 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Constructing Trajectory and Predicting Estimated Time of Arrival for Long Distance Travelling Vessels: A Probability Density-based Scanning Approach
May 13, 2022
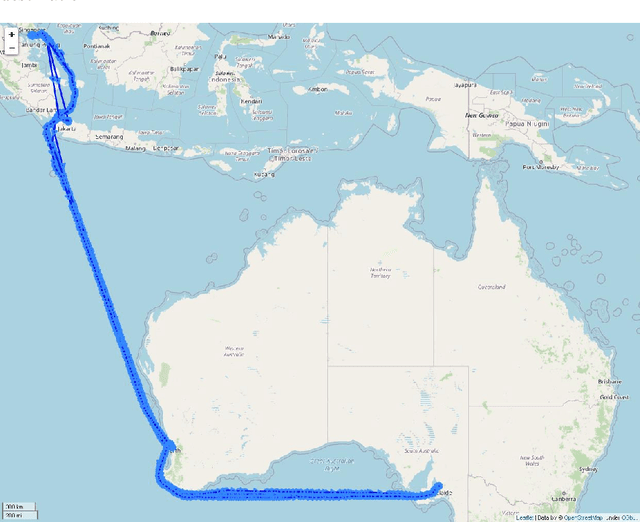
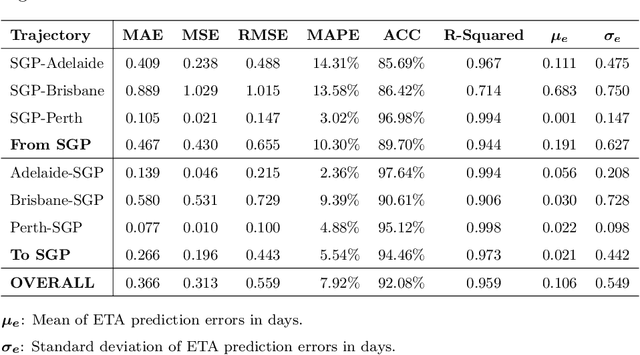
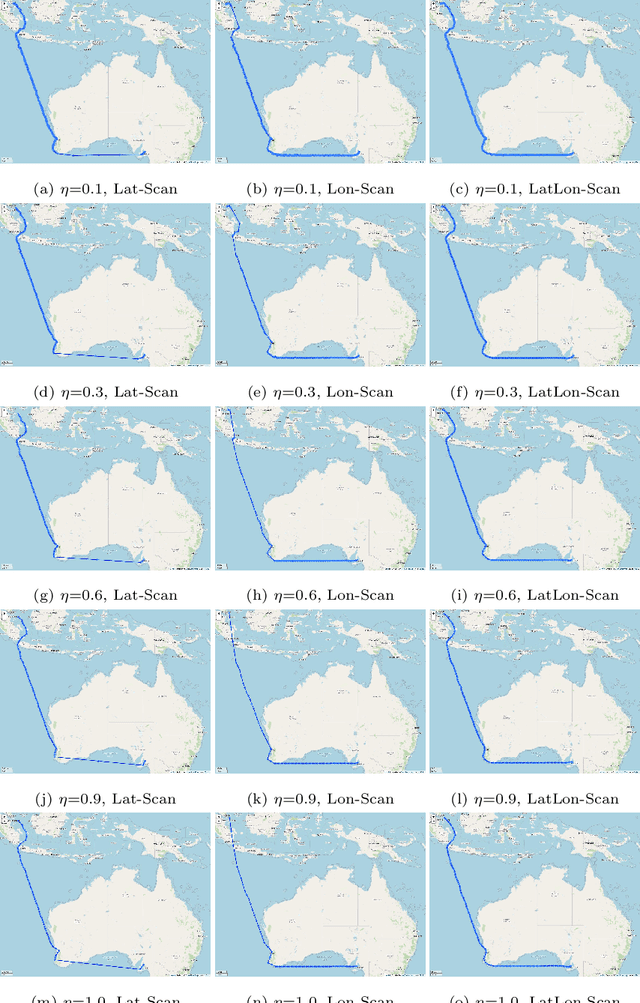
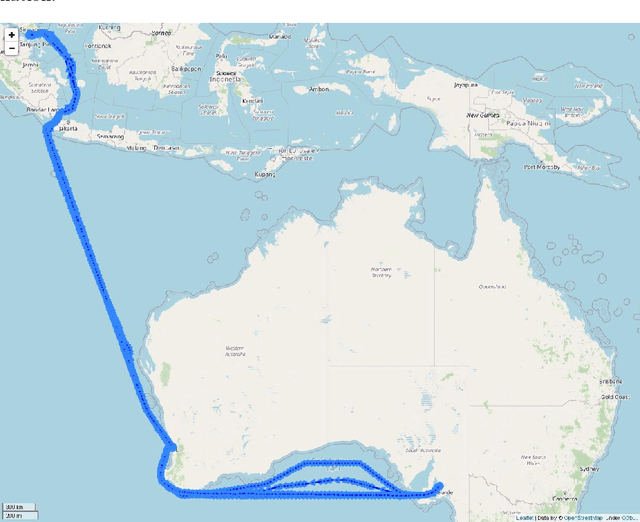
In this study, a probability density-based approach for constructing trajectories is proposed and validated through an typical use-case application: Estimated Time of Arrival (ETA) prediction given origin-destination pairs. The ETA prediction is based on physics and mathematical laws given by the extracted information of probability density-based trajectories constructed. The overall ETA prediction errors are about 0.106 days (i.e. 2.544 hours) on average with 0.549 days (i.e. 13.176 hours) standard deviation, and the proposed approach has an accuracy of 92.08% with 0.959 R-Squared value for overall trajectories between Singapore and Australia ports selected.
