 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributionally Adaptive Meta Reinforcement Learning
Oct 06, 2022
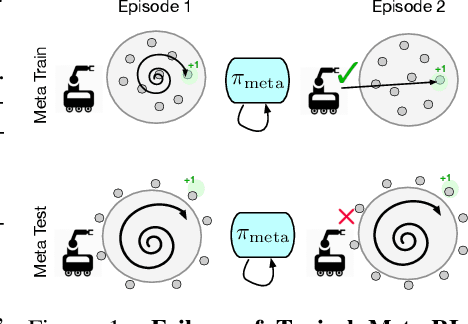

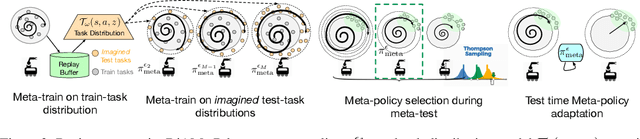
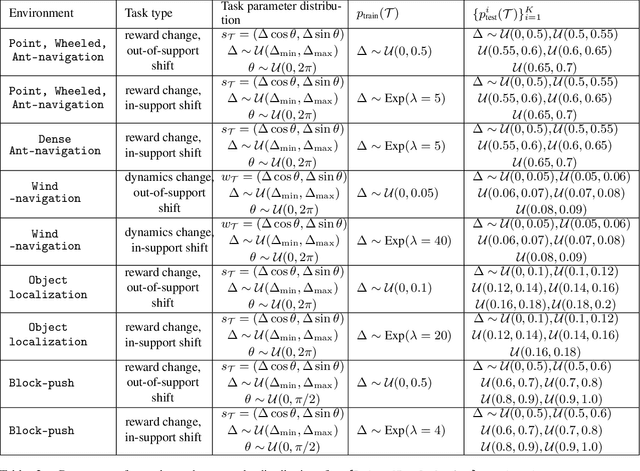
Meta-reinforcement learning algorithms provide a data-driven way to acquire policies that quickly adapt to many tasks with varying rewards or dynamics functions. However, learned meta-policies are often effective only on the exact task distribution on which they were trained and struggle in the presence of distribution shift of test-time rewards or transition dynamics. In this work, we develop a framework for meta-RL algorithms that are able to behave appropriately under test-time distribution shifts in the space of tasks. Our framework centers on an adaptive approach to distributional robustness that trains a population of meta-policies to be robust to varying levels of distribution shift. When evaluated on a potentially shifted test-time distribution of tasks, this allows us to choose the meta-policy with the most appropriate level of robustness, and use it to perform fast adaptation. We formally show how our framework allows for improved regret under distribution shift, and empirically show its efficacy on simulated robotics problems under a wide range of distribution shifts.
Efficient Neural Mapping for Localisation of Unmanned Ground Vehicles
Nov 09, 2022



Global localisation from visual data is a challenging problem applicable to many robotics domains. Prior works have shown that neural networks can be trained to map images of an environment to absolute camera pose within that environment, learning an implicit neural mapping in the process. In this work we evaluate the applicability of such an approach to real-world robotics scenarios, demonstrating that by constraining the problem to 2-dimensions and significantly increasing the quantity of training data, a compact model capable of real-time inference on embedded platforms can be used to achieve localisation accuracy of several centimetres. We deploy our trained model onboard a UGV platform, demonstrating its effectiveness in a waypoint navigation task. Along with this work we will release a novel localisation dataset comprising simulated and real environments, each with training samples numbering in the tens of thousands.
