adversarial perturbations can be emitted from a source other than the communications device, making these attacks practical for devices that cannot manipulate their transmitted signals at the physical layer.
Efficient first-order predictor-corrector multiple objective optimization for fair misinformation detection
Sep 15, 2022
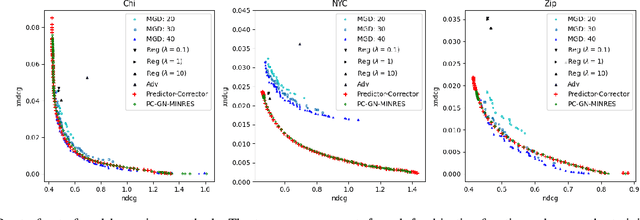
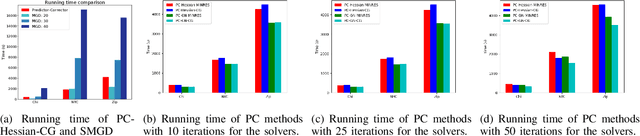
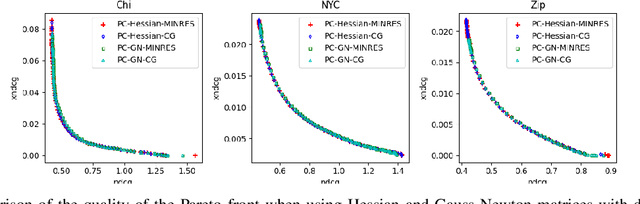
Multiple-objective optimization (MOO) aims to simultaneously optimize multiple conflicting objectives and has found important applications in machine learning, such as minimizing classification loss and discrepancy in treating different populations for fairness. At optimality, further optimizing one objective will necessarily harm at least another objective, and decision-makers need to comprehensively explore multiple optima (called Pareto front) to pinpoint one final solution. We address the efficiency of finding the Pareto front. First, finding the front from scratch using stochastic multi-gradient descent (SMGD) is expensive with large neural networks and datasets. We propose to explore the Pareto front as a manifold from a few initial optima, based on a predictor-corrector method. Second, for each exploration step, the predictor solves a large-scale linear system that scales quadratically in the number of model parameters and requires one backpropagation to evaluate a second-order Hessian-vector product per iteration of the solver. We propose a Gauss-Newton approximation that only scales linearly, and that requires only first-order inner-product per iteration. This also allows for a choice between the MINRES and conjugate gradient methods when approximately solving the linear system. The innovations make predictor-corrector possible for large networks. Experiments on multi-objective (fairness and accuracy) misinformation detection tasks show that 1) the predictor-corrector method can find Pareto fronts better than or similar to SMGD with less time; and 2) the proposed first-order method does not harm the quality of the Pareto front identified by the second-order method, while further reduce running time.
A Trio-Method for Retinal Vessel Segmentation using Image Processing
Sep 19, 2022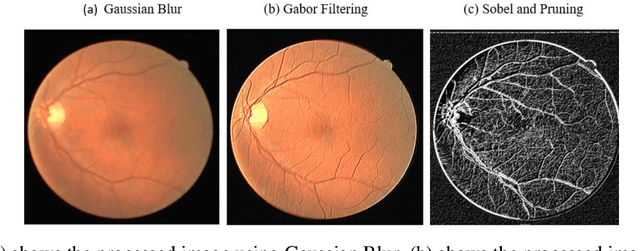

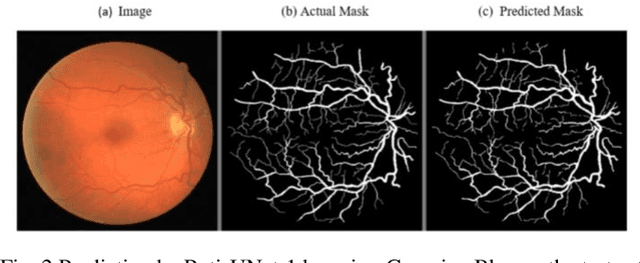

Inner Retinal neurons are a most essential part of the retina and they are supplied with blood via retinal vessels. This paper primarily focuses on the segmentation of retinal vessels using a triple preprocessing approach. DRIVE database was taken into consideration and preprocessed by Gabor Filtering, Gaussian Blur, and Edge Detection by Sobel and Pruning. Segmentation was driven out by 2 proposed U-Net architectures. Both the architectures were compared in terms of all the standard performance metrics. Preprocessing generated varied interesting results which impacted the results shown by the UNet architectures for segmentation. This real-time deployment can help in the efficient pre-processing of images with better segmentation and detection.