A Low Memory Footprint Quantized Neural Network for Depth Completion of Very Sparse Time-of-Flight Depth Maps
May 25, 2022
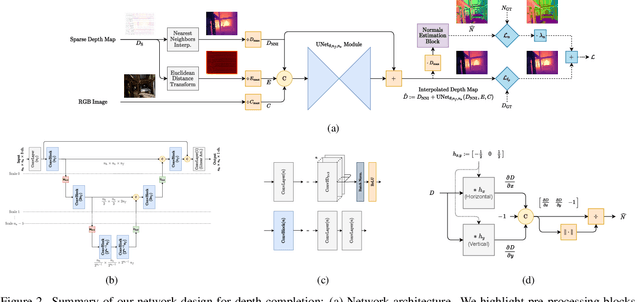
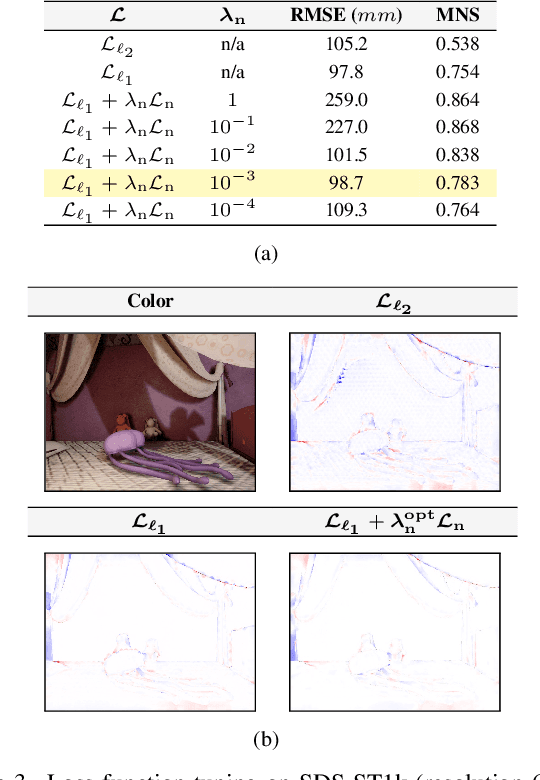
Sparse active illumination enables precise time-of-flight depth sensing as it maximizes signal-to-noise ratio for low power budgets. However, depth completion is required to produce dense depth maps for 3D perception. We address this task with realistic illumination and sensor resolution constraints by simulating ToF datasets for indoor 3D perception with challenging sparsity levels. We propose a quantized convolutional encoder-decoder network for this task. Our model achieves optimal depth map quality by means of input pre-processing and carefully tuned training with a geometry-preserving loss function. We also achieve low memory footprint for weights and activations by means of mixed precision quantization-at-training techniques. The resulting quantized models are comparable to the state of the art in terms of quality, but they require very low GPU times and achieve up to 14-fold memory size reduction for the weights w.r.t. their floating point counterpart with minimal impact on quality metrics.
