 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Interactively Learning to Summarise Timelines by Reinforcement Learning
Nov 14, 2022
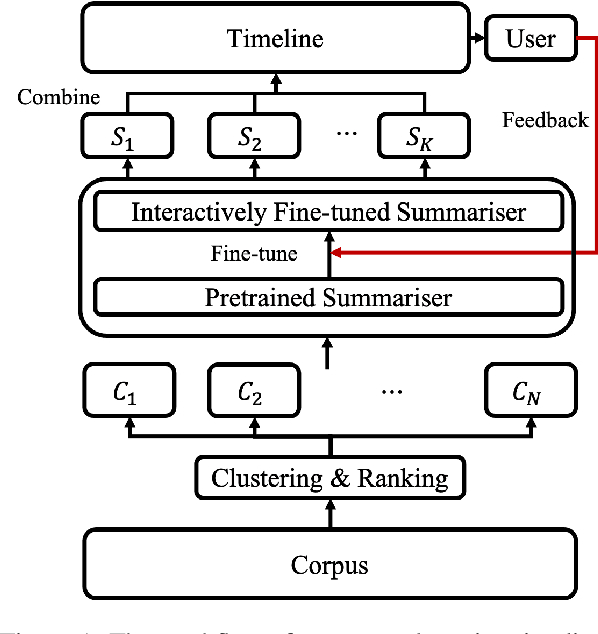
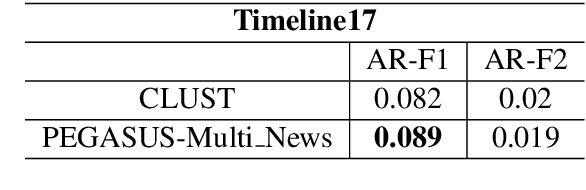
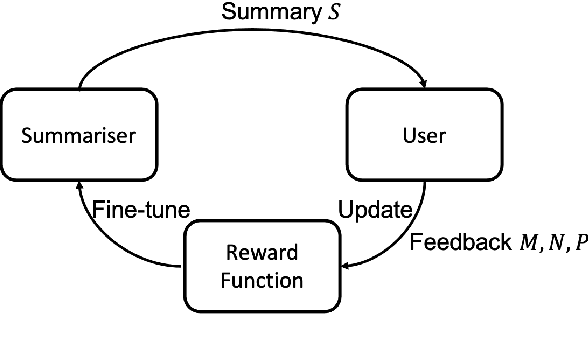
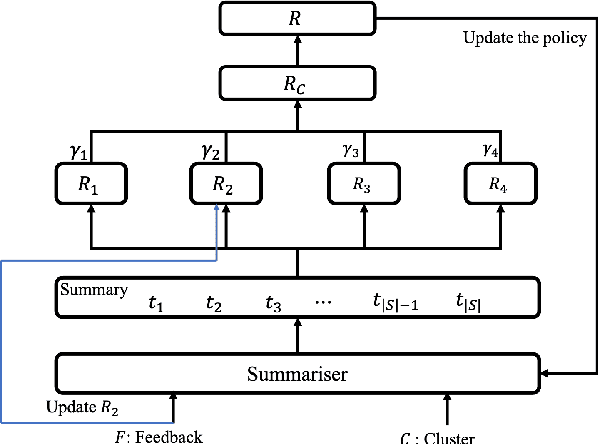
Timeline summarisation (TLS) aims to create a time-ordered summary list concisely describing a series of events with corresponding dates. This differs from general summarisation tasks because it requires the method to capture temporal information besides the main idea of the input documents. This paper proposes a TLS system which can interactively learn from the user's feedback via reinforcement learning and generate timelines satisfying the user's interests. We define a compound reward function that can update automatically according to the received feedback through interaction with the user. The system utilises the reward function to fine-tune an abstractive summarisation model via reinforcement learning to guarantee topical coherence, factual consistency and linguistic fluency of the generated summaries. The proposed system avoids the need of preference feedback from individual users. The experiments show that our system outperforms the baseline on the benchmark TLS dataset and can generate accurate and timeline precises that better satisfy real users.
