 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improvements & Evaluations on the MLCommons CloudMask Benchmark
Mar 07, 2024

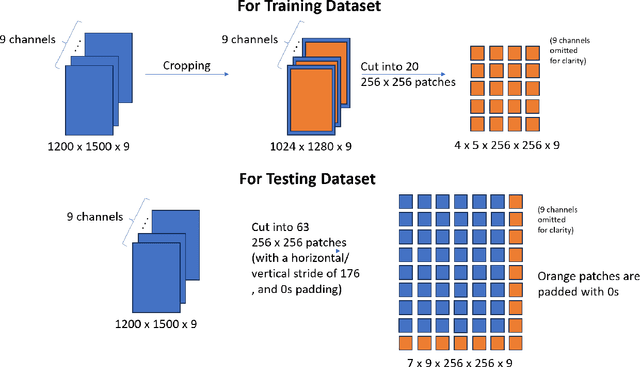
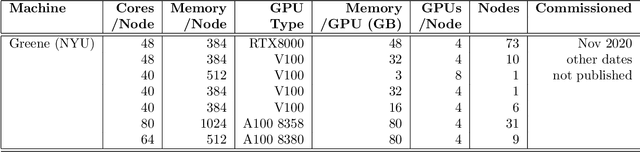
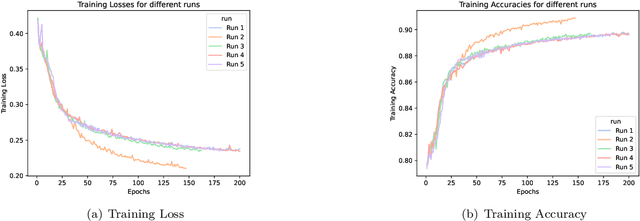
In this paper, we report the performance benchmarking results of deep learning models on MLCommons' Science cloud-masking benchmark using a high-performance computing cluster at New York University (NYU): NYU Greene. MLCommons is a consortium that develops and maintains several scientific benchmarks that can benefit from developments in AI. We provide a description of the cloud-masking benchmark task, updated code, and the best model for this benchmark when using our selected hyperparameter settings. Our benchmarking results include the highest accuracy achieved on the NYU system as well as the average time taken for both training and inference on the benchmark across several runs/seeds. Our code can be found on GitHub. MLCommons team has been kept informed about our progress and may use the developed code for their future work.
Finding Waldo: Towards Efficient Exploration of NeRF Scene Spaces
Mar 08, 2024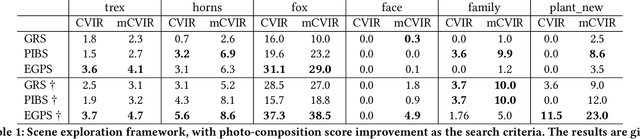

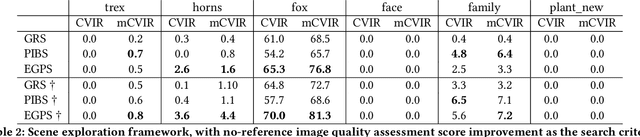

Neural Radiance Fields (NeRF) have quickly become the primary approach for 3D reconstruction and novel view synthesis in recent years due to their remarkable performance. Despite the huge interest in NeRF methods, a practical use case of NeRFs has largely been ignored; the exploration of the scene space modelled by a NeRF. In this paper, for the first time in the literature, we propose and formally define the scene exploration framework as the efficient discovery of NeRF model inputs (i.e. coordinates and viewing angles), using which one can render novel views that adhere to user-selected criteria. To remedy the lack of approaches addressing scene exploration, we first propose two baseline methods called Guided-Random Search (GRS) and Pose Interpolation-based Search (PIBS). We then cast scene exploration as an optimization problem, and propose the criteria-agnostic Evolution-Guided Pose Search (EGPS) for efficient exploration. We test all three approaches with various criteria (e.g. saliency maximization, image quality maximization, photo-composition quality improvement) and show that our EGPS performs more favourably than other baselines. We finally highlight key points and limitations, and outline directions for future research in scene exploration.
