 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed Average Consensus via Noisy and Non-Coherent Over-the-Air Aggregation
Mar 11, 2024
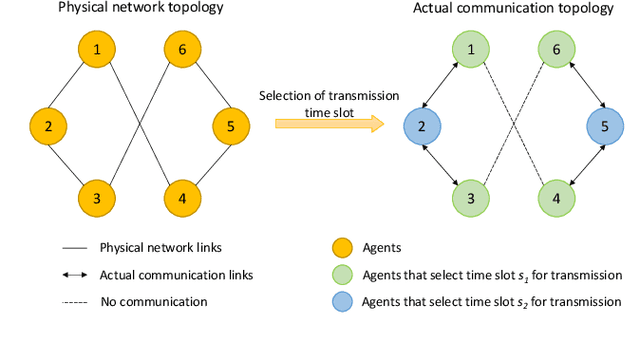
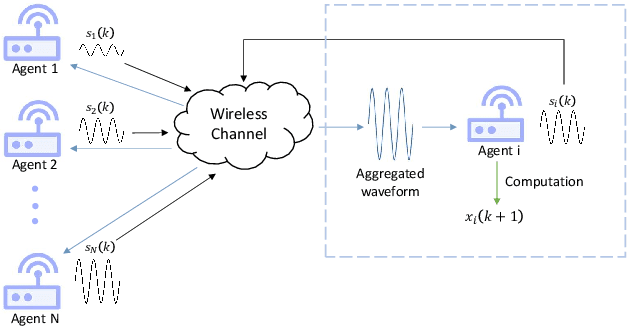
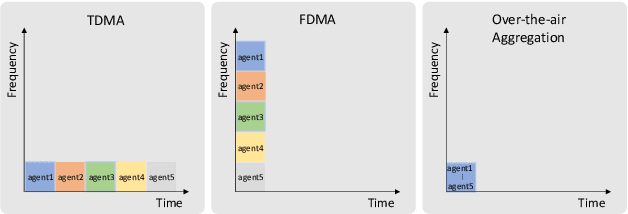
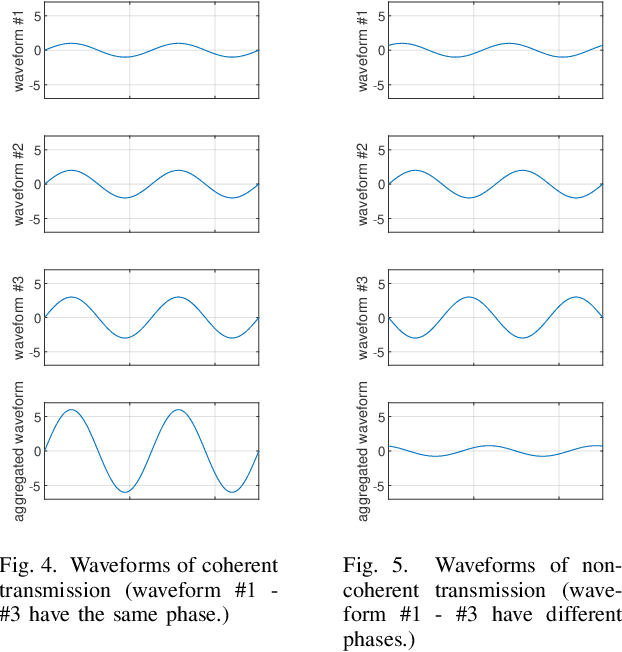
Over-the-air aggregation has attracted widespread attention for its potential advantages in task-oriented applications, such as distributed sensing, learning, and consensus. In this paper, we develop a communication-efficient distributed average consensus protocol by utilizing over-the-air aggregation, which exploits the superposition property of wireless channels rather than combat it. Noisy channels and non-coherent transmission are taken into account, and only half-duplex transceivers are required. We prove that the system can achieve average consensus in mean square and even almost surely under the proposed protocol. Furthermore, we extend the analysis to the scenarios with time-varying topology. Numerical simulation shows the effectiveness of the proposed protocol.
