 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generalizing LTL Instructions via Future Dependent Options
Dec 15, 2022
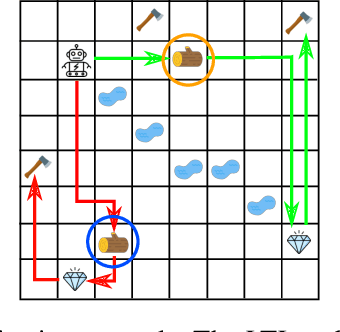
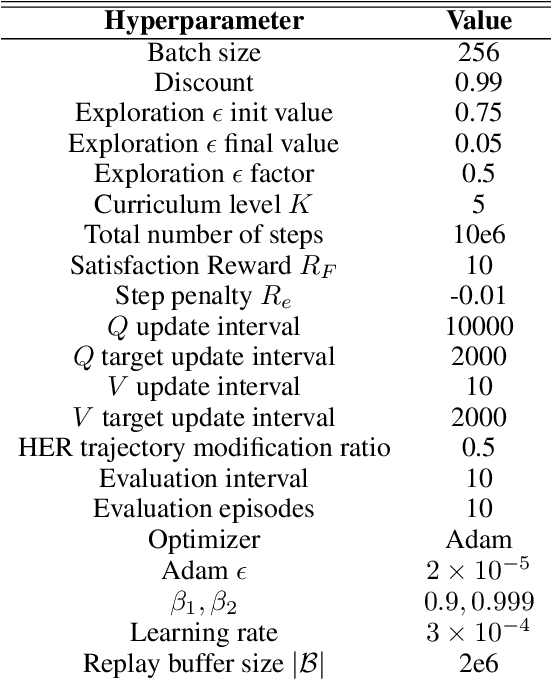

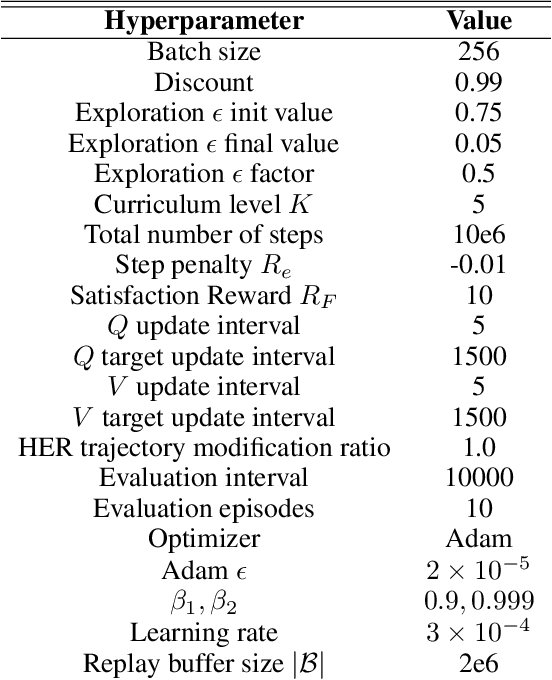
In many real-world applications of control system and robotics, linear temporal logic (LTL) is a widely-used task specification language which has a compositional grammar that naturally induces temporally extended behaviours across tasks, including conditionals and alternative realizations. An important problem in RL with LTL tasks is to learn task-conditioned policies which can zero-shot generalize to new LTL instructions not observed in the training. However, because symbolic observation is often lossy and LTL tasks can have long time horizon, previous works can suffer from issues such as training sampling inefficiency and infeasibility or sub-optimality of the found solutions. In order to tackle these issues, this paper proposes a novel multi-task RL algorithm with improved learning efficiency and optimality. To achieve the global optimality of task completion, we propose to learn options dependent on the future subgoals via a novel off-policy approach. In order to propagate the rewards of satisfying future subgoals back more efficiently, we propose to train a multi-step value function conditioned on the subgoal sequence which is updated with Monte Carlo estimates of multi-step discounted returns. In experiments on three different domains, we evaluate the LTL generalization capability of the agent trained by the proposed method, showing its advantage over previous representative methods.