The Potential of Neural Speech Synthesis-based Data Augmentation for Personalized Speech Enhancement
Nov 14, 2022
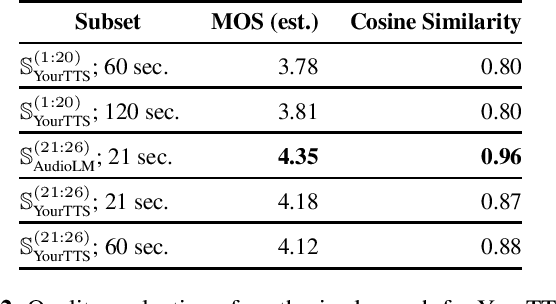
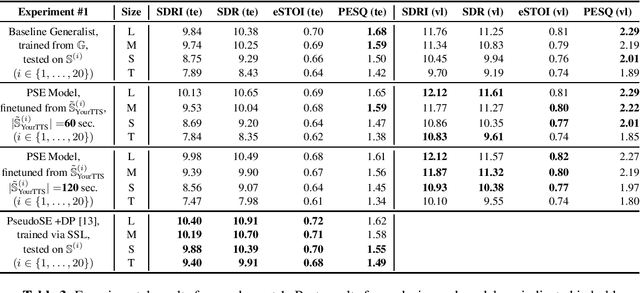
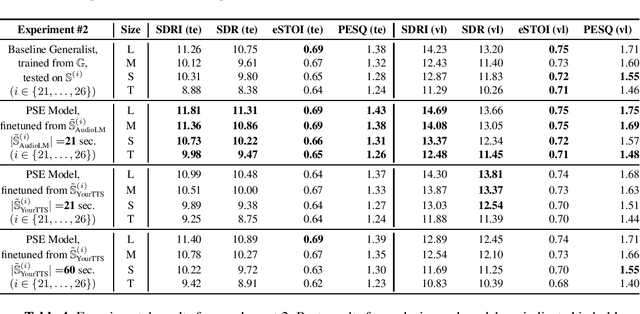
With the advances in deep learning, speech enhancement systems benefited from large neural network architectures and achieved state-of-the-art quality. However, speaker-agnostic methods are not always desirable, both in terms of quality and their complexity, when they are to be used in a resource-constrained environment. One promising way is personalized speech enhancement (PSE), which is a smaller and easier speech enhancement problem for small models to solve, because it focuses on a particular test-time user. To achieve the personalization goal, while dealing with the typical lack of personal data, we investigate the effect of data augmentation based on neural speech synthesis (NSS). In the proposed method, we show that the quality of the NSS system's synthetic data matters, and if they are good enough the augmented dataset can be used to improve the PSE system that outperforms the speaker-agnostic baseline. The proposed PSE systems show significant complexity reduction while preserving the enhancement quality.
