 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analyzing Text Representations under Tight Annotation Budgets: Measuring Structural Alignment
Oct 11, 2022
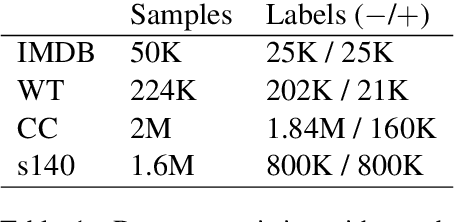
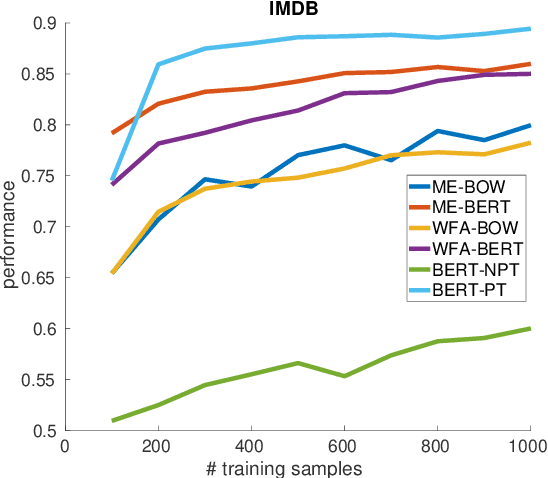
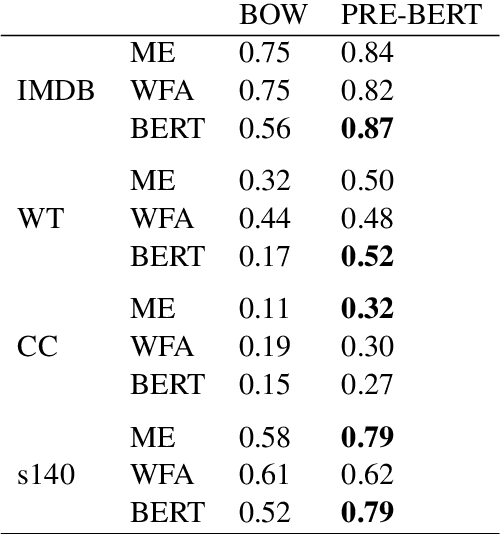
Annotating large collections of textual data can be time consuming and expensive. That is why the ability to train models with limited annotation budgets is of great importance. In this context, it has been shown that under tight annotation budgets the choice of data representation is key. The goal of this paper is to better understand why this is so. With this goal in mind, we propose a metric that measures the extent to which a given representation is structurally aligned with a task. We conduct experiments on several text classification datasets testing a variety of models and representations. Using our proposed metric we show that an efficient representation for a task (i.e. one that enables learning from few samples) is a representation that induces a good alignment between latent input structure and class structure.
