 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Diverse legal case search
Jan 29, 2023
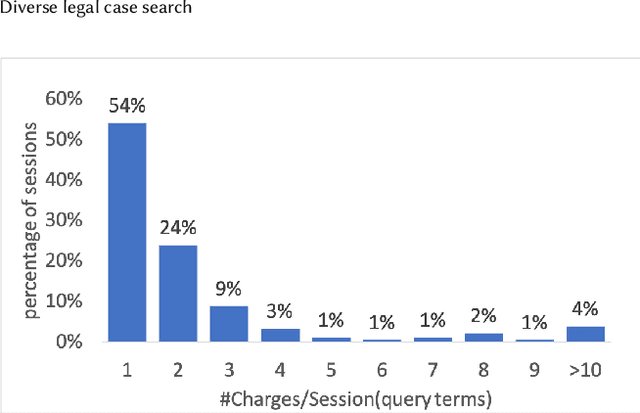

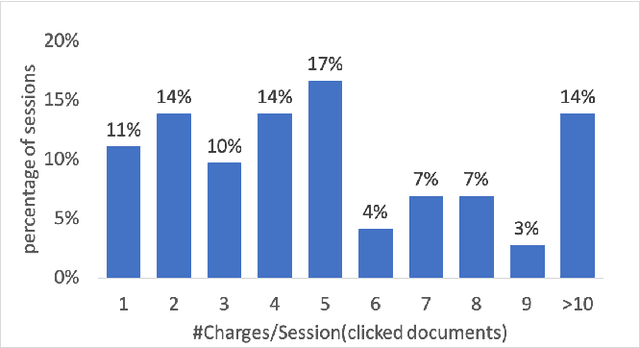

In last decades, legal case search has received more and more attention. Legal practitioners need to work or enhance their efficiency by means of class case search. In the process of searching, legal practitioners often need the search results under several different causes of cases as reference. However, existing work tends to focus on the relevance of the judgments themselves, without considering the connection between the causes of action. Several well-established diversity search techniques already exist in open-field search efforts. However, these techniques do not take into account the specificity of legal search scenarios, e.g., the subtopic may not be independent of each other, but somehow connected. Therefore, we construct a diversity legal retrieval model. This model takes into account both diversity and relevance, and is well adapted to this scenario. At the same time, considering the lack of dataset with diversity labels, we constructed a diversity legal retrieval dataset and obtained labels by manual labeling. experiments confirmed that our model is effective.
On Enhancing Expressive Power via Compositions of Single Fixed-Size ReLU Network
Jan 29, 2023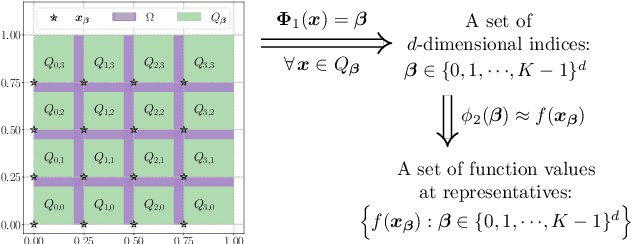
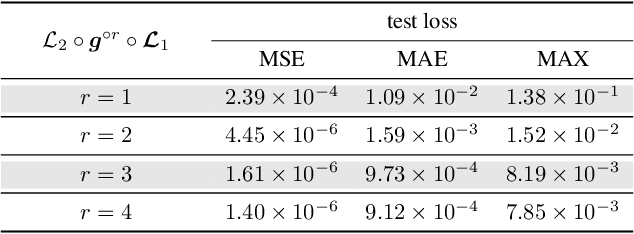
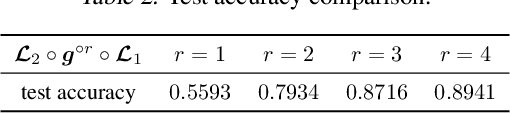
This paper studies the expressive power of deep neural networks from the perspective of function compositions. We show that repeated compositions of a single fixed-size ReLU network can produce super expressive power. In particular, we prove by construction that $\mathcal{L}_2\circ \boldsymbol{g}^{\circ r}\circ \boldsymbol{\mathcal{L}}_1$ can approximate $1$-Lipschitz continuous functions on $[0,1]^d$ with an error $\mathcal{O}(r^{-1/d})$, where $\boldsymbol{g}$ is realized by a fixed-size ReLU network, $\boldsymbol{\mathcal{L}}_1$ and $\mathcal{L}_2$ are two affine linear maps matching the dimensions, and $\boldsymbol{g}^{\circ r}$ means the $r$-times composition of $\boldsymbol{g}$. Furthermore, we extend such a result to generic continuous functions on $[0,1]^d$ with the approximation error characterized by the modulus of continuity. Our results reveal that a continuous-depth network generated via a dynamical system has good approximation power even if its dynamics function is time-independent and realized by a fixed-size ReLU network.
