 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ProtoX: Explaining a Reinforcement Learning Agent via Prototyping
Nov 06, 2022
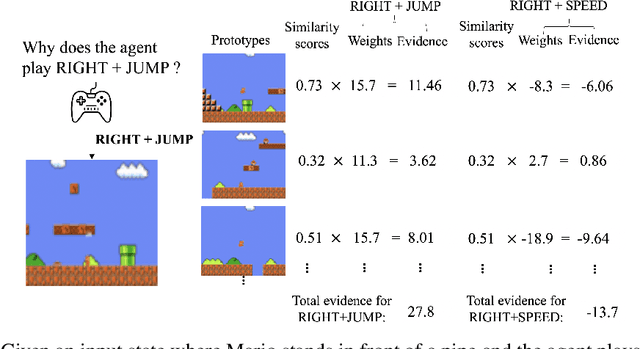
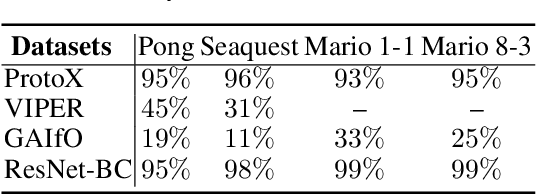
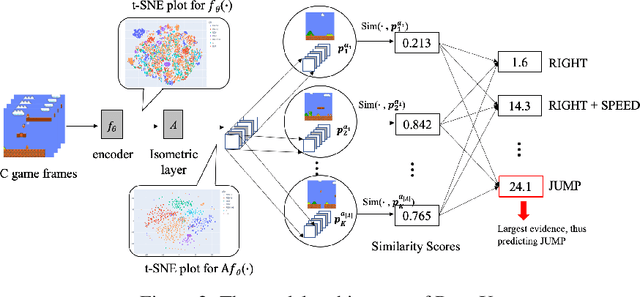

While deep reinforcement learning has proven to be successful in solving control tasks, the "black-box" nature of an agent has received increasing concerns. We propose a prototype-based post-hoc policy explainer, ProtoX, that explains a blackbox agent by prototyping the agent's behaviors into scenarios, each represented by a prototypical state. When learning prototypes, ProtoX considers both visual similarity and scenario similarity. The latter is unique to the reinforcement learning context, since it explains why the same action is taken in visually different states. To teach ProtoX about visual similarity, we pre-train an encoder using contrastive learning via self-supervised learning to recognize states as similar if they occur close together in time and receive the same action from the black-box agent. We then add an isometry layer to allow ProtoX to adapt scenario similarity to the downstream task. ProtoX is trained via imitation learning using behavior cloning, and thus requires no access to the environment or agent. In addition to explanation fidelity, we design different prototype shaping terms in the objective function to encourage better interpretability. We conduct various experiments to test ProtoX. Results show that ProtoX achieved high fidelity to the original black-box agent while providing meaningful and understandable explanations.