Crowdsourced-based Deep Convolutional Networks for Urban Flood Depth Mapping
Sep 06, 2022
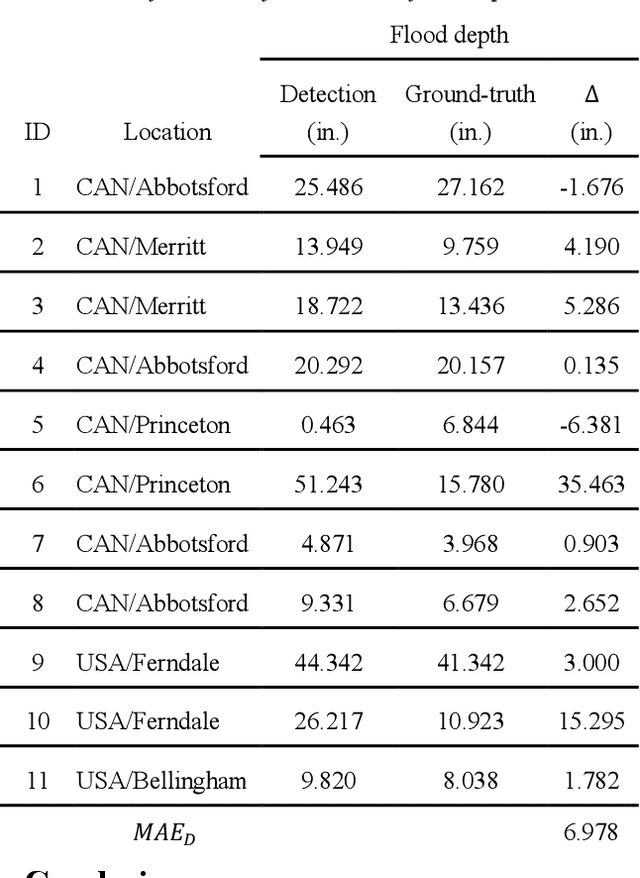
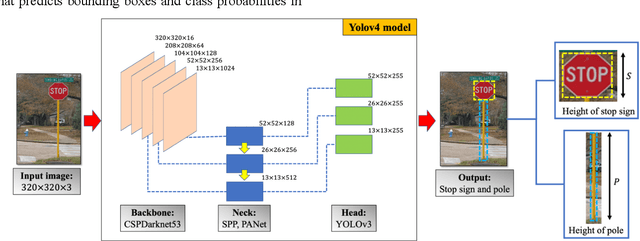

Successful flood recovery and evacuation require access to reliable flood depth information. Most existing flood mapping tools do not provide real-time flood maps of inundated streets in and around residential areas. In this paper, a deep convolutional network is used to determine flood depth with high spatial resolution by analyzing crowdsourced images of submerged traffic signs. Testing the model on photos from a recent flood in the U.S. and Canada yields a mean absolute error of 6.978 in., which is on par with previous studies, thus demonstrating the applicability of this approach to low-cost, accurate, and real-time flood risk mapping.
Recommendations in a Multi-Domain Setting: Adapting for Customization, Scalability and Real-Time Performance
Mar 02, 2022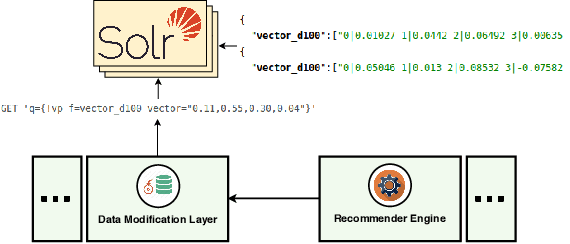
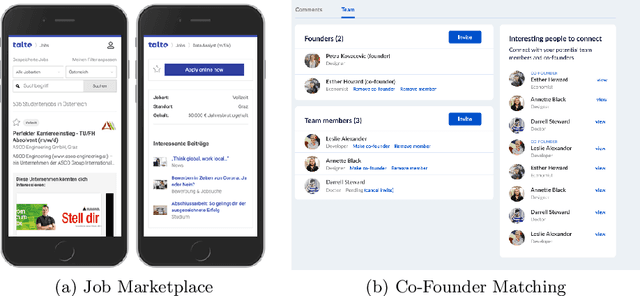
In this industry talk at ECIR'2022, we illustrate how to build a modern recommender system that can serve recommendations in real-time for a diverse set of application domains. Specifically, we present our system architecture that utilizes popular recommendation algorithms from the literature such as Collaborative Filtering, Content-based Filtering as well as various neural embedding approaches (e.g., Doc2Vec, Autoencoders, etc.). We showcase the applicability of our system architecture using two real-world use-cases, namely providing recommendations for the domains of (i) job marketplaces, and (ii) entrepreneurial start-up founding. We strongly believe that our experiences from both research- and industry-oriented settings should be of interest for practitioners in the field of real-time multi-domain recommender systems.