MamMIL: Multiple Instance Learning for Whole Slide Images with State Space Models
Mar 08, 2024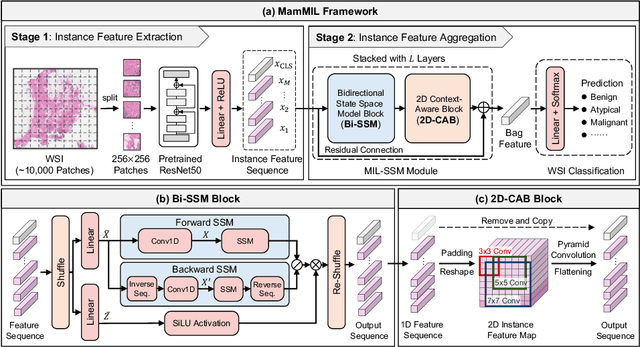
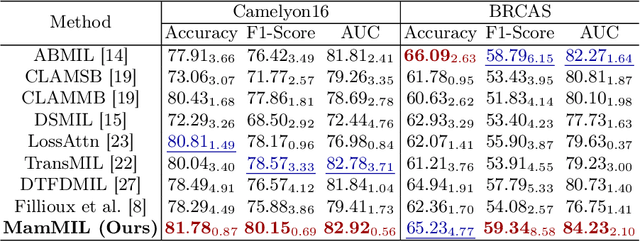
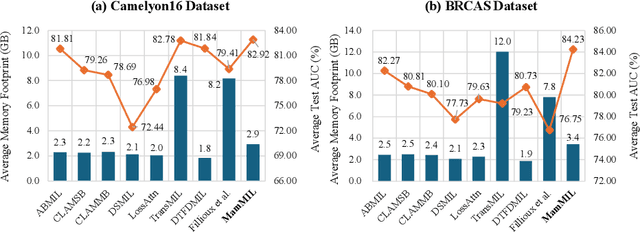
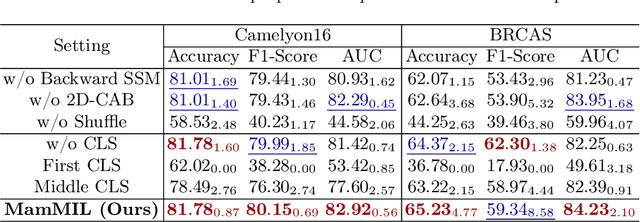
Recently, pathological diagnosis, the gold standard for cancer diagnosis, has achieved superior performance by combining the Transformer with the multiple instance learning (MIL) framework using whole slide images (WSIs). However, the giga-pixel nature of WSIs poses a great challenge for the quadratic-complexity self-attention mechanism in Transformer to be applied in MIL. Existing studies usually use linear attention to improve computing efficiency but inevitably bring performance bottlenecks. To tackle this challenge, we propose a MamMIL framework for WSI classification by cooperating the selective structured state space model (i.e., Mamba) with MIL for the first time, enabling the modeling of instance dependencies while maintaining linear complexity. Specifically, to solve the problem that Mamba can only conduct unidirectional one-dimensional (1D) sequence modeling, we innovatively introduce a bidirectional state space model and a 2D context-aware block to enable MamMIL to learn the bidirectional instance dependencies with 2D spatial relationships. Experiments on two datasets show that MamMIL can achieve advanced classification performance with smaller memory footprints than the state-of-the-art MIL frameworks based on the Transformer. The code will be open-sourced if accepted.