Evaluating Digital Tools for Sustainable Agriculture using Causal Inference
Nov 06, 2022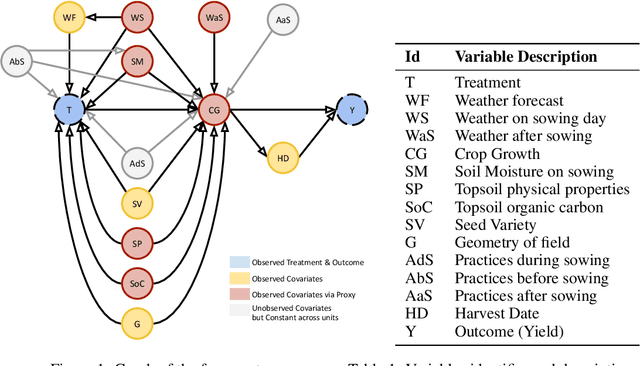
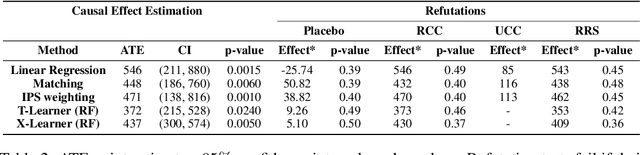

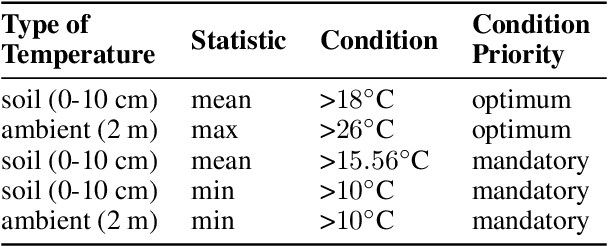
In contrast to the rapid digitalization of several industries, agriculture suffers from low adoption of climate-smart farming tools. Even though AI-driven digital agriculture can offer high-performing predictive functionalities, it lacks tangible quantitative evidence on its benefits to the farmers. Field experiments can derive such evidence, but are often costly and time consuming. To this end, we propose an observational causal inference framework for the empirical evaluation of the impact of digital tools on target farm performance indicators. This way, we can increase farmers' trust by enhancing the transparency of the digital agriculture market, and in turn accelerate the adoption of technologies that aim to increase productivity and secure a sustainable and resilient agriculture against a changing climate. As a case study, we perform an empirical evaluation of a recommendation system for optimal cotton sowing, which was used by a farmers' cooperative during the growing season of 2021. We leverage agricultural knowledge to develop a causal graph of the farm system, we use the back-door criterion to identify the impact of recommendations on the yield and subsequently estimate it using several methods on observational data. The results show that a field sown according to our recommendations enjoyed a significant increase in yield (12% to 17%).
ONE-NAS: An Online NeuroEvolution based Neural Architecture Search for Time Series Forecasting
Feb 27, 2022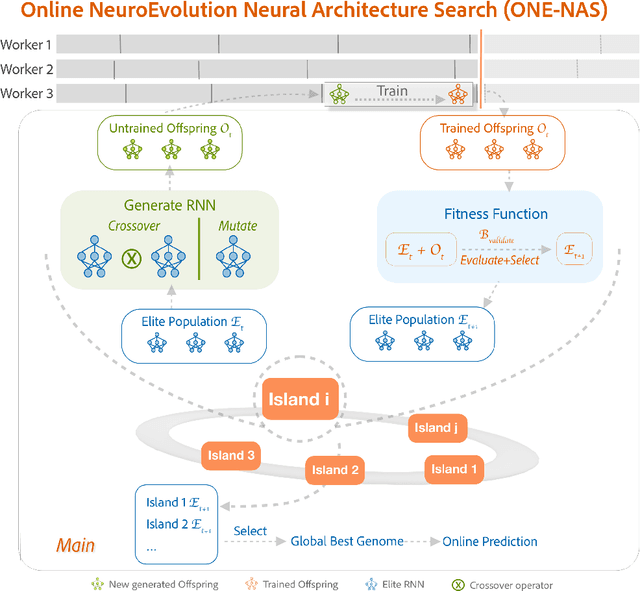
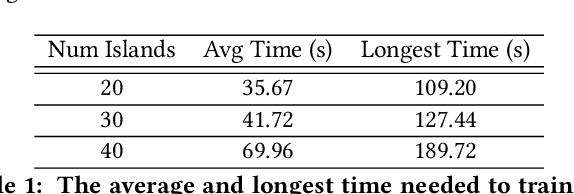

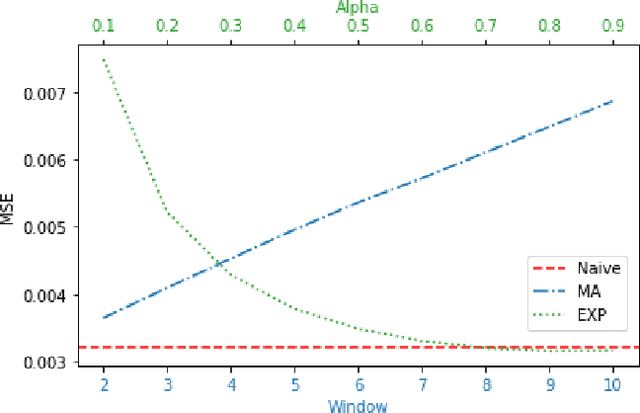
Time series forecasting (TSF) is one of the most important tasks in data science, as accurate time series (TS) predictions can drive and advance a wide variety of domains including finance, transportation, health care, and power systems. However, real-world utilization of machine learning (ML) models for TSF suffers due to pretrained models being able to learn and adapt to unpredictable patterns as previously unseen data arrives over longer time scales. To address this, models must