Multiscale Latent-Guided Entropy Model for LiDAR Point Cloud Compression
Sep 26, 2022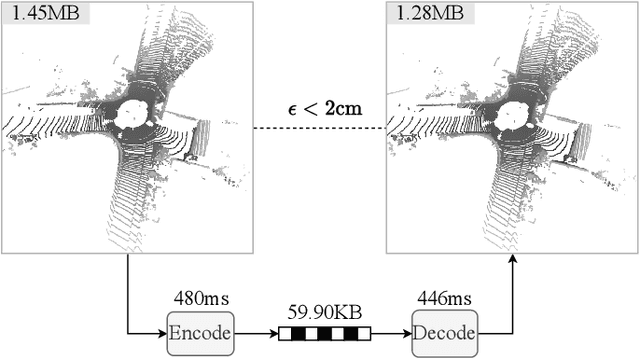
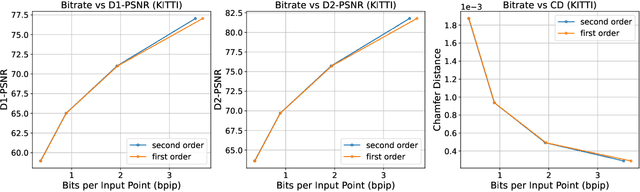
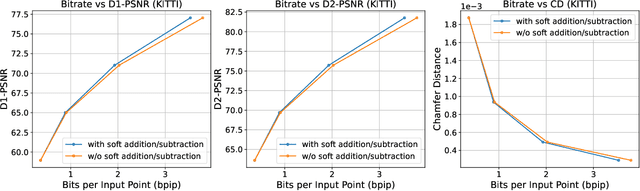

The non-uniform distribution and extremely sparse nature of the LiDAR point cloud (LPC) bring significant challenges to its high-efficient compression. This paper proposes a novel end-to-end, fully-factorized deep framework that encodes the original LPC into an octree structure and hierarchically decomposes the octree entropy model in layers. The proposed framework utilizes a hierarchical latent variable as side information to encapsulate the sibling and ancestor dependence, which provides sufficient context information for the modelling of point cloud distribution while enabling the parallel encoding and decoding of octree nodes in the same layer. Besides, we propose a residual coding framework for the compression of the latent variable, which explores the spatial correlation of each layer by progressive downsampling, and model the corresponding residual with a fully-factorized entropy model. Furthermore, we propose soft addition and subtraction for residual coding to improve network flexibility. The comprehensive experiment results on the LiDAR benchmark SemanticKITTI and MPEG-specified dataset Ford demonstrates that our proposed framework achieves state-of-the-art performance among all the previous LPC frameworks. Besides, our end-to-end, fully-factorized framework is proved by experiment to be high-parallelized and time-efficient and saves more than 99.8% of decoding time compared to previous state-of-the-art methods on LPC compression.
Data-driven and machine-learning based prediction of wave propagation behavior in dam-break flood
Sep 19, 2022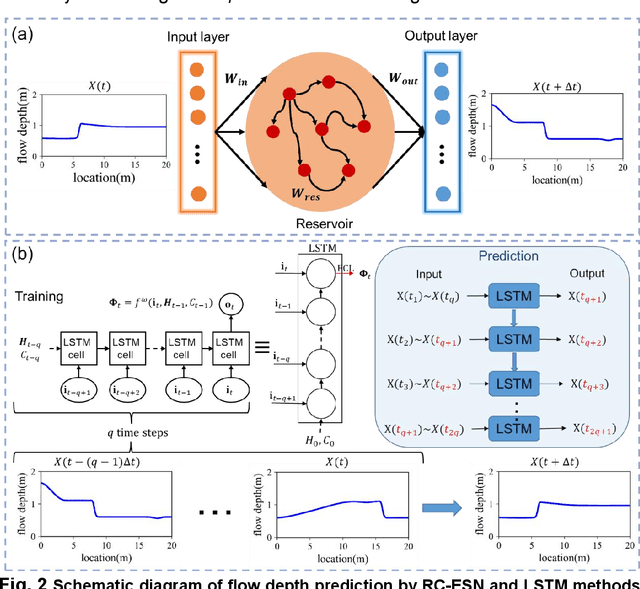