DroneNet: Crowd Density Estimation using Self-ONNs for Drones
Nov 14, 2022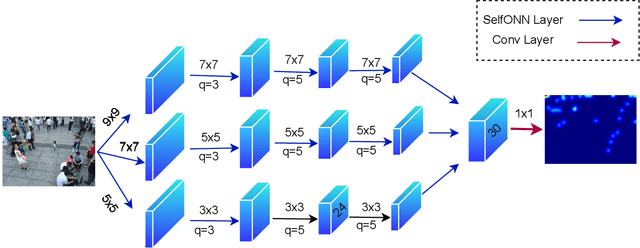
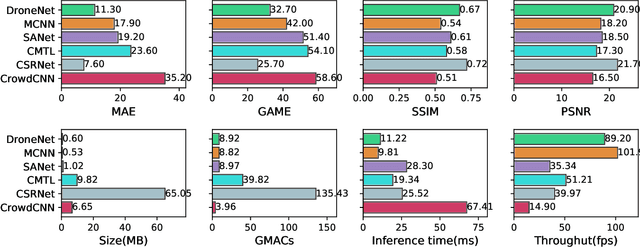

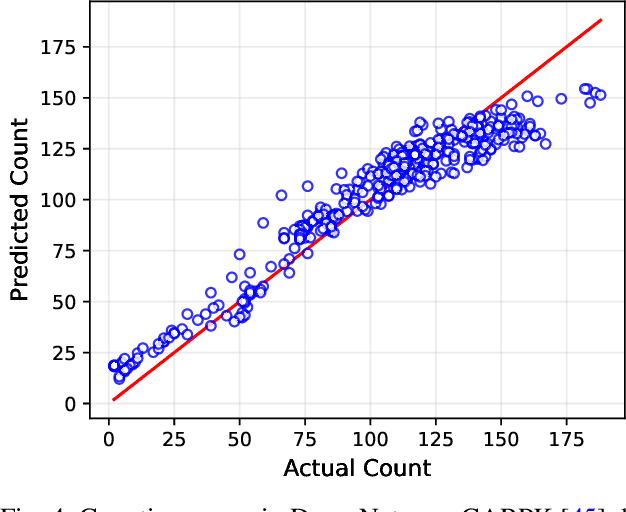
Video surveillance using drones is both convenient and efficient due to the ease of deployment and unobstructed movement of drones in many scenarios. An interesting application of drone-based video surveillance is to estimate crowd densities (both pedestrians and vehicles) in public places. Deep learning using convolution neural networks (CNNs) is employed for automatic crowd counting and density estimation using images and videos. However, the performance and accuracy of such models typically depend upon the model architecture i.e., deeper CNN models improve accuracy at the cost of increased inference time. In this paper, we propose a novel crowd density estimation model for drones (DroneNet) using Self-organized Operational Neural Networks (Self-ONN). Self-ONN provides efficient learning capabilities with lower computational complexity as compared to CNN-based models. We tested our algorithm on two drone-view public datasets. Our evaluation shows that the proposed DroneNet shows superior performance on an equivalent CNN-based model.
Joint Communication and Computation Design in Transmissive RMS Transceiver Enabled Multi-Tier Computing Networks
Oct 27, 2022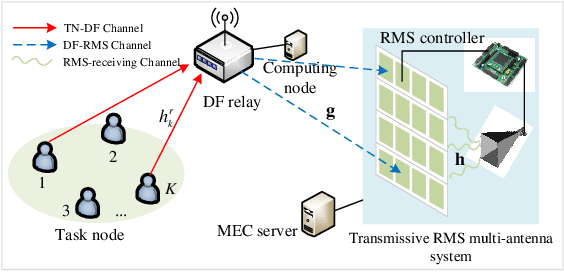
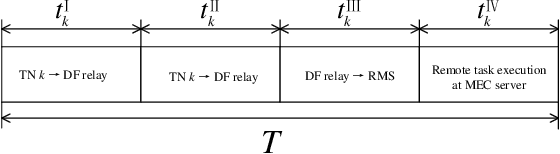
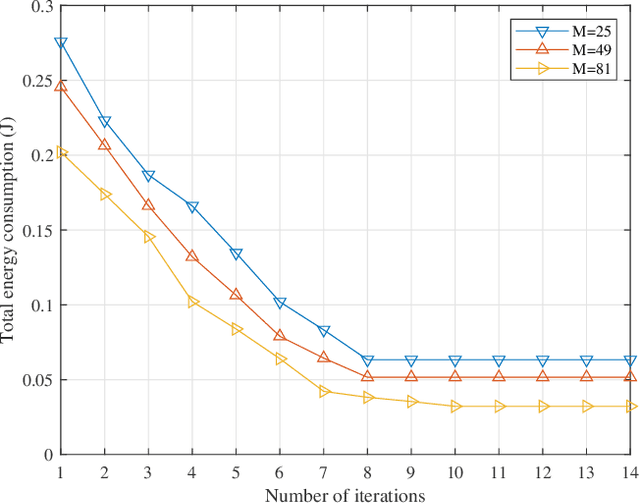
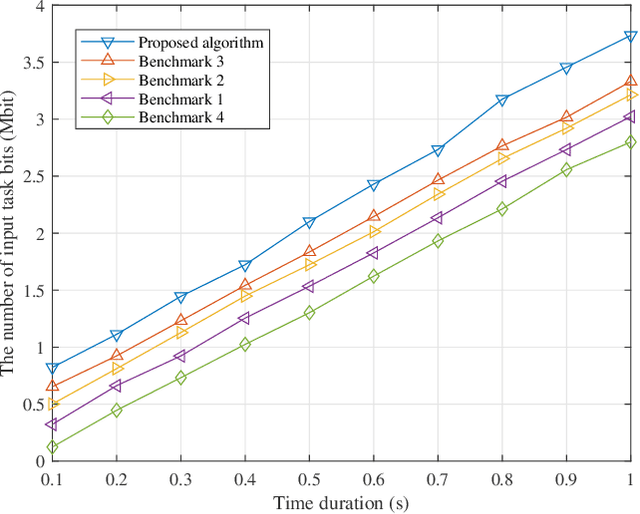
In this paper, a novel transmissive reconfigurable meta-surface (RMS) transceiver enabled multi-tier computing network architecture is proposed for improving computing capability, decreasing computing delay and reducing base station (BS) deployment cost, in which transmissive RMS equipped with a feed