be periodically retained or redesigned, which takes significant human and computational resources. This work presents the Online NeuroEvolution based Neural Architecture Search (ONE-NAS) algorithm, which to the authors' knowledge is the first neural architecture search algorithm capable of automatically designing and training new recurrent neural networks (RNNs) in an online setting. Without any pretraining, ONE-NAS utilizes populations of RNNs which are continuously updated with new network structures and weights in response to new multivariate input data. ONE-NAS is tested on real-world large-scale multivariate wind turbine data as well a univariate Dow Jones Industrial Average (DJIA) dataset, and is shown to outperform traditional statistical time series forecasting, including naive, moving average, and exponential smoothing methods, as well as state of the art online ARIMA strategies.
Graph-Augmented Normalizing Flows for Anomaly Detection of Multiple Time Series
Feb 16, 2022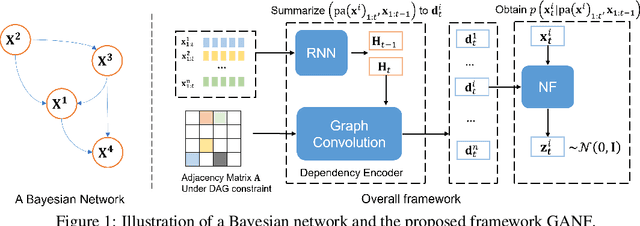

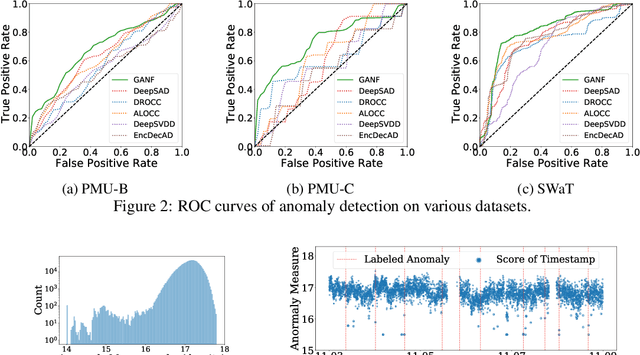
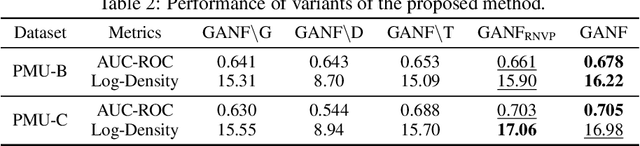
Anomaly detection is a widely studied task for a broad variety of data types; among them, multiple time series appear frequently in applications, including for example, power grids and traffic networks. Detecting anomalies for multiple time series, however, is a challenging subject, owing to the intricate interdependencies among the constituent series. We hypothesize that anomalies occur in low density regions of a distribution and explore the use of normalizing flows for unsupervised anomaly detection, because of their superior quality in density estimation. Moreover, we propose a novel flow model by imposing a Bayesian network among constituent series. A Bayesian network is a directed acyclic graph (DAG) that models causal relationships; it factorizes the joint probability of the series into the product of easy-to-evaluate conditional probabilities. We call such a graph-augmented normalizing flow approach GANF and propose joint estimation of the DAG with flow parameters. We conduct extensive experiments on real-world datasets and demonstrate the effectiveness of GANF for density estimation, anomaly detection, and identification of time series distribution drift.
