 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Safe Learning of Linear Time-Invariant Systems
Nov 01, 2021
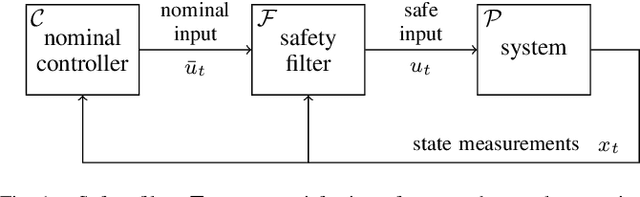
We consider safety in simultaneous learning and control of discrete-time linear time-invariant systems. We provide rigorous confidence bounds on the learned model of the system based on the number of utilized state measurements. These bounds are used to modify control inputs to the system via an optimization problem with potentially time-varying safety constraints. We prove that the state can only exit the safe set with small probability, provided a feasible solution to the safety-constrained optimization exists. This optimization problem is then reformulated in a more computationally-friendly format by tightening the safety constraints to account for model uncertainty during learning. The tightening decreases as the confidence in the learned model improves. We finally prove that, under persistence of excitation, the tightening becomes negligible as more measurements are gathered.
A review of probabilistic forecasting and prediction with machine learning
Sep 17, 2022
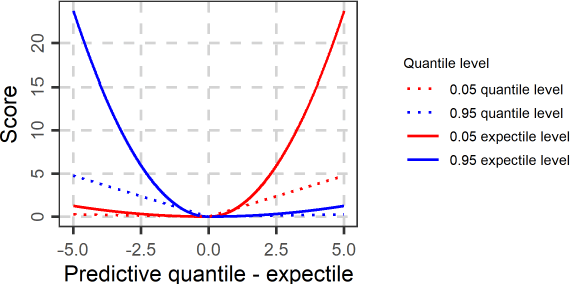
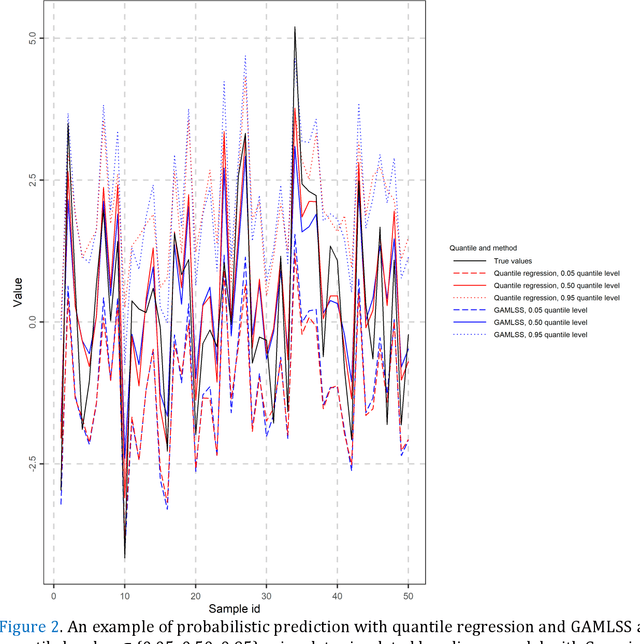
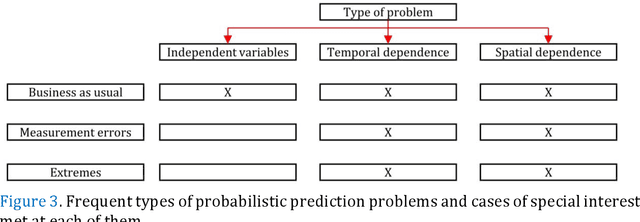
Predictions and forecasts of machine learning models should take the form of probability distributions, aiming to increase the quantity of information communicated to end users. Although applications of probabilistic prediction and forecasting with machine learning models in academia and industry are becoming more frequent, related concepts and methods have not been formalized and structured under a holistic view of the entire field. Here, we review the topic of predictive uncertainty estimation with machine learning algorithms, as well as the related metrics (consistent scoring functions and proper scoring rules) for assessing probabilistic predictions. The review covers a time period spanning from the introduction of early statistical (linear regression and time series models, based on Bayesian statistics or quantile regression) to recent machine learning algorithms (including generalized additive models for location, scale and shape, random forests, boosting and deep learning algorithms) that are more flexible by nature. The review of the progress in the field, expedites our understanding on how to develop new algorithms tailored to users' needs, since the latest advancements are based on some fundamental concepts applied to more complex algorithms. We conclude by classifying the material and discussing challenges that are becoming a hot topic of research.