United We Pretrain, Divided We Fail! Representation Learning for Time Series by Pretraining on 75 Datasets at Once
Feb 23, 2024In natural language processing and vision, pretraining is utilized to learn effective representations. Unfortunately, the success of pretraining does not easily carry over to time series due to potential mismatch between sources and target. Actually, common belief is that multi-dataset pretraining does not work for time series! Au contraire, we introduce a new self-supervised contrastive pretraining approach to learn one encoding from many unlabeled and diverse time series datasets, so that the single learned representation can then be reused in several target domains for, say, classification. Specifically, we propose the XD-MixUp interpolation method and the Soft Interpolation Contextual Contrasting (SICC) loss. Empirically, this outperforms both supervised training and other self-supervised pretraining methods when finetuning on low-data regimes. This disproves the common belief: We can actually learn from multiple time series datasets, even from 75 at once.
Cafe-Mpc: A Cascaded-Fidelity Model Predictive Control Framework with Tuning-Free Whole-Body Control
Mar 09, 2024

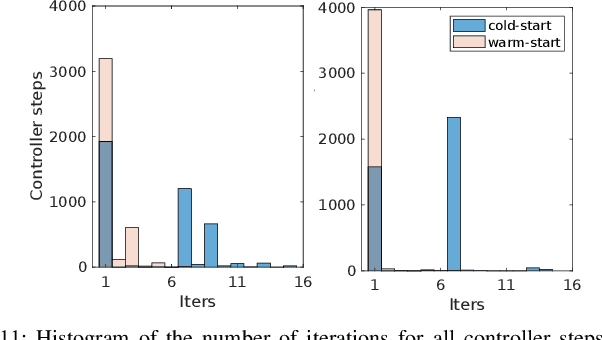
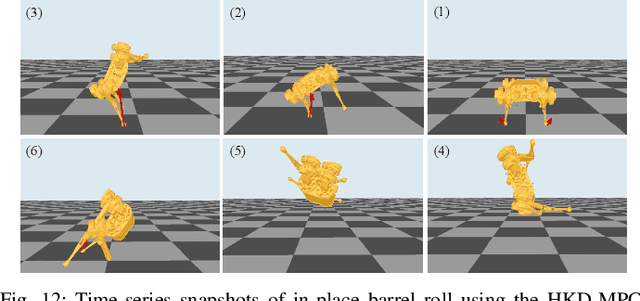
This work introduces an optimization-based locomotion control framework for on-the-fly synthesis of complex dynamic maneuvers. At the core of the proposed framework is a cascaded-fidelity model predictive controller (Cafe-Mpc). Cafe-Mpc strategically relaxes the planning problem along the prediction horizon (i.e., with descending model fidelity, increasingly coarse time steps, and relaxed constraints) for computational and performance gains. This problem is numerically solved with an efficient customized multiple-shooting iLQR (MS-iLQR) solver that is tailored for hybrid systems. The action-value function from Cafe-Mpc is then used as the basis for a new value-function-based whole-body control (VWBC) technique that avoids additional tuning for the WBC. In this respect, the proposed framework unifies whole-body MPC and more conventional whole-body quadratic programming (QP), which have been treated as separate components in previous works. We study the effects of the cascaded relaxations in Cafe-Mpc on the tracking performance and required computation time. We also show that the Cafe-Mpc, if configured appropriately, advances the performance of whole-body MPC without necessarily increasing computational cost. Further, we show the superior performance of the proposed VWBC over the Ricatti feedback controller in terms of constraint handling. The proposed framework enables accomplishing for the first time gymnastic-style running barrel roll on the MIT Mini Cheetah, a task where conventional MPC fails. Video: https://youtu.be/YiNqrgj9mb8.
