 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Domain Coupler: A Wireless Native Neural Backbone for Channel Representation and Deduction
Jun 20, 2026Data representation is a fundamental issue in deep learning. However, as wireless data scales and deeply couples across many physical domains such as time, space, and frequency, existing wireless artificial intelligence (AI) technologies lack dedicated representation solutions. Instead, they mainly rely on stitching general-purpose networks, a tool-driven paradigm that inevitably results in structural redundancy and bottlenecks in information flow. To fill this gap, this paper proposes Coupler, a wireless native-AI neural backbone designed for representation learning of channel state information (CSI)--the pivotal data in wireless systems. Leveraging the revealed physical insights of channel tensors, Coupler decomposes representation learning into individual domains on a layer-by-layer basis, and then couples the learned domain-specific features through a dimension-staggered cascade. This full-domain interleaved learning architecture enables superior parameter efficiency and fine-grained multi-domain feature fusion. Based on this backbone, we use the complex-domain multilayer perceptrons (CMLPs) as spatial and frequency domain learners, while employing three optional mechanisms--convolution, attention, or gating--to capture temporal dependencies. This results in a series of efficient channel learning schemes with diverse functionalities and extreme lightweights, showcasing the compactness, versatility and flexibility of Coupler. We evaluate these schemes on channel deduction, a general representation task encompassing channel estimation, interpolation, prediction, and feedback. Extensive experimental evaluations validate their significant performance gains and robust applicability even for real-world measured data, demonstrating the potential of Coupler as a promising basic architecture in the design of wireless foundation models.
LLM-Based Digital Twin Intelligence for Application-Aware Network Selection in 6G Heterogeneous Wireless Networks
Jun 10, 2026Future 6G heterogeneous wireless networks (HWNs) are expected to support multiple radio access technologies (RATs), dynamic wireless environments, and applications with diverse quality-of-service (QoS) requirements. In such environments, network selection (NS) cannot rely only on instantaneous radio measurements or static ranking rules. Instead, access decisions must account for the evolving wireless state, service intent, packet-level QoS behavior, and candidate-RAT dynamics. This paper proposes a large language model (LLM)-based digital twin (DT) framework for stable, application-aware RAT selection under candidate-set evolution. The main idea is to shift NS from an instantaneous decision-matrix operation to a decision process over an evolving wireless DT state. The constructed DT combines site-specific geometry, Sionna RT-based propagation descriptors, ns-3 packet-level QoS emulation, service context, candidate-RAT information, and decision memory. Rather than acting as a general-purpose controller for 6G networks, the LLM is used for DT-grounded decision intelligence in this specific NS task. On top of this DT, a unified intent agent translates user and service requirements into structured decision priorities for two complementary NS branches: an LLM-assisted multi-attribute decision-making branch (MADM--LLM--NS) and a direct LLM-based ranking branch (LLM--NS). To improve decision stability, the framework further introduces history-aware adaptive normalization (HAAN) and DT-memory-driven retrieval-augmented in-context learning (RA--ICL). Numerical results show that the proposed framework reduces rank-reversal problem and unnecessary handover events, while improving service-aware QoS satisfaction compared with representative MADM-based NS baselines.
Diffusion Inpainting MIMO-OFDM Channels with Limited Noisy Observations
Apr 10, 2026Acquiring the channel state information from limited and noisy observations at pilot positions is critical for wireless multiple-input multiple-output (MIMO)-orthogonal frequency division multiplexing (OFDM) systems. In this paper, we view this process as a conditional generative task in which the partial noisy channel estimates at the pilots are utilized as a ``prompt'' to guide the diffusion ``inpainting'' of the underlying channel. To this end, we resort to a general Conditional Diffusion Transformer (CDiT) framework with a well-designed network architecture and update rule. In particular, we design a dedicated embedding strategy to encode and adapt to different pilot patterns and noise levels, and utilize a special cross-attention mechanism to align the partial raw channel observations with the denoised channel at each time step of the generation process. This architecture effectively anchors the diffusion process, enabling the model to accurately recover full channel details from limited noisy observations. Comprehensive experimental results show that, the proposed approach achieves a performance gain of over 5 dB compared to the baselines under varying noise conditions, and provides robust channel acquisition even under a sparse pilot density of 1/32 without significant performance loss compared to the denser pilot cases. Moreover, it is capable of generating high-quality channel matrices within just 10 inference steps, effectively balancing estimation accuracy with computational efficiency and inference speed. Ablation studies demonstrate the rationality of the model design and the necessity of its modules.
