 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
3D LiDAR Aided GNSS NLOS Mitigation for Reliable GNSS-RTK Positioning in Urban Canyons
Dec 11, 2022
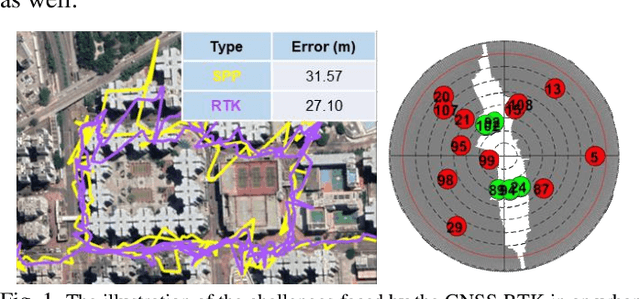
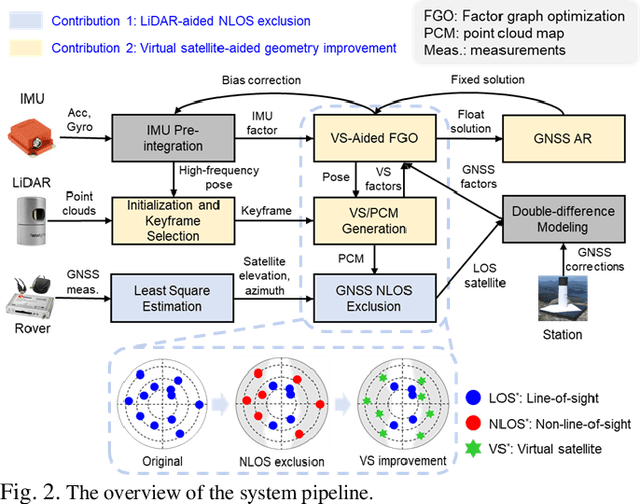

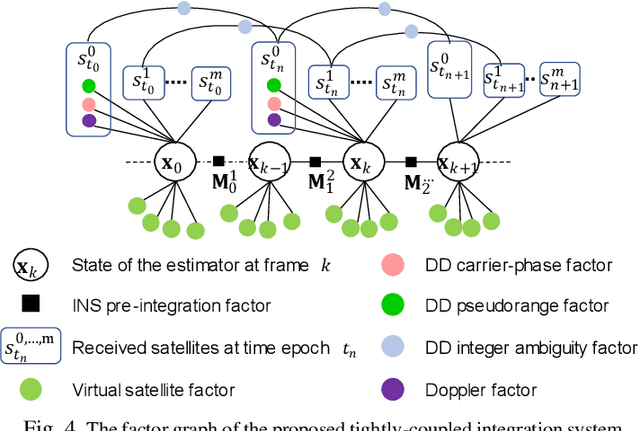
GNSS and LiDAR odometry are complementary as they provide absolute and relative positioning, respectively. Their integration in a loosely-coupled manner is straightforward but is challenged in urban canyons due to the GNSS signal reflections. Recent proposed 3D LiDAR-aided (3DLA) GNSS methods employ the point cloud map to identify the non-line-of-sight (NLOS) reception of GNSS signals. This facilitates the GNSS receiver to obtain improved urban positioning but not achieve a sub-meter level. GNSS real-time kinematics (RTK) uses carrier phase measurements to obtain decimeter-level positioning. In urban areas, the GNSS RTK is not only challenged by multipath and NLOS-affected measurement but also suffers from signal blockage by the building. The latter will impose a challenge in solving the ambiguity within the carrier phase measurements. In the other words, the model observability of the ambiguity resolution (AR) is greatly decreased. This paper proposes to generate virtual satellite (VS) measurements using the selected LiDAR landmarks from the accumulated 3D point cloud maps (PCM). These LiDAR-PCM-made VS measurements are tightly-coupled with GNSS pseudorange and carrier phase measurements. Thus, the VS measurements can provide complementary constraints, meaning providing low-elevation-angle measurements in the across-street directions. The implementation is done using factor graph optimization to solve an accurate float solution of the ambiguity before it is fed into LAMBDA. The effectiveness of the proposed method has been validated by the evaluation conducted on our recently open-sourced challenging dataset, UrbanNav. The result shows the fix rate of the proposed 3DLA GNSS RTK is about 30% while the conventional GNSS-RTK only achieves about 14%. In addition, the proposed method achieves sub-meter positioning accuracy in most of the data collected in challenging urban areas.