Analysis of Biomass Sustainability Indicators from a Machine Learning Perspective
Feb 02, 2023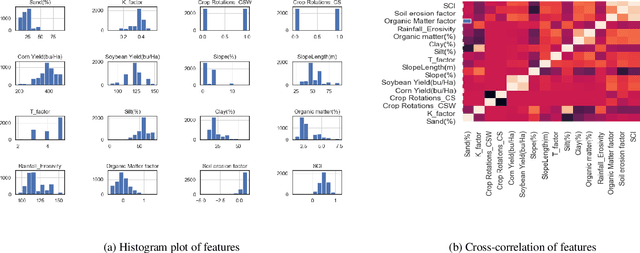
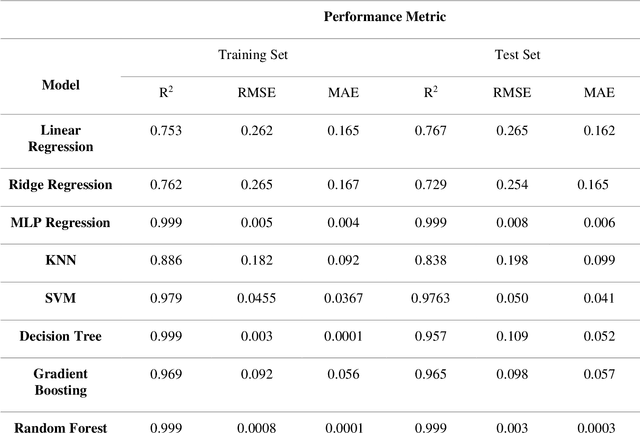
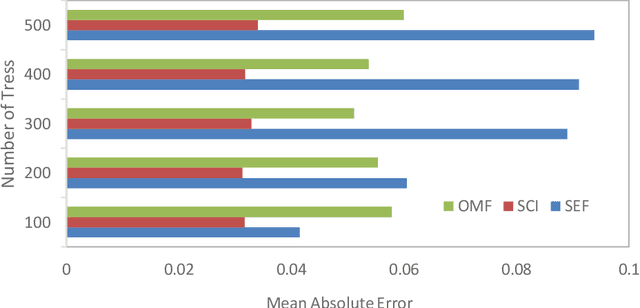
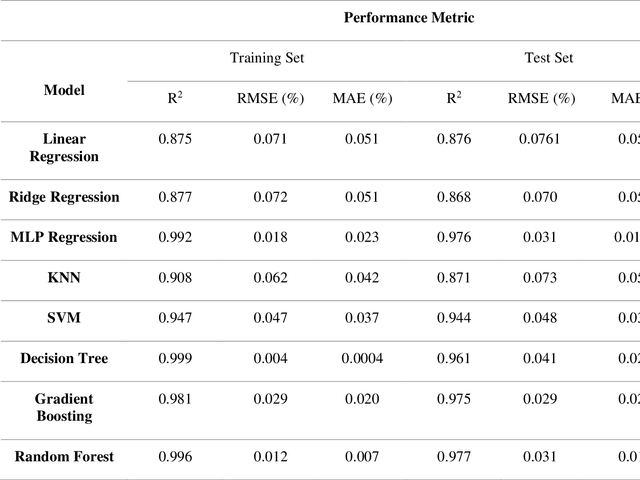
Plant biomass estimation is critical due to the variability of different environmental factors and crop management practices associated with it. The assessment is largely impacted by the accurate prediction of different environmental sustainability indicators. A robust model to predict sustainability indicators is a must for the biomass community. This study proposes a robust model for biomass sustainability prediction by analyzing sustainability indicators using machine learning models. The prospect of ensemble learning was also investigated to analyze the regression problem. All experiments were carried out on a crop residue data from the Ohio state. Ten machine learning models, namely, linear regression, ridge regression, multilayer perceptron, k-nearest neighbors, support vector machine, decision tree, gradient boosting, random forest, stacking and voting, were analyzed to estimate three biomass sustainability indicators, namely soil erosion factor, soil conditioning index, and organic matter factor. The performance of the model was assessed using cross-correlation (R2), root mean squared error and mean absolute error metrics. The results showed that Random Forest was the best performing model to assess sustainability indicators. The analyzed model can now serve as a guide for assessing sustainability indicators in real time.