Prepared for the Worst: A Learning-Based Adversarial Attack for Resilience Analysis of the ICP Algorithm
Mar 08, 2024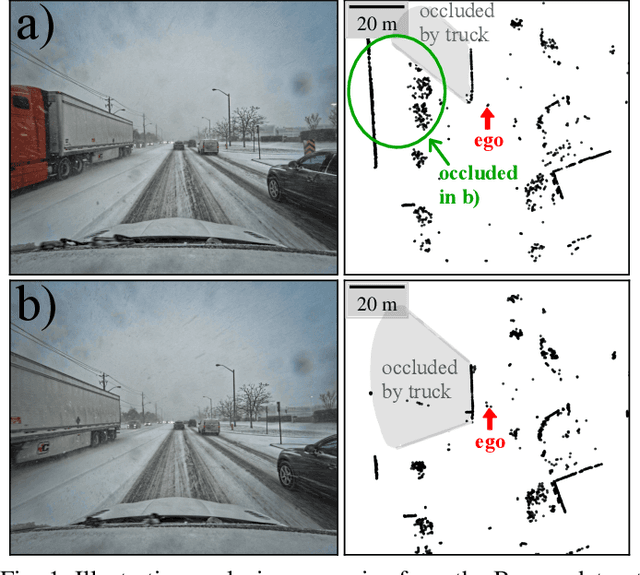
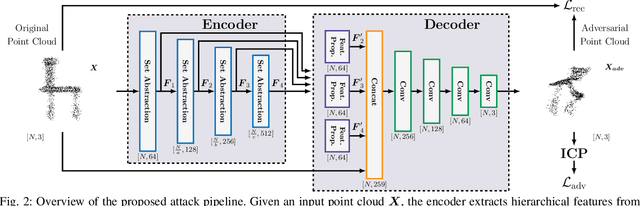
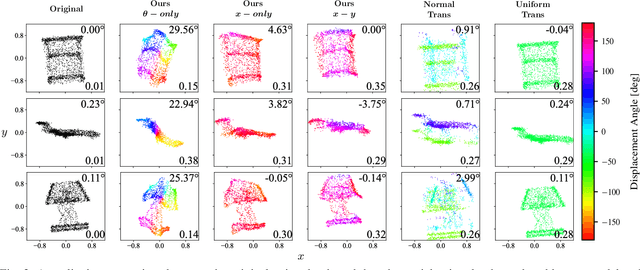
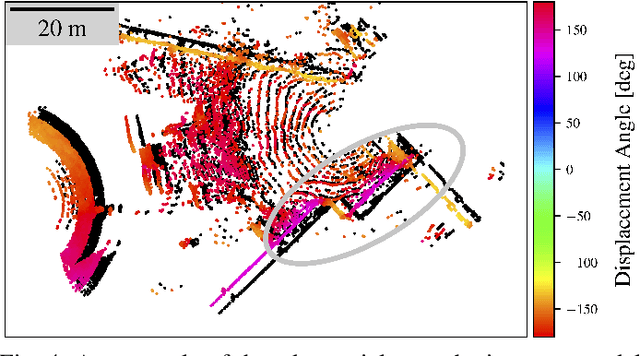
This paper presents a novel method to assess the resilience of the Iterative Closest Point (ICP) algorithm via deep-learning-based attacks on lidar point clouds. For safety-critical applications such as autonomous navigation, ensuring the resilience of algorithms prior to deployments is of utmost importance. The ICP algorithm has become the standard for lidar-based localization. However, the pose estimate it produces can be greatly affected by corruption in the measurements. Corruption can arise from a variety of scenarios such as occlusions, adverse weather, or mechanical issues in the sensor. Unfortunately, the complex and iterative nature of ICP makes assessing its resilience to corruption challenging. While there have been efforts to create challenging datasets and develop simulations to evaluate the resilience of ICP empirically, our method focuses on finding the maximum possible ICP pose error using perturbation-based adversarial attacks. The proposed attack induces significant pose errors on ICP and outperforms baselines more than 88% of the time across a wide range of scenarios. As an example application, we demonstrate that our attack can be used to identify areas on a map where ICP is particularly vulnerable to corruption in the measurements.