Universal Generative Modeling in Dual-domain for Dynamic MR Imaging
Dec 15, 2022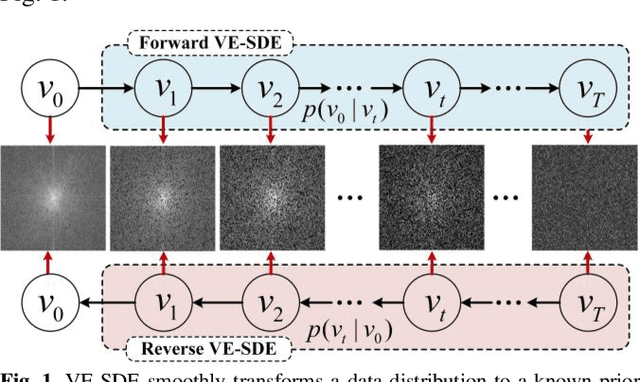
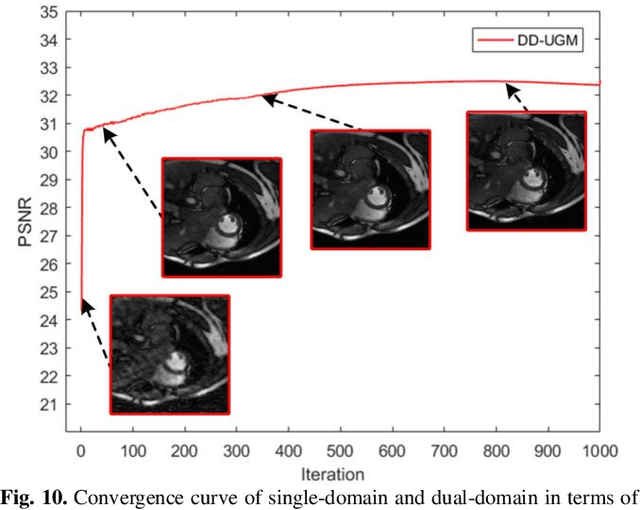
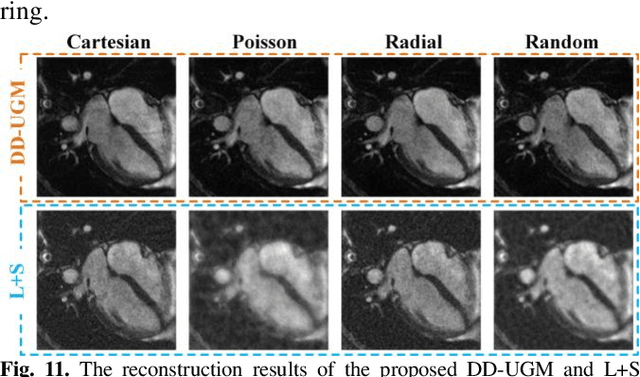
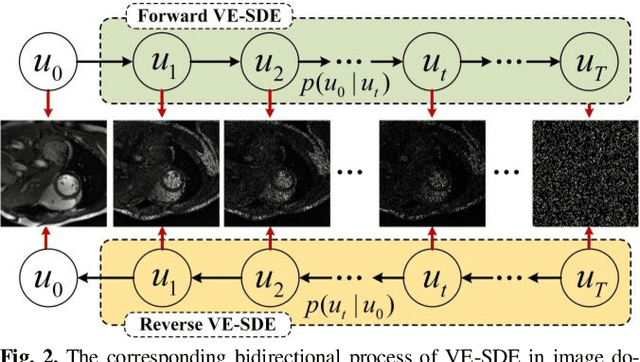
Dynamic magnetic resonance image reconstruction from incomplete k-space data has generated great research interest due to its capability to reduce scan time. Never-theless, the reconstruction problem is still challenging due to its ill-posed nature. Recently, diffusion models espe-cially score-based generative models have exhibited great potential in algorithm robustness and usage flexi-bility. Moreover, the unified framework through the variance exploding stochastic differential equation (VE-SDE) is proposed to enable new sampling methods and further extend the capabilities of score-based gener-ative models. Therefore, by taking advantage of the uni-fied framework, we proposed a k-space and image Du-al-Domain collaborative Universal Generative Model (DD-UGM) which combines the score-based prior with low-rank regularization penalty to reconstruct highly under-sampled measurements. More precisely, we extract prior components from both image and k-space domains via a universal generative model and adaptively handle these prior components for faster processing while maintaining good generation quality. Experimental comparisons demonstrated the noise reduction and detail preservation abilities of the proposed method. Much more than that, DD-UGM can reconstruct data of differ-ent frames by only training a single frame image, which reflects the flexibility of the proposed model.