On Representations of Mean-Field Variational Inference
Oct 20, 2022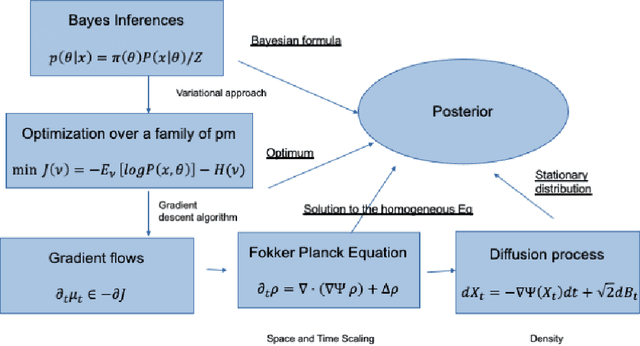
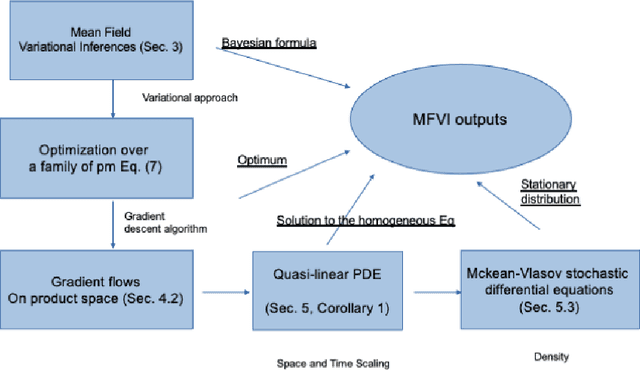
The mean field variational inference (MFVI) formulation restricts the general Bayesian inference problem to the subspace of product measures. We present a framework to analyze MFVI algorithms, which is inspired by a similar development for general variational Bayesian formulations. Our approach enables the MFVI problem to be represented in three different manners: a gradient flow on Wasserstein space, a system of Fokker-Planck-like equations and a diffusion process. Rigorous guarantees are established to show that a time-discretized implementation of the coordinate ascent variational inference algorithm in the product Wasserstein space of measures yields a gradient flow in the limit. A similar result is obtained for their associated densities, with the limit being given by a quasi-linear partial differential equation. A popular class of practical algorithms falls in this framework, which provides tools to establish convergence. We hope this framework could be used to guarantee convergence of algorithms in a variety of approaches, old and new, to solve variational inference problems.
Private Algorithms with Private Predictions
Oct 20, 2022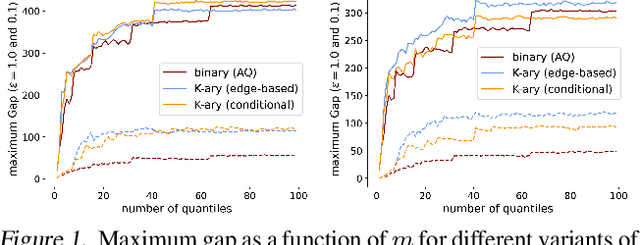
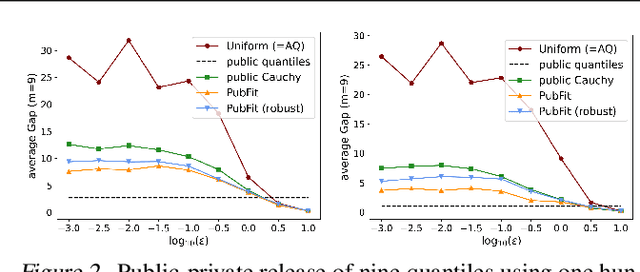
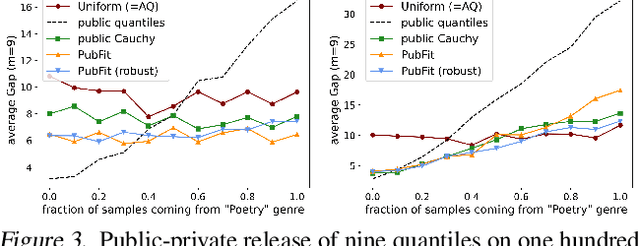
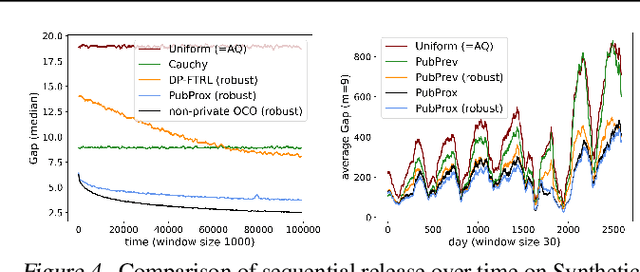
When applying differential privacy to sensitive data, a common way of getting improved performance is to use external information such as other sensitive data, public data, or human priors. We propose to use the algorithms with predictions framework -- previously applied largely to improve time complexity or competitive ratios -- as a powerful way of designing and analyzing privacy-preserving methods that can take advantage of such external information to improve utility. For four important tasks -- quantile release, its extension to multiple quantiles, covariance estimation, and data release -- we construct prediction-dependent differentially private methods whose utility scales with natural measures of prediction quality. The analyses enjoy several advantages, including minimal assumptions about the data, natural ways of adding robustness to noisy predictions, and novel "meta" algorithms that can learn predictions from other (potentially sensitive) data. Overall, our results demonstrate how to enable differentially private algorithms to make use of and learn noisy predictions, which holds great promise for improving utility while preserving privacy across a variety of tasks.