Pseudo-inverse reconstruction of bandlimited signals from nonuniform generalized samples with orthogonal kernels
Mar 04, 2024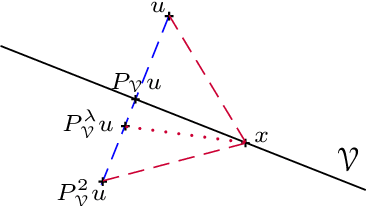
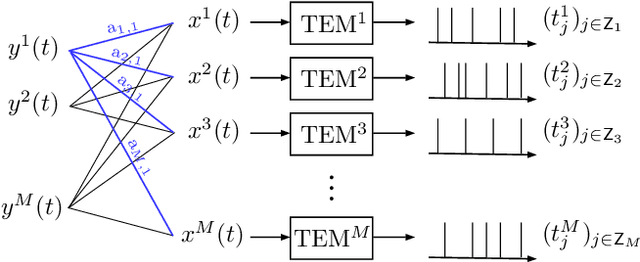
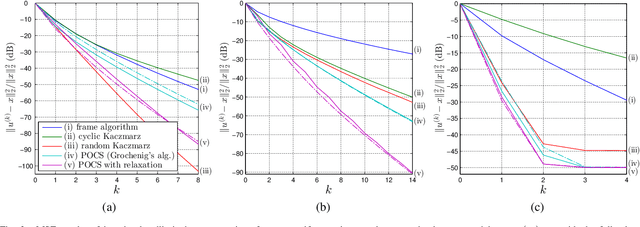
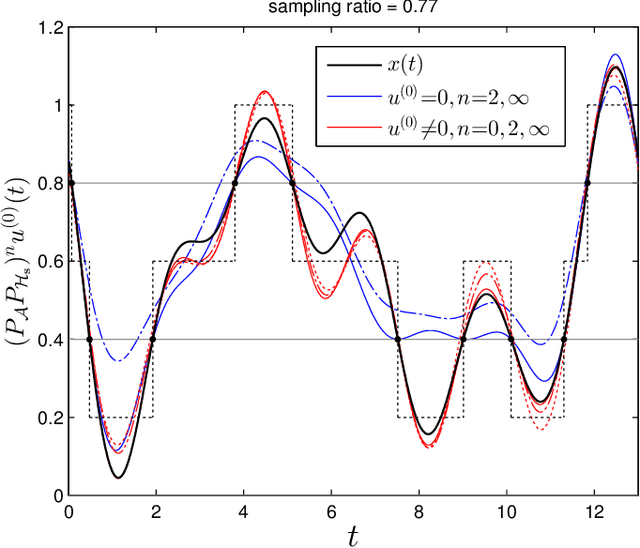
Contrary to the traditional pursuit of research on nonuniform sampling of bandlimited signals, the objective of the present paper is not to find sampling conditions that permit perfect reconstruction, but to perform the best possible signal recovery from any given set of nonuniform samples, whether it is finite as in practice, or infinite to achieve the possibility of unique reconstruction in $L^2({\bf R})$. This leads us to consider the pseudo-inverse of the whole sampling map as a linear operator of Hilbert spaces. We propose in this paper an iterative algorithm that systematically performs this pseudo-inversion under the following conditions: (i) the input lies in some closed space $\cal A$ (such as a space of bandlimited functions); (ii) the samples are formed by inner product of the input with given kernel functions; (iii) these functions are orthogonal at least in a Hilbert space $\cal H$ that is larger than $\cal A$. This situation turns out to appear in certain time encoders that are part of the increasingly important area of event-based sampling. As a result of pseudo-inversion, we systematically achieve perfect reconstruction whenever the samples uniquely characterize the input, we obtain minimal-norm estimates when the sampling is insufficient, and the reconstruction errors are controlled in the case of noisy sampling. The algorithm consists in alternating two projections according to the general method of projections onto convex sets (POCS) and can be implemented by iterating time-varying discrete-time filtering. We finally show that our signal and sampling assumptions appear in a nontrivial manner in other existing problems of data acquisition. This includes multi-channel time encoding where $\cal H$ is of the type $L^2({\bf R})^M$, and traditional point sampling with the adoption of a Sobolev space $\cal H$.
Fusion Encoder Networks
Mar 04, 2024In this paper we present fusion encoder networks (FENs): a class of algorithms for creating neural networks that map sequences to outputs. The resulting neural network has only logarithmic depth (alleviating the degradation of data as it propagates through the network) and can process sequences in linear time (or in logarithmic time with a linear number of processors). The crucial property of FENs is that they learn by training a quasi-linear number of constant-depth feed-forward neural networks in parallel. The fact that these networks have constant depth means that backpropagation works well. We note that currently the performance of FENs is only conjectured as we are yet to implement them.
