 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A prior Estimates for Deep Residual Network in Continuous-time Reinforcement Learning
Feb 24, 2024
Deep reinforcement learning excels in numerous large-scale practical applications. However, existing performance analyses ignores the unique characteristics of continuous-time control problems, is unable to directly estimate the generalization error of the Bellman optimal loss and require a boundedness assumption. Our work focuses on continuous-time control problems and proposes a method that is applicable to all such problems where the transition function satisfies semi-group and Lipschitz properties. Under this method, we can directly analyze the \emph{a priori} generalization error of the Bellman optimal loss. The core of this method lies in two transformations of the loss function. To complete the transformation, we propose a decomposition method for the maximum operator. Additionally, this analysis method does not require a boundedness assumption. Finally, we obtain an \emph{a priori} generalization error without the curse of dimensionality.
DeepCDCL: An CDCL-based Neural Network Verification Framework
Mar 12, 2024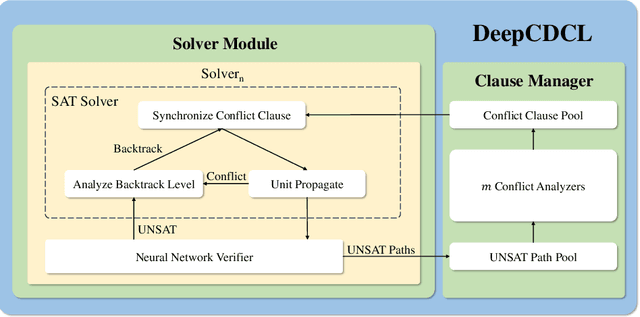
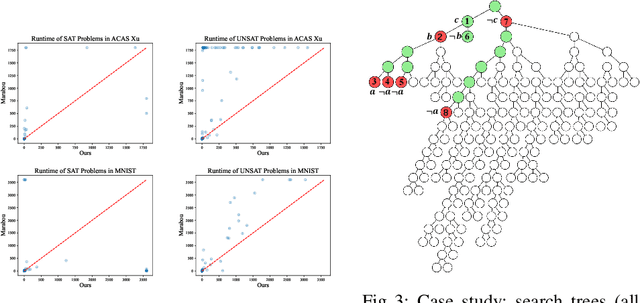
Neural networks in safety-critical applications face increasing safety and security concerns due to their susceptibility to little disturbance. In this paper, we propose DeepCDCL, a novel neural network verification framework based on the Conflict-Driven Clause Learning (CDCL) algorithm. We introduce an asynchronous clause learning and management structure, reducing redundant time consumption compared to the direct application of the CDCL framework. Furthermore, we also provide a detailed evaluation of the performance of our approach on the ACAS Xu and MNIST datasets, showing that a significant speed-up is achieved in most cases.
Limits of Approximating the Median Treatment Effect
Mar 15, 2024Average Treatment Effect (ATE) estimation is a well-studied problem in causal inference. However, it does not necessarily capture the heterogeneity in the data, and several approaches have been proposed to tackle the issue, including estimating the Quantile Treatment Effects. In the finite population setting containing $n$ individuals, with treatment and control values denoted by the potential outcome vectors $\mathbf{a}, \mathbf{b}$, much of the prior work focused on estimating median$(\mathbf{a}) -$ median$(\mathbf{b})$, where median($\mathbf x$) denotes the median value in the sorted ordering of all the values in vector $\mathbf x$. It is known that estimating the difference of medians is easier than the desired estimand of median$(\mathbf{a-b})$, called the Median Treatment Effect (MTE). The fundamental problem of causal inference -- for every individual $i$, we can only observe one of the potential outcome values, i.e., either the value $a_i$ or $b_i$, but not both, makes estimating MTE particularly challenging. In this work, we argue that MTE is not estimable and detail a novel notion of approximation that relies on the sorted order of the values in $\mathbf{a-b}$. Next, we identify a quantity called variability that exactly captures the complexity of MTE estimation. By drawing connections to instance-optimality studied in theoretical computer science, we show that every algorithm for estimating the MTE obtains an approximation error that is no better than the error of an algorithm that computes variability. Finally, we provide a simple linear time algorithm for computing the variability exactly. Unlike much prior work, a particular highlight of our work is that we make no assumptions about how the potential outcome vectors are generated or how they are correlated, except that the potential outcome values are $k$-ary, i.e., take one of $k$ discrete values.