AutoCTS: Automated Correlated Time Series Forecasting -- Extended Version
Dec 21, 2021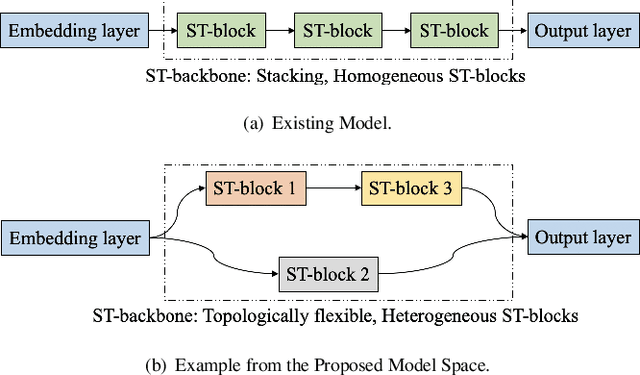
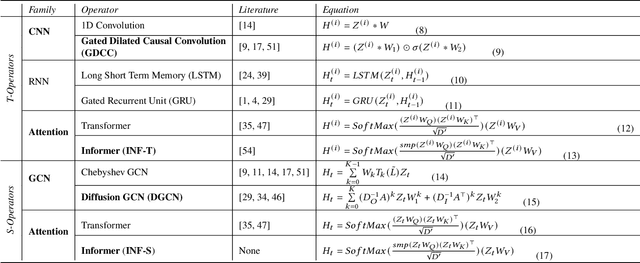
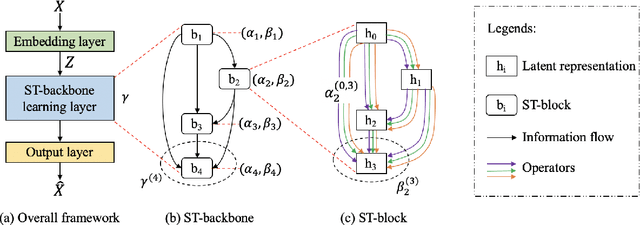

Correlated time series (CTS) forecasting plays an essential role in many cyber-physical systems, where multiple sensors emit time series that capture interconnected processes. Solutions based on deep learning that deliver state-of-the-art CTS forecasting performance employ a variety of spatio-temporal (ST) blocks that are able to model temporal dependencies and spatial correlations among time series. However, two challenges remain. First, ST-blocks are designed manually, which is time consuming and costly. Second, existing forecasting models simply stack the same ST-blocks multiple times, which limits the model potential. To address these challenges, we propose AutoCTS that is able to automatically identify highly competitive ST-blocks as well as forecasting models with heterogeneous ST-blocks connected using diverse topologies, as opposed to the same ST-blocks connected using simple stacking. Specifically, we design both a micro and a macro search space to model possible architectures of ST-blocks and the connections among heterogeneous ST-blocks, and we provide a search strategy that is able to jointly explore the search spaces to identify optimal forecasting models. Extensive experiments on eight commonly used CTS forecasting benchmark datasets justify our design choices and demonstrate that AutoCTS is capable of automatically discovering forecasting models that outperform state-of-the-art human-designed models. This is an extended version of ``AutoCTS: Automated Correlated Time Series Forecasting'', to appear in PVLDB 2022.