Telecom World Models: Unifying Digital Twins, Foundation Models, and Predictive Planning for 6G
Apr 08, 2026The integration of machine learning tools into telecom networks, has led to two prevailing paradigms, namely, language-based systems, such as Large Language Models (LLMs), and physics-based systems, such as Digital Twins (DTs). While LLM-based approaches enable flexible interaction and automation, they lack explicit representations of network dynamics. DTs, in contrast, offer a high-fidelity network simulation, but remain scenario-specific and are not designed for learning or decision-making under uncertainty. This gap becomes critical for 6G systems, where decisions must take into account the evolving network states, uncertainty, and the cascading effects of control actions across multiple layers. In this article, we introduce the {Telecom World Model}~(TWM) concept, an architecture for learned, action-conditioned, uncertainty-aware modeling of telecom system dynamics. We decompose the problem into two interacting worlds, a controllable system world consisting of operator-configurable settings and an external world that captures propagation, mobility, traffic, and failures. We propose a three-layer architecture, comprising a field world model for spatial environment prediction, a control/dynamics world model for action-conditioned Key Performance Indicator (KPI) trajectory prediction, and a telecom foundation model layer for intent translation and orchestration. We showcase a comparative analysis between existing paradigms, which demonstrates that TWM jointly provides telecom state grounding, fast action-conditioned roll-outs, calibrated uncertainty, multi-timescale dynamics, model-based planning, and LLM-integrated guardrails. Furthermore, we present a proof-of-concept on network slicing to validate the proposed architecture, showing that the full three-layer pipeline outperforms single-world baselines and accurately predicts KPI trajectories.
Two-Layer Reinforcement Learning-Assisted Joint Beamforming and Trajectory Optimization for Multi-UAV Downlink Communications
Jan 19, 2026Unmanned aerial vehicles (UAVs) are pivotal for future 6G non-terrestrial networks, yet their high mobility creates a complex coupled optimization problem for beamforming and trajectory design. Existing numerical methods suffer from prohibitive latency, while standard deep learning often ignores dynamic interference topology, limiting scalability. To address these issues, this paper proposes a hierarchically decoupled framework synergizing graph neural networks (GNNs) with multi-agent reinforcement learning. Specifically, on the short timescale, we develop a topology-aware GNN beamformer by incorporating GraphNorm. By modeling the dynamic UAV-user association as a time-varying heterogeneous graph, this method explicitly extracts interference patterns to achieve sub-millisecond inference. On the long timescale, trajectory planning is modeled as a decentralized partially observable Markov decision process and solved via the multi-agent proximal policy optimization algorithm under the centralized training with decentralized execution paradigm, facilitating cooperative behaviors. Extensive simulation results demonstrate that the proposed framework significantly outperforms state-of-the-art optimization heuristics and deep learning baselines in terms of system sum rate, convergence speed, and generalization capability.
Analogical Learning for Cross-Scenario Generalization: Framework and Application to Intelligent Localization
Apr 09, 2025



Existing learning models often exhibit poor generalization when deployed across diverse scenarios. It is mainly due to that the underlying reference frame of the data varies with the deployment environment and settings. However, despite the data of each scenario has its distinct reference frame, its generation generally follows the same underlying physical rule. Based on these findings, this article proposes a brand-new universal deep learning framework named analogical learning (AL), which provides a highly efficient way to implicitly retrieve the reference frame information associated with a scenario and then to make accurate prediction by relative analogy across scenarios. Specifically, an elegant bipartite neural network architecture called Mateformer is designed, the first part of which calculates the relativity within multiple feature spaces between the input data and a small amount of embedded data from the current scenario, while the second part uses these relativity to guide the nonlinear analogy. We apply AL to the typical multi-scenario learning problem of intelligent wireless localization in cellular networks. Extensive experiments show that AL achieves state-of-the-art accuracy, stable transferability and robust adaptation to new scenarios without any tuning, and outperforming conventional methods with a precision improvement of nearly two orders of magnitude. All data and code are available at https://github.com/ziruichen-research/ALLoc.