DiffusionBERT: Improving Generative Masked Language Models with Diffusion Models
Nov 30, 2022

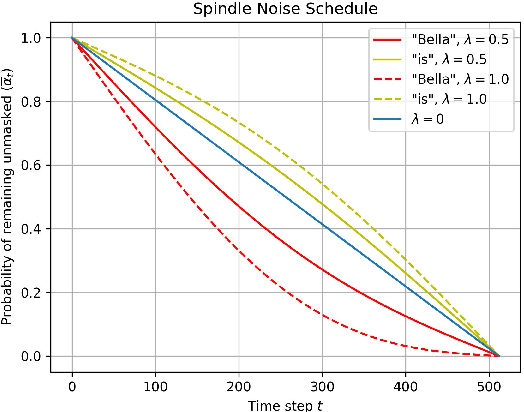
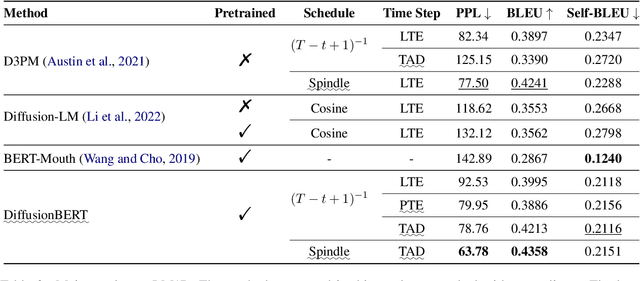
We present DiffusionBERT, a new generative masked language model based on discrete diffusion models. Diffusion models and many pre-trained language models have a shared training objective, i.e., denoising, making it possible to combine the two powerful models and enjoy the best of both worlds. On the one hand, diffusion models offer a promising training strategy that helps improve the generation quality. On the other hand, pre-trained denoising language models (e.g., BERT) can be used as a good initialization that accelerates convergence. We explore training BERT to learn the reverse process of a discrete diffusion process with an absorbing state and elucidate several designs to improve it. First, we propose a new noise schedule for the forward diffusion process that controls the degree of noise added at each step based on the information of each token. Second, we investigate several designs of incorporating the time step into BERT. Experiments on unconditional text generation demonstrate that DiffusionBERT achieves significant improvement over existing diffusion models for text (e.g., D3PM and Diffusion-LM) and previous generative masked language models in terms of perplexity and BLEU score.