antenna can be regarded as a new type of multi-antenna system. We formulate a total energy consumption minimization problem by a joint optimization of subcarrier allocation, task input bits, time slot allocation, transmit power allocation and RMS transmissive coefficient while taking into account the constraints of communication resources and computing resources. This formulated problem is a non-convex optimization problem due to the high coupling of optimization variables, which is NP-hard to obtain its optimal solution. To address the above challenging problems, block coordinate descent (BCD) technique is employed to decouple the optimization variables to solve the problem. Specifically, the joint optimization problem of subcarrier allocation, task input bits, time slot allocation, transmit power allocation and RMS transmissive coefficient is divided into three subproblems to solve by applying BCD. Then, the decoupled three subproblems are optimized alternately by using successive convex approximation (SCA) and difference-convex (DC) programming until the convergence is achieved. Numerical results verify that our proposed algorithm is superior in reducing total energy consumption compared to other benchmarks.
Adapting to Mixing Time in Stochastic Optimization with Markovian Data
Feb 09, 2022
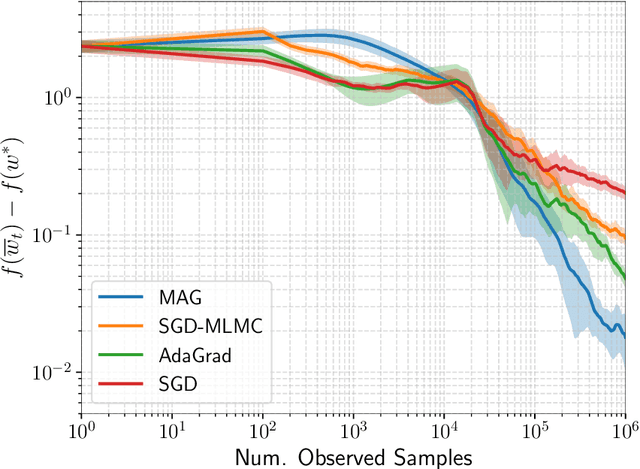
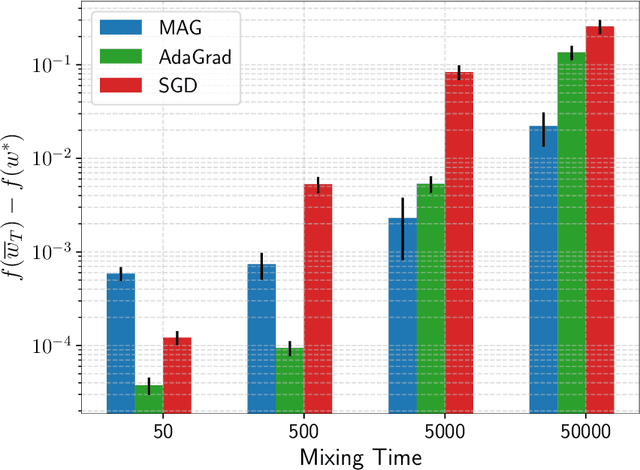
We consider stochastic optimization problems where data is drawn from a Markov chain. Existing methods for this setting crucially rely on knowing the mixing time of the chain, which in real-world applications is usually unknown. We propose the first optimization method that does not require the knowledge of the mixing time, yet obtains the optimal asymptotic convergence rate when applied to convex problems. We further show that our approach