A Data Source Dependency Analysis Framework for Large Scale Data Science Projects
Dec 15, 2022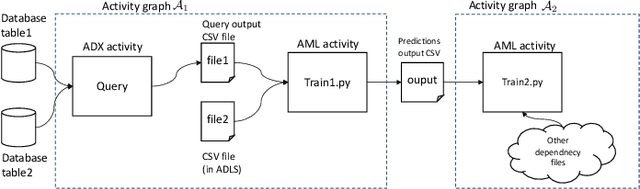
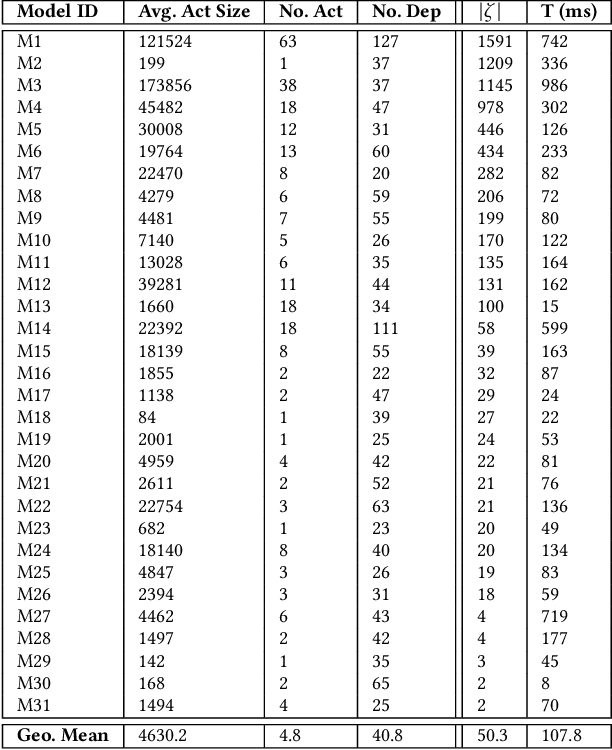

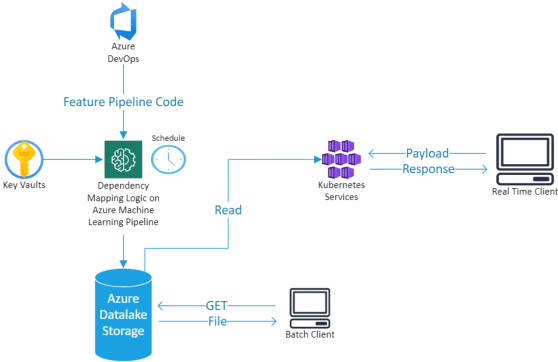
Dependency hell is a well-known pain point in the development of large software projects and machine learning (ML) code bases are not immune from it. In fact, ML applications suffer from an additional form, namely, "data source dependency hell". This term refers to the central role played by data and its unique quirks that often lead to unexpected failures of ML models which cannot be explained by code changes. In this paper, we present an automated dependency mapping framework that allows MLOps engineers to monitor the whole dependency map of their models in a fast paced engineering environment and thus mitigate ahead of time the consequences of any data source changes (e.g., re-train model, ignore data, set default data etc.). Our system is based on a unified and generic approach, employing techniques from static analysis, from which data sources can be identified reliably for any type of dependency on a wide range of source languages and artefacts. The dependency mapping framework is exposed as a REST web API where the only input is the path to the Git repository hosting the code base. Currently used by MLOps engineers at Microsoft, we expect such dependency map APIs to be adopted more widely by MLOps engineers in the future.