A Greek Parliament Proceedings Dataset for Computational Linguistics and Political Analysis
Oct 23, 2022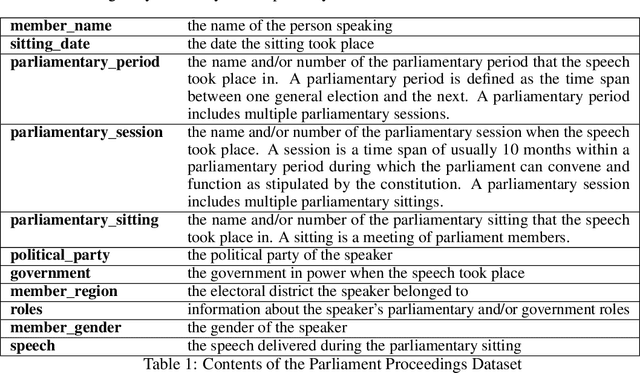
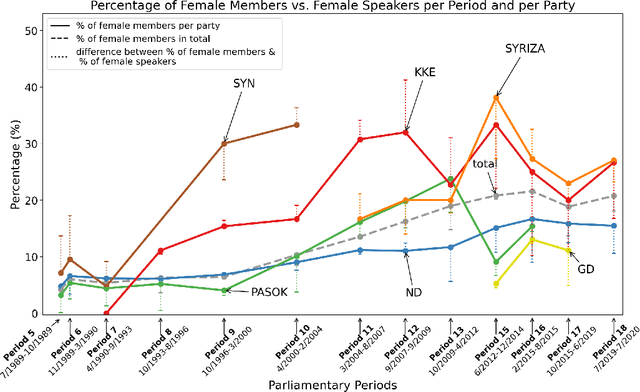
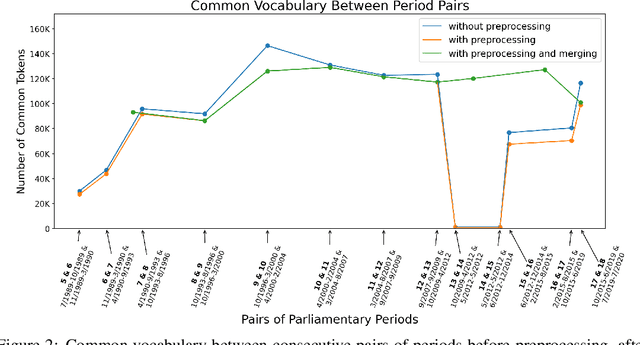

Large, diachronic datasets of political discourse are hard to come across, especially for resource-lean languages such as Greek. In this paper, we introduce a curated dataset of the Greek Parliament Proceedings that extends chronologically from 1989 up to 2020. It consists of more than 1 million speeches with extensive metadata, extracted from 5,355 parliamentary record files. We explain how it was constructed and the challenges that we had to overcome. The dataset can be used for both computational linguistics and political analysis-ideally, combining the two. We present such an application, showing (i) how the dataset can be used to study the change of word usage through time, (ii) between significant historical events and political parties, (iii) by evaluating and employing algorithms for detecting semantic shifts.
AU-Aware Vision Transformers for Biased Facial Expression Recognition
Nov 12, 2022
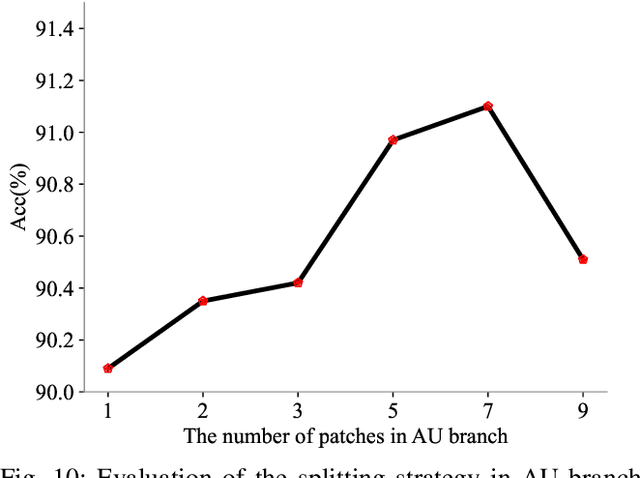

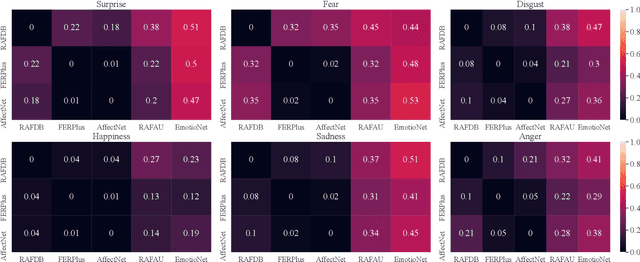
Studies have proven that domain bias and label bias exist in different Facial Expression Recognition (FER) datasets, making it hard to improve the performance of a specific dataset by adding other datasets. For the FER bias issue, recent researches mainly focus on the cross-domain issue with advanced domain adaption algorithms. This paper addresses another problem: how to boost FER performance by leveraging cross-domain datasets. Unlike the coarse and biased expression label, the facial Action Unit (AU) is fine-grained and objective suggested by psychological studies. Motivated by this, we resort to the AU information of different FER datasets for performance boosting and make contributions as follows. First, we experimentally show that the naive joint training of multiple FER datasets is harmful to the FER performance of individual datasets. We further introduce expression-specific