A Late Multi-Modal Fusion Model for Detecting Hybrid Spam E-mail
Oct 26, 2022
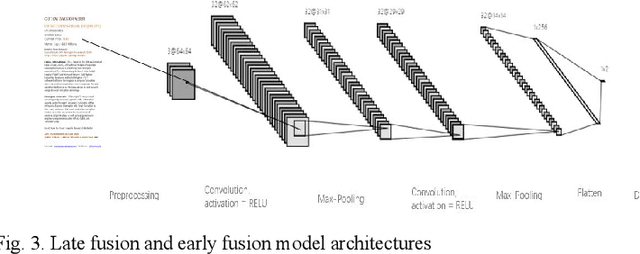
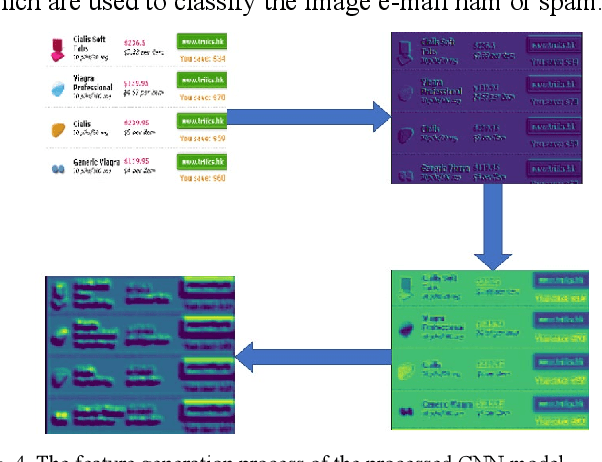

In recent years, spammers are now trying to obfuscate their intents by introducing hybrid spam e-mail combining both image and text parts, which is more challenging to detect in comparison to e-mails containing text or image only. The motivation behind this research is to design an effective approach filtering out hybrid spam e-mails to avoid situations where traditional text-based or image-baesd only filters fail to detect hybrid spam e-mails. To the best of our knowledge, a few studies have been conducted with the goal of detecting hybrid spam e-mails. Ordinarily, Optical Character Recognition (OCR) technology is used to eliminate the image parts of spam by transforming images into text. However, the research questions are that although OCR scanning is a very successful technique in processing text-and-image hybrid spam, it is not an effective solution for dealing with huge quantities due to the CPU power required and the execution time it takes to scan e-mail files. And the OCR techniques are not always reliable in the transformation processes. To address such problems, we propose new late multi-modal fusion training frameworks for a text-and-image hybrid spam e-mail filtering system compared to the classical early fusion detection frameworks based on the OCR method. Convolutional Neural Network (CNN) and Continuous Bag of Words were implemented to extract features from image and text parts of hybrid spam respectively, whereas generated features were fed to sigmoid layer and Machine Learning based classifiers including Random Forest (RF), Decision Tree (DT), Naive Bayes (NB) and Support Vector Machine (SVM) to determine the e-mail ham or spam.