Solving Reasoning Tasks with a Slot Transformer
Oct 20, 2022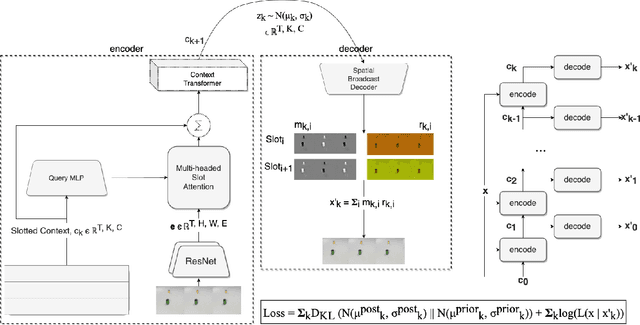
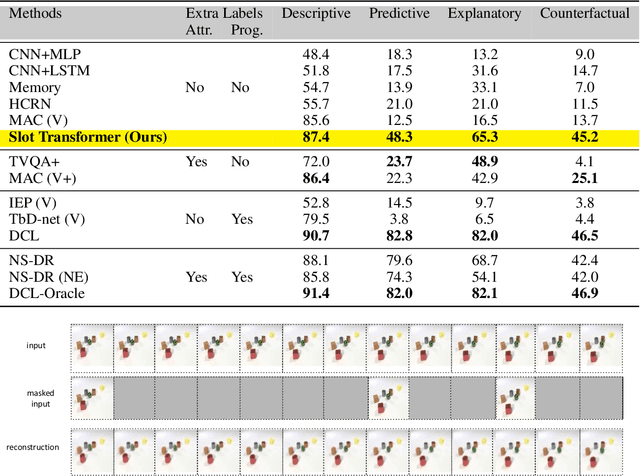
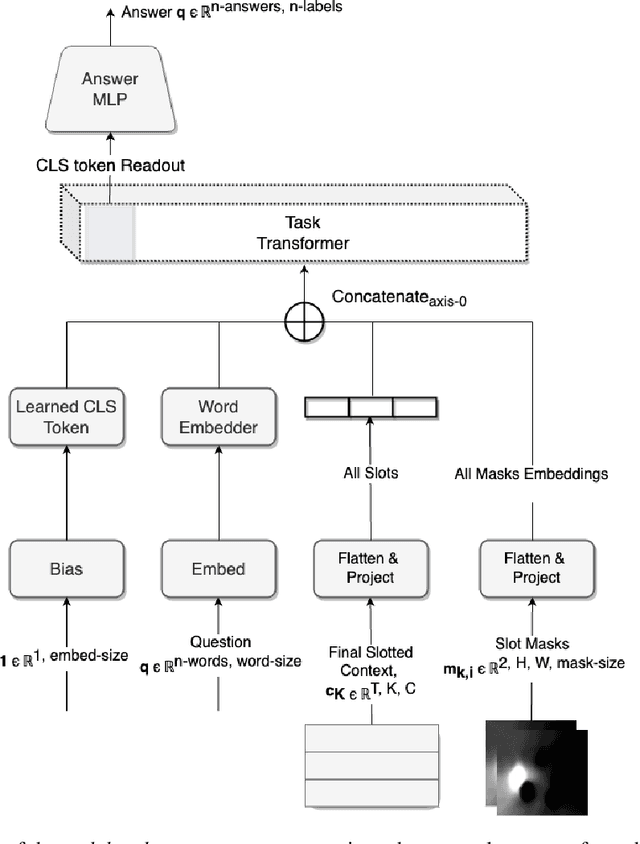
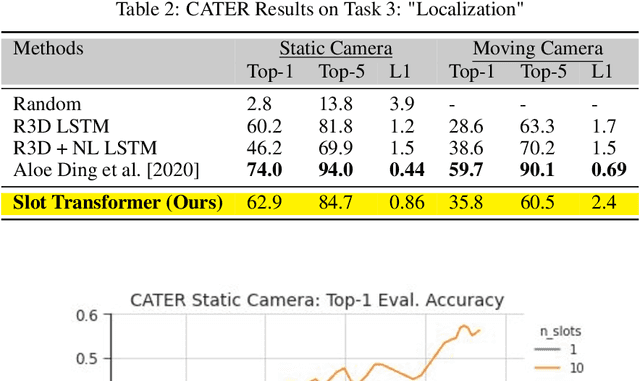
The ability to carve the world into useful abstractions in order to reason about time and space is a crucial component of intelligence. In order to successfully perceive and act effectively using senses we must parse and compress large amounts of information for further downstream reasoning to take place, allowing increasingly complex concepts to emerge. If there is any hope to scale representation learning methods to work with real world scenes and temporal dynamics then there must be a way to learn accurate, concise, and composable abstractions across time. We present the Slot Transformer, an architecture that leverages slot attention, transformers and iterative variational inference on video scene data to infer such representations. We evaluate the Slot Transformer on CLEVRER, Kinetics-600 and CATER datesets and demonstrate that the approach allows us to develop robust modeling and reasoning around complex behaviours as well as scores on these datasets that compare favourably to existing baselines. Finally we evaluate the effectiveness of key components of the architecture, the model's representational capacity and its ability to predict from incomplete input.