mean images and AU cosine distances to measure FER dataset bias. This novel measurement shows consistent conclusions with experimental degradation of joint training. Second, we propose a simple yet conceptually-new framework, AU-aware Vision Transformer (AU-ViT). It improves the performance of individual datasets by jointly training auxiliary datasets with AU or pseudo-AU labels. We also find that the AU-ViT is robust to real-world occlusions. Moreover, for the first time, we prove that a carefully-initialized ViT achieves comparable performance to advanced deep convolutional networks. Our AU-ViT achieves state-of-the-art performance on three popular datasets, namely 91.10% on RAF-DB, 65.59% on AffectNet, and 90.15% on FERPlus. The code and models will be released soon.
ClassActionPrediction: A Challenging Benchmark for Legal Judgment Prediction of Class Action Cases in the US
Nov 01, 2022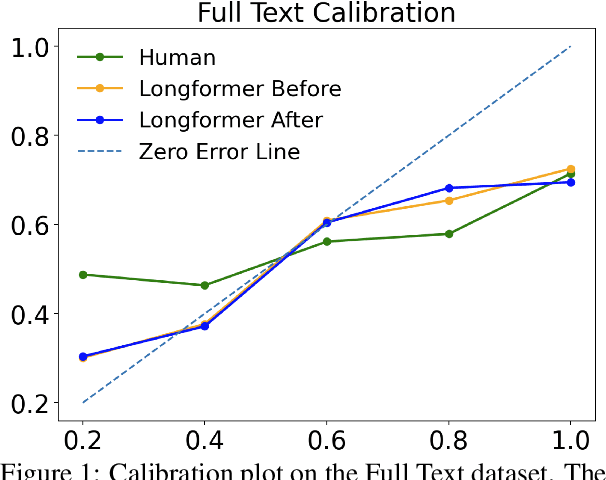
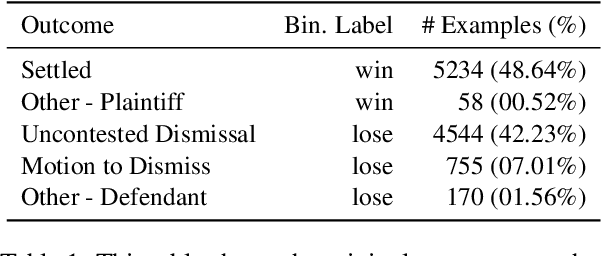
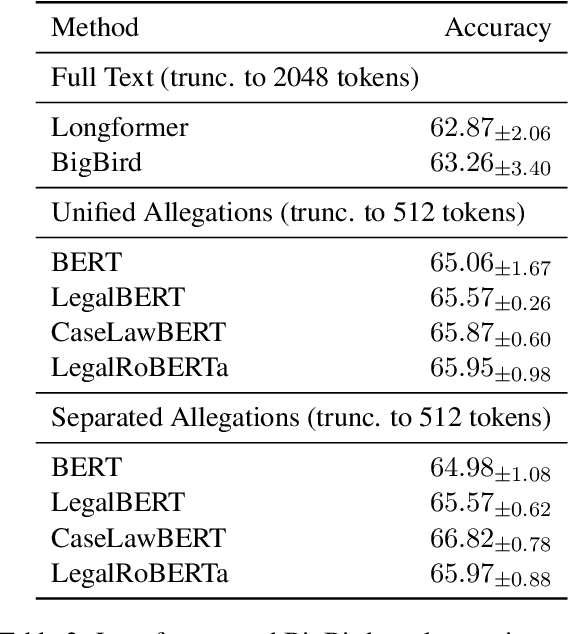
The research field of Legal Natural Language Processing (NLP) has been very active recently, with Legal Judgment Prediction (LJP) becoming one of the most extensively studied tasks. To date, most publicly released LJP datasets originate from countries with civil law. In this work, we release, for the first time, a challenging LJP dataset focused on class action cases in the US. It is the first dataset in the common law system that focuses on the harder and more realistic task involving the complaints as input instead of the often used facts summary written by the court. Additionally, we study the difficulty of the task by collecting expert human predictions, showing that even human experts can only reach 53% accuracy on this dataset. Our Longformer model clearly outperforms the human baseline (63%), despite only considering the first 2,048 tokens. Furthermore, we perform a detailed error analysis and find that the Longformer model is significantly better calibrated than the human experts. Finally, we publicly release the dataset and the code used for the experiments.