A Study on the Intersection of GPU Utilization and CNN Inference
Dec 15, 2022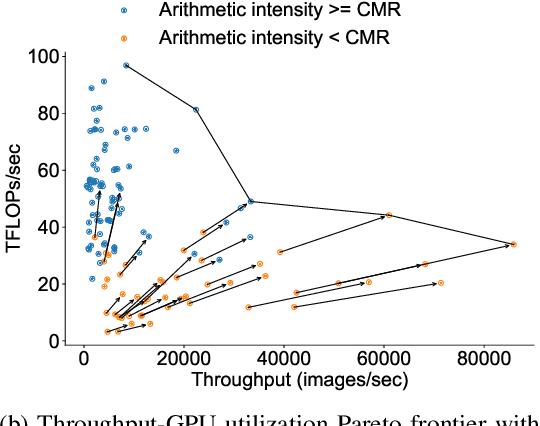
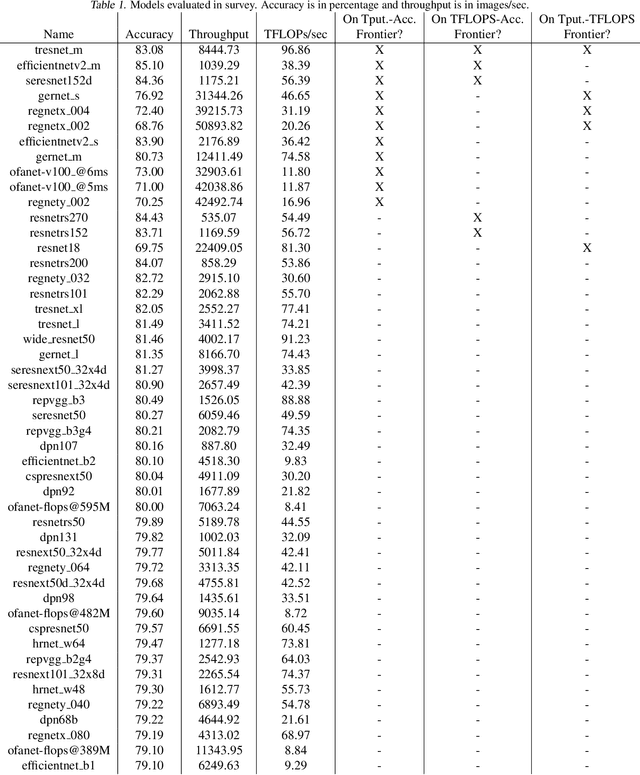
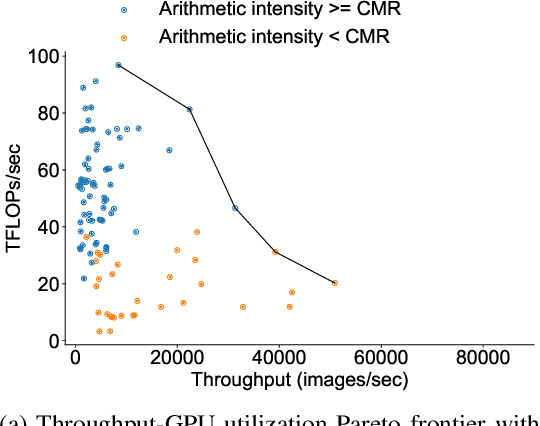
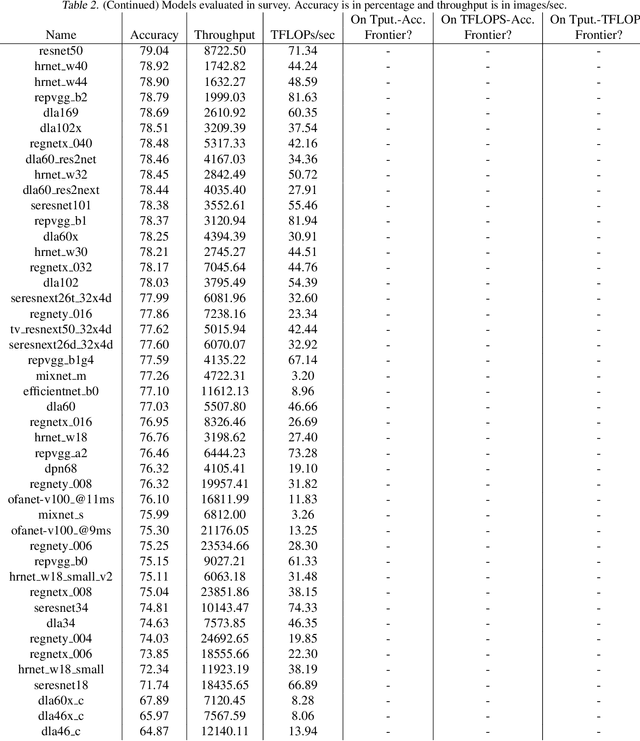
There has been significant progress in developing neural network architectures that both achieve high predictive performance and that also achieve high application-level inference throughput (e.g., frames per second). Another metric of increasing importance is GPU utilization during inference: the measurement of how well a deployed neural network uses the computational capabilities of the GPU on which it runs. Achieving high GPU utilization is critical to increasing application-level throughput and ensuring a good return on investment for deploying GPUs. This paper analyzes the GPU utilization of convolutional neural network (CNN) inference. We first survey the GPU utilization of CNNs to show that there is room to improve the GPU utilization of many of these CNNs. We then investigate the GPU utilization of networks within a neural architecture search (NAS) search space, and explore how using GPU utilization as a metric could potentially be used to accelerate NAS itself. Our study makes the case that there is room to improve the inference-time GPU utilization of CNNs and that knowledge of GPU utilization has the potential to benefit even applications that do not target utilization itself. We hope that the results of this study will spur future innovation in designing GPU-efficient neural networks.