High-Resolution Depth Estimation for 360-degree Panoramas through Perspective and Panoramic Depth Images Registration
Oct 20, 2022
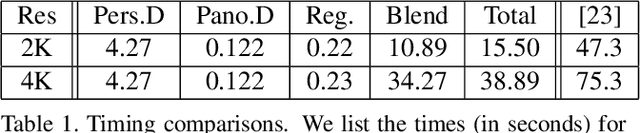
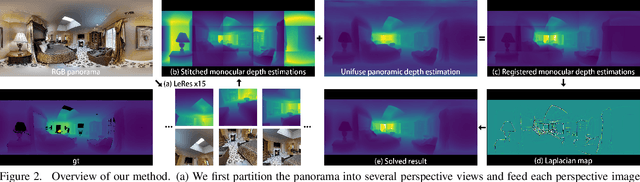
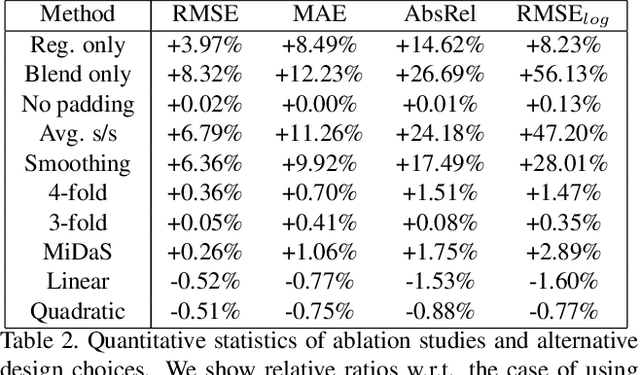
We propose a novel approach to compute high-resolution (2048x1024 and higher) depths for panoramas that is significantly faster and qualitatively and qualitatively more accurate than the current state-of-the-art method (360MonoDepth). As traditional neural network-based methods have limitations in the output image sizes (up to 1024x512) due to GPU memory constraints, both 360MonoDepth and our method rely on stitching multiple perspective disparity or depth images to come out a unified panoramic depth map. However, to achieve globally consistent stitching, 360MonoDepth relied on solving extensive disparity map alignment and Poisson-based blending problems, leading to high computation time. Instead, we propose to use an existing panoramic depth map (computed in real-time by any panorama-based method) as the common target for the individual perspective depth maps to register to. This key idea made producing globally consistent stitching results from a straightforward task. Our experiments show that our method generates qualitatively better results than existing panorama-based methods, and further outperforms them quantitatively on datasets unseen by these methods.
AlphaSnake: Policy Iteration on a Nondeterministic NP-hard Markov Decision Process
Nov 17, 2022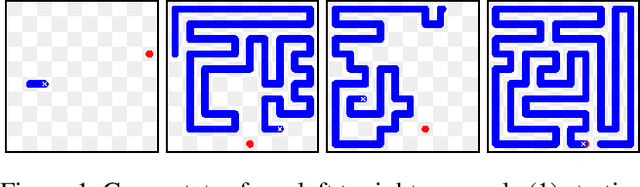
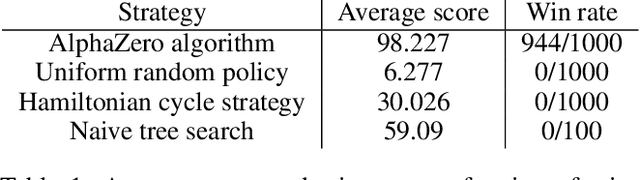
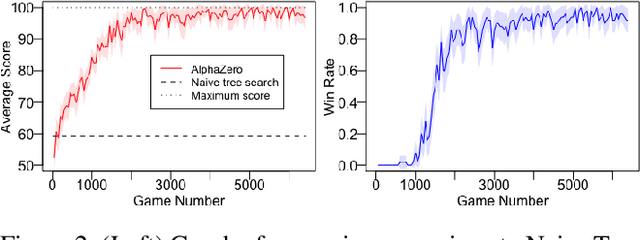
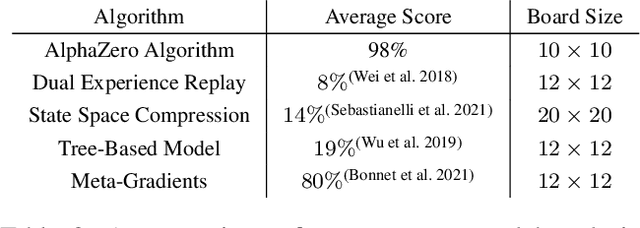
Reinforcement learning has recently been used to approach well-known NP-hard combinatorial problems in graph theory. Among these problems, Hamiltonian cycle problems are exceptionally difficult to analyze, even when restricted to individual instances of structurally complex graphs. In this paper, we use Monte Carlo Tree Search (MCTS), the search algorithm behind many state-of-the-art reinforcement learning algorithms such as AlphaZero, to create autonomous agents that learn to play the game of Snake, a game centered on properties