Over-the-Air Computation for Distributed Systems: Something Old and Something New
Nov 01, 2022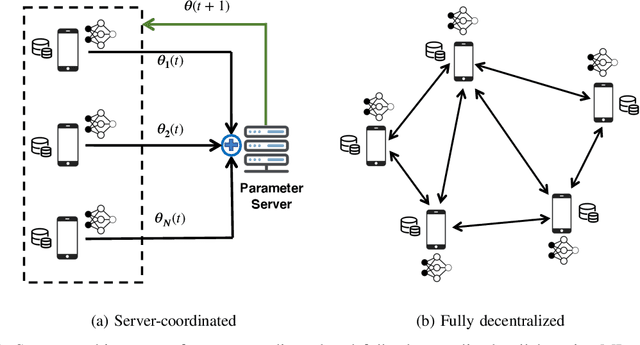
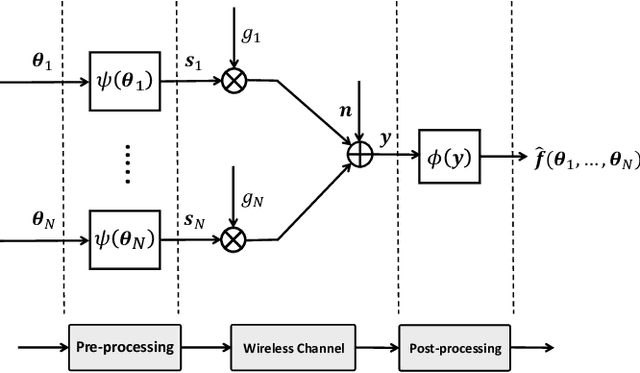

Facing the upcoming era of Internet-of-Things and connected intelligence, efficient information processing, computation and communication design becomes a key challenge in large-scale intelligent systems. Recently, Over-the-Air (OtA) computation has been proposed for data aggregation and distributed function computation over a large set of network nodes. Theoretical foundations for this concept exist for a long time, but it was mainly investigated within the context of wireless sensor networks. There are still many open questions when applying OtA computation in different types of distributed systems where modern wireless communication technology is applied. In this article, we provide a comprehensive overview of the OtA computation principle and its applications in distributed learning, control, and inference systems, for both server-coordinated and fully decentralized architectures. Particularly, we highlight the importance of the statistical heterogeneity of data and wireless channels, the temporal evolution of model updates, and the choice of performance metrics, for the communication design in OtA federated learning (FL) systems. Several key challenges in privacy, security and robustness aspects of OtA FL are also identified for further investigation.