can be extended to: (i) finding stationary points in non-convex optimization with Markovian data, and (ii) obtaining better dependence on the mixing time in temporal difference (TD) learning; in both cases, our method is completely oblivious to the mixing time. Our method relies on a novel combination of multi-level Monte Carlo (MLMC) gradient estimation together with an adaptive learning method.
Non-stationary Risk-sensitive Reinforcement Learning: Near-optimal Dynamic Regret, Adaptive Detection, and Separation Design
Nov 19, 2022
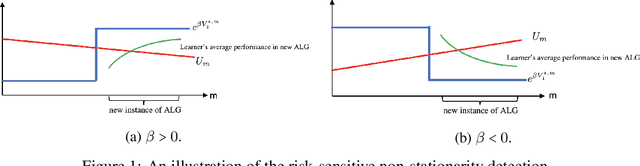
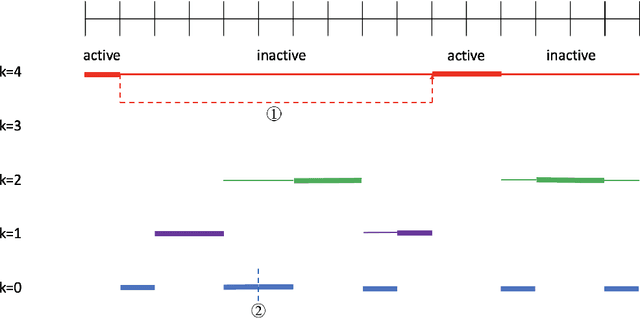
We study risk-sensitive reinforcement learning (RL) based on an entropic risk measure in episodic non-stationary Markov decision processes (MDPs). Both the reward functions and the state transition kernels are unknown and allowed to vary arbitrarily over time with a budget on their cumulative variations. When this variation budget is known a prior, we propose two restart-based algorithms, namely Restart-RSMB and Restart-RSQ, and establish their dynamic regrets. Based on these results, we further present a meta-algorithm that does not require any prior knowledge of the variation budget and can adaptively detect the non-stationarity on the exponential value functions. A dynamic regret lower bound is then established for non-stationary risk-sensitive RL to certify the near-optimality of the proposed algorithms. Our results also show that the risk control and the handling of the non-stationarity can be separately designed in the algorithm if the variation budget is known a prior, while the non-stationary detection mechanism in the adaptive algorithm depends on the risk parameter. This work offers the first non-asymptotic theoretical analyses for the non-stationary risk-sensitive RL in the literature.