The computational prediction of wave propagation in dam-break floods is a long-standing problem in hydrodynamics and hydrology. Until now, conventional numerical models based on Saint-Venant equations are the dominant approaches. Here we show that a machine learning model that is well-trained on a minimal amount of data, can help predict the long-term dynamic behavior of a one-dimensional dam-break flood with satisfactory accuracy. For this purpose, we solve the Saint-Venant equations for a one-dimensional dam-break flood scenario using the Lax-Wendroff numerical scheme and train the reservoir computing echo state network (RC-ESN) with the dataset by the simulation results consisting of time-sequence flow depths. We demonstrate a good prediction ability of the RC-ESN model, which ahead predicts wave propagation behavior 286 time-steps in the dam-break flood with a root mean square error (RMSE) smaller than 0.01, outperforming the conventional long short-term memory (LSTM) model which reaches a comparable RMSE of only 81 time-steps ahead. To show the performance of the RC-ESN model, we also provide a sensitivity analysis of the prediction accuracy concerning the key parameters including training set size, reservoir size, and spectral radius. Results indicate that the RC-ESN are less dependent on the training set size, a medium reservoir size K=1200~2600 is sufficient. We confirm that the spectral radius \r{ho} shows a complex influence on the prediction accuracy and suggest a smaller spectral radius \r{ho} currently. By changing the initial flow depth of the dam break, we also obtained the conclusion that the prediction horizon of RC-ESN is larger than that of LSTM.
Teacher-Student Architecture for Knowledge Learning: A Survey
Oct 28, 2022
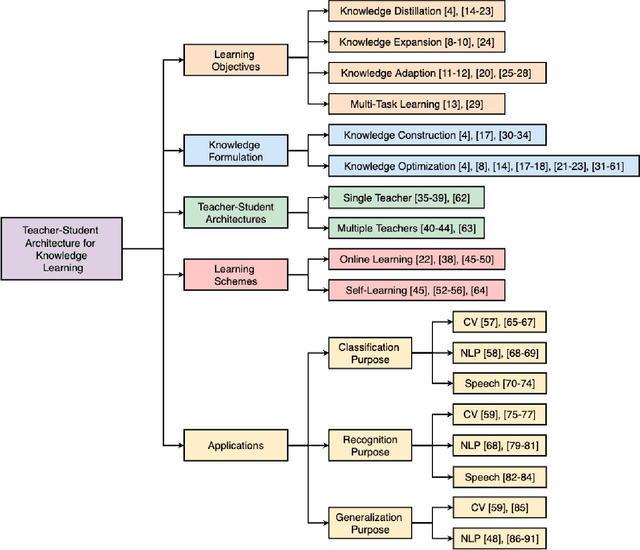
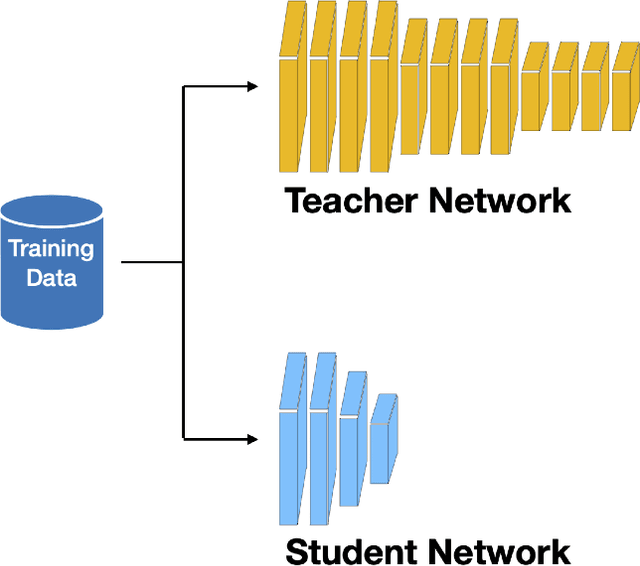