BotSIM: An End-to-End Bot Simulation Toolkit for Commercial Task-Oriented Dialog Systems
Nov 30, 2022
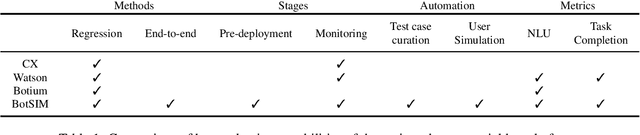
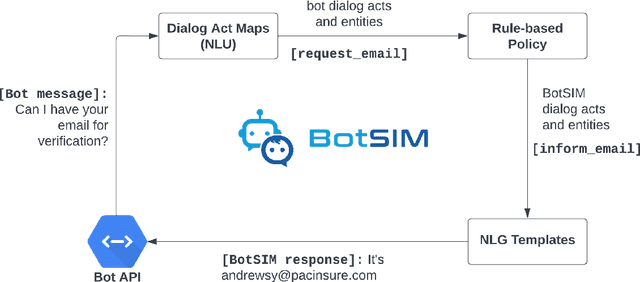
We introduce BotSIM, a modular, open-source Bot SIMulation environment with dialog generation, user simulation and conversation analytics capabilities. BotSIM aims to serve as a one-stop solution for large-scale data-efficient end-to-end evaluation, diagnosis and remediation of commercial task-oriented dialog (TOD) systems to significantly accelerate commercial bot development and evaluation, reduce cost and time-to-market. BotSIM adopts a layered design comprising the infrastructure layer, the adaptor layer and the application layer. The infrastructure layer hosts key models and components to support BotSIM's major functionalities via a streamlined "generation-simulation-remediation" pipeline. The adaptor layer is used to extend BotSIM to accommodate new bot platforms. The application layer provides a suite of command line tools and a Web App to significantly lower the entry barrier for BotSIM users such as bot admins or practitioners. In this report, we focus on the technical designs of various system components. A detailed case study using Einstein BotBuilder is also presented to show how to apply BotSIM pipeline for bot evaluation and remediation. The detailed system descriptions can be found in our system demo paper. The toolkit is available at: https://github.com/salesforce/BotSIM .
Understanding Cryptocoins Trends Correlations
Nov 30, 2022Crypto-coins (also known as cryptocurrencies) are tradable digital assets. Notable examples include Bitcoin, Ether and Litecoin. Ownerships of cryptocoins are registered on distributed ledgers (i.e., blockchains). Secure encryption techniques guarantee the security of the transactions (transfers of coins across owners), registered into the ledger. Cryptocoins are exchanged for specific trading prices. While history has shown the extreme volatility of such trading prices across all different sets of crypto-assets, it remains unclear what and if there are tight relations between the trading prices of different cryptocoins. Major coin exchanges (i.e., Coinbase) provide trend correlation indicators to coin owners, suggesting possible acquisitions or sells. However, these correlations remain largely unvalidated. In this paper, we shed lights on the trend correlations across a large variety of cryptocoins, by investigating their coin-price correlation trends over a period of two years. Our experimental results suggest strong correlation patterns between main coins (Ethereum, Bitcoin) and alt-coins. We believe our study can support forecasting techniques for time-series modeling in the context of crypto-coins. We release our dataset and code to reproduce our analysis to the research community.
* 8 pages, 4 figures
Monte Carlo Tree Search Algorithms for Risk-Aware and Multi-Objective Reinforcement Learning
Dec 06, 2022
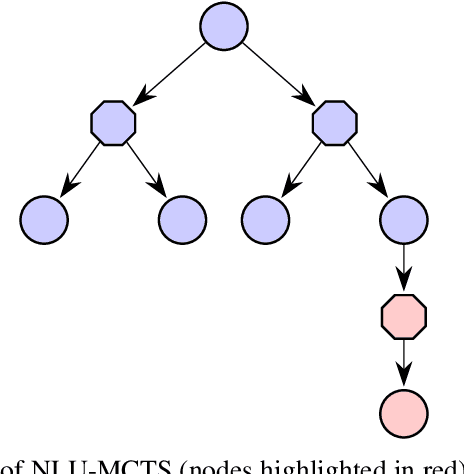
In many risk-aware and multi-objective reinforcement learning settings, the utility of the user is derived from a single execution of a policy. In these settings, making decisions based on the average future returns is not suitable. For example, in a medical setting a patient may only have one opportunity to treat their illness. Making decisions using just the expected future returns -- known in reinforcement learning as the value -- cannot account for the potential range of adverse or positive outcomes a decision may have. Therefore, we should use the distribution over expected future returns differently to represent the critical information that the agent requires at decision time by taking both the future and accrued returns into consideration. In this paper, we propose two novel Monte Carlo tree search algorithms. Firstly, we present a Monte Carlo tree search algorithm that can compute policies for nonlinear utility functions (NLU-MCTS) by optimising the utility of the different possible returns attainable from individual policy executions, resulting in good policies for both risk-aware and multi-objective settings. Secondly, we propose a distributional Monte Carlo tree search algorithm (DMCTS) which extends NLU-MCTS. DMCTS computes an approximate posterior distribution over the utility of the returns, and utilises Thompson sampling during planning to compute policies in risk-aware and multi-objective settings. Both algorithms outperform the state-of-the-art in multi-objective reinforcement learning for the expected utility of the returns.