Evaluation of Synthetically Generated CT for use in Transcranial Focused Ultrasound Procedures
Oct 26, 2022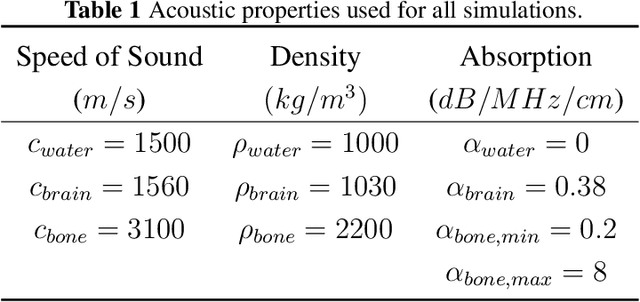
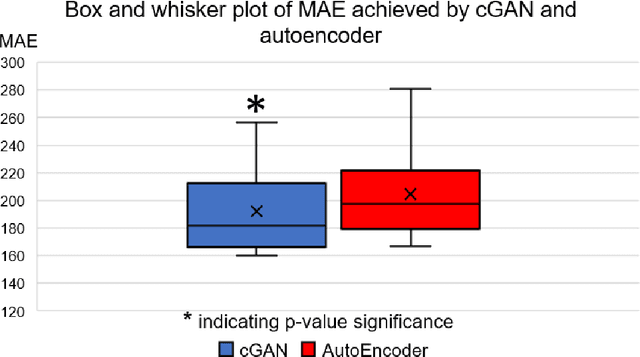
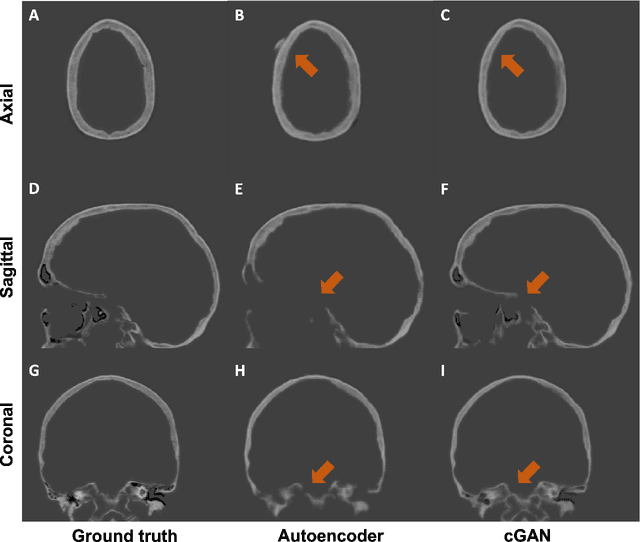
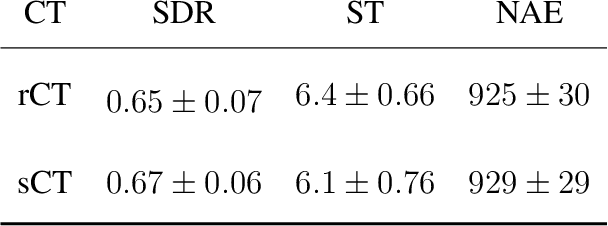
Transcranial focused ultrasound (tFUS) is a therapeutic ultrasound method that focuses sound through the skull to a small region noninvasively and often under MRI guidance. CT imaging is used to estimate the acoustic properties that vary between individual skulls to enable effective focusing during tFUS procedures, exposing patients to potentially harmful radiation. A method to estimate acoustic parameters in the skull without the need for CT would be desirable. Here, we synthesized CT images from routinely acquired T1-weighted MRI by using a 3D patch-based conditional generative adversarial network (cGAN) and evaluated the performance of synthesized CT (sCT) images for treatment planning with tFUS. We compared the performance of sCT to real CT (rCT) images for tFUS planning using Kranion and simulations using the acoustic toolbox, k-Wave. Simulations were performed for 3 tFUS scenarios: 1) no aberration correction, 2) correction with phases calculated from Kranion, and 3) phase shifts calculated from time-reversal. From Kranion, skull density ratio, skull thickness, and number of active elements between rCT and sCT had Pearson's Correlation Coefficients of 0.94, 0.92, and 0.98, respectively. Among 20 targets, differences in simulated peak pressure between rCT and sCT were largest without phase correction (12.4$\pm$8.1%) and smallest with Kranion phases (7.3$\pm$6.0%). The distance between peak focal locations between rCT and sCT was less than 1.3 mm for all simulation cases. Real and synthetically generated skulls had comparable image similarity, skull measurements, and acoustic simulation metrics. Our work demonstrates the feasibility of replacing real CTs with the MR-synthesized CT for tFUS planning. Source code and a docker image with the trained model are available at https://github.com/han-liu/SynCT_TcMRgFUS
Out-of-Vocabulary Challenge Report
Sep 14, 2022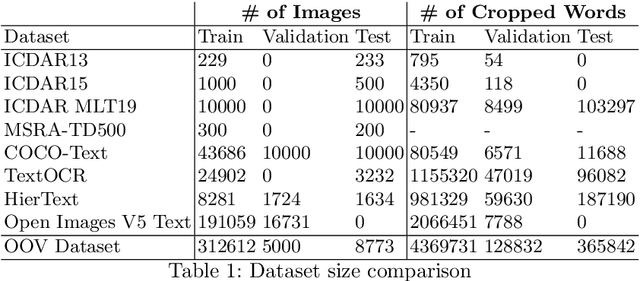

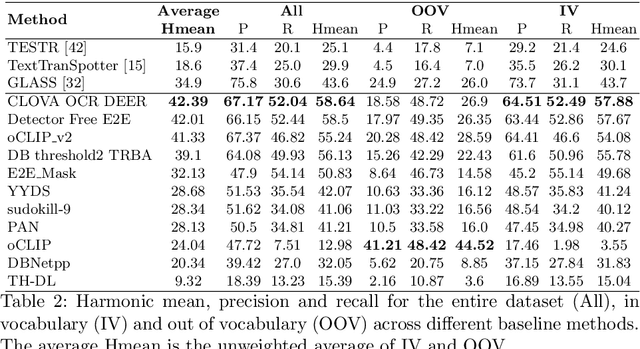