FogGuard: guarding YOLO against fog using perceptual loss
Mar 13, 2024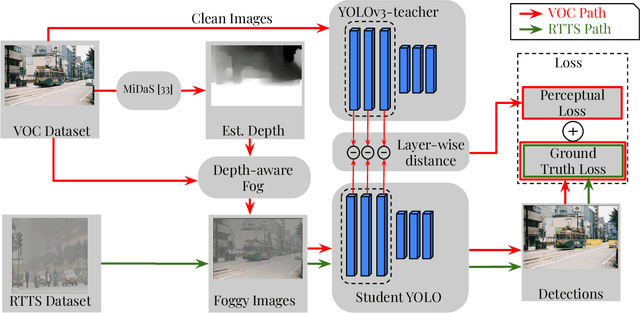
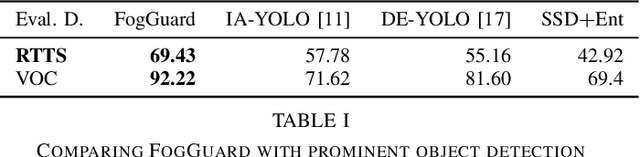

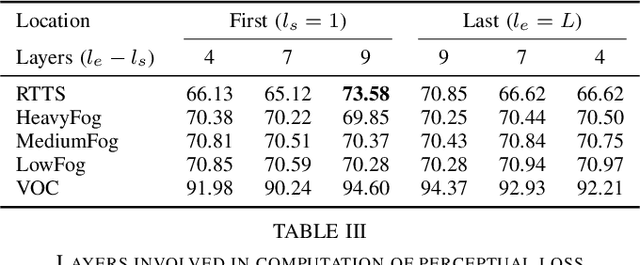
In this paper, we present a novel fog-aware object detection network called FogGuard, designed to address the challenges posed by foggy weather conditions. Autonomous driving systems heavily rely on accurate object detection algorithms, but adverse weather conditions can significantly impact the reliability of deep neural networks (DNNs). Existing approaches fall into two main categories, 1) image enhancement such as IA-YOLO 2) domain adaptation based approaches. Image enhancement based techniques attempt to generate fog-free image. However, retrieving a fogless image from a foggy image is a much harder problem than detecting objects in a foggy image. Domain-adaptation based approaches, on the other hand, do not make use of labelled datasets in the target domain. Both categories of approaches are attempting to solve a harder version of the problem. Our approach builds over fine-tuning on the Our framework is specifically designed to compensate for foggy conditions present in the scene, ensuring robust performance even. We adopt YOLOv3 as the baseline object detection algorithm and introduce a novel Teacher-Student Perceptual loss, to high accuracy object detection in foggy images. Through extensive evaluations on common datasets such as PASCAL VOC and RTTS, we demonstrate the improvement in performance achieved by our network. We demonstrate that FogGuard achieves 69.43\% mAP, as compared to 57.78\% for YOLOv3 on the RTTS dataset. Furthermore, we show that while our training method increases time complexity, it does not introduce any additional overhead during inference compared to the regular YOLO network.