BENK: The Beran Estimator with Neural Kernels for Estimating the Heterogeneous Treatment Effect
Nov 19, 2022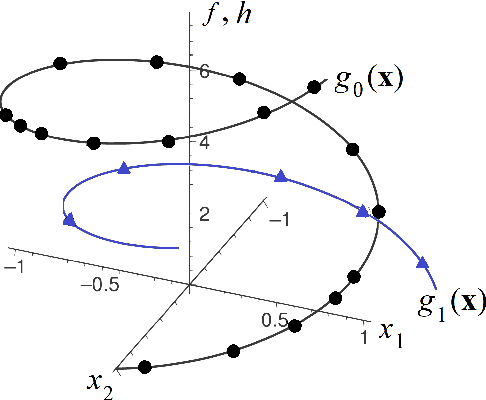
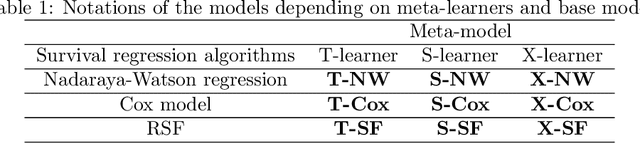
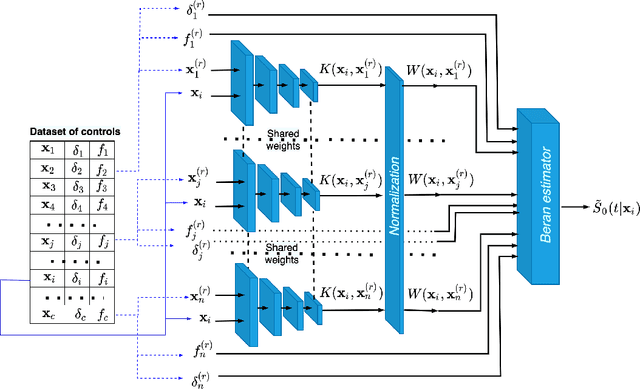
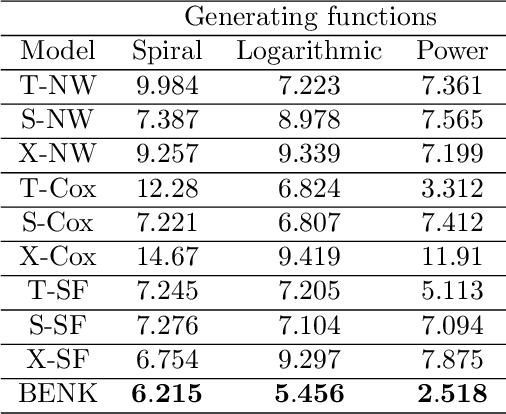
A method for estimating the conditional average treatment effect under condition of censored time-to-event data called BENK (the Beran Estimator with Neural Kernels) is proposed. The main idea behind the method is to apply the Beran estimator for estimating the survival functions of controls and treatments. Instead of typical kernel functions in the Beran estimator, it is proposed to implement kernels in the form of neural networks of a specific form called the neural kernels. The conditional average treatment effect is estimated by using the survival functions as outcomes of the control and treatment neural networks which consists of a set of neural kernels with shared parameters. The neural kernels are more flexible and can accurately model a complex location structure of feature vectors. Various numerical simulation experiments illustrate BENK and compare it with the well-known T-learner, S-learner and X-learner for several types of the control and treatment outcome functions based on the Cox models, the random survival forest and the Nadaraya-Watson regression with Gaussian kernels. The code of proposed algorithms implementing BENK is available in https://github.com/Stasychbr/BENK.