A comprehensive study on Frequent Pattern Mining and Clustering categories for topic detection in Persian text stream
Mar 15, 2024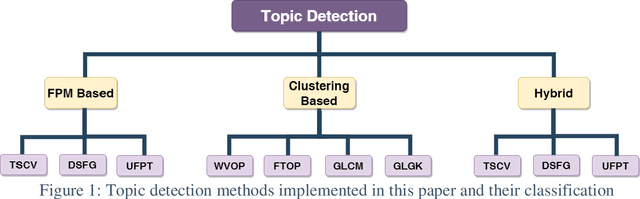

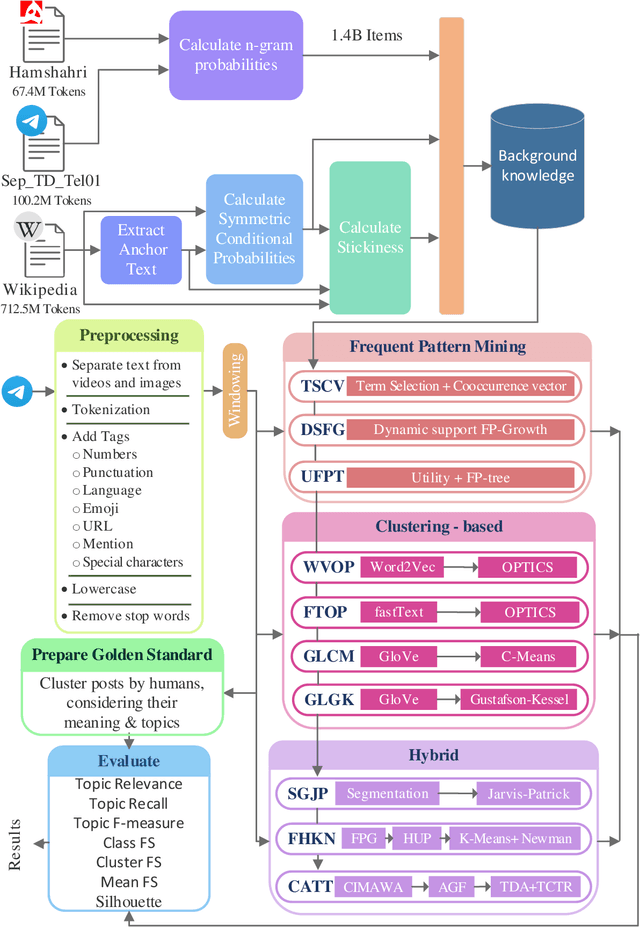
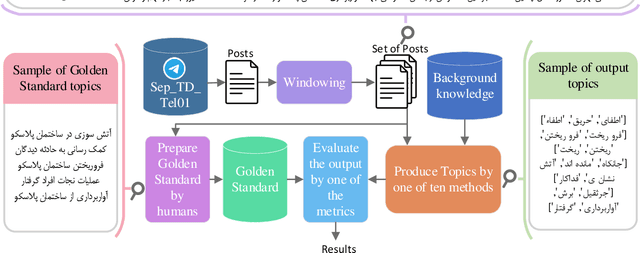
Topic detection is a complex process and depends on language because it somehow needs to analyze text. There have been few studies on topic detection in Persian, and the existing algorithms are not remarkable. Therefore, we aimed to study topic detection in Persian. The objectives of this study are: 1) to conduct an extensive study on the best algorithms for topic detection, 2) to identify necessary adaptations to make these algorithms suitable for the Persian language, and 3) to evaluate their performance on Persian social network texts. To achieve these objectives, we have formulated two research questions: First, considering the lack of research in Persian, what modifications should be made to existing frameworks, especially those developed in English, to make them compatible with Persian? Second, how do these algorithms perform, and which one is superior? There are various topic detection methods that can be categorized into different categories. Frequent pattern and clustering are selected for this research, and a hybrid of both is proposed as a new category. Then, ten methods from these three categories are selected. All of them are re-implemented from scratch, changed, and adapted with Persian. These ten methods encompass different types of topic detection methods and have shown good performance in English. The text of Persian social network posts is used as the dataset. Additionally, a new multiclass evaluation criterion, called FS, is used in this paper for the first time in the field of topic detection. Approximately 1.4 billion tokens are processed during experiments. The results indicate that if we are searching for keyword-topics that are easily understandable by humans, the hybrid category is better. However, if the aim is to cluster posts for further analysis, the frequent pattern category is more suitable.