Non-autoregressive Sequence-to-Sequence Vision-Language Models
Mar 04, 2024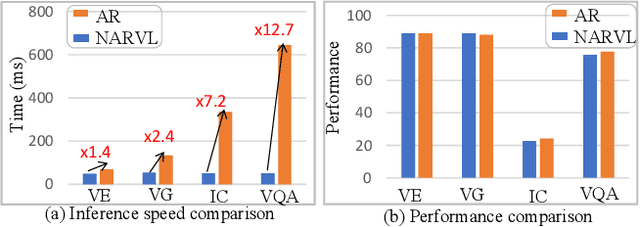
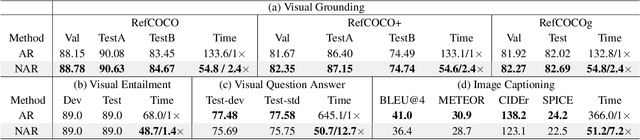
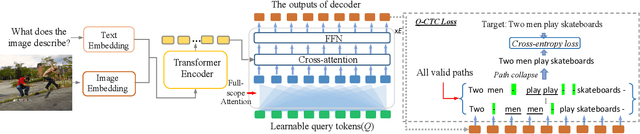
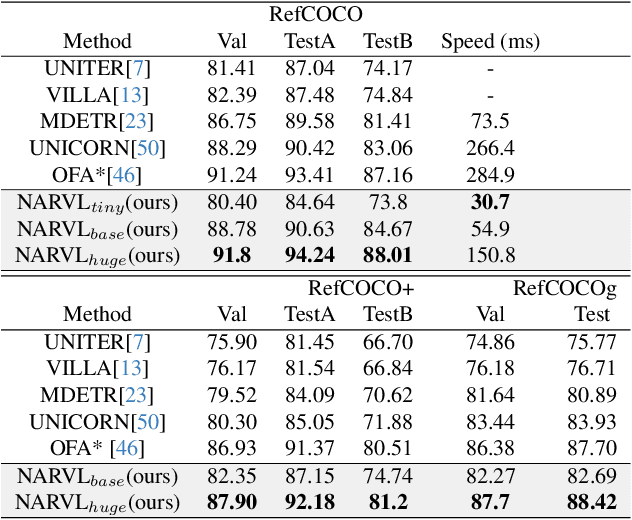
Sequence-to-sequence vision-language models are showing promise, but their applicability is limited by their inference latency due to their autoregressive way of generating predictions. We propose a parallel decoding sequence-to-sequence vision-language model, trained with a Query-CTC loss, that marginalizes over multiple inference paths in the decoder. This allows us to model the joint distribution of tokens, rather than restricting to conditional distribution as in an autoregressive model. The resulting model, NARVL, achieves performance on-par with its state-of-the-art autoregressive counterpart, but is faster at inference time, reducing from the linear complexity associated with the sequential generation of tokens to a paradigm of constant time joint inference.
Exposure-Conscious Path Planning for Equal-Exposure Corridors
Mar 04, 2024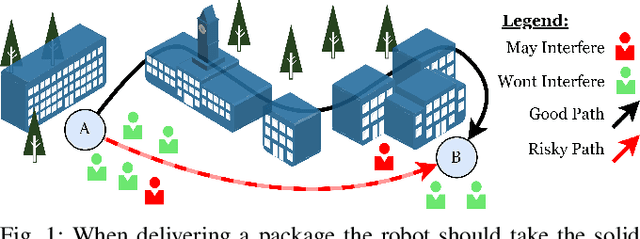
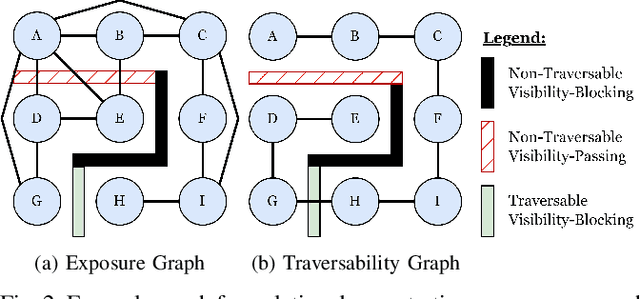
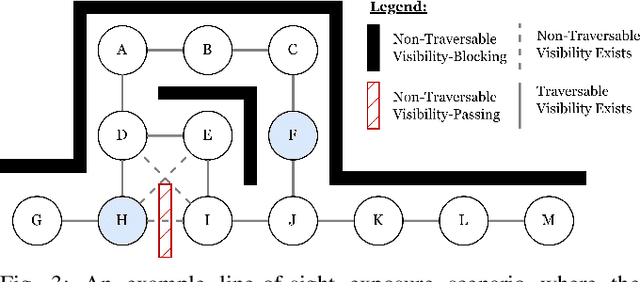
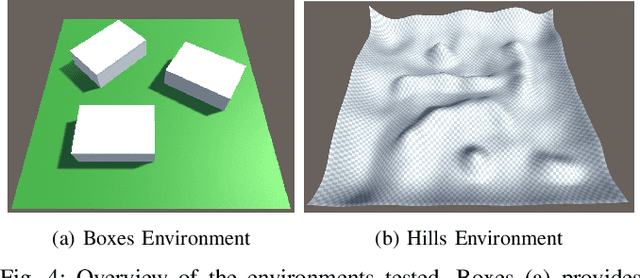
While maximizing line-of-sight coverage of specific regions or agents in the environment is a well explored path planning objective, the converse problem of minimizing exposure to the entire environment during navigation is especially interesting in the context of minimizing detection risk. This work demonstrates that minimizing line-of-sight exposure to the environment is non-Markovian, which cannot be efficiently solved optimally with traditional path planning. The optimality gap of the graph-search algorithm A* and the trade-offs in optimality vs. computation time of several approximating heuristics is explored. Finally, the concept of equal-exposure corridors, which afford polynomial time determination of all paths that do not increase exposure, is presented.