Over-the-Air Split Machine Learning in Wireless MIMO Networks
Oct 07, 2022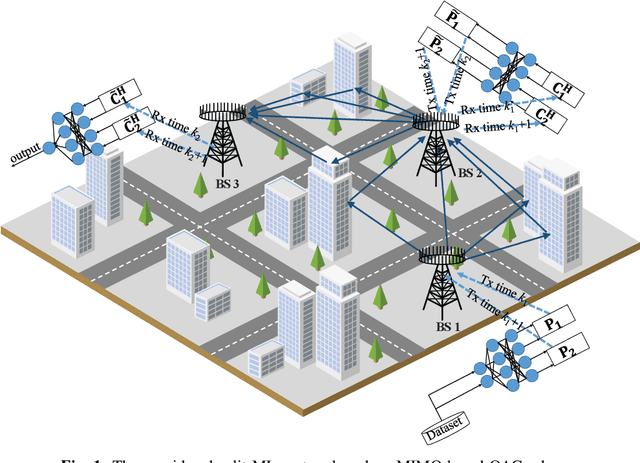
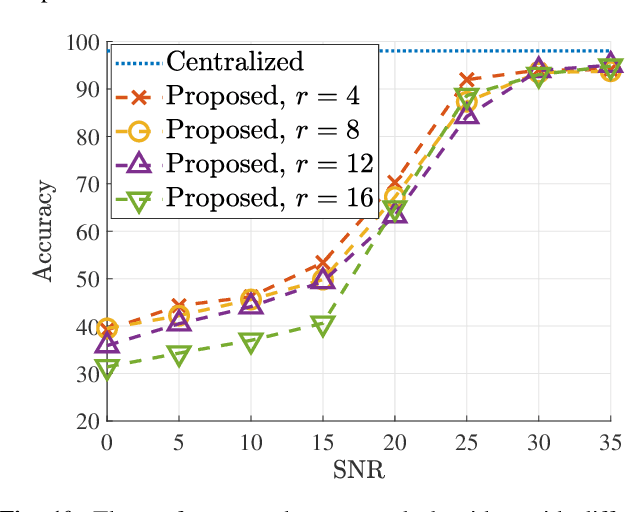
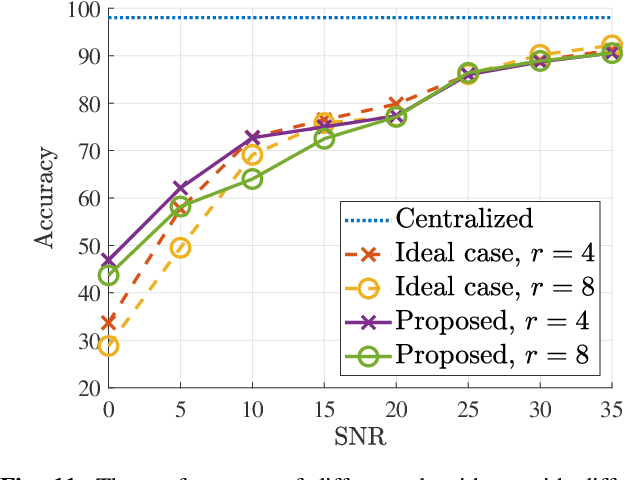
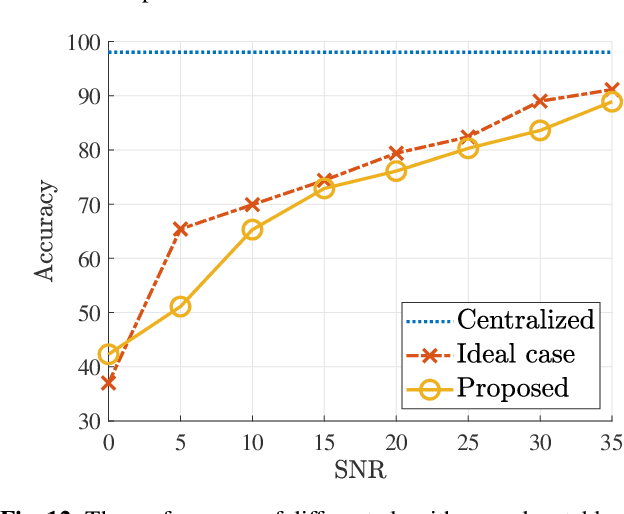
In split machine learning (ML), different partitions of a neural network (NN) are executed by different computing nodes, requiring a large amount of communication cost. To ease communication burden, over-the-air computation (OAC) can efficiently implement all or part of the computation at the same time of communication. Based on the proposed system, the system implementation over wireless network is introduced and we provide the problem formulation. In particular, we show that the inter-layer connection in a NN of any size can be mathematically decomposed into a set of linear precoding and combining transformations over MIMO channels. Therefore, the precoding matrix at the transmitter and the combining matrix at the receiver of each MIMO link, as well as the channel matrix itself, can jointly serve as a fully connected layer of the NN. The generalization of the proposed scheme to the conventional NNs is also introduced. Finally, we extend the proposed scheme to the widely used convolutional neural networks and demonstrate its effectiveness under both the static and quasi-static memory channel conditions with comprehensive simulations. In such a split ML system, the precoding and combining matrices are regarded as trainable parameters, while MIMO channel matrix is regarded as unknown (implicit) parameters.
Temporal Feature Alignment in Contrastive Self-Supervised Learning for Human Activity Recognition