adSformers: Personalization from Short-Term Sequences and Diversity of Representations in Etsy Ads
Feb 02, 2023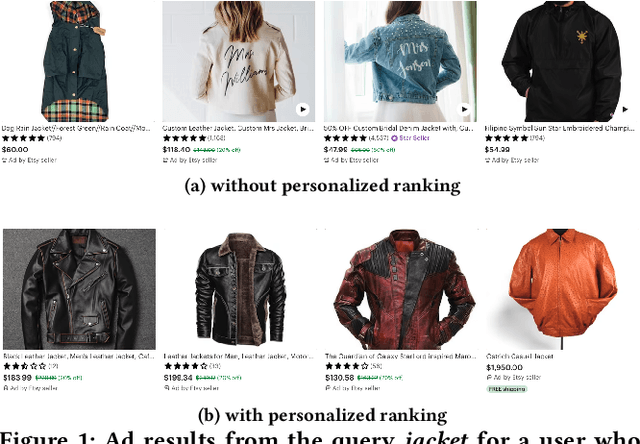

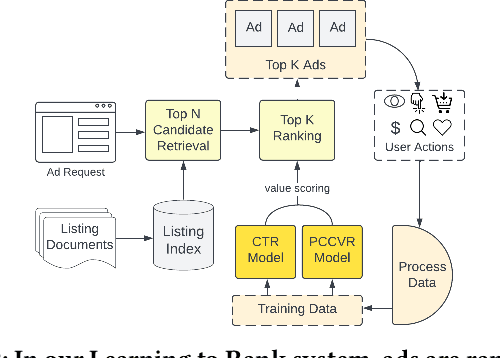
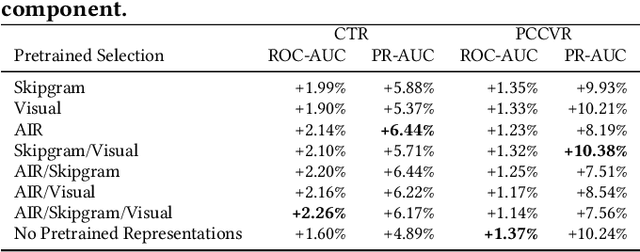
In this article, we present our approach to personalizing Etsy Ads through encoding and learning from short-term (one-hour) sequences of user actions and diverse representations. To this end we introduce a three-component adSformer diversifiable personalization module (ADPM) and illustrate how we use this module to derive a short-term dynamic user representation and personalize the Click-Through Rate (CTR) and Post-Click Conversion Rate (PCCVR) models used in sponsored search (ad) ranking. The first component of the ADPM is a custom transformer encoder that learns the inherent structure from the sequence of actions. ADPM's second component enriches the signal through visual, multimodal and textual pretrained representations. Lastly, the third ADPM component includes a "learned" on the fly average pooled representation. The ADPM-personalized CTR and PCCVR models, henceforth referred to as adSformer CTR and adSformer PCCVR, outperform the CTR and PCCVR production baselines by $+6.65\%$ and $+12.70\%$, respectively, in offline Precision-Recall Area Under the Curve (PR AUC). At the time of this writing, following the online gains in A/B tests, such as $+5.34\%$ in return on ad spend, a seller success metric, we are ramping up the adSformers to $100\%$ traffic in Etsy Ads.