Arbitrary-Scale Image Generation and Upsampling using Latent Diffusion Model and Implicit Neural Decoder
Mar 15, 2024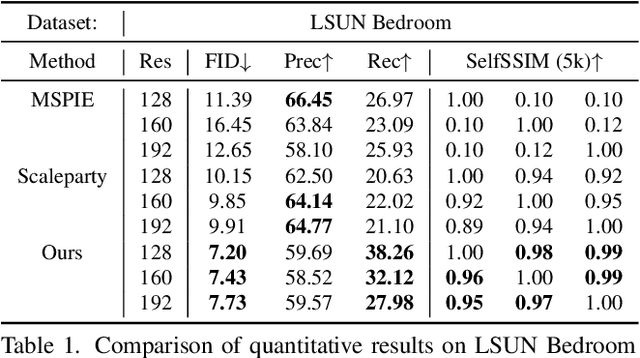
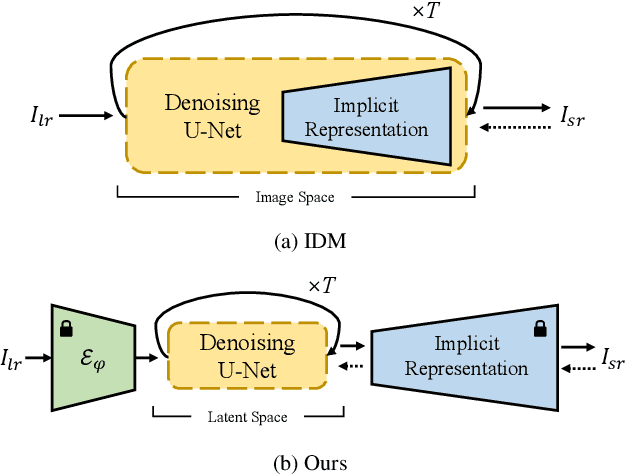

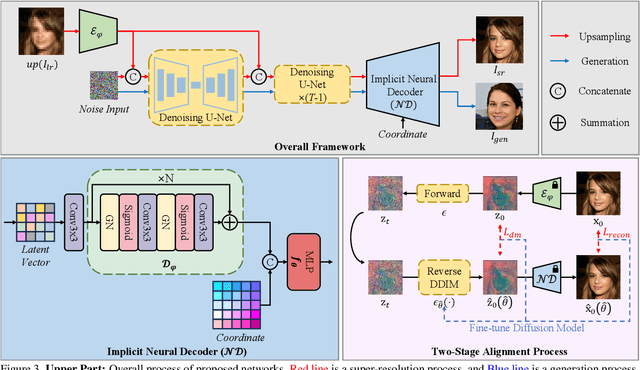
Super-resolution (SR) and image generation are important tasks in computer vision and are widely adopted in real-world applications. Most existing methods, however, generate images only at fixed-scale magnification and suffer from over-smoothing and artifacts. Additionally, they do not offer enough diversity of output images nor image consistency at different scales. Most relevant work applied Implicit Neural Representation (INR) to the denoising diffusion model to obtain continuous-resolution yet diverse and high-quality SR results. Since this model operates in the image space, the larger the resolution of image is produced, the more memory and inference time is required, and it also does not maintain scale-specific consistency. We propose a novel pipeline that can super-resolve an input image or generate from a random noise a novel image at arbitrary scales. The method consists of a pretrained auto-encoder, a latent diffusion model, and an implicit neural decoder, and their learning strategies. The proposed method adopts diffusion processes in a latent space, thus efficient, yet aligned with output image space decoded by MLPs at arbitrary scales. More specifically, our arbitrary-scale decoder is designed by the symmetric decoder w/o up-scaling from the pretrained auto-encoder, and Local Implicit Image Function (LIIF) in series. The latent diffusion process is learnt by the denoising and the alignment losses jointly. Errors in output images are backpropagated via the fixed decoder, improving the quality of output images. In the extensive experiments using multiple public benchmarks on the two tasks i.e. image super-resolution and novel image generation at arbitrary scales, the proposed method outperforms relevant methods in metrics of image quality, diversity and scale consistency. It is significantly better than the relevant prior-art in the inference speed and memory usage.