Towards Optimizing Human-Centric Objectives in AI-Assisted Decision-Making With Offline Reinforcement Learning
Mar 09, 2024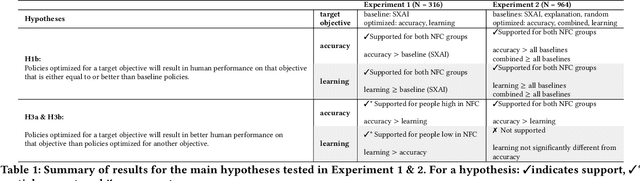
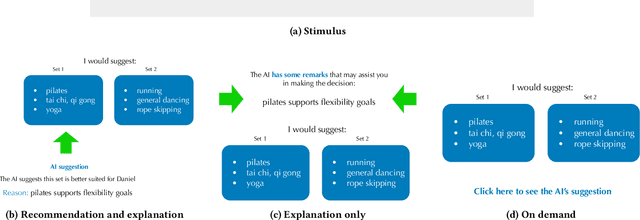
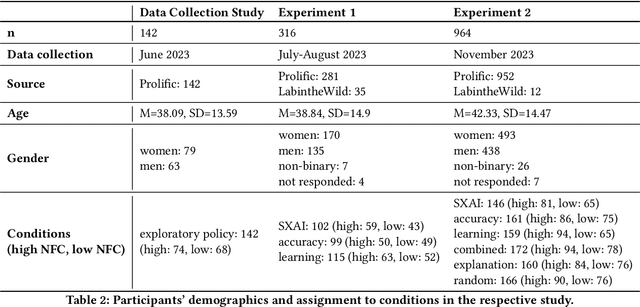
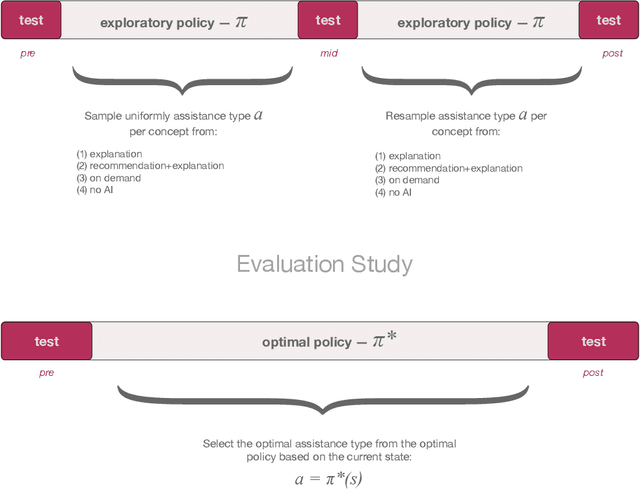
As AI assistance is increasingly infused into decision-making processes, we may seek to optimize human-centric objectives beyond decision accuracy, such as skill improvement or task enjoyment of individuals interacting with these systems. With this aspiration in mind, we propose offline reinforcement learning (RL) as a general approach for modeling human-AI decision-making to optimize such human-centric objectives. Our approach seeks to optimize different objectives by adaptively providing decision support to humans -- the right type of assistance, to the right person, at the right time. We instantiate our approach with two objectives: human-AI accuracy on the decision-making task and human learning about the task, and learn policies that optimize these two objectives from previous human-AI interaction data. We compare the optimized policies against various baselines in AI-assisted decision-making. Across two experiments (N = 316 and N = 964), our results consistently demonstrate that people interacting with policies optimized for accuracy achieve significantly better accuracy -- and even human-AI complementarity -- compared to those interacting with any other type of AI support. Our results further indicate that human learning is more difficult to optimize than accuracy, with participants who interacted with learning-optimized policies showing significant learning improvement only at times. Our research (1) demonstrates offline RL to be a promising approach to model dynamics of human-AI decision-making, leading to policies that may optimize various human-centric objectives and provide novel insights about the AI-assisted decision-making space, and (2) emphasizes the importance of considering human-centric objectives beyond decision accuracy in AI-assisted decision-making, while also opening up the novel research challenge of optimizing such objectives.