Oct 07, 2022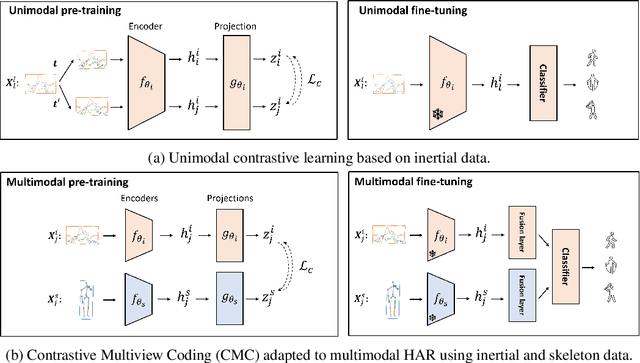
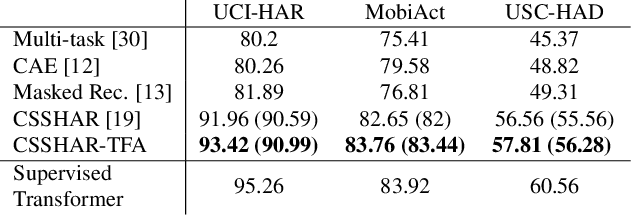
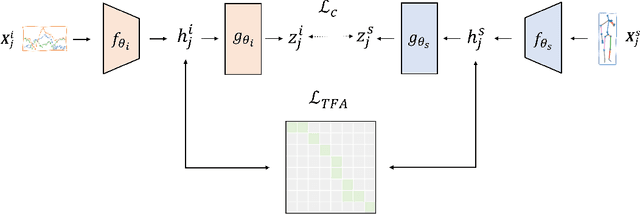
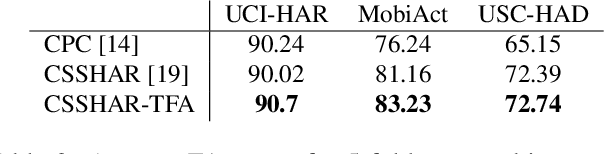
Automated Human Activity Recognition has long been a problem of great interest in human-centered and ubiquitous computing. In the last years, a plethora of supervised learning algorithms based on deep neural networks has been suggested to address this problem using various modalities. While every modality has its own limitations, there is one common challenge. Namely, supervised learning requires vast amounts of annotated data which is practically hard to collect. In this paper, we benefit from the self-supervised learning paradigm (SSL) that is typically used to learn deep feature representations from unlabeled data. Moreover, we upgrade a contrastive SSL framework, namely SimCLR, widely used in various applications by introducing a temporal feature alignment procedure for Human Activity Recognition. Specifically, we propose integrating a dynamic time warping (DTW) algorithm in a latent space to force features to be aligned in a temporal dimension. Extensive experiments have been conducted for the unimodal scenario with inertial modality as well as in multimodal settings using inertial and skeleton data. According to the obtained results, the proposed approach has a great potential in learning robust feature representations compared to the recent SSL baselines, and clearly outperforms supervised models in semi-supervised learning. The code for the unimodal case is available via the following link: https://github.com/bulatkh/csshar_tfa.
