 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBellman-Taylor Score Decoding for Markov Decision Processes with State-Dependent Feasible Action Sets
Jun 09, 2026Many Markov decision processes (MDPs) in operations research have feasible actions that are state dependent and defined implicitly by various operational constraints. These features make it difficult to use standard deep reinforcement learning (DRL) algorithms, whose action interfaces typically assume either a fixed finite action catalog or a simple Euclidean space. Motivated by a Taylor expansion of the optimal action-value function, we propose Bellman--Taylor score decoding, a framework that moves policy learning to a Euclidean score space while enforcing feasibility through an action decoder. The induced latent-score MDP then can be optimized by standard DRL algorithms without differentiating through the decoder. We provide a performance guarantee showing that the optimality gap of this approach decomposes into a structural approximation error and an algorithmic learning error. Lastly, we apply this framework to a queueing network control problem, where the policy essentially learns a state-dependent index-based dispatching rule. Numerical experiments show near-optimal performance in small instances and considerable improvements over benchmarks in larger systems.
Bias and Extrapolation in Markovian Linear Stochastic Approximation with Constant Stepsizes
Oct 03, 2022
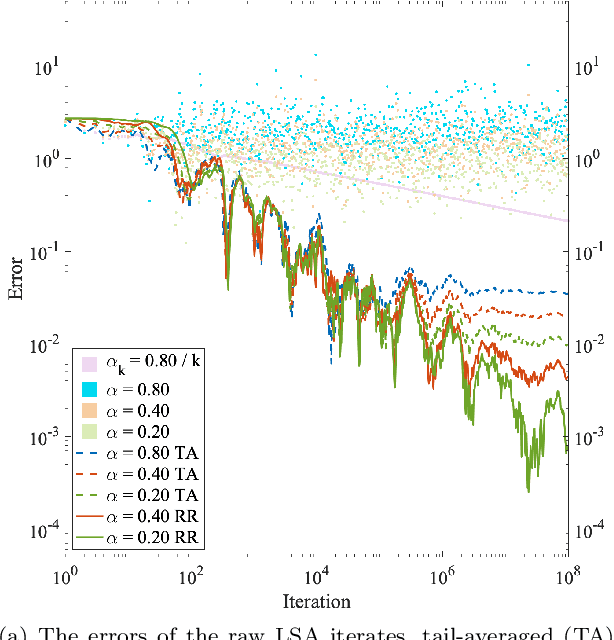
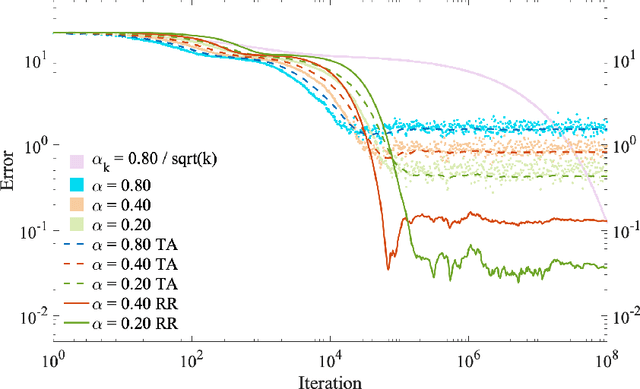
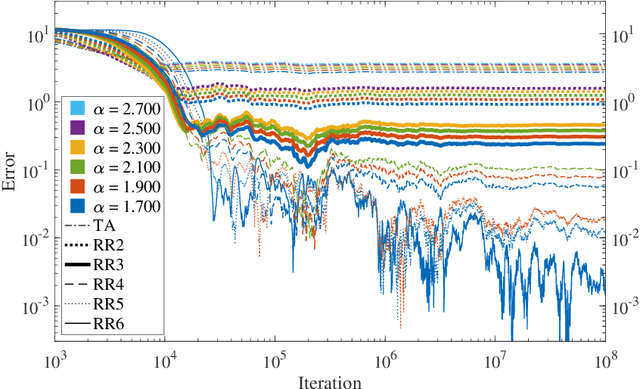
We consider Linear Stochastic Approximation (LSA) with a constant stepsize and Markovian data. Viewing the joint process of the data and LSA iterate as a time-homogeneous Markov chain, we prove its convergence to a unique limiting and stationary distribution in Wasserstein distance and establish non-asymptotic, geometric convergence rates. Furthermore, we show that the bias vector of this limit admits an infinite series expansion with respect to the stepsize. Consequently, the bias is proportional to the stepsize up to higher order terms. This result stands in contrast with LSA under i.i.d. data, for which the bias vanishes. In the reversible chain setting, we provide a general characterization of the relationship between the bias and the mixing time of the Markovian data, establishing that they are roughly proportional to each other. While Polyak-Ruppert tail-averaging reduces the variance of the LSA iterates, it does not affect the bias. The above characterization allows us to show that the bias can be reduced using Richardson-Romberg extrapolation with $m \ge 2$ stepsizes, which eliminates the $m - 1$ leading terms in the bias expansion. This extrapolation scheme leads to an exponentially smaller bias and an improved mean squared error, both in theory and empirically. Our results immediately apply to the Temporal Difference learning algorithm with linear function approximation, Markovian data and constant stepsizes.