Fast Inference of Removal-Based Node Influence
Mar 13, 2024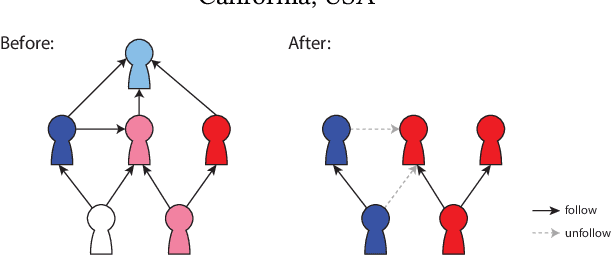


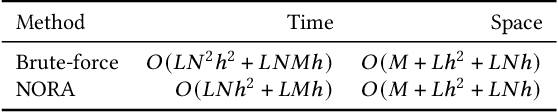
Graph neural networks (GNNs) are widely utilized to capture the information spreading patterns in graphs. While remarkable performance has been achieved, there is a new trending topic of evaluating node influence. We propose a new method of evaluating node influence, which measures the prediction change of a trained GNN model caused by removing a node. A real-world application is, "In the task of predicting Twitter accounts' polarity, had a particular account been removed, how would others' polarity change?". We use the GNN as a surrogate model whose prediction could simulate the change of nodes or edges caused by node removal. To obtain the influence for every node, a straightforward way is to alternately remove every node and apply the trained GNN on the modified graph. It is reliable but time-consuming, so we need an efficient method. The related lines of work, such as graph adversarial attack and counterfactual explanation, cannot directly satisfy our needs, since they do not focus on the global influence score for every node. We propose an efficient and intuitive method, NOde-Removal-based fAst GNN inference (NORA), which uses the gradient to approximate the node-removal influence. It only costs one forward propagation and one backpropagation to approximate the influence score for all nodes. Extensive experiments on six datasets and six GNN models verify the effectiveness of NORA. Our code is available at https://github.com/weikai-li/NORA.git.
Optimizing Risk-averse Human-AI Hybrid Teams
Mar 13, 2024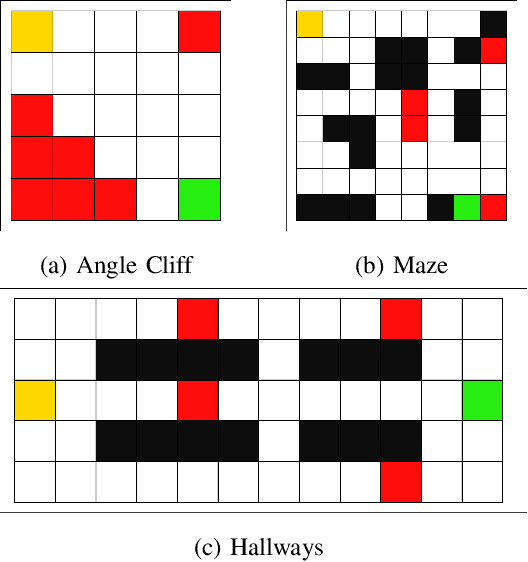
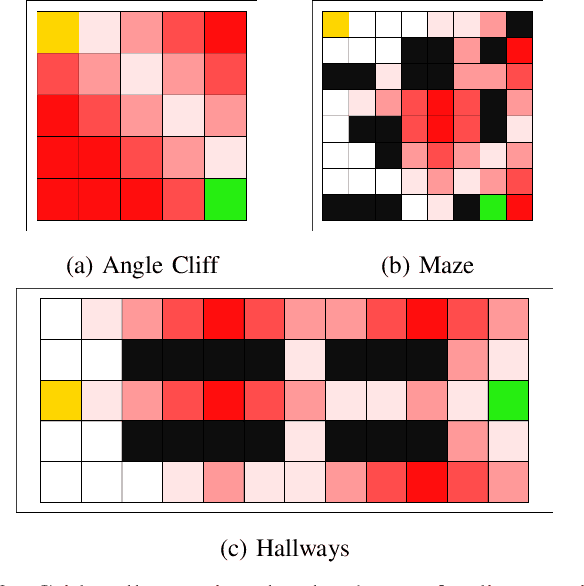
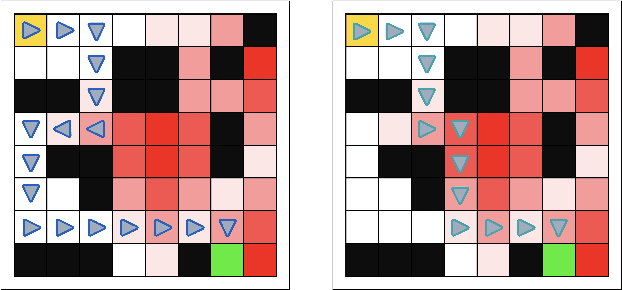
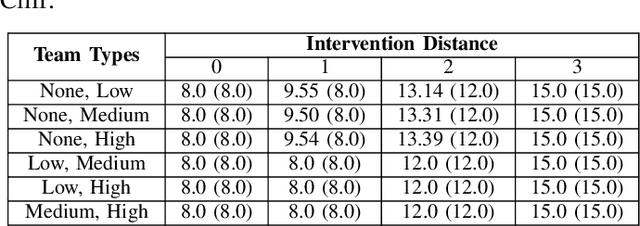
We anticipate increased instances of humans and AI systems working together in what we refer to as a hybrid team. The increase in collaboration is expected as AI systems gain proficiency and their adoption becomes more widespread. However, their behavior is not error-free, making hybrid teams a very suitable solution. As such, we consider methods for improving performance for these teams of humans