This paper presents final results of the Out-Of-Vocabulary 2022 (OOV) challenge. The OOV contest introduces an important aspect that is not commonly studied by Optical Character Recognition (OCR) models, namely, the recognition of unseen scene text instances at training time. The competition compiles a collection of public scene text datasets comprising of 326,385 images with 4,864,405 scene text instances, thus covering a wide range of data distributions. A new and independent validation and test set is formed with scene text instances that are out of vocabulary at training time. The competition was structured in two tasks, end-to-end and cropped scene text recognition respectively. A thorough analysis of results from baselines and different participants is presented. Interestingly, current state-of-the-art models show a significant performance gap under the newly studied setting. We conclude that the OOV dataset proposed in this challenge will be an essential area to be explored in order to develop scene text models that achieve more robust and generalized predictions.
Exploration with Global Consistency Using Real-Time Re-integration and Active Loop Closure
Apr 06, 2022
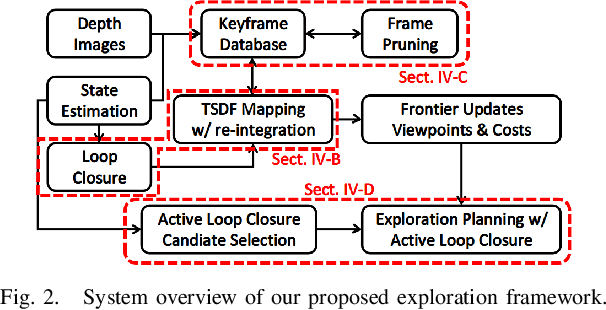
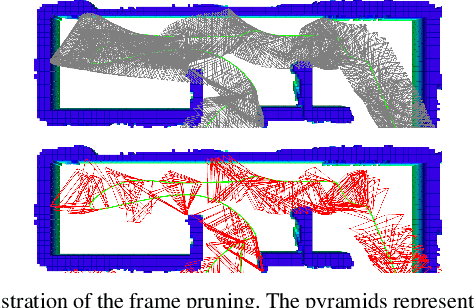

Despite recent progress of robotic exploration, most methods assume that drift-free localization is available, which is problematic in reality and causes severe distortion of the reconstructed map. In this work, we present a systematic exploration mapping and planning framework that deals with drifted localization, allowing efficient and globally consistent reconstruction. A real-time re-integration-based mapping approach along with a frame pruning mechanism is proposed, which rectifies map distortion effectively when drifted localization is corrected upon detecting loop-closure. Besides, an exploration planning method considering historical viewpoints is presented to enable active loop closing, which promotes a higher opportunity to correct localization errors and further improves the mapping quality. We evaluate both the mapping and planning methods as well as the entire system comprehensively in simulation and real-world experiments, showing their effectiveness in practice. The implementation of the proposed method will be made open-source for the benefit of the robotics community.