Embedding Representation of Academic Heterogeneous Information Networks Based on Federated Learning
Oct 07, 2022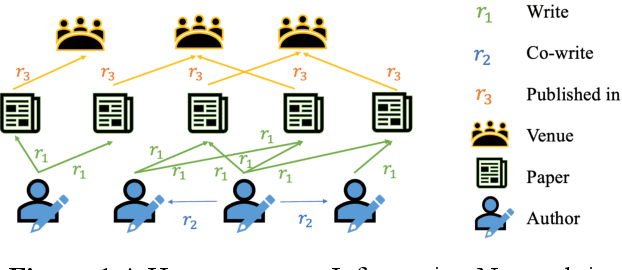
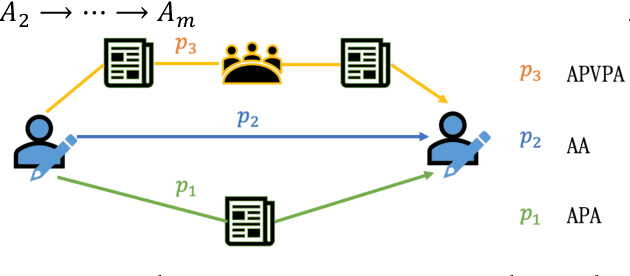
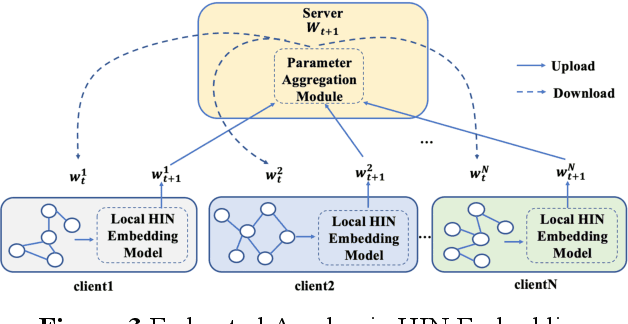
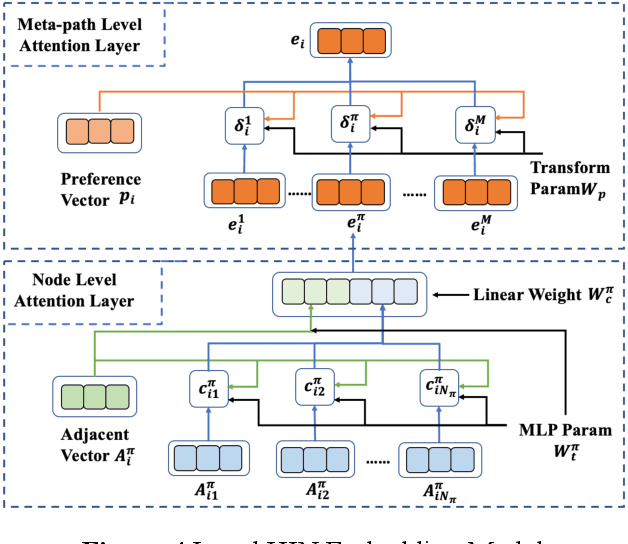
Academic networks in the real world can usually be portrayed as heterogeneous information networks (HINs) with multi-type, universally connected nodes and multi-relationships. Some existing studies for the representation learning of homogeneous information networks cannot be applicable to heterogeneous information networks because of the lack of ability to issue heterogeneity. At the same time, data has become a factor of production, playing an increasingly important role. Due to the closeness and blocking of businesses among different enterprises, there is a serious phenomenon of data islands. To solve the above challenges, aiming at the data information of scientific research teams closely related to science and technology, we proposed an academic heterogeneous information network embedding representation learning method based on federated learning (FedAHE), which utilizes node attention and meta path attention mechanism to learn low-dimensional, dense and real-valued vector representations while preserving the rich topological information and meta-path-based semantic information of nodes in network. Moreover, we combined federated learning with the representation learning of HINs composed of scientific research teams and put forward a federal training mechanism based on dynamic weighted aggregation of parameters (FedDWA) to optimize the node embeddings of HINs. Through sufficient experiments, the efficiency, accuracy and feasibility of our proposed framework are demonstrated.