Mixed-Strategy Nash Equilibrium for Crowd Navigation
Mar 05, 2024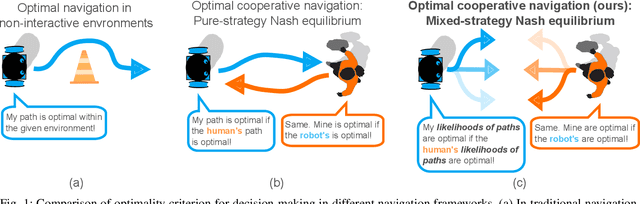
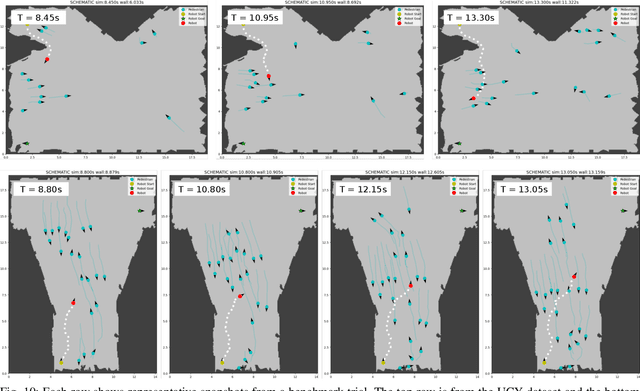
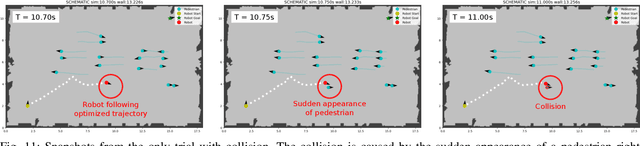
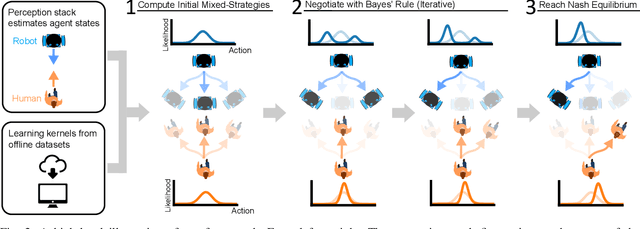
We address the problem of finding mixed-strategy Nash equilibrium for crowd navigation. Mixed-strategy Nash equilibrium provides a rigorous model for the robot to anticipate uncertain yet cooperative human behavior in crowds, but the computation cost is often too high for scalable and real-time decision-making. Here we prove that a simple iterative Bayesian updating scheme converges to the Nash equilibrium of a mixed-strategy social navigation game. Furthermore, we propose a data-driven framework to construct the game by initializing agent strategies as Gaussian processes learned from human datasets. Based on the proposed mixed-strategy Nash equilibrium model, we develop a sampling-based crowd navigation framework that can be integrated into existing navigation methods and runs in real-time on a laptop CPU. We evaluate our framework in both simulated environments and real-world human datasets in unstructured environments. Our framework consistently outperforms both non-learning and learning-based methods on both safety and navigation efficiency and reaches human-level crowd navigation performance on top of a meta-planner.