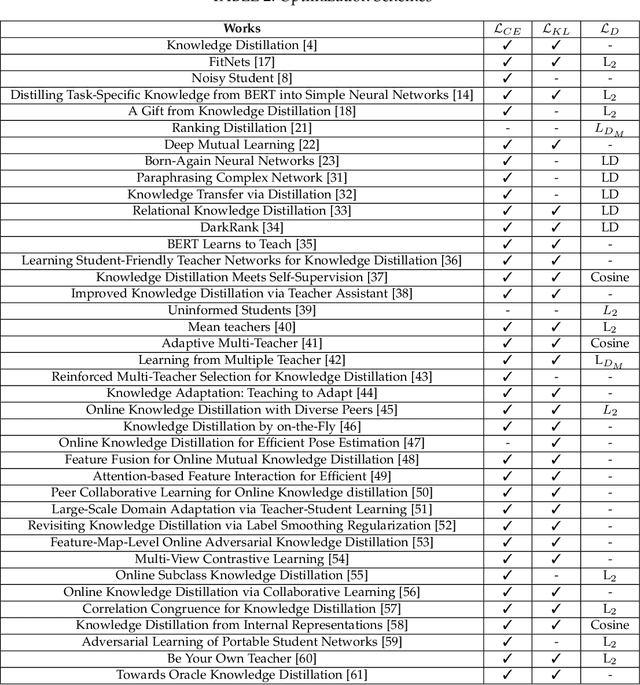
Although Deep Neural Networks (DNNs) have shown a strong capacity to solve large-scale problems in many areas, such DNNs with voluminous parameters are hard to be deployed in a real-time system. To tackle this issue, Teacher-Student architectures were first utilized in knowledge distillation, where simple student networks can achieve comparable performance to deep teacher networks. Recently, Teacher-Student architectures have been effectively and widely embraced on various knowledge learning objectives, including knowledge distillation, knowledge expansion, knowledge adaption, and multi-task learning. With the help of Teacher-Student architectures, current studies are able to achieve multiple knowledge-learning objectives through lightweight and effective student networks. Different from the existing knowledge distillation surveys, this survey detailedly discusses Teacher-Student architectures with multiple knowledge learning objectives. In addition, we systematically introduce the knowledge construction and optimization process during the knowledge learning and then analyze various Teacher-Student architectures and effective learning schemes that have been leveraged to learn representative and robust knowledge. This paper also summarizes the latest applications of Teacher-Student architectures based on different purposes (i.e., classification, recognition, and generation). Finally, the potential research directions of knowledge learning are investigated on the Teacher-Student architecture design, the quality of knowledge, and the theoretical studies of regression-based learning, respectively. With this comprehensive survey, both industry practitioners and the academic community can learn insightful guidelines about Teacher-Student architectures on multiple knowledge learning objectives.