ERNet: Unsupervised Collective Extraction and Registration in Neuroimaging Data
Dec 06, 2022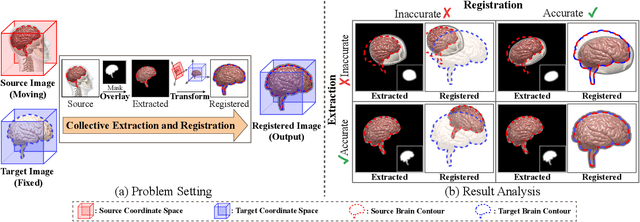
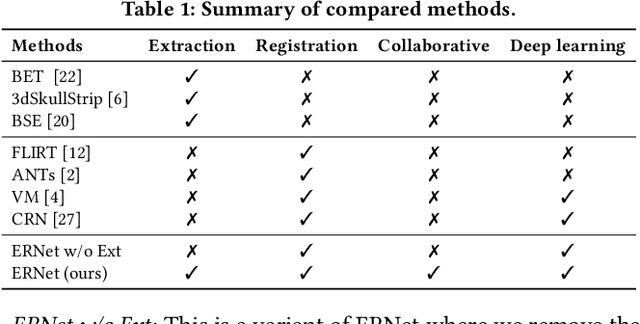
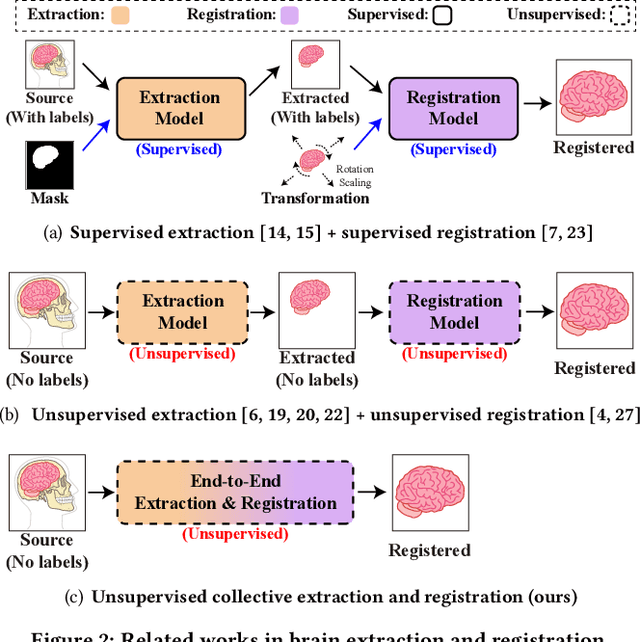

Brain extraction and registration are important preprocessing steps in neuroimaging data analysis, where the goal is to extract the brain regions from MRI scans (i.e., extraction step) and align them with a target brain image (i.e., registration step). Conventional research mainly focuses on developing methods for the extraction and registration tasks separately under supervised settings. The performance of these methods highly depends on the amount of training samples and visual inspections performed by experts for error correction. However, in many medical studies, collecting voxel-level labels and conducting manual quality control in high-dimensional neuroimages (e.g., 3D MRI) are very expensive and time-consuming. Moreover, brain extraction and registration are highly related tasks in neuroimaging data and should be solved collectively. In this paper, we study the problem of unsupervised collective extraction and registration in neuroimaging data. We propose a unified end-to-end framework, called ERNet (Extraction-Registration Network), to jointly optimize the extraction and registration tasks, allowing feedback between them. Specifically, we use a pair of multi-stage extraction and registration modules to learn the extraction mask and transformation, where the extraction network improves the extraction accuracy incrementally and the registration network successively warps the extracted image until it is well-aligned with the target image. Experiment results on real-world datasets show that our proposed method can effectively improve the performance on extraction and registration tasks in neuroimaging data. Our code and data can be found at https://github.com/ERNetERNet/ERNet