of Hamiltonian cycles on grid graphs. The game of Snake can be formulated as a single-player discounted Markov Decision Process (MDP) where the agent must behave optimally in a stochastic environment. Determining the optimal policy for Snake, defined as the policy that maximizes the probability of winning - or win rate - with higher priority and minimizes the expected number of time steps to win with lower priority, is conjectured to be NP-hard. Performance-wise, compared to prior work in the Snake game, our algorithm is the first to achieve a win rate over $0.5$ (a uniform random policy achieves a win rate $< 2.57 \times 10^{-15}$), demonstrating the versatility of AlphaZero in approaching NP-hard environments.
Random-LTD: Random and Layerwise Token Dropping Brings Efficient Training for Large-scale Transformers
Nov 17, 2022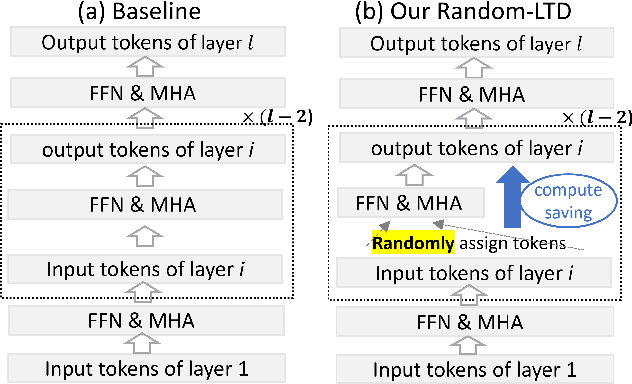

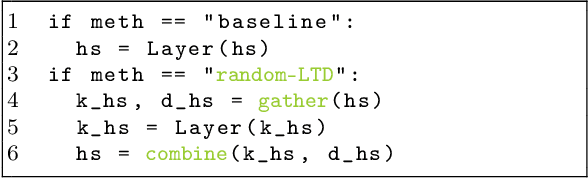
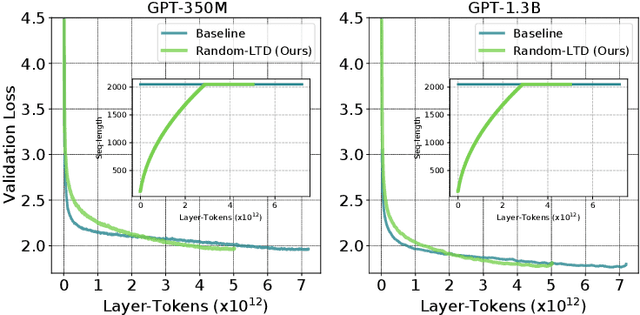
Large-scale transformer models have become the de-facto architectures for various machine learning applications, e.g., CV and NLP. However, those large models also introduce prohibitive training costs. To mitigate this issue, we propose a novel random and layerwise token dropping method (random-LTD), which skips the computation of a subset of the input tokens at all middle layers. Particularly, random-LTD achieves considerable speedups and comparable accuracy as the standard training baseline. Compared to other token dropping methods, random-LTD does not require (1) any importance score-based metrics, (2) any special token treatment (e.g., [CLS]), and (3) many layers in full sequence length training except the first and the last layers. Besides, a new LayerToken learning rate schedule is proposed for pretraining problems that resolve the heavy tuning requirement for our proposed training mechanism. Finally, we demonstrate that random-LTD can be applied to broader applications, including GPT and BERT pretraining as well as ViT and GPT finetuning tasks. Our results show that random-LTD can save about 33.3% theoretical compute cost and 25.6% wall-clock training time while achieving similar zero-shot evaluations on GPT-31.3B as compared to baseline.