Energy Efficient Training of SNN using Local Zeroth Order Method
Feb 02, 2023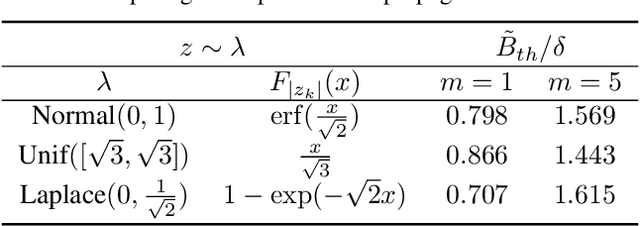
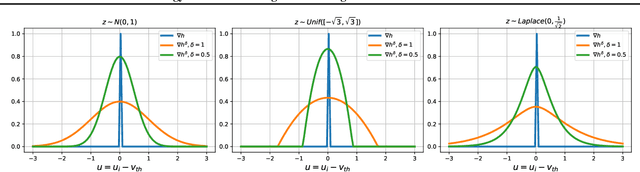
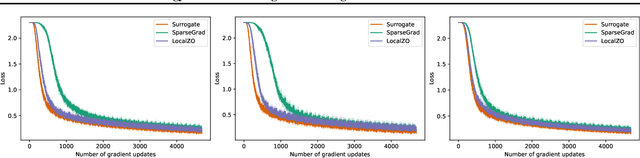
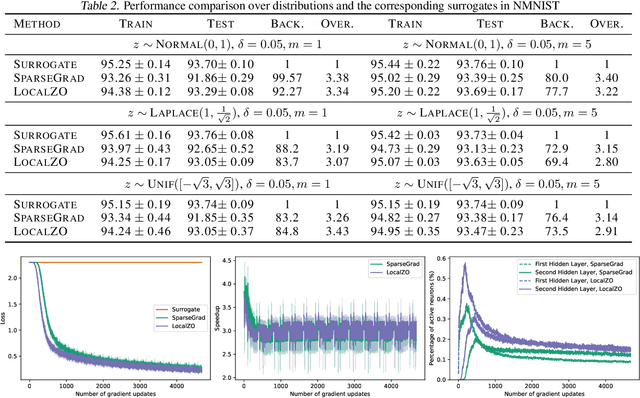
Spiking neural networks are becoming increasingly popular for their low energy requirement in real-world tasks with accuracy comparable to the traditional ANNs. SNN training algorithms face the loss of gradient information and non-differentiability due to the Heaviside function in minimizing the model loss over model parameters. To circumvent the problem surrogate method uses a differentiable approximation of the Heaviside in the backward pass, while the forward pass uses the Heaviside as the spiking function. We propose to use the zeroth order technique at the neuron level to resolve this dichotomy and use it within the automatic differentiation tool. As a result, we establish a theoretical connection between the proposed local zeroth-order technique and the existing surrogate methods and vice-versa. The proposed method naturally lends itself to energy-efficient training of SNNs on GPUs. Experimental results with neuromorphic datasets show that such implementation requires less than 1 percent neurons to be active in the backward pass, resulting in a 100x speed-up in the backward computation time. Our method offers better generalization compared to the state-of-the-art energy-efficient technique while maintaining similar efficiency.