Efficient Learning of Voltage Control Strategies via Model-based Deep Reinforcement Learning
Dec 06, 2022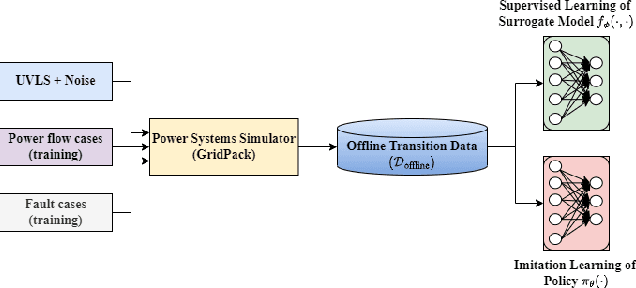
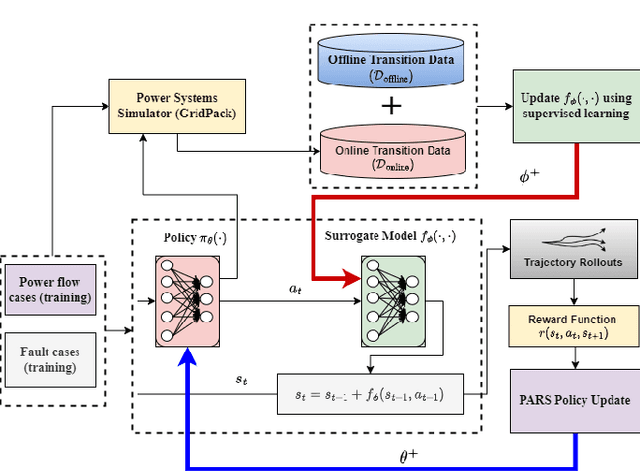
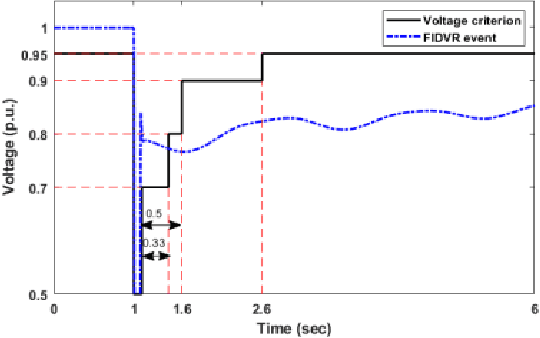
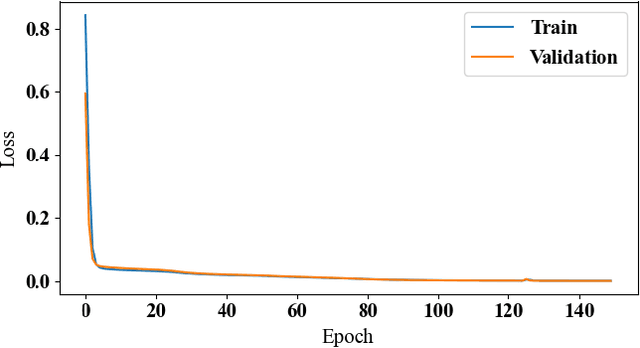
This article proposes a model-based deep reinforcement learning (DRL) method to design emergency control strategies for short-term voltage stability problems in power systems. Recent advances show promising results in model-free DRL-based methods for power systems, but model-free methods suffer from poor sample efficiency and training time, both critical for making state-of-the-art DRL algorithms practically applicable. DRL-agent learns an optimal policy via a trial-and-error method while interacting with the real-world environment. And it is desirable to minimize the direct interaction of the DRL agent with the real-world power grid due to its safety-critical nature. Additionally, state-of-the-art DRL-based policies are mostly trained using a physics-based grid simulator where dynamic simulation is computationally intensive, lowering the training efficiency. We propose a novel model-based-DRL framework where a deep neural network (DNN)-based dynamic surrogate model, instead of a real-world power-grid or physics-based simulation, is utilized with the policy learning framework, making the process faster and sample efficient. However, stabilizing model-based DRL is challenging because of the complex system dynamics of large-scale power systems. We solved these issues by incorporating imitation learning to have a warm start in policy learning, reward-shaping, and multi-step surrogate loss. Finally, we achieved 97.5% sample efficiency and 87.7% training efficiency for an application to the IEEE 300-bus test system.