A Latent Space Model for HLA Compatibility Networks in Kidney Transplantation
Nov 04, 2022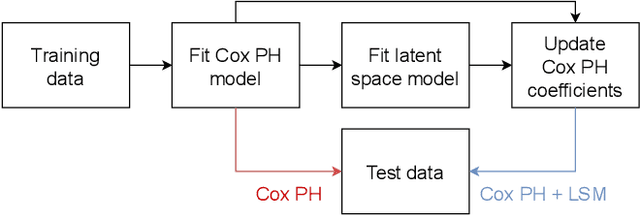
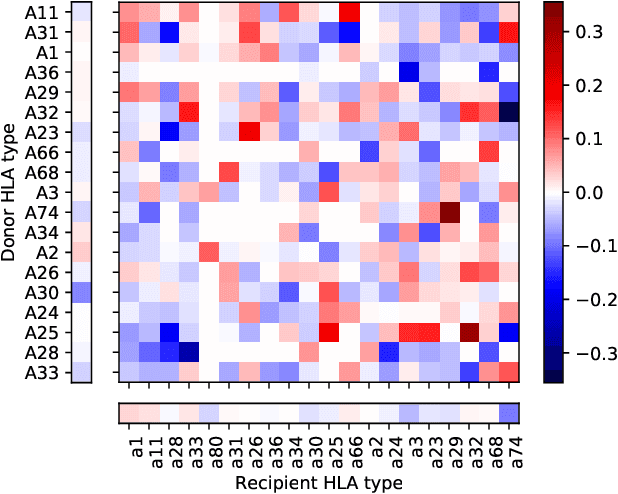
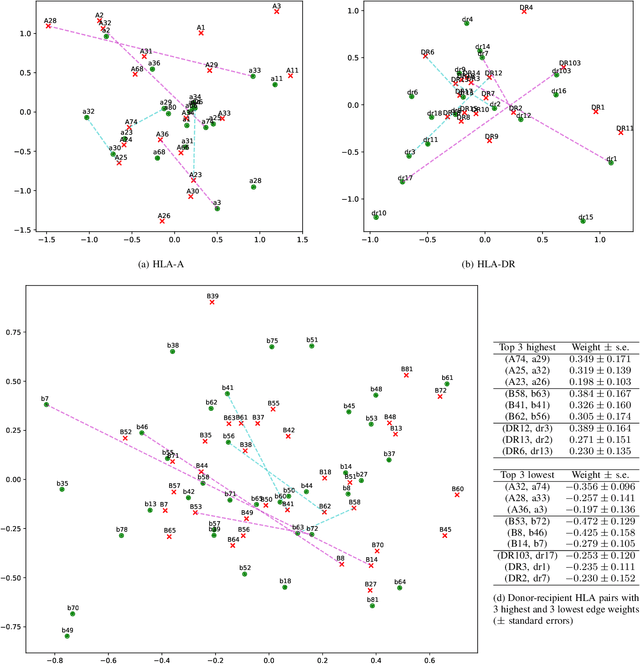
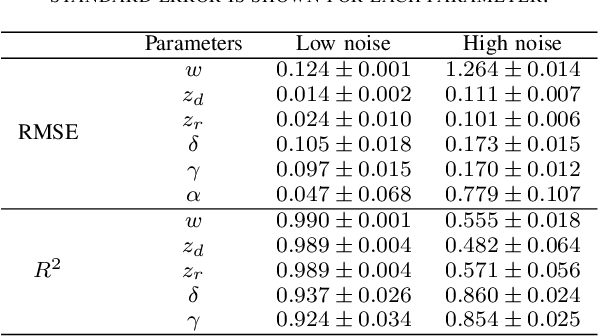
Kidney transplantation is the preferred treatment for people suffering from end-stage renal disease. Successful kidney transplants still fail over time, known as graft failure; however, the time to graft failure, or graft survival time, can vary significantly between different recipients. A significant biological factor affecting graft survival times is the compatibility between the human leukocyte antigens (HLAs) of the donor and recipient. We propose to model HLA compatibility using a network, where the nodes denote different HLAs of the donor and recipient, and edge weights denote compatibilities of the HLAs, which can be positive or negative. The network is indirectly observed, as the edge weights are estimated from transplant outcomes rather than directly observed. We propose a latent space model for such indirectly-observed weighted and signed networks. We demonstrate that our latent space model can not only result in more accurate estimates of HLA compatibilities, but can also be incorporated into survival analysis models to improve accuracy for the downstream task of predicting graft survival times.
