 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDELFI: Deep Mixture Models for Long-term Air Quality Forecasting in the Delhi National Capital Region
Oct 28, 2022



The identification and control of human factors in climate change is a rapidly growing concern and robust, real-time air-quality monitoring and forecasting plays a critical role in allowing effective policy formulation and implementation. This paper presents DELFI, a novel deep learning-based mixture model to make effective long-term predictions of Particulate Matter (PM) 2.5 concentrations. A key novelty in DELFI is its multi-scale approach to the forecasting problem. The observation that point predictions are more suitable in the short-term and probabilistic predictions in the long-term allows accurate predictions to be made as much as 24 hours in advance. DELFI incorporates meteorological data as well as pollutant-based features to ensure a robust model that is divided into two parts: (i) a stack of three Long Short-Term Memory (LSTM) networks that perform differential modelling of the same window of past data, and (ii) a fully-connected layer enabling attention to each of the components. Experimental evaluation based on deployment of 13 stations in the Delhi National Capital Region (Delhi-NCR) in India establishes that DELFI offers far superior predictions especially in the long-term as compared to even non-parametric baselines. The Delhi-NCR recorded the 3rd highest PM levels amongst 39 mega-cities across the world during 2011-2015 and DELFI's performance establishes it as a potential tool for effective long-term forecasting of PM levels to enable public health management and environment protection.
AI-based Monitoring and Response System for Hospital Preparedness towards COVID-19 in Southeast Asia
Jul 30, 2020
This research paper proposes a COVID-19 monitoring and response system to identify the surge in the volume of patients at hospitals and shortage of critical equipment like ventilators in South-east Asian countries, to understand the burden on health facilities. This can help authorities in these regions with resource planning measures to redirect resources to the regions identified by the model. Due to the lack of publicly available data on the influx of patients in hospitals, or the shortage of equipment, ICU units or hospital beds that regions in these countries might be facing, we leverage Twitter data for gleaning this information. The approach has yielded accurate results for states in India, and we are working on validating the model for the remaining countries so that it can serve as a reliable tool for authorities to monitor the burden on hospitals.
$S^3$Net: Semantic-Aware Self-supervised Depth Estimation with Monocular Videos and Synthetic Data
Jul 28, 2020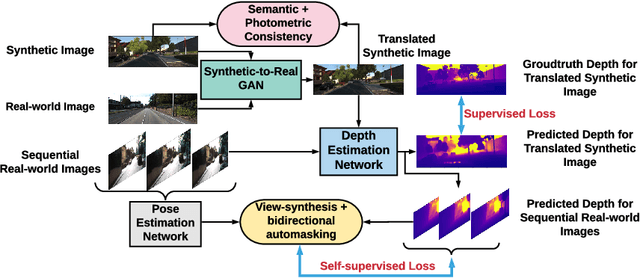
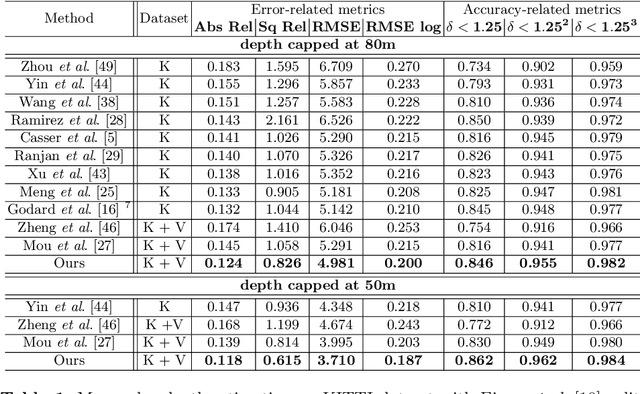

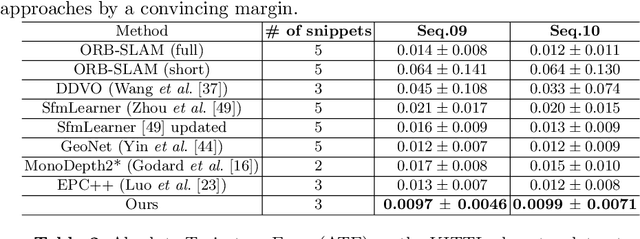
Solving depth estimation with monocular cameras enables the possibility of widespread use of cameras as low-cost depth estimation sensors in applications such as autonomous driving and robotics. However, learning such a scalable depth estimation model would require a lot of labeled data which is expensive to collect. There are two popular existing approaches which do not require annotated depth maps: (i) using labeled synthetic and unlabeled real data in an adversarial framework to predict more accurate depth, and (ii) unsupervised models which exploit geometric structure across space and time in monocular video frames. Ideally, we would like to leverage features provided by both approaches as they complement each other; however, existing methods do not adequately exploit these additive benefits. We present $S^3$Net, a self-supervised framework which combines these complementary features: we use synthetic and real-world images for training while exploiting geometric, temporal, as well as semantic constraints. Our novel consolidated architecture provides a new state-of-the-art in self-supervised depth estimation using monocular videos. We present a unique way to train this self-supervised framework, and achieve (i) more than $15\%$ improvement over previous synthetic supervised approaches that use domain adaptation and (ii) more than $10\%$ improvement over previous self-supervised approaches which exploit geometric constraints from the real data.