Utilizing Explainable AI for improving the Performance of Neural Networks
Oct 07, 2022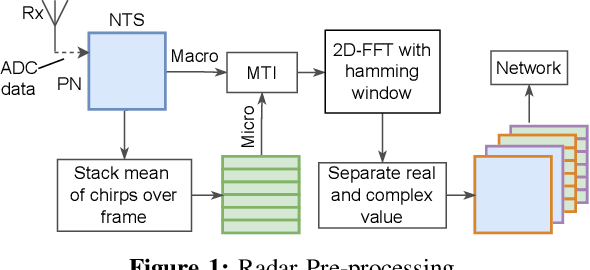
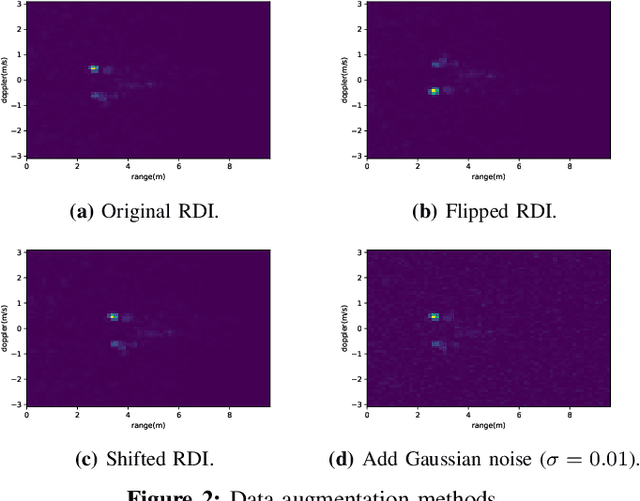
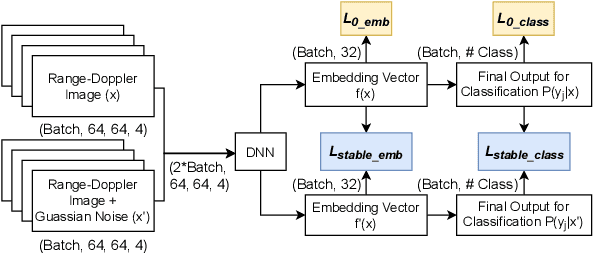

Nowadays, deep neural networks are widely used in a variety of fields that have a direct impact on society. Although those models typically show outstanding performance, they have been used for a long time as black boxes. To address this, Explainable Artificial Intelligence (XAI) has been developing as a field that aims to improve the transparency of the model and increase their trustworthiness. We propose a retraining pipeline that consistently improves the model predictions starting from XAI and utilizing state-of-the-art techniques. To do that, we use the XAI results, namely SHapley Additive exPlanations (SHAP) values, to give specific training weights to the data samples. This leads to an improved training of the model and, consequently, better performance. In order to benchmark our method, we evaluate it on both real-life and public datasets. First, we perform the method on a radar-based people counting scenario. Afterward, we test it on the CIFAR-10, a public Computer Vision dataset. Experiments using the SHAP-based retraining approach achieve a 4% more accuracy w.r.t. the standard equal weight retraining for people counting tasks. Moreover, on the CIFAR-10, our SHAP-based weighting strategy ends up with a 3% accuracy rate than the training procedure with equal weighted samples.