GreenMO: Virtualized User-proportionate MIMO
Nov 29, 2022
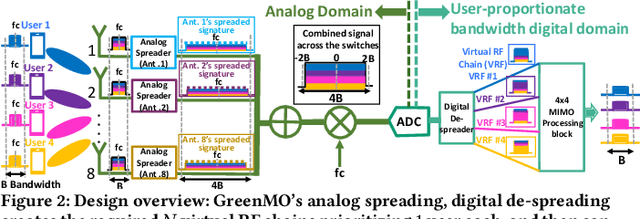
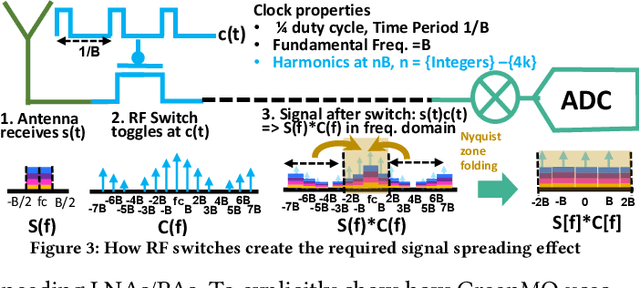
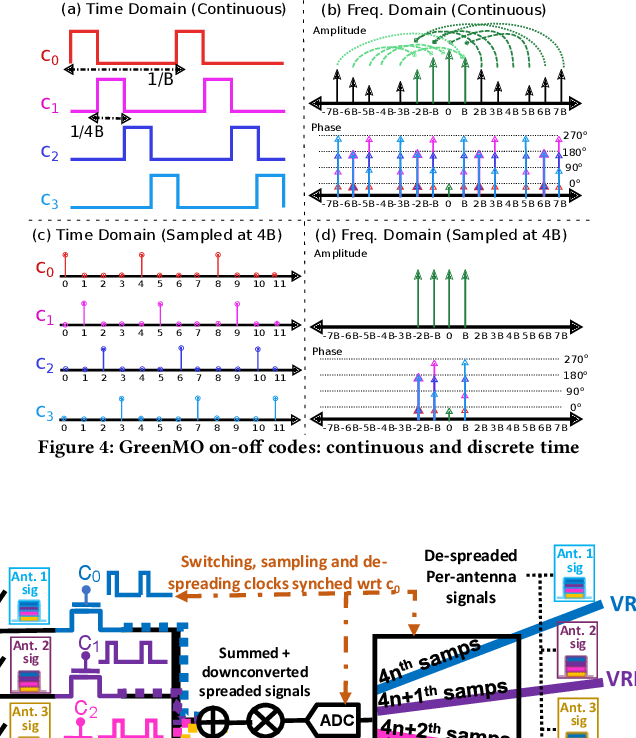
With the turn of new decade, wireless communications face a major challenge on connecting many more new users and devices, at the same time being energy efficient and minimizing its carbon footprint. However, the current approaches to address the growing number of users and spectrum demands, like traditional fully digital architectures for Massive MIMO, demand exorbitant energy consumption. The reason is that traditionally MIMO requires a separate RF chain per antenna, so the power consumption scales with number of antennas, instead of number of users, hence becomes energy inefficient. Instead, GreenMO creates a new massive MIMO architecture which is able to use many more antennas while keeping power consumption to user-proportionate numbers. To achieve this GreenMO introduces for the first time, the concept of virtualization of the RF chain hardware. Instead of laying the RF chains physically to each antenna, GreenMO creates these RF chains virtually in digital domain. This also enables GreenMO to be the first flexible massive MIMO architecture. Since GreenMO's virtual RF chains are created on the fly digitally, it can tune the number of these virtual chains according to the user load, hence always flexibly consume user-proportionate power. Thus, GreenMO paves the way for green and flexible massive MIMO. We prototype GreenMO on a PCB with eight antennas and evaluate it with a WARPv3 SDR platform in an office environment. The results demonstrate that GreenMO is 3x more power-efficient than traditional Massive MIMO and 4x more spectrum-efficient than traditional OFDMA systems, while multiplexing 4 users, and can save upto 40% power in modern 5G NR base stations.