and AI systems. For hybrid teams, we will refer to both the humans and AI systems as agents. To improve team performance over that seen for agents operating individually, we propose a manager which learns, through a standard Reinforcement Learning scheme, how to best delegate, over time, the responsibility of taking a decision to any of the agents. We further guide the manager's learning so they also minimize how many changes in delegation are made resulting from undesirable team behavior. We demonstrate the optimality of our manager's performance in several grid environments which include failure states which terminate an episode and should be avoided. We perform our experiments with teams of agents with varying degrees of acceptable risk, in the form of proximity to a failure state, and measure the manager's ability to make effective delegation decisions with respect to its own risk-based constraints, then compare these to the optimal decisions. Our results show our manager can successfully learn desirable delegations which result in team paths near/exactly optimal with respect to path length and number of delegations.
MD-Dose: A Diffusion Model based on the Mamba for Radiotherapy Dose Prediction
Mar 13, 2024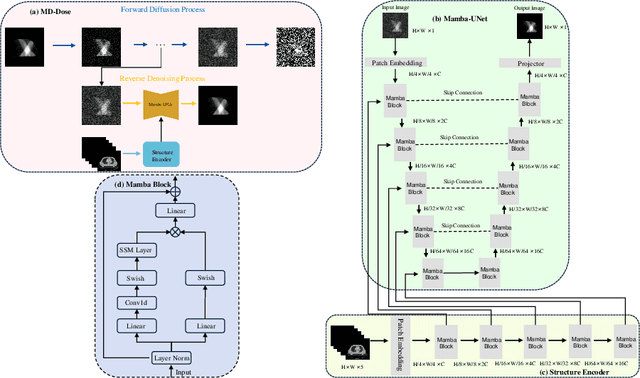
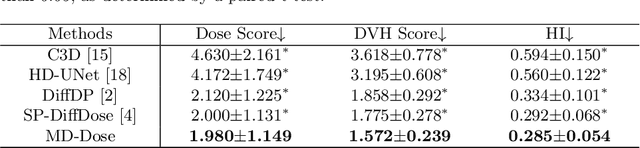
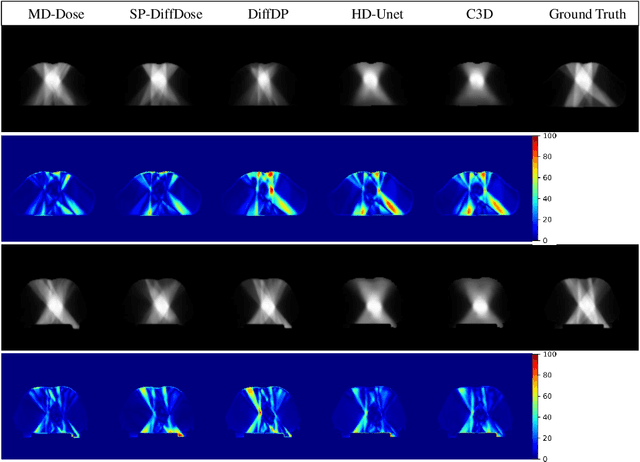
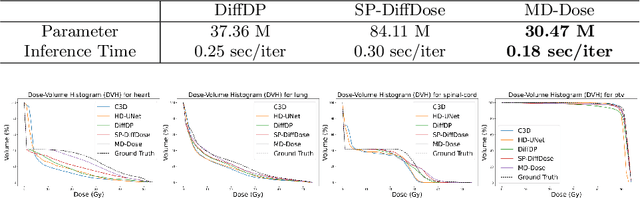
Radiation therapy is crucial in cancer treatment. Experienced experts typically iteratively generate high-quality dose distribution maps, forming the basis for excellent radiation therapy plans. Therefore, automated prediction of dose distribution maps is significant in expediting the treatment process and providing a better starting point for developing radiation therapy plans. With the remarkable results of diffusion models in predicting high-frequency regions of dose distribution maps, dose prediction methods based on diffusion models have been extensively studied. However, existing methods mainly utilize CNNs or Transformers as denoising networks. CNNs lack the capture of global receptive fields, resulting in suboptimal prediction performance. Transformers excel in global modeling but face quadratic complexity with image