UnfoldML: Cost-Aware and Uncertainty-Based Dynamic 2D Prediction for Multi-Stage Classification
Oct 28, 2022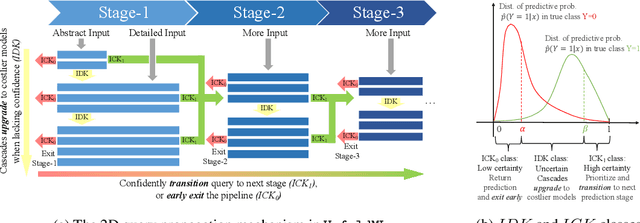

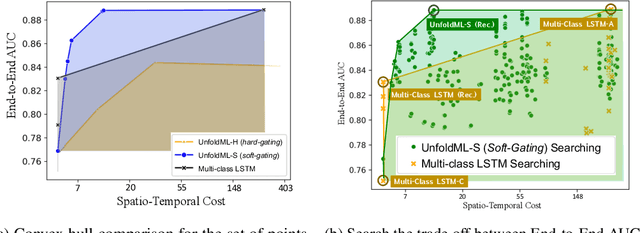
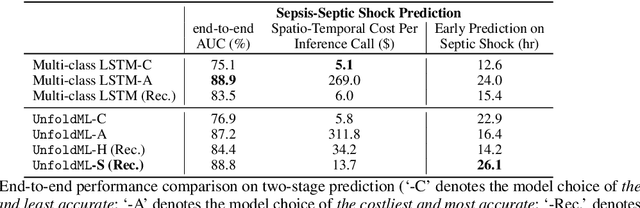
Machine Learning (ML) research has focused on maximizing the accuracy of predictive tasks. ML models, however, are increasingly more complex, resource intensive, and costlier to deploy in resource-constrained environments. These issues are exacerbated for prediction tasks with sequential classification on progressively transitioned stages with ''happens-before'' relation between them.We argue that it is possible to ''unfold'' a monolithic single multi-class classifier, typically trained for all stages using all data, into a series of single-stage classifiers. Each single-stage classifier can be cascaded gradually from cheaper to more expensive binary classifiers that are trained using only the necessary data modalities or features required for that stage. UnfoldML is a cost-aware and uncertainty-based dynamic 2D prediction pipeline for multi-stage classification that enables (1) navigation of the accuracy/cost tradeoff space, (2) reducing the spatio-temporal cost of inference by orders of magnitude, and (3) early prediction on proceeding stages. UnfoldML achieves orders of magnitude better cost in clinical settings, while detecting multi-stage disease development in real time. It achieves within 0.1% accuracy from the highest-performing multi-class baseline, while saving close to 20X on spatio-temporal cost of inference and earlier (3.5hrs) disease onset prediction. We also show that UnfoldML generalizes to image classification, where it can predict different level of labels (from coarse to fine) given different level of abstractions of a image, saving close to 5X cost with as little as 0.4% accuracy reduction.