Over-the-Air Split Learning with MIMO-Based Neural Network and Constellation-Based Activation
Oct 08, 2022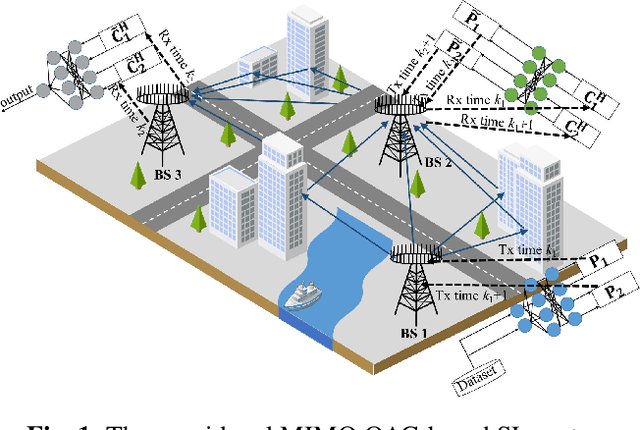
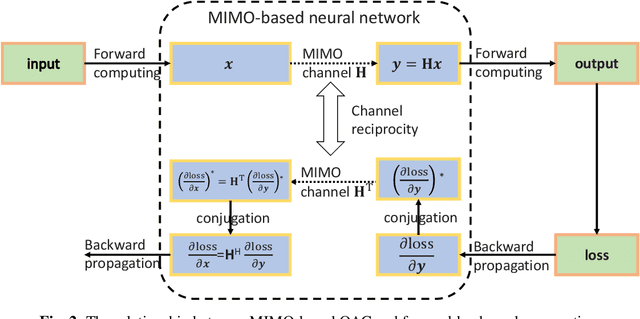
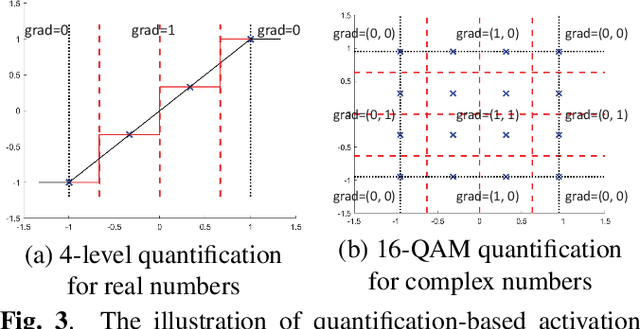
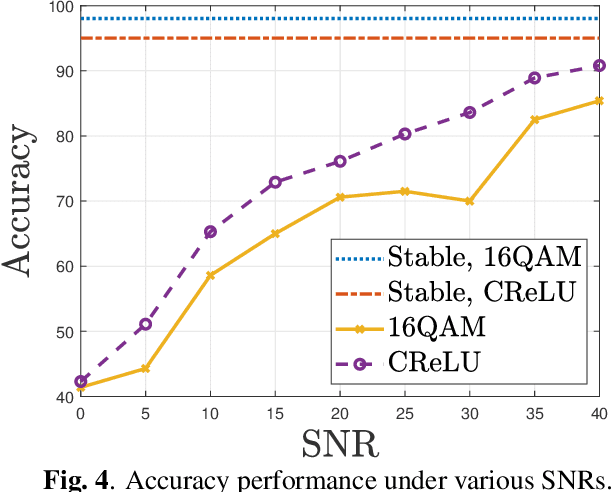
This paper investigates a communication-efficient split learning (SL) over multiple-input multiple-output (MIMO) communication system. In particular, we mathematically decompose the inter-layer connection of a neural network (NN) to a series of linear precoding and combining transformations using over-the-air computation (OAC), which synergistically form a linear layer in NNs. The precoding and combining matrices are trainable parameters in such a system, whereas the MIMO channel is implicit. The proposed system eliminates the implicit channel estimation through exploiting the channel reciprocity and properly casting the backpropagation process, significantly saving the system costs and further improving the overall efficiency. The practical constellation diagrams are used as the activation function to avoid sending arbitrary analog signals as in the traditional OAC system. Numerical results are illustrated to demonstrate the effectiveness of the proposed scheme.