Optimal consumption-investment choices under wealth-driven risk aversion
Oct 03, 2022
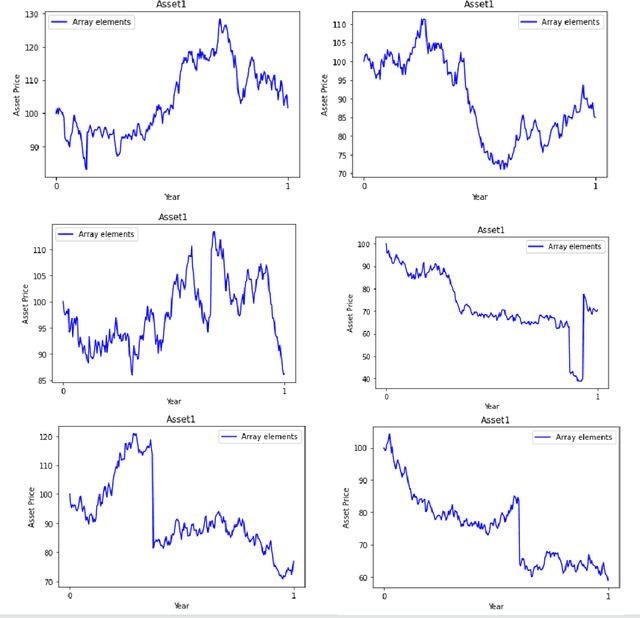
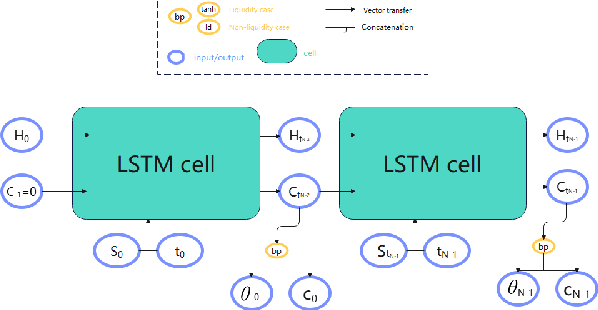
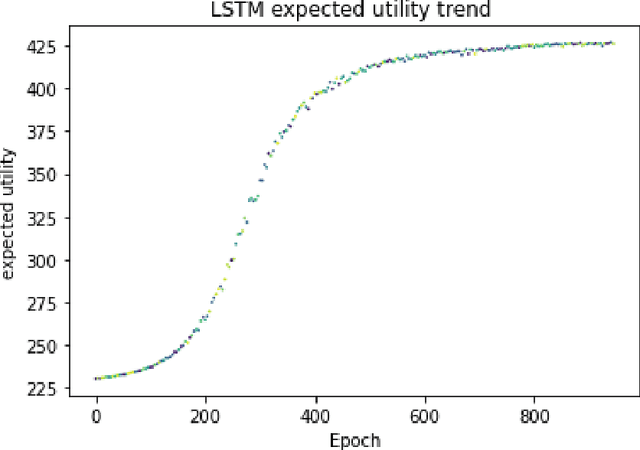
CRRA utility where the risk aversion coefficient is a constant is commonly seen in various economics models. But wealth-driven risk aversion rarely shows up in investor's investment problems. This paper mainly focus on numerical solutions to the optimal consumption-investment choices under wealth-driven aversion done by neural network. A jump-diffusion model is used to simulate the artificial data that is needed for the neural network training. The WDRA Model is set up for describing the investment problem and there are two parameters that require to be optimized, which are the investment rate of the wealth on the risky assets and the consumption during the investment time horizon. Under this model, neural network LSTM with one objective function is implemented and shows promising results.
A large sample theory for infinitesimal gradient boosting
Oct 03, 2022Infinitesimal gradient boosting is defined as the vanishing-learning-rate limit of the popular tree-based gradient boosting algorithm from machine learning (Dombry and Duchamps, 2021). It is characterized as the solution of a nonlinear ordinary differential equation in a infinite-dimensional function space where the infinitesimal boosting operator driving the dynamics depends on the training sample. We consider the asymptotic behavior of the model in the large sample limit and prove its convergence to a deterministic process. This infinite population limit is again characterized by a differential equation that depends on the population distribution. We explore some properties of this population limit: we prove that the dynamics makes the test error decrease and we consider its long time behavior.