ISAACS: Iterative Soft Adversarial Actor-Critic for Safety
Dec 06, 2022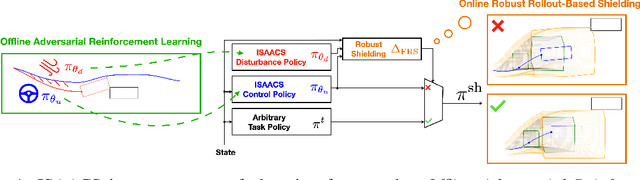
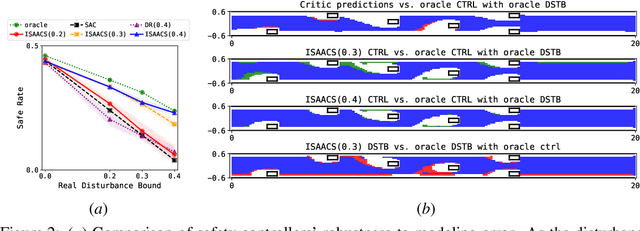
The deployment of robots in uncontrolled environments requires them to operate robustly under previously unseen scenarios, like irregular terrain and wind conditions. Unfortunately, while rigorous safety frameworks from robust optimal control theory scale poorly to high-dimensional nonlinear dynamics, control policies computed by more tractable "deep" methods lack guarantees and tend to exhibit little robustness to uncertain operating conditions. This work introduces a novel approach enabling scalable synthesis of robust safety-preserving controllers for robotic systems with general nonlinear dynamics subject to bounded modeling error by combining game-theoretic safety analysis with adversarial reinforcement learning in simulation. Following a soft actor-critic scheme, a safety-seeking fallback policy is co-trained with an adversarial "disturbance" agent that aims to invoke the worst-case realization of model error and training-to-deployment discrepancy allowed by the designer's uncertainty. While the learned control policy does not intrinsically guarantee safety, it is used to construct a real-time safety filter (or shield) with robust safety guarantees based on forward reachability rollouts. This shield can be used in conjunction with a safety-agnostic control policy, precluding any task-driven actions that could result in loss of safety. We evaluate our learning-based safety approach in a 5D race car simulator, compare the learned safety policy to the numerically obtained optimal solution, and empirically validate the robust safety guarantee of our proposed safety shield against worst-case model discrepancy.