Data-Efficient Strategies for Expanding Hate Speech Detection into Under-Resourced Languages
Oct 20, 2022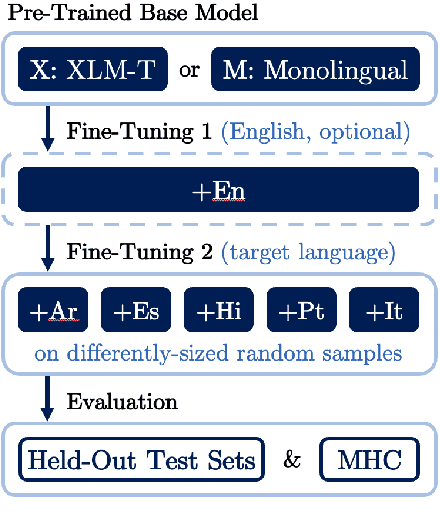
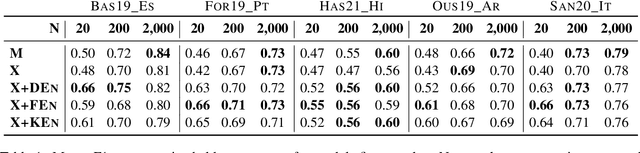
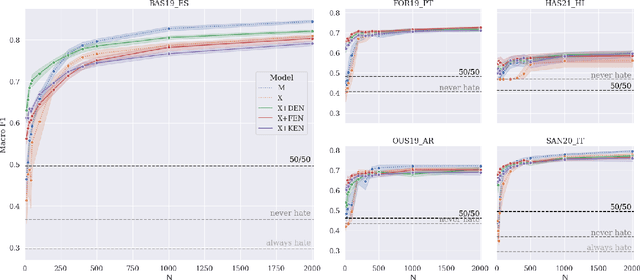
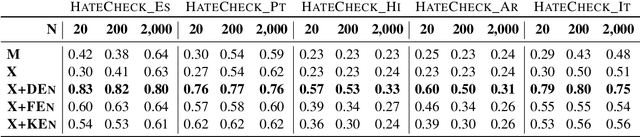
Hate speech is a global phenomenon, but most hate speech datasets so far focus on English-language content. This hinders the development of more effective hate speech detection models in hundreds of languages spoken by billions across the world. More data is needed, but annotating hateful content is expensive, time-consuming and potentially harmful to annotators. To mitigate these issues, we explore data-efficient strategies for expanding hate speech detection into under-resourced languages. In a series of experiments with mono- and multilingual models across five non-English languages, we find that 1) a small amount of target-language fine-tuning data is needed to achieve strong performance, 2) the benefits of using more such data decrease exponentially, and 3) initial fine-tuning on readily-available English data can partially substitute target-language data and improve model generalisability. Based on these findings, we formulate actionable recommendations for hate speech detection in low-resource language settings.