Toward Efficient Physical and Algorithmic Design of Automated Garages
Feb 02, 2023
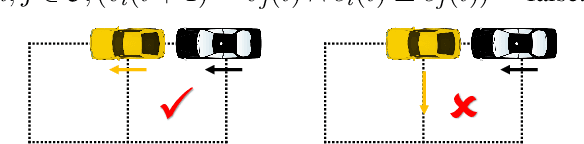
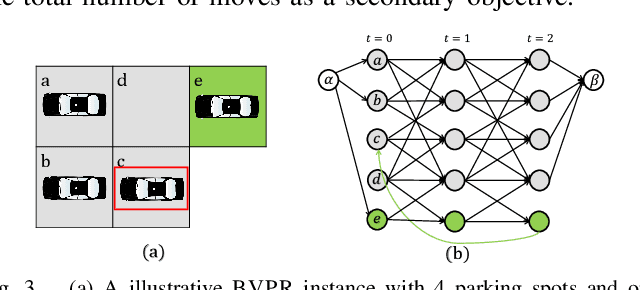

Parking in large metropolitan areas is often a time-consuming task with further implications toward traffic patterns that affect urban landscaping. Reducing the premium space needed for parking has led to the development of automated mechanical parking systems. Compared to regular garages having one or two rows of vehicles in each island, automated garages can have multiple rows of vehicles stacked together to support higher parking demands. Although this multi-row layout reduces parking space, it makes the parking and retrieval more complicated. In this work, we propose an automated garage design that supports near 100% parking density. Modeling the problem of parking and retrieving multiple vehicles as a special class of multi-robot path planning problem, we propose associated algorithms for handling all common operations of the automated garage, including (1) optimal algorithm and near-optimal methods that find feasible and efficient solutions for simultaneous parking/retrieval and (2) a novel shuffling mechanism to rearrange vehicles to facilitate scheduled retrieval at rush hours. We conduct thorough simulation studies showing the proposed methods are promising for large and high-density real-world parking applications.
Quantum Recurrent Neural Networks for Sequential Learning
Feb 07, 2023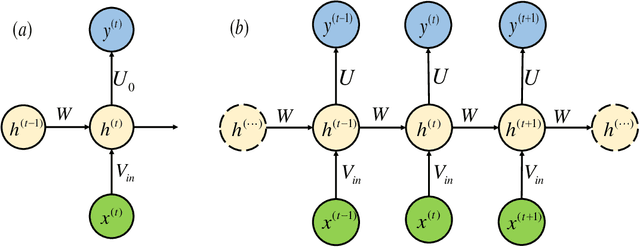
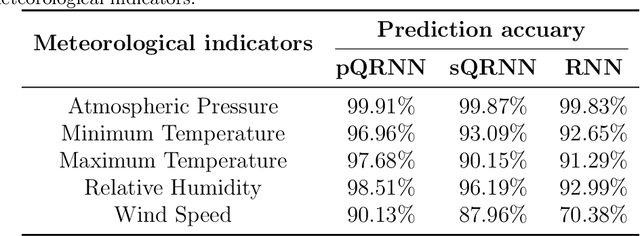
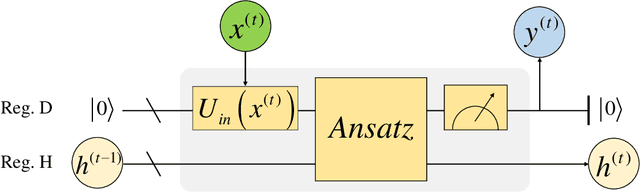
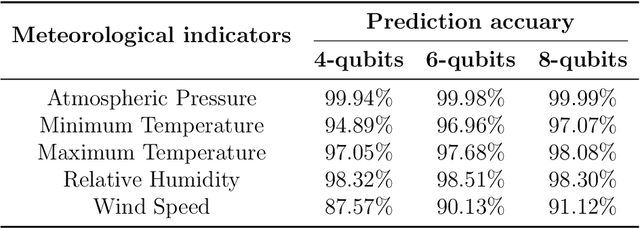
Quantum neural network (QNN) is one of the promising directions where the near-term noisy intermediate-scale quantum (NISQ) devices could find advantageous applications against classical resources. Recurrent neural networks are the most fundamental networks for sequential learning, but up to now there is still a lack of canonical model of quantum recurrent neural network (QRNN), which certainly restricts the research in the field of quantum deep learning. In the present work, we propose a new kind of QRNN which would be a good candidate as the canonical QRNN model, where, the quantum recurrent blocks (QRBs) are constructed in the hardware-efficient way, and the QRNN is built by stacking the QRBs in a staggered way that can greatly reduce the algorithm's requirement with regard to the coherent time of quantum devices. That is, our QRNN is much more accessible on NISQ devices. Furthermore, the performance of the present QRNN model is verified concretely using three different kinds of classical sequential data, i.e., meteorological indicators, stock price, and text categorization. The numerical experiments show that our QRNN achieves much better performance in prediction (classification) accuracy against the classical RNN and state-of-the-art QNN models for sequential learning, and can predict the changing details of temporal sequence data. The practical circuit structure and superior performance indicate that the present QRNN is a promising learning model to find quantum advantageous applications in the near term.