Over-the-Air Split Machine Learning in Wireless MIMO Networks
Oct 07, 2022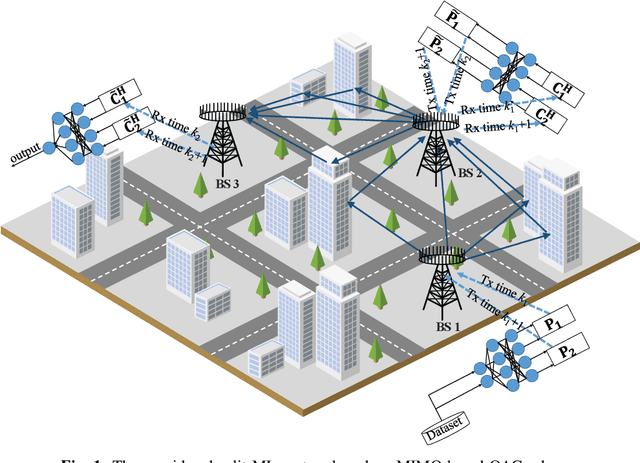
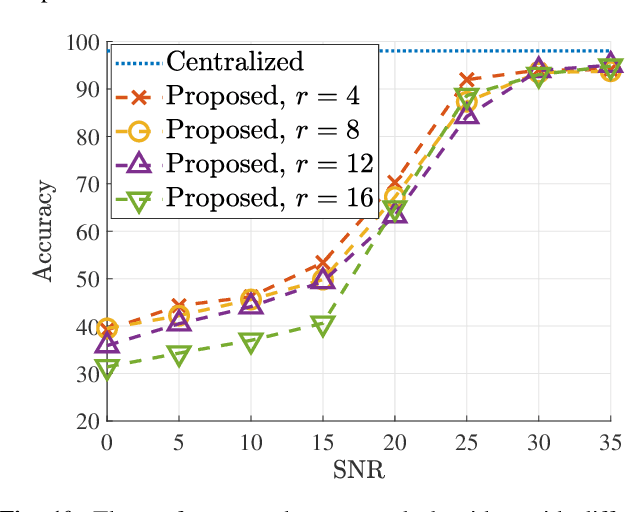
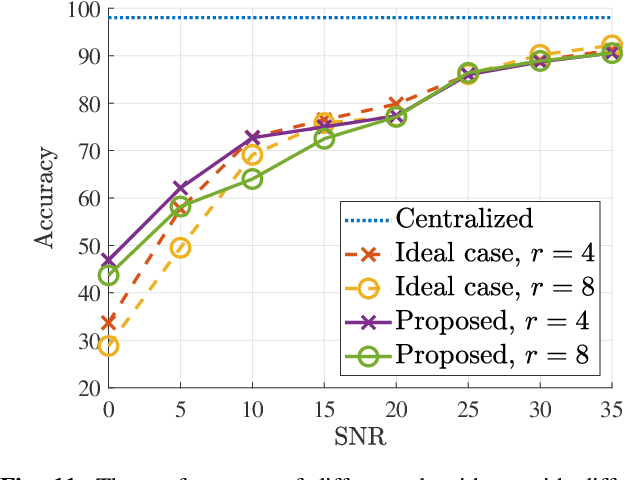
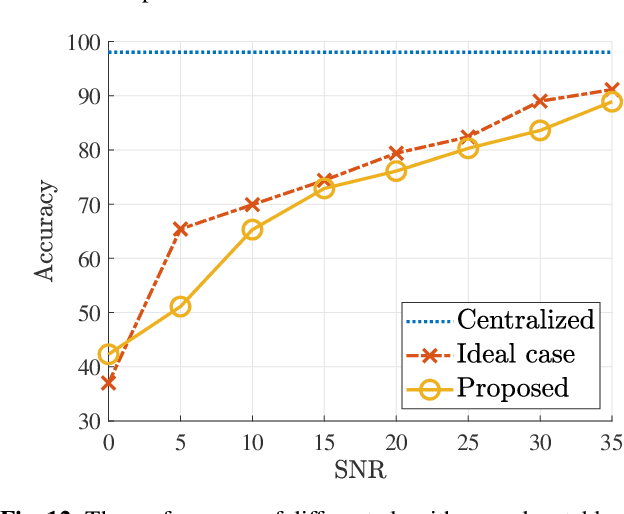
In split machine learning (ML), different partitions of a neural network (NN) are executed by different computing nodes, requiring a large amount of communication cost. To ease communication burden, over-the-air computation (OAC) can efficiently implement all or part of the computation at the same time of communication. Based on the proposed system, the system implementation over wireless network is introduced and we provide the problem formulation. In particular, we show that the inter-layer connection in a NN of any size can be mathematically decomposed into a set of linear precoding and combining transformations over MIMO channels. Therefore, the precoding matrix at the transmitter and the combining matrix at the receiver of each MIMO link, as well as the channel matrix itself, can jointly serve as a fully connected layer of the NN. The generalization of the proposed scheme to the conventional NNs is also introduced. Finally, we extend the proposed scheme to the widely used convolutional neural networks and demonstrate its effectiveness under both the static and quasi-static memory channel conditions with comprehensive simulations. In such a split ML system, the precoding and combining matrices are regarded as trainable parameters, while MIMO channel matrix is regarded as unknown (implicit) parameters.