Non-line-of-sight imaging with arbitrary illumination and detection pattern
Nov 01, 2022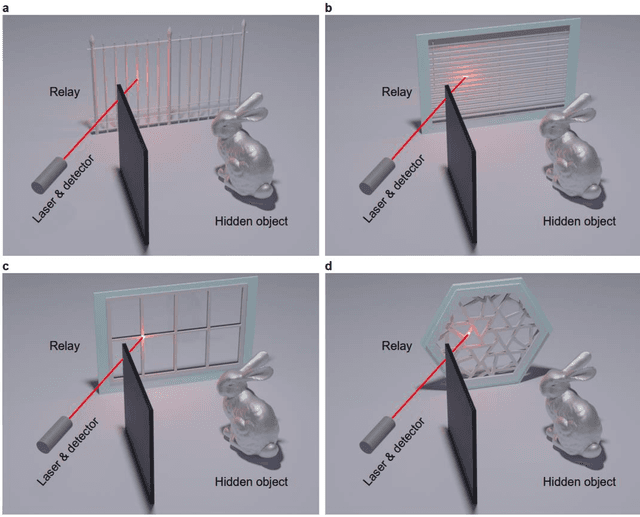
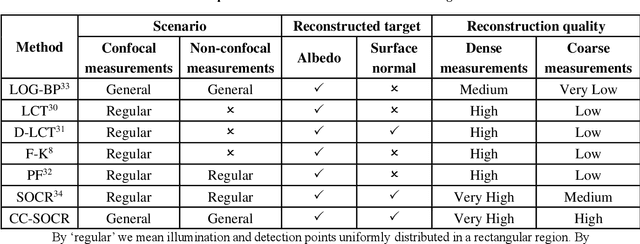
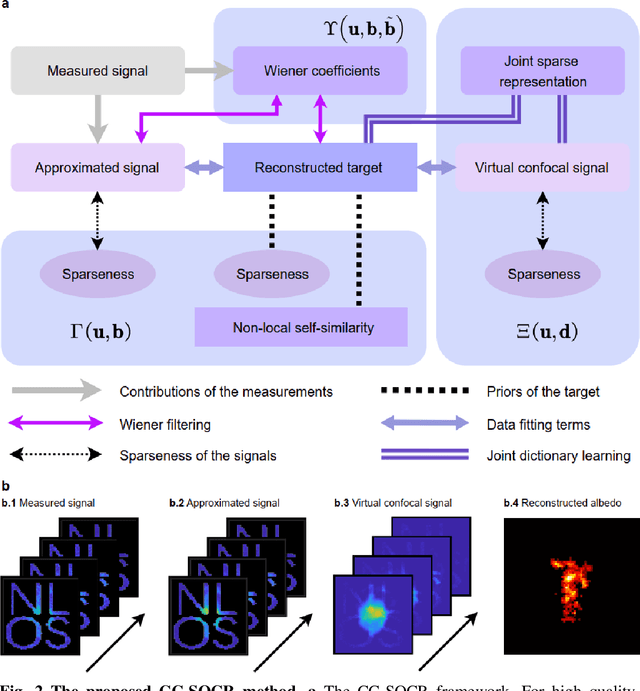
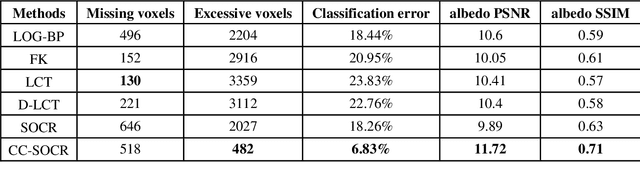
Non-line-of-sight (NLOS) imaging aims at reconstructing targets obscured from the direct line of sight. Existing NLOS imaging algorithms require dense measurements at rectangular grid points in a large area of the relay surface, which severely hinders their availability to variable relay scenarios in practical applications such as robotic vision, autonomous driving, rescue operations and remote sensing. In this work, we propose a Bayesian framework for NLOS imaging with no specific requirements on the spatial pattern of illumination and detection points. By introducing virtual confocal signals, we design a confocal complemented signal-object collaborative regularization (CC-SOCR) algorithm for high quality reconstructions. Our approach is capable of reconstructing both albedo and surface normal of the hidden objects with fine details under the most general relay setting. Moreover, with a regular relay surface, coarse rather than dense measurements are enough for our approach such that the acquisition time can be reduced significantly. As demonstrated in multiple experiments, the new framework substantially enhances the applicability of NLOS imaging.