Dynamic Sensor Placement Based on Graph Sampling Theory
Nov 08, 2022

In this paper, we consider a dynamic sensor placement problem where sensors can move within a network over time. Sensor placement problem aims to select M sensor positions from N candidates where M < N. Most existing methods assume that sensors are static, i.e., they do not move, however, many mobile sensors like drones, robots, and vehicles can change their positions over time. Moreover, underlying measurement conditions could also be changed that are difficult to cover the statically placed sensors. We tackle the problem by allowing the sensors to change their positions in their neighbors on the network. Based on a perspective of dictionary learning, we sequentially learn the dictionary from a pool of observed signals on the network based on graph sampling theory. Using the learned dictionary, we dynamically determine the sensor positions such that the non-observed signals on the network can be best recovered from the observations. Furthermore, sensor positions in each time slot can be optimized in a decentralized manner to reduce the calculation cost. In experiments, we validate the effectiveness of the proposed method via the mean squared error (MSE) of the reconstructed signals. The proposed dynamic sensor placement outperforms the existing static ones both in synthetic and real data.
VideoDex: Learning Dexterity from Internet Videos
Dec 08, 2022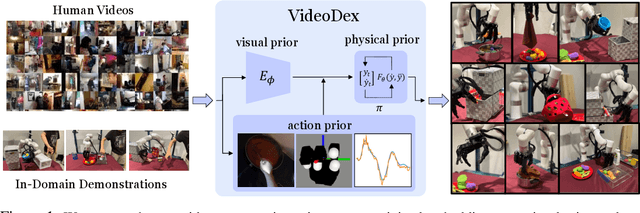
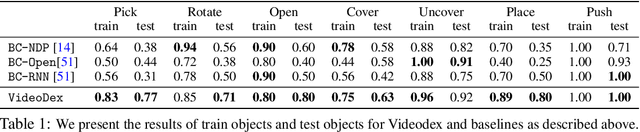

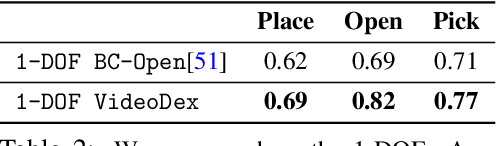
To build general robotic agents that can operate in many environments, it is often imperative for the robot to collect experience in the real world. However, this is often not feasible due to safety, time, and hardware restrictions. We thus propose leveraging the next best thing as real-world experience: internet videos of humans using their hands. Visual priors, such as visual features, are often learned from videos, but we believe that more information from videos can be utilized as a stronger prior. We build a learning algorithm, VideoDex, that leverages visual, action, and physical priors from human video datasets to guide robot behavior. These actions and physical priors in the neural network dictate the typical human behavior for a particular robot task. We test our approach on a robot arm and dexterous hand-based system and show strong results on various manipulation tasks, outperforming various state-of-the-art methods. Videos at https://video-dex.github.io