DELFI: Deep Mixture Models for Long-term Air Quality Forecasting in the Delhi National Capital Region
Oct 28, 2022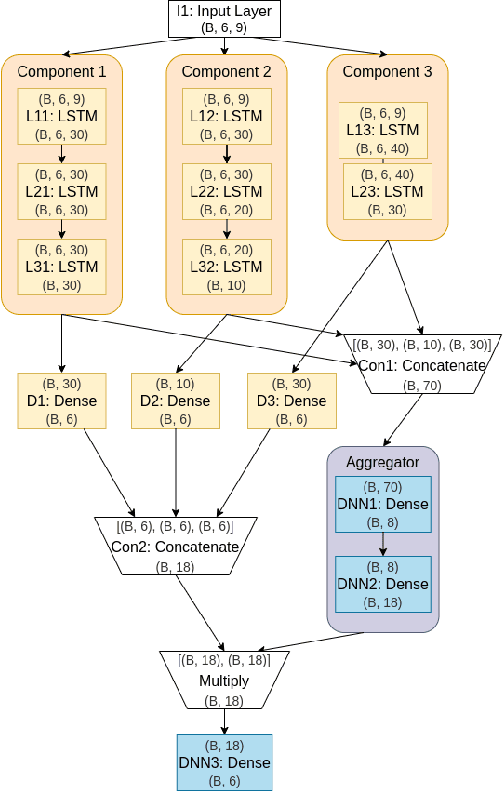

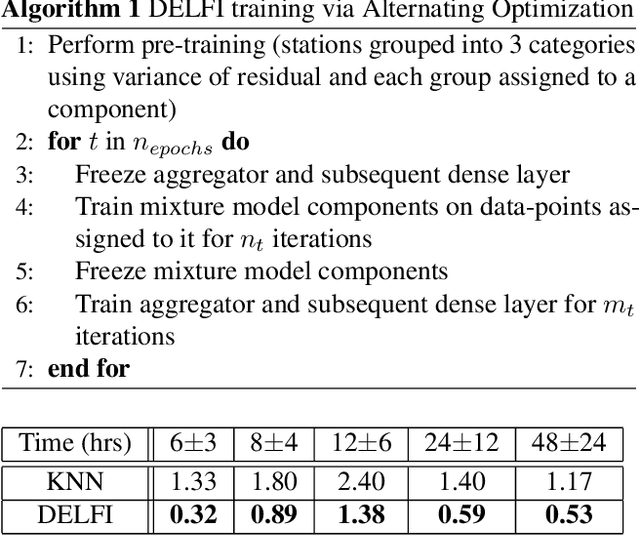
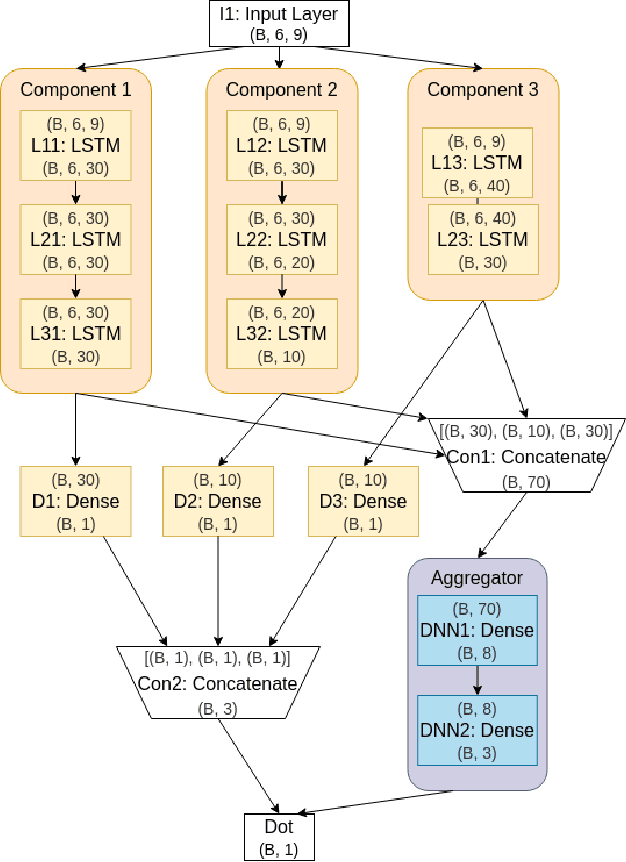
The identification and control of human factors in climate change is a rapidly growing concern and robust, real-time air-quality monitoring and forecasting plays a critical role in allowing effective policy formulation and implementation. This paper presents DELFI, a novel deep learning-based mixture model to make effective long-term predictions of Particulate Matter (PM) 2.5 concentrations. A key novelty in DELFI is its multi-scale approach to the forecasting problem. The observation that point predictions are more suitable in the short-term and probabilistic predictions in the long-term allows accurate predictions to be made as much as 24 hours in advance. DELFI incorporates meteorological data as well as pollutant-based features to ensure a robust model that is divided into two parts: (i) a stack of three Long Short-Term Memory (LSTM) networks that perform differential modelling of the same window of past data, and (ii) a fully-connected layer enabling attention to each of the components. Experimental evaluation based on deployment of 13 stations in the Delhi National Capital Region (Delhi-NCR) in India establishes that DELFI offers far superior predictions especially in the long-term as compared to even non-parametric baselines. The Delhi-NCR recorded the 3rd highest PM levels amongst 39 mega-cities across the world during 2011-2015 and DELFI's performance establishes it as a potential tool for effective long-term forecasting of PM levels to enable public health management and environment protection.