Scaling Self-Supervised End-to-End Driving with Multi-View Attention Learning
Feb 07, 2023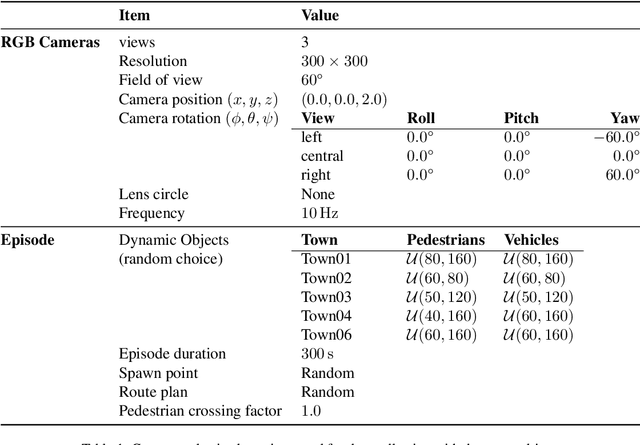
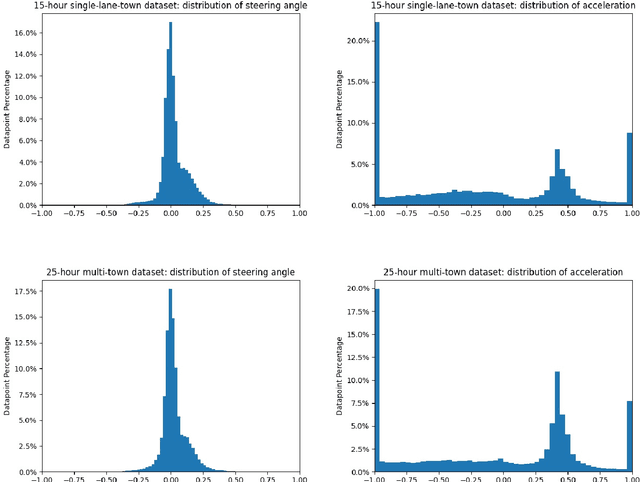

On end-to-end driving, a large amount of expert driving demonstrations is used to train an agent that mimics the expert by predicting its control actions. This process is self-supervised on vehicle signals (e.g., steering angle, acceleration) and does not require extra costly supervision (human labeling). Yet, the improvement of existing self-supervised end-to-end driving models has mostly given room to modular end-to-end models where labeling data intensive format such as semantic segmentation are required during training time. However, we argue that the latest self-supervised end-to-end models were developed in sub-optimal conditions with low-resolution images and no attention mechanisms. Further, those models are confined with limited field of view and far from the human visual cognition which can quickly attend far-apart scene features, a trait that provides an useful inductive bias. In this context, we present a new end-to-end model, trained by self-supervised imitation learning, leveraging a large field of view and a self-attention mechanism. These settings are more contributing to the agent's understanding of the driving scene, which brings a better imitation of human drivers. With only self-supervised training data, our model yields almost expert performance in CARLA's Nocrash metrics and could be rival to the SOTA models requiring large amounts of human labeled data. To facilitate further research, our code will be released.