Runtime Analysis for the NSGA-II: Proving, Quantifying, and Explaining the Inefficiency For Many Objectives
Dec 08, 2022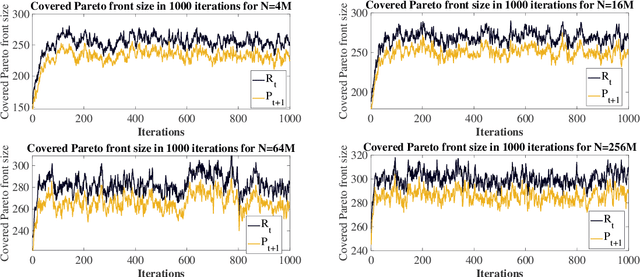
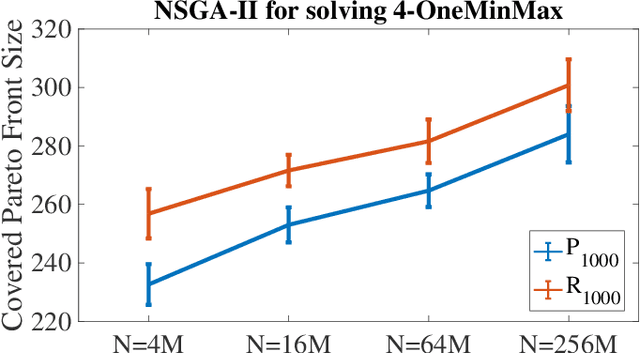
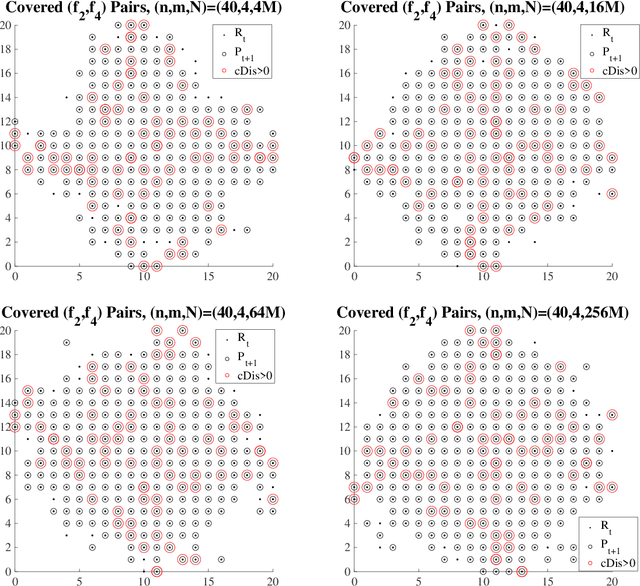
The NSGA-II is one of the most prominent algorithms to solve multi-objective optimization problems. Despite numerous successful applications, several studies have shown that the NSGA-II is less effective for larger numbers of objectives. In this work, we use mathematical runtime analyses to rigorously demonstrate and quantify this phenomenon. We show that even on the simple OneMinMax benchmark, where every solution is Pareto optimal, the NSGA-II also with large population sizes cannot compute the full Pareto front (objective vectors of all Pareto optima) in sub-exponential time when the number of objectives is at least three. Our proofs suggest that the reason for this unexpected behavior lies in the fact that in the computation of the crowding distance, the different objectives are regarded independently. This is not a problem for two objectives, where any sorting of a pair-wise incomparable set of solutions according to one objective is also such a sorting according to the other objective (in the inverse order).
Surround-view Fisheye BEV-Perception for Valet Parking: Dataset, Baseline and Distortion-insensitive Multi-task Framework
Dec 08, 2022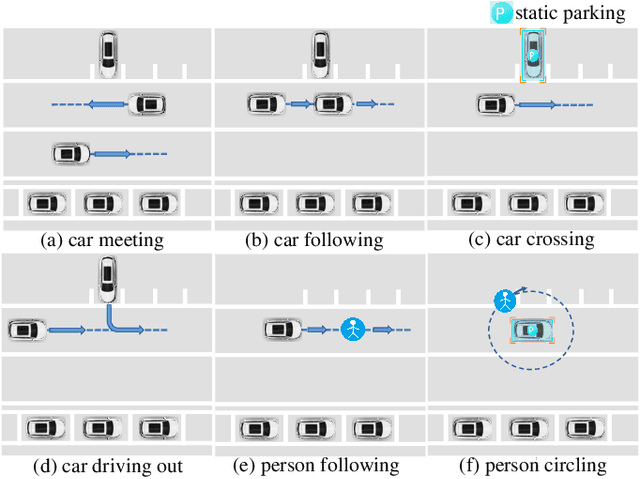


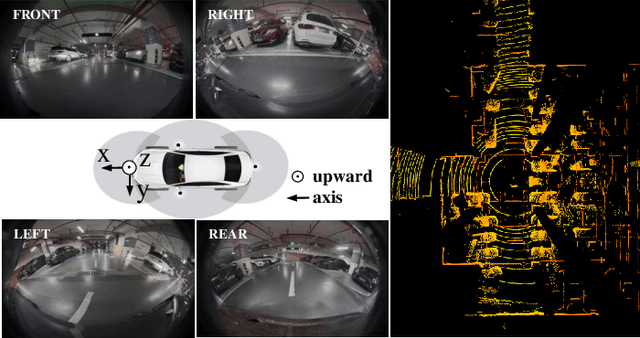
Surround-view fisheye perception under valet parking scenes is fundamental and crucial in autonomous driving. Environmental conditions in parking lots perform differently from the common public datasets, such as imperfect light and opacity, which substantially impacts on perception performance. Most existing networks based on public datasets may generalize suboptimal results on these valet parking scenes, also affected by the fisheye distortion. In this article, we introduce a new large-scale fisheye dataset called Fisheye Parking Dataset(FPD) to promote the research in dealing with diverse real-world surround-view parking cases. Notably, our compiled FPD exhibits excellent characteristics for different surround-view perception tasks. In addition, we also propose our real-time distortion-insensitive multi-task framework Fisheye Perception Network (FPNet), which improves the surround-view fisheye BEV perception by enhancing the fisheye distortion operation and multi-task lightweight designs. Extensive experiments validate the effectiveness of our approach and the dataset's exceptional generalizability.
* 12 pages, 11 figures