Learning to Control Rapidly Changing Synaptic Connections: An Alternative Type of Memory in Sequence Processing Artificial Neural Networks
Nov 17, 2022Short-term memory in standard, general-purpose, sequence-processing recurrent neural networks (RNNs) is stored as activations of nodes or "neurons." Generalising feedforward NNs to such RNNs is mathematically straightforward and natural, and even historical: already in 1943, McCulloch and Pitts proposed this as a surrogate to "synaptic modifications" (in effect, generalising the Lenz-Ising model, the first non-sequence processing RNN architecture of the 1920s). A lesser known alternative approach to storing short-term memory in "synaptic connections" -- by parameterising and controlling the dynamics of a context-sensitive time-varying weight matrix through another NN -- yields another "natural" type of short-term memory in sequence processing NNs: the Fast Weight Programmers (FWPs) of the early 1990s. FWPs have seen a recent revival as generic sequence processors, achieving competitive performance across various tasks. They are formally closely related to the now popular Transformers. Here we present them in the context of artificial NNs as an abstraction of biological NNs -- a perspective that has not been stressed enough in previous FWP work. We first review aspects of FWPs for pedagogical purposes, then discuss connections to related works motivated by insights from neuroscience.
Imputation of Missing Streamflow Data at Multiple Gauging Stations in Benin Republic
Nov 17, 2022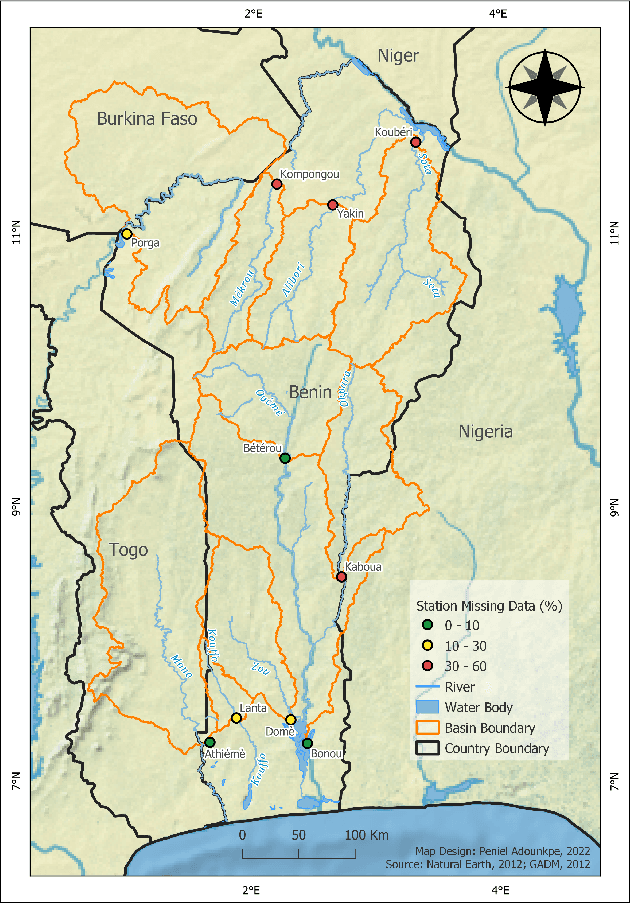
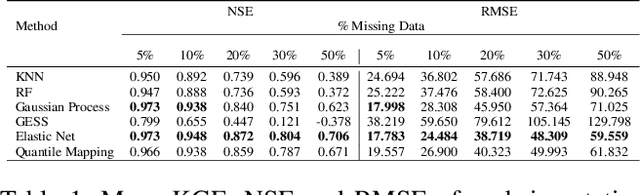
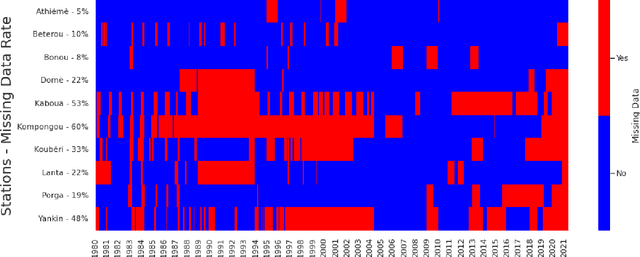
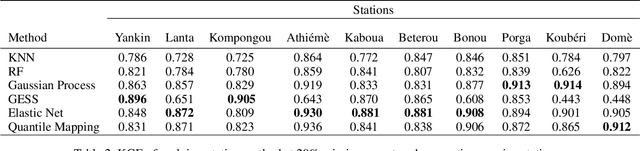
Streamflow observation data is vital for flood monitoring, agricultural, and settlement planning. However, such streamflow data are commonly plagued with missing observations due to various causes such as harsh environmental conditions and constrained operational resources. This problem is often more pervasive in under-resourced areas such as Sub-Saharan Africa. In this work, we reconstruct streamflow time series data through bias correction of the GEOGloWS ECMWF streamflow service (GESS) forecasts at ten river gauging stations in Benin Republic. We perform bias correction by fitting Quantile Mapping, Gaussian Process, and Elastic Net regression in a constrained training period. We show by simulating missingness in a testing period that GESS forecasts have a significant bias that results in low predictive skill over the ten Beninese stations. Our findings suggest that overall bias