Fairness in Forecasting of Observations of Linear Dynamical Systems
Sep 16, 2022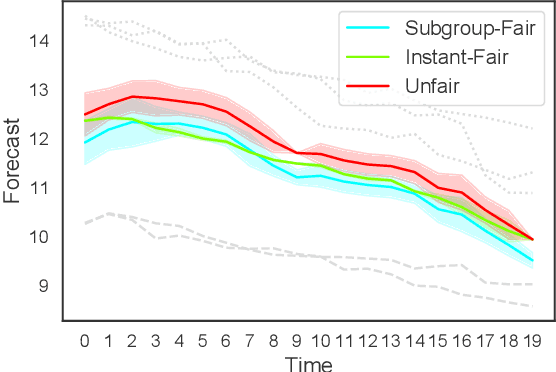
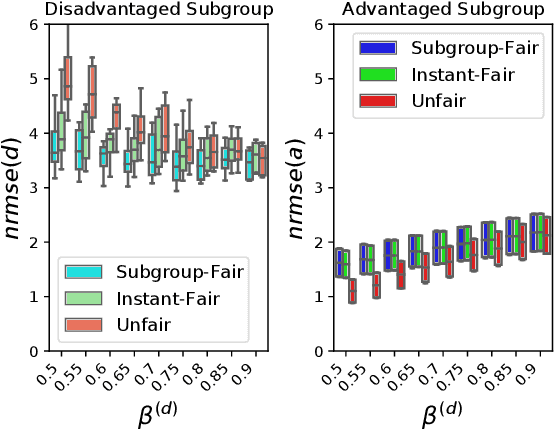
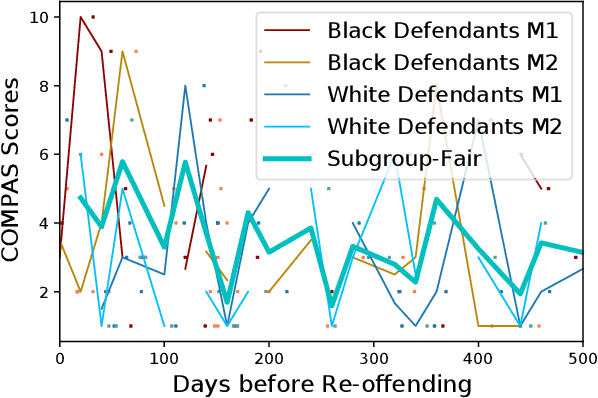
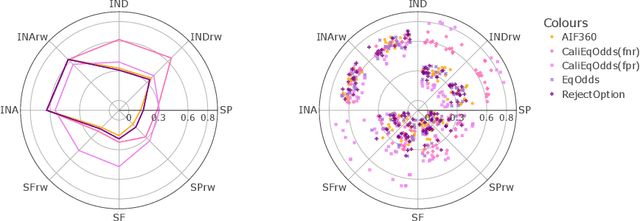
In machine learning, training data often capture the behaviour of multiple subgroups of some underlying human population. When the nature of training data for subgroups are not controlled carefully, under-representation bias arises. To counter this effect we introduce two natural notions of subgroup fairness and instantaneous fairness to address such under-representation bias in time-series forecasting problems. Here we show globally convergent methods for the fairness-constrained learning problems using hierarchies of convexifications of non-commutative polynomial optimisation problems. Our empirical results on a biased data set motivated by insurance applications and the well-known COMPAS data set demonstrate the efficacy of our methods. We also show that by exploiting sparsity in the convexifications, we can reduce the run time of our methods considerably.
Forecasting Patient Flows with Pandemic Induced Concept Drift using Explainable Machine Learning
Nov 01, 2022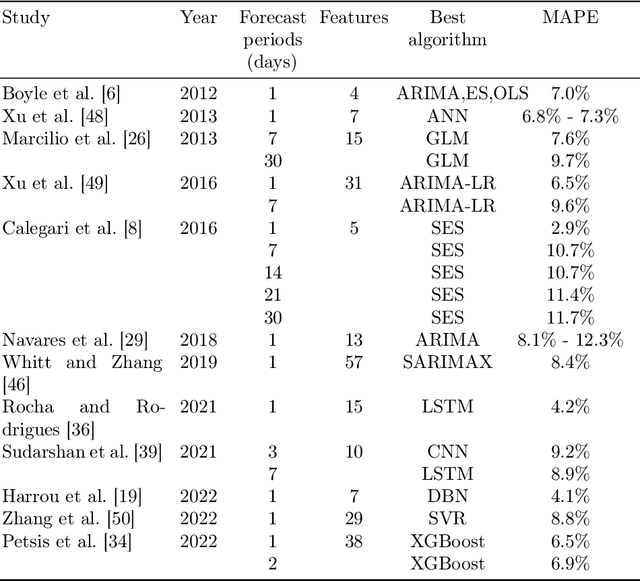
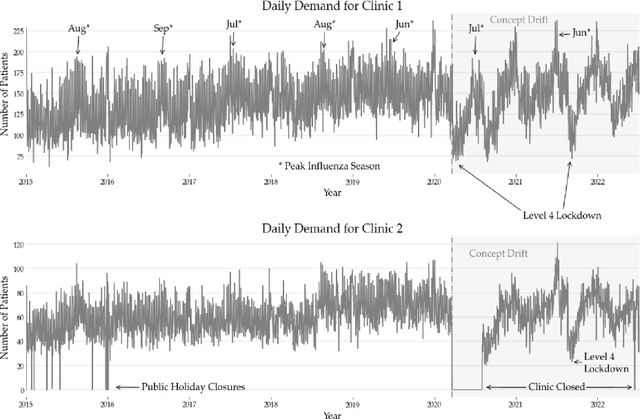

Accurately forecasting patient arrivals at Urgent Care Clinics (UCCs) and Emergency Departments (EDs) is important for effective resourcing and patient care. However, correctly estimating patient flows is not straightforward since it depends on many drivers. The predictability of patient arrivals has recently been further complicated by the COVID-19 pandemic conditions and the resulting lockdowns. This study investigates how a suite of novel quasi-real-time variables like Google search terms, pedestrian traffic, the prevailing incidence levels of influenza, as well as the COVID-19 Alert Level indicators can both generally improve the forecasting models of patient flows and effectively adapt the models to the unfolding disruptions of pandemic conditions. This research also uniquely contributes to the body of work in this domain by employing tools from the eXplainable AI field to investigate more deeply the internal mechanics of the models than has previously been done. The Voting ensemble-based method combining machine learning and statistical techniques was the most reliable in our experiments. Our study showed that the prevailing COVID-19 Alert Level feature together with Google search terms and pedestrian traffic were effective at producing generalisable forecasts. The implications of this study are that proxy variables can effectively augment standard autoregressive features to ensure accurate forecasting of patient flows. The experiments showed that the proposed features are potentially effective model inputs for preserving forecast accuracies in the event of future pandemic outbreaks.