Delay-aware Backpressure Routing Using Graph Neural Networks
Nov 19, 2022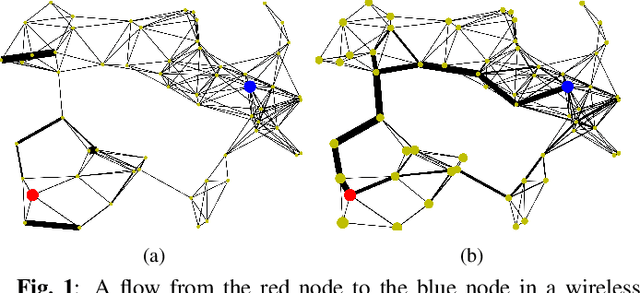
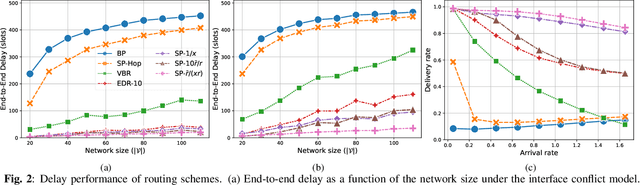
We propose a throughput-optimal biased backpressure (BP) algorithm for routing, where the bias is learned through a graph neural network that seeks to minimize end-to-end delay. Classical BP routing provides a simple yet powerful distributed solution for resource allocation in wireless multi-hop networks but has poor delay performance. A low-cost approach to improve this delay performance is to favor shorter paths by incorporating pre-defined biases in the BP computation, such as a bias based on the shortest path (hop) distance to the destination. In this work, we improve upon the widely-used metric of hop distance (and its variants) for the shortest path bias by introducing a bias based on the link duty cycle, which we predict using a graph convolutional neural network. Numerical results show that our approach can improve the delay performance compared to classical BP and existing BP alternatives based on pre-defined bias while being adaptive to interference density. In terms of complexity, our distributed implementation only introduces a one-time overhead (linear in the number of devices in the network) compared to classical BP, and a constant overhead compared to the lowest-complexity existing bias-based BP algorithms.
A Space-Time Neural Network for Analysis of Stress Evolution under DC Current Stressing
Mar 29, 2022
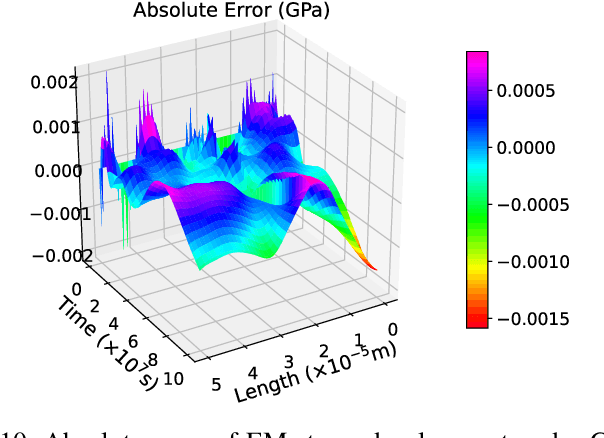
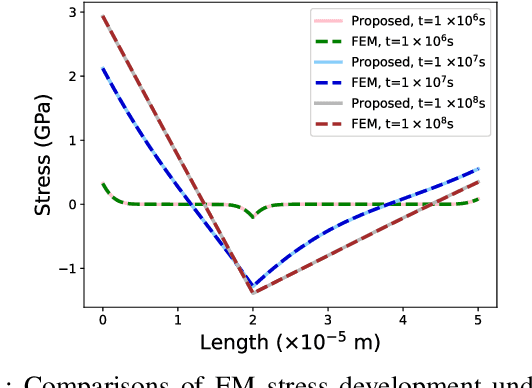
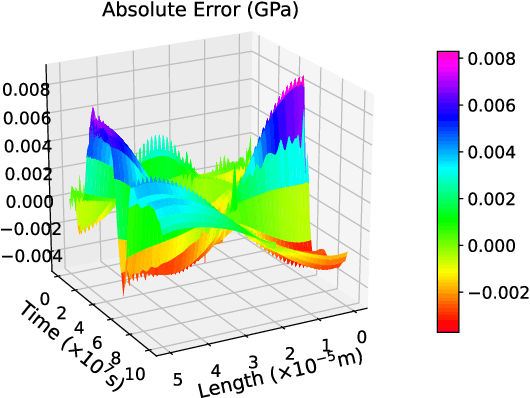
The electromigration (EM)-induced reliability issues in very large scale integration (VLSI) circuits have attracted increased attention due to the continuous technology scaling. Traditional EM models often lead to overly pessimistic prediction incompatible with the shrinking design margin in future technology nodes. Motivated by the latest success of neural networks in solving differential equations in physical problems, we propose a novel mesh-free model to compute EM-induced stress evolution in VLSI circuits. The model utilizes a specifically crafted space-time physics-informed neural network (STPINN) as the solver for EM analysis. By coupling the physics-based EM analysis with dynamic temperature incorporating Joule heating and via effect, we can observe stress evolution along multi-segment interconnect trees under constant, time-dependent and space-time-dependent temperature during the void nucleation phase. The proposed STPINN method obviates the time discretization and meshing required in conventional numerical stress evolution analysis and offers significant computational savings. Numerical comparison with competing schemes demonstrates a 2x ~ 52x speedup with a satisfactory accuracy.