size, resulting in significant computational overhead. To tackle these challenges, we introduce a novel diffusion model, MD-Dose, based on the Mamba architecture for predicting radiation therapy dose distribution in thoracic cancer patients. In the forward process, MD-Dose adds Gaussian noise to dose distribution maps to obtain pure noise images. In the backward process, MD-Dose utilizes a noise predictor based on the Mamba to predict the noise, ultimately outputting the dose distribution maps. Furthermore, We develop a Mamba encoder to extract structural information and integrate it into the noise predictor for localizing dose regions in the planning target volume (PTV) and organs at risk (OARs). Through extensive experiments on a dataset of 300 thoracic tumor patients, we showcase the superiority of MD-Dose in various metrics and time consumption.
Pig aggression classification using CNN, Transformers and Recurrent Networks
Mar 13, 2024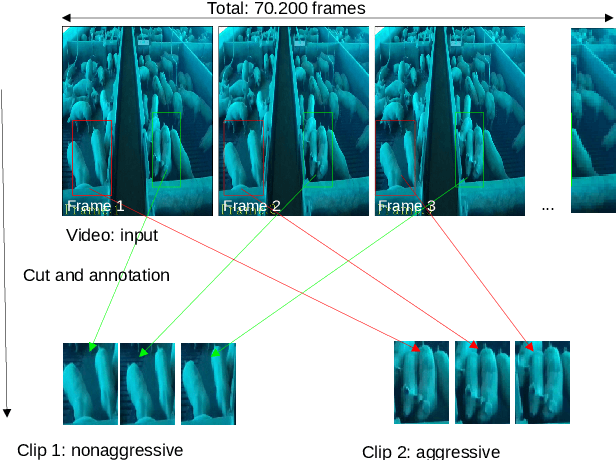
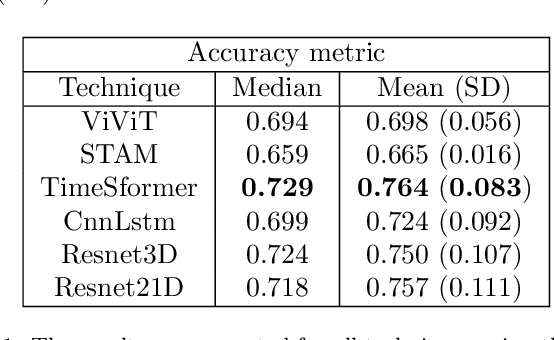

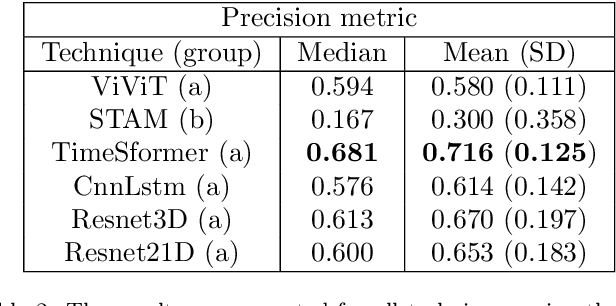
The development of techniques that can be used to analyze and detect animal behavior is a crucial activity for the livestock sector, as it is possible to monitor the stress and animal welfare and contributes to decision making in the farm. Thus, the development of applications can assist breeders in making decisions to improve production performance and reduce costs, once the animal behavior is analyzed by humans and this can lead to susceptible errors and time consumption. Aggressiveness in pigs is an example of behavior that is studied to reduce its impact through animal classification and identification. However, this process is laborious and susceptible to errors, which can be reduced through automation by visually classifying videos captured in controlled environment. The captured videos can be used for training and, as a result, for classification through computer vision and artificial intelligence, employing neural network techniques. The main techniques utilized in this study are variants of transformers: STAM, TimeSformer, and ViViT, as well as techniques using convolutions, such as ResNet3D2, Resnet(2+1)D, and CnnLstm. These techniques were