Pi theorem formulation of flood mapping
Nov 01, 2022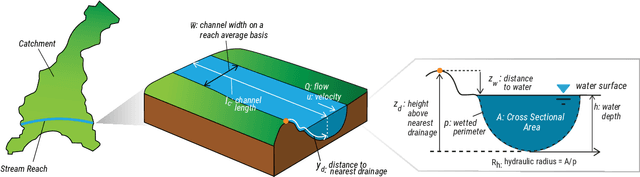
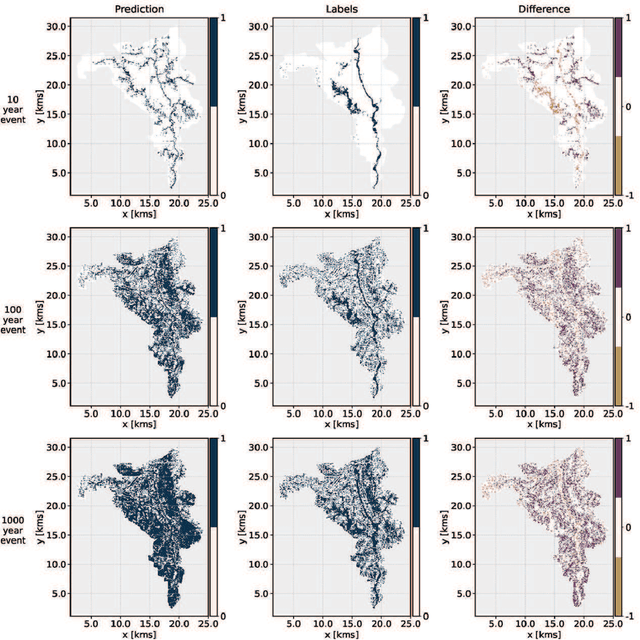
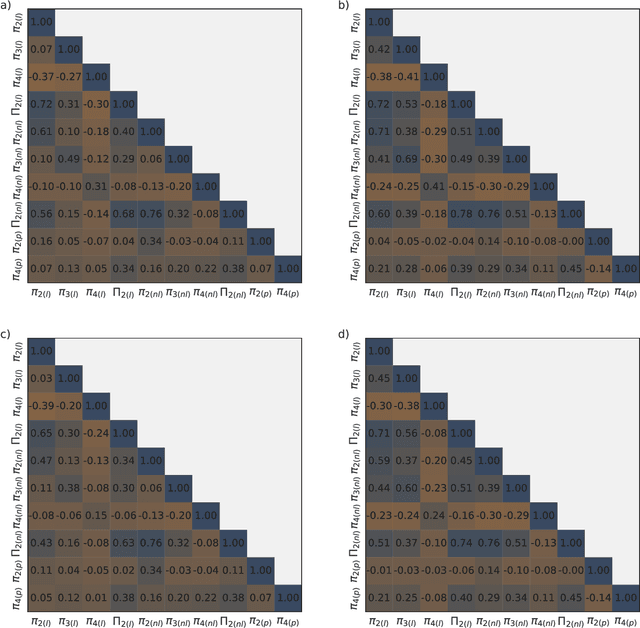
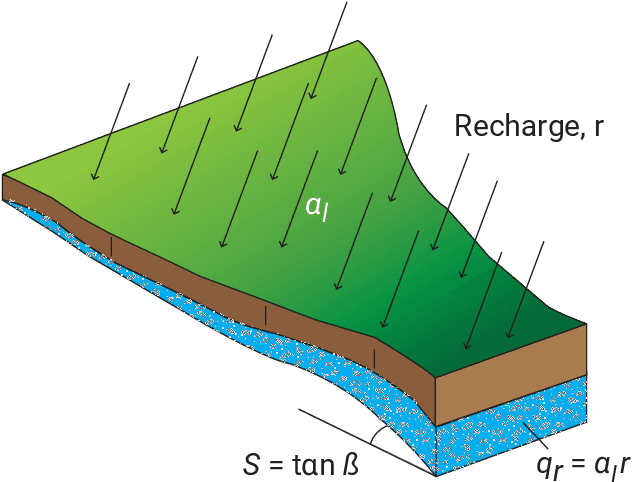
While physical phenomena are stated in terms of physical laws that are homogeneous in all dimensions, the mechanisms and patterns of the physical phenomena are independent of the form of the units describing the physical process. Accordingly, across different conditions, the similarity of a process may be captured through a dimensionless reformulation of the physical problem with Buckingham $\Pi$ theorem. Here, we apply Buckingham $\Pi$ theorem for creating dimensionless indices for capturing the similarity of the flood process, and in turn, these indices allow machine learning to map the likelihood of pluvial (flash) flooding over a landscape. In particular, we use these dimensionless predictors with a logistic regression machine learning (ML) model for a probabilistic determination of flood risk. The logistic regression derived flood maps compare well to 2D hydraulic model results that are the basis of the Federal Emergency Management Agency (FEMA) maps. As a result, the indices and logistic regression also provide the potential to expand existing FEMA maps to new (unmapped) areas and a wider spectrum of flood flows and precipitation events. Our results demonstrate that the new dimensionless indices capture the similarity of the flood process across different topographies and climate regions. Consequently, these dimensionless indices may expand observations of flooding (e.g., satellite) to the risk of flooding in new areas, as well as provide a basis for the rapid, real-time estimation of flood risk on a worldwide scale.