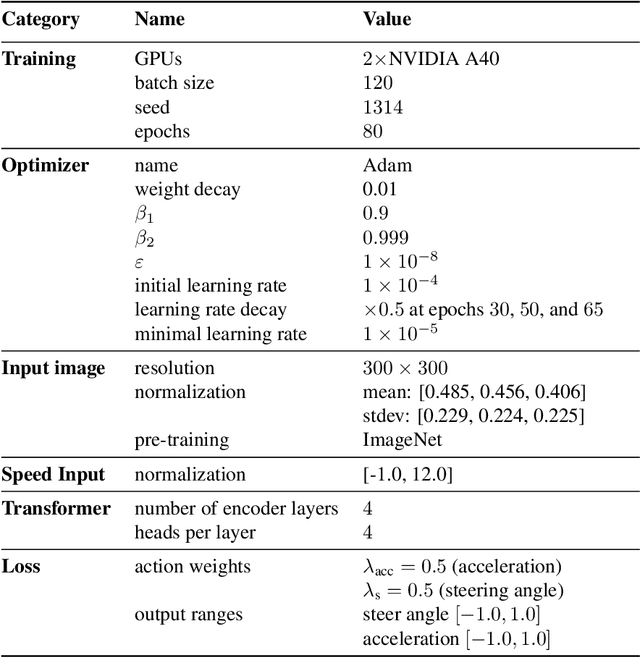
Patch Gradient Descent: Training Neural Networks on Very Large Images
Jan 31, 2023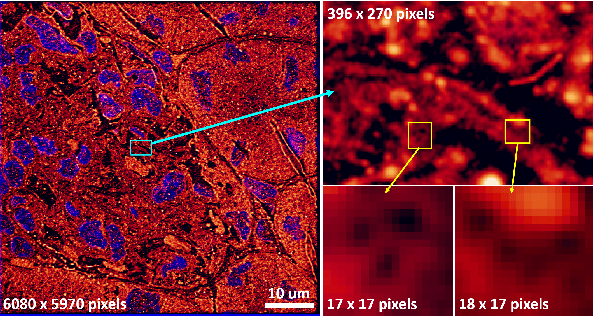
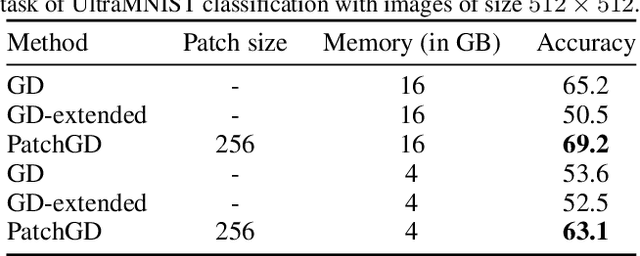
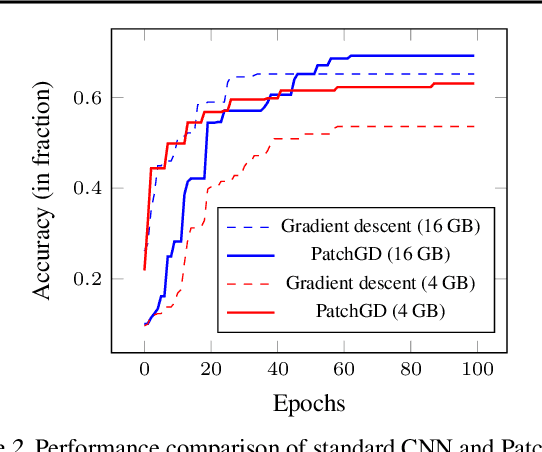
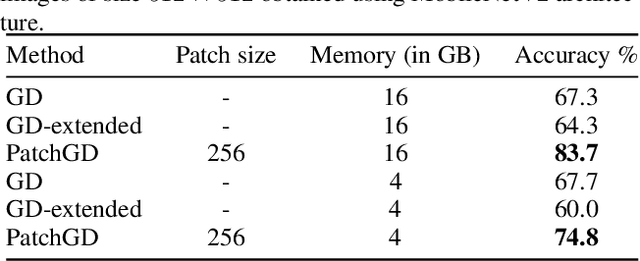
Traditional CNN models are trained and tested on relatively low resolution images (<300 px), and cannot be directly operated on large-scale images due to compute and memory constraints. We propose Patch Gradient Descent (PatchGD), an effective learning strategy that allows to train the existing CNN architectures on large-scale images in an end-to-end manner. PatchGD is based on the hypothesis that instead of performing gradient-based updates on an entire image at once, it should be possible to achieve a good solution by performing model updates on only small parts of the image at a time, ensuring that the majority of it is covered over the course of iterations. PatchGD thus extensively enjoys better memory and compute efficiency when training models on large scale images. PatchGD is thoroughly evaluated on two datasets - PANDA and UltraMNIST with ResNet50 and MobileNetV2 models under different memory constraints. Our evaluation clearly shows that PatchGD is much more stable and efficient than the standard gradient-descent method in handling large images, and especially when the compute memory is limited.