employed for pig video classification with the objective of identifying aggressive and non-aggressive behaviors. In this work, various techniques were compared to analyze the contribution of using transformers, in addition to the effectiveness of the convolution technique in video classification. The performance was evaluated using accuracy, precision, and recall. The TimerSformer technique showed the best results in video classification, with median accuracy of 0.729.
Local Binary and Multiclass SVMs Trained on a Quantum Annealer
Mar 13, 2024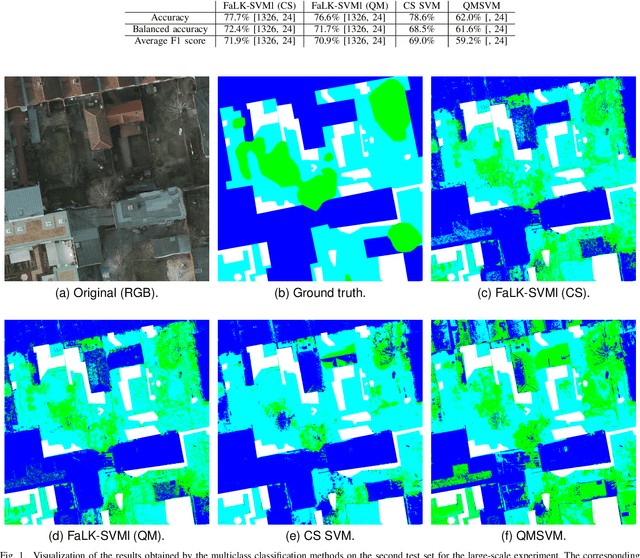



Support vector machines (SVMs) are widely used machine learning models (e.g., in remote sensing), with formulations for both classification and regression tasks. In the last years, with the advent of working quantum annealers, hybrid SVM models characterised by quantum training and classical execution have been introduced. These models have demonstrated comparable performance to their classical counterparts. However, they are limited in the training set size due to the restricted connectivity of the current quantum annealers. Hence, to take advantage of large datasets (like those related to Earth observation), a strategy is required. In the classical domain, local SVMs, namely, SVMs trained on the data samples selected by a k-nearest neighbors model, have already proven successful. Here, the local application of quantum-trained SVM models is proposed and empirically assessed. In particular, this approach allows overcoming the constraints on the training set size of the quantum-trained models while enhancing their performance. In practice, the FaLK-SVM method, designed for efficient local SVMs, has been combined with quantum-trained SVM models for binary and multiclass classification. In addition, for comparison, FaLK-SVM has been interfaced for the first time with a classical single-step multiclass SVM model (CS SVM). Concerning the empirical evaluation, D-Wave's quantum annealers and real-world datasets taken from the remote sensing domain have been employed. The results have shown the effectiveness and scalability of the proposed approach, but also its practical applicability in a real-world large-scale scenario.