ApacheJIT: A Large Dataset for Just-In-Time Defect Prediction
Feb 28, 2022
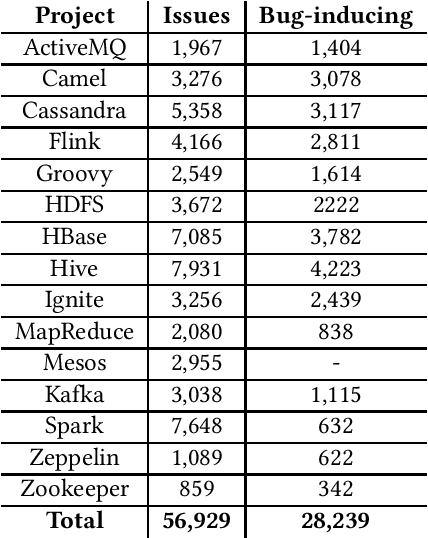
In this paper, we present ApacheJIT, a large dataset for Just-In-Time defect prediction. ApacheJIT consists of clean and bug-inducing software changes in popular Apache projects. ApacheJIT has a total of 106,674 commits (28,239 bug-inducing and 78,435 clean commits). Having a large number of commits makes ApacheJIT a suitable dataset for machine learning models, especially deep learning models that require large training sets to effectively generalize the patterns present in the historical data to future data. In addition to the original dataset, we also present carefully selected training and test sets that we recommend to be used in training and evaluating machine learning models.
Real-time smart vehicle surveillance system
Nov 24, 2021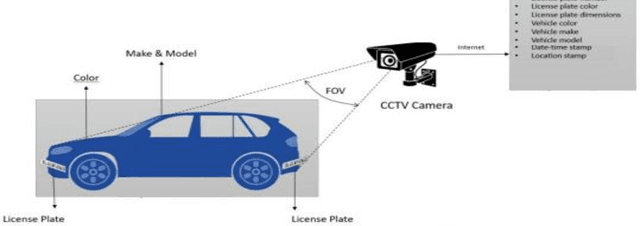
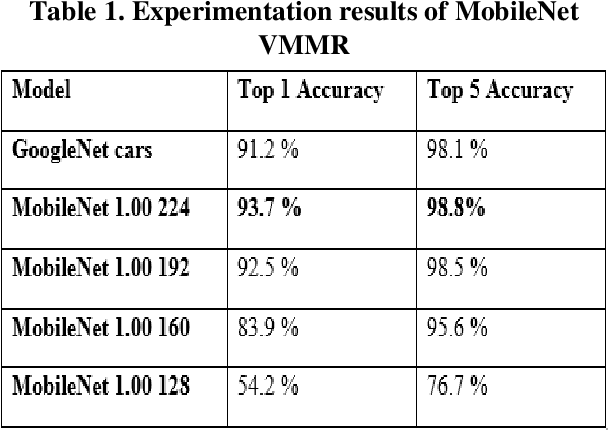

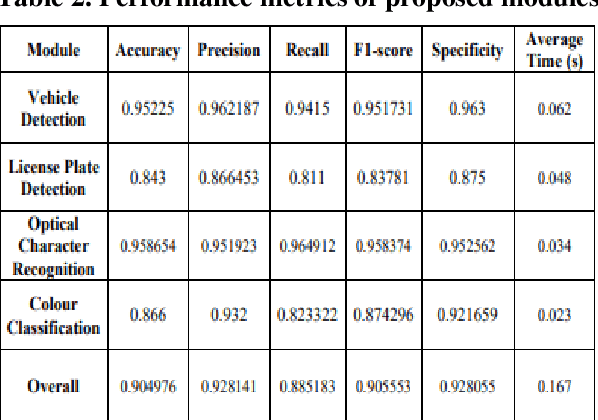
Over the last decade, there has been a spike in criminal activity all around the globe. According to the Indian police department, vehicle theft is one of the least solved offenses, and almost 19% of all recorded cases are related to motor vehicle theft. To overcome these adversaries, we propose a real-time vehicle surveillance system, which detects and tracks the suspect vehicle using the CCTV video feed. The proposed system extracts various attributes of the vehicle such as Make, Model, Color, License plate number, and type of the license plate. Various image processing and deep learning algorithms are employed to meet the objectives of the proposed system. The extracted features can be used as evidence to report violations of law. Although the system uses more parameters, it is still able to make real time predictions with minimal latency and accuracy loss.