Cell tracking for live-cell microscopy using an activity-prioritized assignment strategy
Oct 20, 2022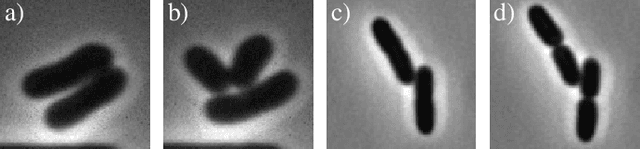


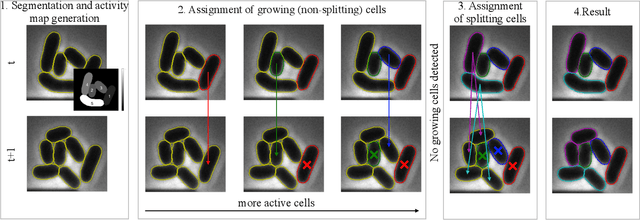
Cell tracking is an essential tool in live-cell imaging to determine single-cell features, such as division patterns or elongation rates. Unlike in common multiple object tracking, in microbial live-cell experiments cells are growing, moving, and dividing over time, to form cell colonies that are densely packed in mono-layer structures. With increasing cell numbers, following the precise cell-cell associations correctly over many generations becomes more and more challenging, due to the massively increasing number of possible associations. To tackle this challenge, we propose a fast parameter-free cell tracking approach, which consists of activity-prioritized nearest neighbor assignment of growing cells and a combinatorial solver that assigns splitting mother cells to their daughters. As input for the tracking, Omnipose is utilized for instance segmentation. Unlike conventional nearest-neighbor-based tracking approaches, the assignment steps of our proposed method are based on a Gaussian activity-based metric, predicting the cell-specific migration probability, thereby limiting the number of erroneous assignments. In addition to being a building block for cell tracking, the proposed activity map is a standalone tracking-free metric for indicating cell activity. Finally, we perform a quantitative analysis of the tracking accuracy for different frame rates, to inform life scientists about a suitable (in terms of tracking performance) choice of the frame rate for their cultivation experiments, when cell tracks are the desired key outcome.
Decentralized LiDAR-inertial Swarm Odometry
Sep 14, 2022
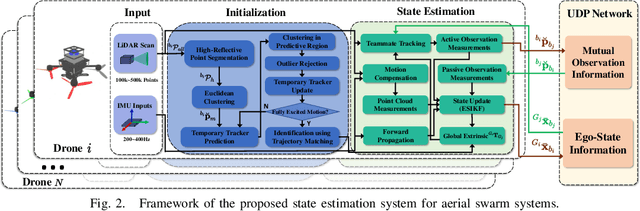
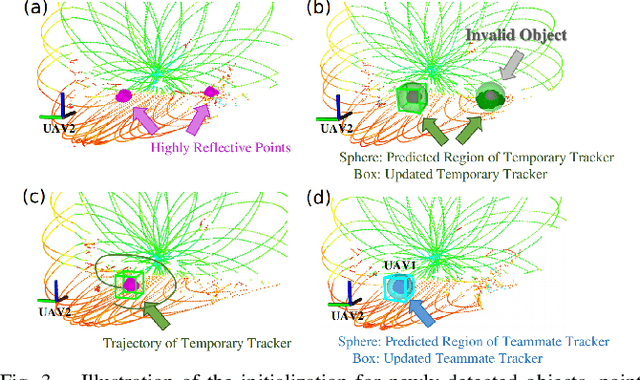
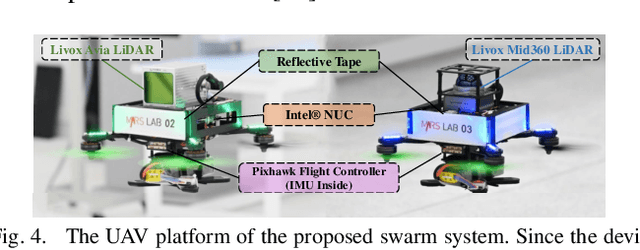
Accurate self and relative state estimation are the critical preconditions for completing swarm tasks, e.g., collaborative autonomous exploration, target tracking, search and rescue. This paper proposes a fully decentralized state estimation method for aerial swarm systems, in which each drone performs precise ego-state estimation, exchanges ego-state and mutual observation information by wireless communication, and estimates relative state with respect to (w.r.t.) the rest of UAVs, all in real-time and only based on LiDAR-inertial measurements. A novel 3D LiDAR-based drone detection, identification and tracking method is proposed to obtain observations of teammate drones. The mutual observation measurements are then tightly-coupled with IMU and LiDAR measurements to perform real-time and accurate estimation of ego-state and relative state jointly. Extensive real-world experiments show the broad adaptability to complicated scenarios, including GPS-denied scenes, degenerate scenes for camera (dark night) or LiDAR (facing a single wall). Compared with ground-truth provided by motion capture system, the result shows the centimeter-level localization accuracy which outperforms other state-of-the-art LiDAR-inertial odometry for single UAV system.