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
Oct 07, 2022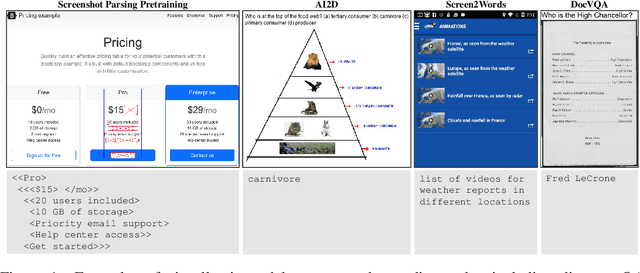


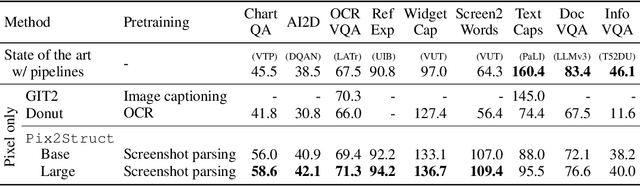
Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
Zero-Shot Retargeting of Learned Quadruped Locomotion Policies Using Hybrid Kinodynamic Model Predictive Control
Sep 28, 2022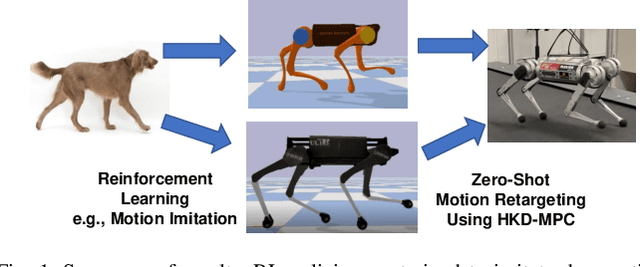
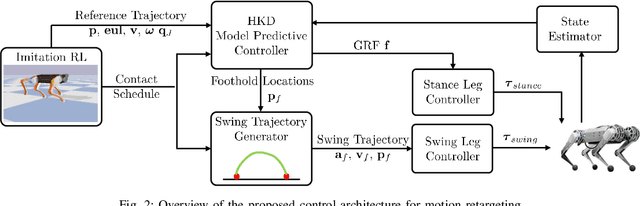


Reinforcement Learning (RL) has witnessed great strides for quadruped locomotion, with continued progress in the reliable sim-to-real transfer of policies. However, it remains a challenge to reuse a policy on another robot, which could save time for retraining. In this work, we present a framework for zero-shot policy retargeting wherein diverse motor skills can be transferred between robots of different shapes and sizes. The new framework centers on a planning-and-control pipeline that systematically integrates RL and Model Predictive Control (MPC). The planning stage employs RL to generate a dynamically plausible trajectory as well as the contact schedule, avoiding the combinatorial complexity of contact sequence optimization. This information is then used to seed the MPC to stabilize and robustify the policy roll-out via a new Hybrid Kinodynamic (HKD) model that implicitly optimizes the foothold locations. Hardware results show an ability to transfer policies from both the A1 and Laikago robots to the MIT Mini Cheetah robot without requiring any policy re-tuning.