Playable Environments: Video Manipulation in Space and Time
Mar 03, 2022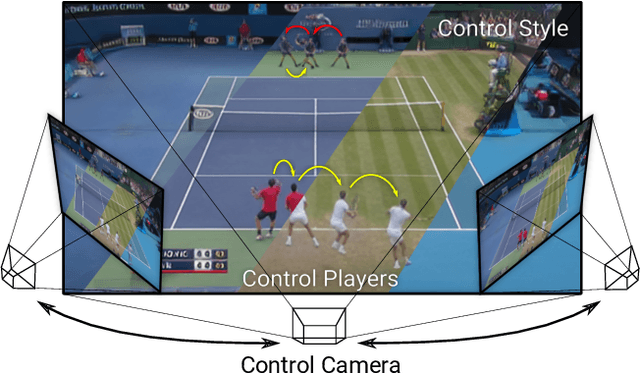

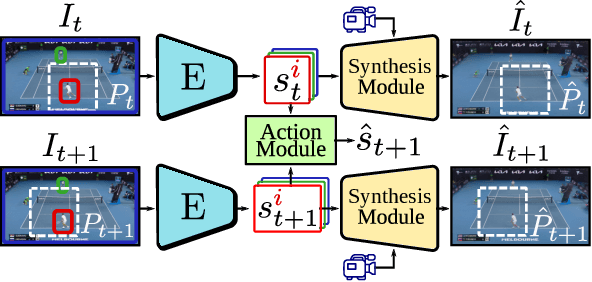
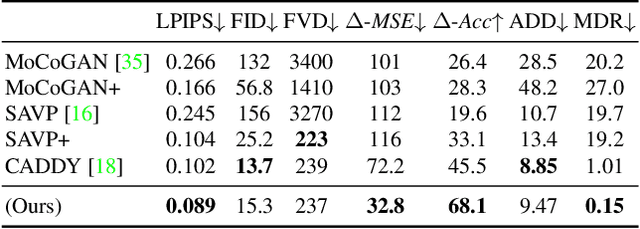
We present Playable Environments - a new representation for interactive video generation and manipulation in space and time. With a single image at inference time, our novel framework allows the user to move objects in 3D while generating a video by providing a sequence of desired actions. The actions are learnt in an unsupervised manner. The camera can be controlled to get the desired viewpoint. Our method builds an environment state for each frame, which can be manipulated by our proposed action module and decoded back to the image space with volumetric rendering. To support diverse appearances of objects, we extend neural radiance fields with style-based modulation. Our method trains on a collection of various monocular videos requiring only the estimated camera parameters and 2D object locations. To set a challenging benchmark, we introduce two large scale video datasets with significant camera movements. As evidenced by our experiments, playable environments enable several creative applications not attainable by prior video synthesis works, including playable 3D video generation, stylization and manipulation. Further details, code and examples are available at https://willi-menapace.github.io/playable-environments-website