Bias and Extrapolation in Markovian Linear Stochastic Approximation with Constant Stepsizes
Oct 03, 2022
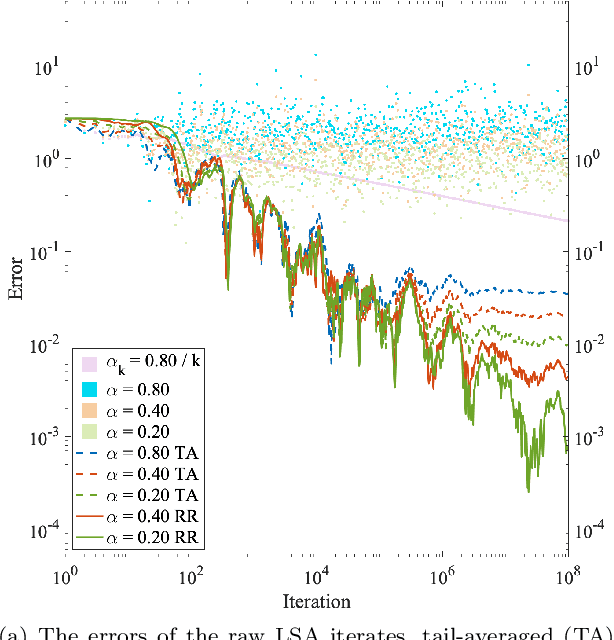
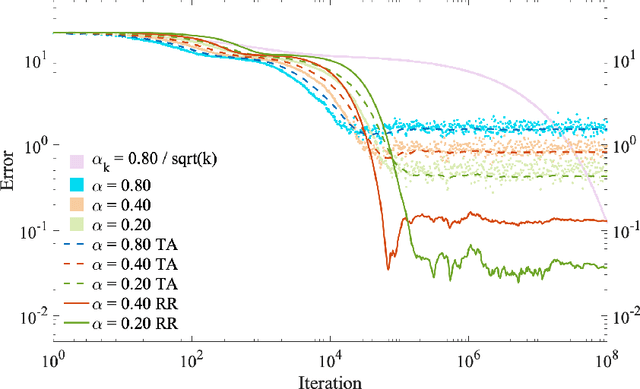
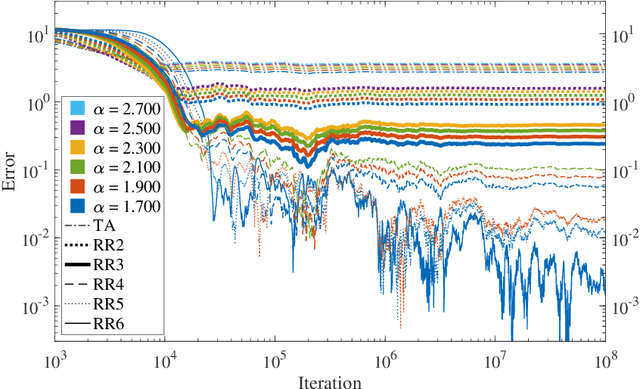
We consider Linear Stochastic Approximation (LSA) with a constant stepsize and Markovian data. Viewing the joint process of the data and LSA iterate as a time-homogeneous Markov chain, we prove its convergence to a unique limiting and stationary distribution in Wasserstein distance and establish non-asymptotic, geometric convergence rates. Furthermore, we show that the bias vector of this limit admits an infinite series expansion with respect to the stepsize. Consequently, the bias is proportional to the stepsize up to higher order terms. This result stands in contrast with LSA under i.i.d. data, for which the bias vanishes. In the reversible chain setting, we provide a general characterization of the relationship between the bias and the mixing time of the Markovian data, establishing that they are roughly proportional to each other. While Polyak-Ruppert tail-averaging reduces the variance of the LSA iterates, it does not affect the bias. The above characterization allows us to show that the bias can be reduced using Richardson-Romberg extrapolation with $m \ge 2$ stepsizes, which eliminates the $m - 1$ leading terms in the bias expansion. This extrapolation scheme leads to an exponentially smaller bias and an improved mean squared error, both in theory and empirically. Our results immediately apply to the Temporal Difference learning algorithm with linear function approximation, Markovian data and constant stepsizes.