Warped Dynamic Linear Models for Time Series of Counts
Oct 27, 2021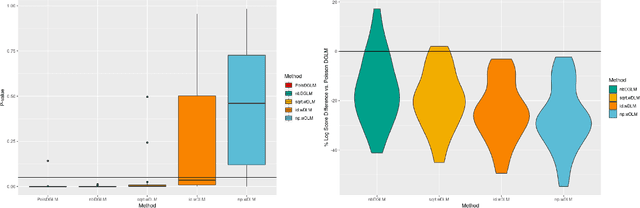
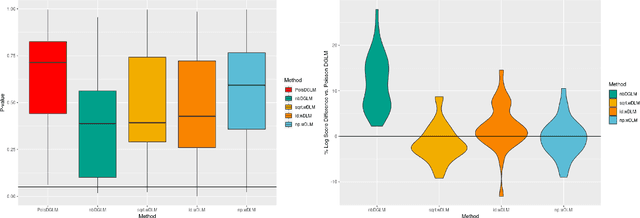
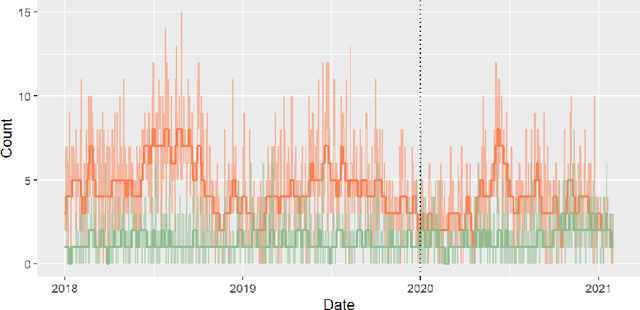
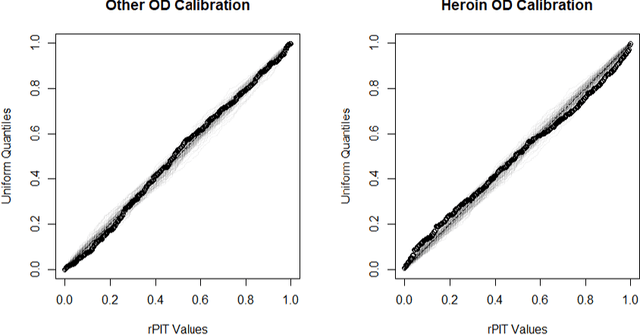
Dynamic Linear Models (DLMs) are commonly employed for time series analysis due to their versatile structure, simple recursive updating, and probabilistic forecasting. However, the options for count time series are limited: Gaussian DLMs require continuous data, while Poisson-based alternatives often lack sufficient modeling flexibility. We introduce a novel methodology for count time series by warping a Gaussian DLM. The warping function has two components: a transformation operator that provides distributional flexibility and a rounding operator that ensures the correct support for the discrete data-generating process. Importantly, we develop conjugate inference for the warped DLM, which enables analytic and recursive updates for the state space filtering and smoothing distributions. We leverage these results to produce customized and efficient computing strategies for inference and forecasting, including Monte Carlo simulation for offline analysis and an optimal particle filter for online inference. This framework unifies and extends a variety of discrete time series models and is valid for natural counts, rounded values, and multivariate observations. Simulation studies illustrate the excellent forecasting capabilities of the warped DLM. The proposed approach is applied to a multivariate time series of daily overdose counts and demonstrates both modeling and computational successes.