correction by Elastic Net and Gaussian Process regression achieves superior skill relative to traditional imputation by Random Forest, k-Nearest Neighbour, and GESS lookup. The findings of this work provide a basis for integrating global GESS streamflow data into operational early-warning decision-making systems (e.g., flood alert) in countries vulnerable to drought and flooding due to extreme weather events.
PickNet: Real-Time Channel Selection for Ad Hoc Microphone Arrays
Jan 24, 2022
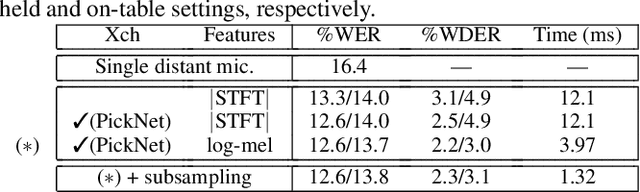
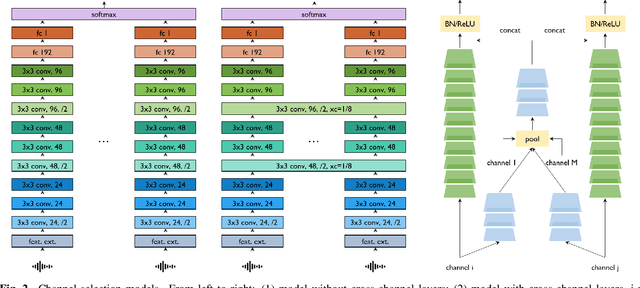
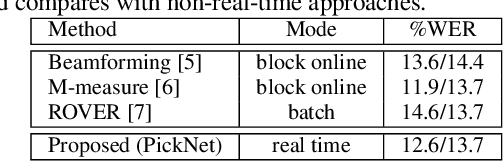
This paper proposes PickNet, a neural network model for real-time channel selection for an ad hoc microphone array consisting of multiple recording devices like cell phones. Assuming at most one person to be vocally active at each time point, PickNet identifies the device that is spatially closest to the active person for each time frame by using a short spectral patch of just hundreds of milliseconds. The model is applied to every time frame, and the short time frame signals from the selected microphones are concatenated across the frames to produce an output signal. As the personal devices are usually held close to their owners, the output signal is expected to have higher signal-to-noise and direct-to-reverberation ratios on average than the input signals. Since PickNet utilizes only limited acoustic context at each time frame, the system using the proposed model works in real time and is robust to changes in acoustic conditions. Speech recognition-based evaluation was carried out by using real conversational recordings obtained with various smartphones. The proposed model yielded significant gains in word error rate with limited computational cost over systems using a block-online beamformer and a single distant microphone.
Exact bounds on the amplitude and phase of the interval discrete Fourier transform in polynomial time
May 27, 2022We elucidate why an interval algorithm that computes the exact bounds on the amplitude and phase of the discrete Fourier transform can run in polynomial time. We address this question from a formal perspective to provide the mathematical foundations underpinning such an algorithm. We show that the procedure set out by the algorithm fully addresses the dependency problem of interval arithmetic, making it usable in a variety of applications involving the discrete Fourier transform. For example when analysing signals with poor precision, signals with missing data, and for automatic error propagation and verified computations.