Real-time Model Predictive Control and System Identification Using Differentiable Physics Simulation
Feb 20, 2022
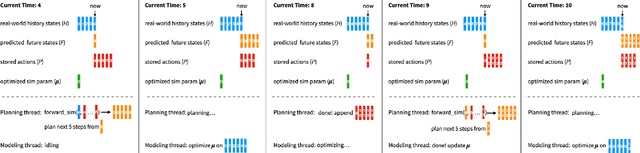
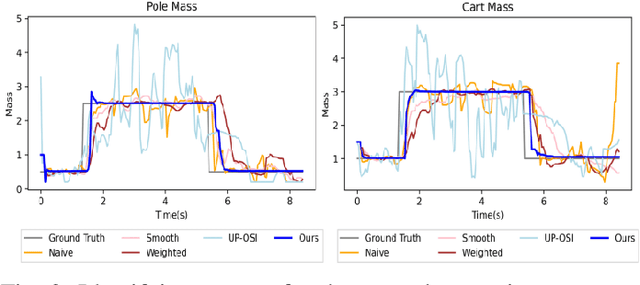
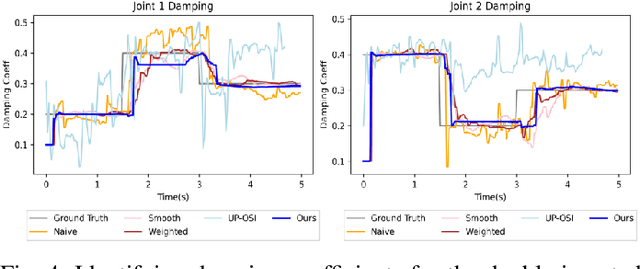
Developing robot controllers in a simulated environment is advantageous but transferring the controllers to the target environment presents challenges, often referred to as the "sim-to-real gap". We present a method for continuous improvement of modeling and control after deploying the robot to a dynamically-changing target environment. We develop a differentiable physics simulation framework that performs online system identification and optimal control simultaneously, using the incoming observations from the target environment in real time. To ensure robust system identification against noisy observations, we devise an algorithm to assess the confidence of our estimated parameters, using numerical analysis of the dynamic equations. To ensure real-time optimal control, we adaptively schedule the optimization window in the future so that the optimized actions can be replenished faster than they are consumed, while staying as up-to-date with new sensor information as possible. The constant re-planning based on a constantly improved model allows the robot to swiftly adapt to the changing environment and utilize real-world data in the most sample-efficient way. Thanks to a fast differentiable physics simulator, the optimization for both system identification and control can be solved efficiently for robots operating in real time. We demonstrate our method on a set of examples in simulation and show that our results are favorable compared to baseline methods.