A Generalized Framework with Adaptive Weighted Soft-Margin for Imbalanced SVM Classification
Mar 13, 2024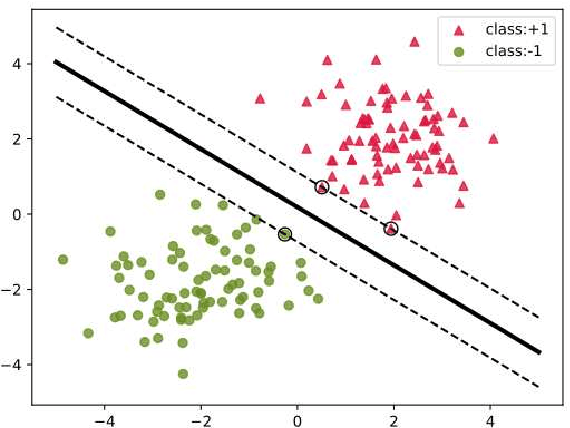

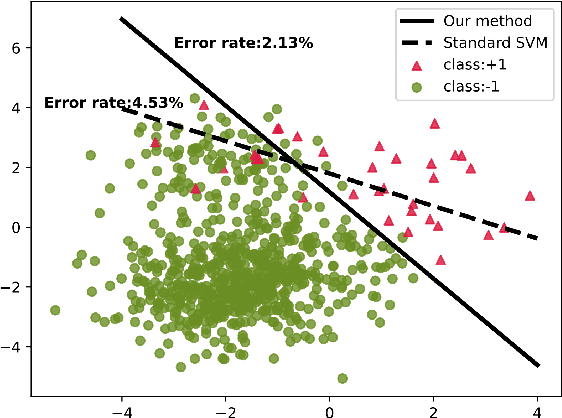
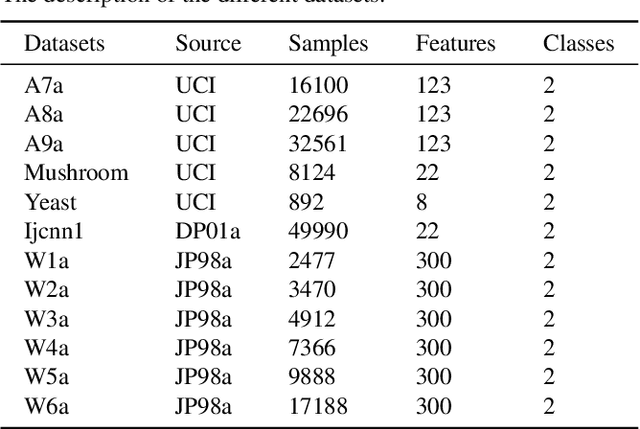
Category imbalance is one of the most popular and important issues in the domain of classification. In this paper, we present a new generalized framework with Adaptive Weight function for soft-margin Weighted SVM (AW-WSVM), which aims to enhance the issue of imbalance and outlier sensitivity in standard support vector machine (SVM) for classifying two-class data. The weight coefficient is introduced into the unconstrained soft-margin support vector machines, and the sample weights are updated before each training. The Adaptive Weight function (AW function) is constructed from the distance between the samples and the decision hyperplane, assigning different weights to each sample. A weight update method is proposed, taking into account the proximity of the support vectors to the decision hyperplane. Before training, the weights of the corresponding samples are initialized according to different categories. Subsequently, the samples close to the decision hyperplane are identified and assigned more weights. At the same time, lower weights are assigned to samples that are far from the decision hyperplane. Furthermore, we also put forward an effective way to eliminate noise. To evaluate the strength of the proposed generalized framework, we conducted experiments on standard datasets and emotion classification datasets with different imbalanced ratios (IR). The experimental results prove that the proposed generalized framework outperforms in terms of accuracy, recall metrics and G-mean, validating the effectiveness of the weighted strategy provided in this paper in enhancing support vector machines.