Interaction Visual Transformer for Egocentric Action Anticipation
Nov 25, 2022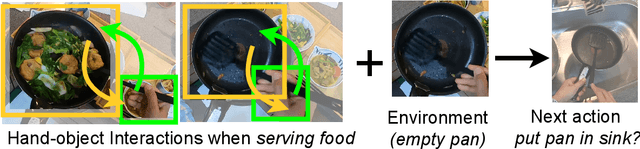
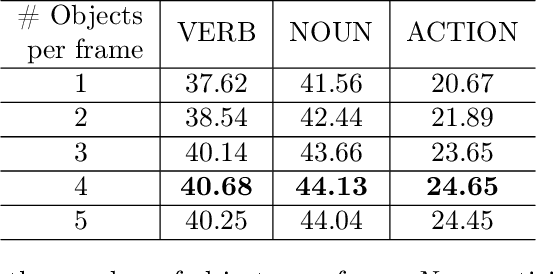
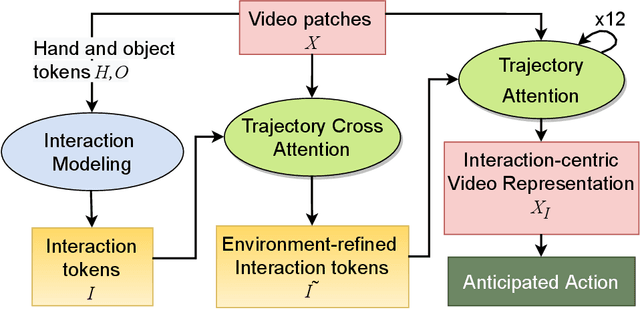
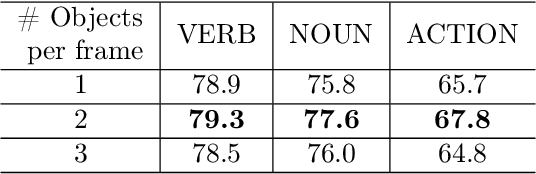
Human-object interaction is one of the most important visual cues that has not been explored for egocentric action anticipation. We propose a novel Transformer variant to model interactions by computing the change in the appearance of objects and human hands due to the execution of the actions and use those changes to refine the video representation. Specifically, we model interactions between hands and objects using Spatial Cross-Attention (SCA) and further infuse contextual information using Trajectory Cross-Attention to obtain environment-refined interaction tokens. Using these tokens, we construct an interaction-centric video representation for action anticipation. We term our model InAViT which achieves state-of-the-art action anticipation performance on large-scale egocentric datasets EPICKTICHENS100 (EK100) and EGTEA Gaze+. InAViT outperforms other visual transformer-based methods including object-centric video representation. On the EK100 evaluation server, InAViT is the top-performing method on the public leaderboard (at the time of submission) where it outperforms the second-best model by 3.3% on mean-top5 recall.
Adaptive Attention Link-based Regularization for Vision Transformers
Nov 25, 2022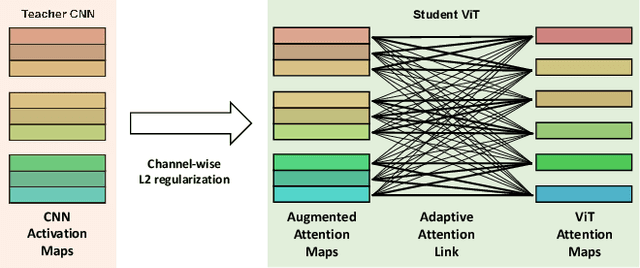

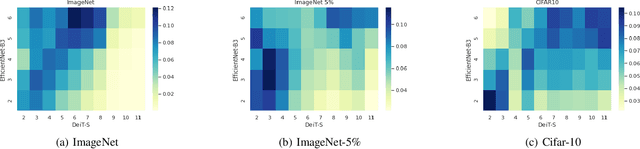

Although transformer networks are recently employed in various vision tasks with outperforming performance, extensive training data and a lengthy training time are required to train a model to disregard an inductive bias. Using trainable links between the channel-wise spatial attention of a pre-trained Convolutional Neural Network (CNN) and the attention head of Vision Transformers (ViT), we present a regularization technique to improve the training efficiency of ViT. The trainable links are referred to as the attention augmentation module, which is trained simultaneously with ViT, boosting the training of ViT and allowing it to avoid the overfitting issue caused by a lack of data. From the trained attention augmentation module, we can extract the relevant relationship between each CNN activation map and each ViT attention head, and based on this, we also propose an advanced attention augmentation module. Consequently, even with a small amount of data, the suggested method considerably improves the performance of ViT while achieving faster convergence during training.