Communication-Efficient Federated Learning with Binary Neural Networks
Oct 05, 2021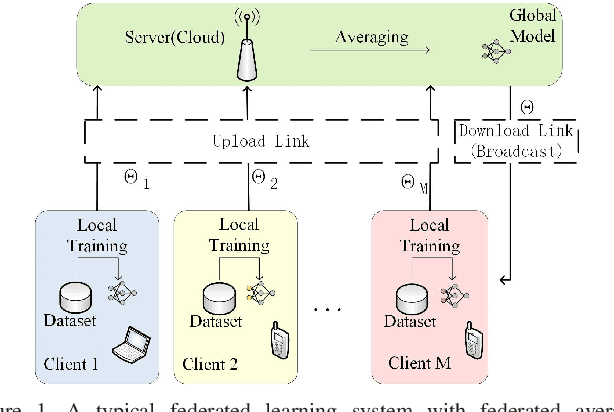
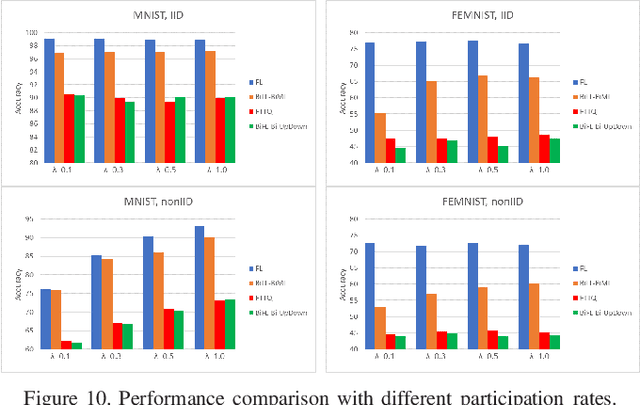
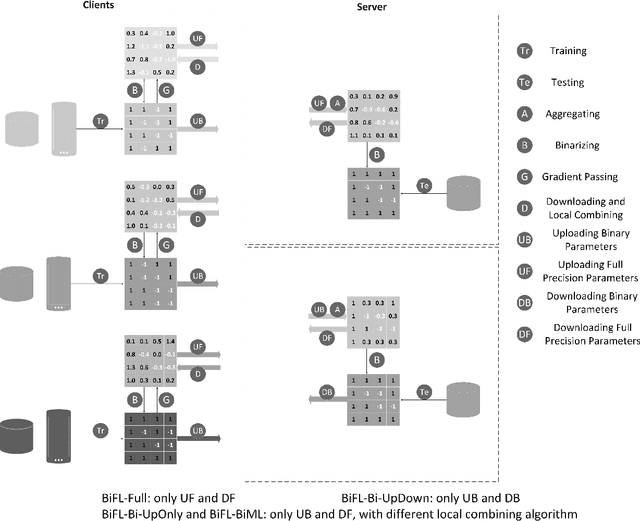

Federated learning (FL) is a privacy-preserving machine learning setting that enables many devices to jointly train a shared global model without the need to reveal their data to a central server. However, FL involves a frequent exchange of the parameters between all the clients and the server that coordinates the training. This introduces extensive communication overhead, which can be a major bottleneck in FL with limited communication links. In this paper, we consider training the binary neural networks (BNN) in the FL setting instead of the typical real-valued neural networks to fulfill the stringent delay and efficiency requirement in wireless edge networks. We introduce a novel FL framework of training BNN, where the clients only upload the binary parameters to the server. We also propose a novel parameter updating scheme based on the Maximum Likelihood (ML) estimation that preserves the performance of the BNN even without the availability of aggregated real-valued auxiliary parameters that are usually needed during the training of the BNN. Moreover, for the first time in the literature, we theoretically derive the conditions under which the training of BNN is converging. { Numerical results show that the proposed FL framework significantly reduces the communication cost compared to the conventional neural networks with typical real-valued parameters, and the performance loss incurred by the binarization can be further compensated by a hybrid method.