PromptMix: Text-to-image diffusion models enhance the performance of lightweight networks
Jan 31, 2023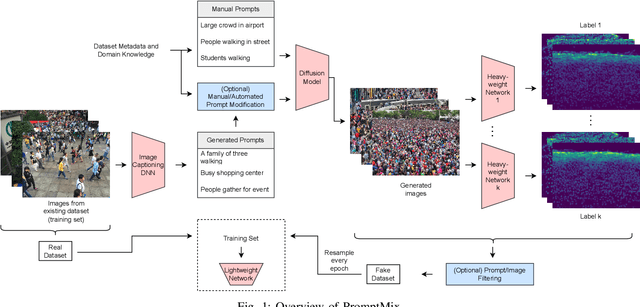

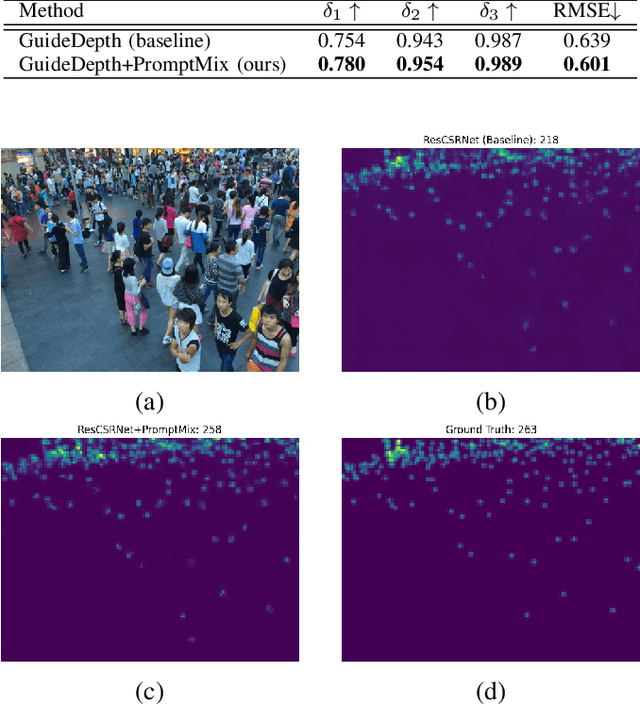

Many deep learning tasks require annotations that are too time consuming for human operators, resulting in small dataset sizes. This is especially true for dense regression problems such as crowd counting which requires the location of every person in the image to be annotated. Techniques such as data augmentation and synthetic data generation based on simulations can help in such cases. In this paper, we introduce PromptMix, a method for artificially boosting the size of existing datasets, that can be used to improve the performance of lightweight networks. First, synthetic images are generated in an end-to-end data-driven manner, where text prompts are extracted from existing datasets via an image captioning deep network, and subsequently introduced to text-to-image diffusion models. The generated images are then annotated using one or more high-performing deep networks, and mixed with the real dataset for training the lightweight network. By extensive experiments on five datasets and two tasks, we show that PromptMix can significantly increase the performance of lightweight networks by up to 26%.