Physics-Informed Deep Learning for Motion-Corrected Reconstruction of Quantitative Brain MRI
Mar 13, 2024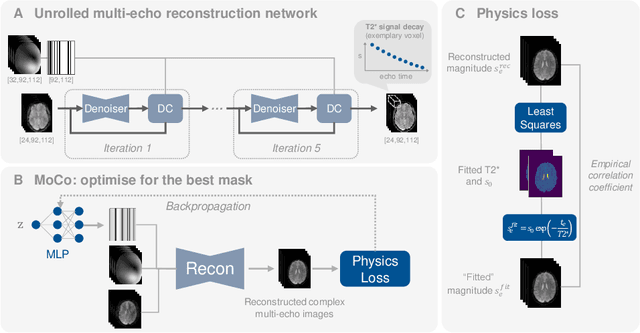

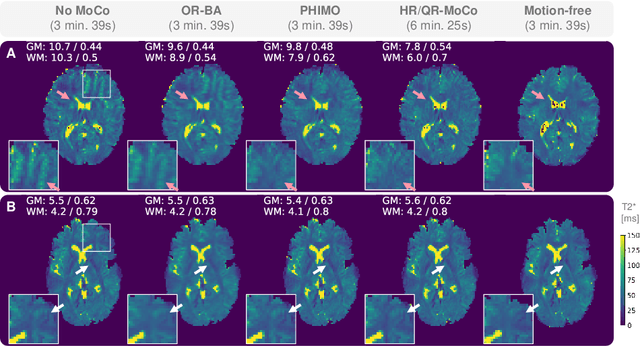
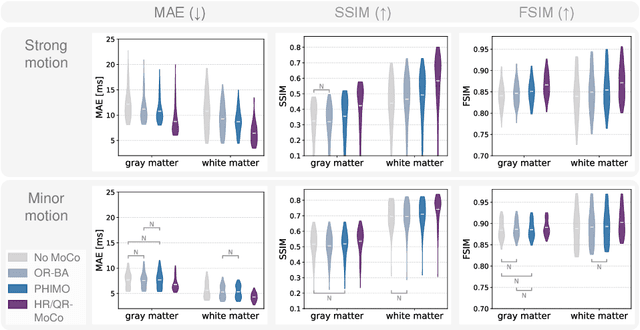
We propose PHIMO, a physics-informed learning-based motion correction method tailored to quantitative MRI. PHIMO leverages information from the signal evolution to exclude motion-corrupted k-space lines from a data-consistent reconstruction. We demonstrate the potential of PHIMO for the application of T2* quantification from gradient echo MRI, which is particularly sensitive to motion due to its sensitivity to magnetic field inhomogeneities. A state-of-the-art technique for motion correction requires redundant acquisition of the k-space center, prolonging the acquisition. We show that PHIMO can detect and exclude intra-scan motion events and, thus, correct for severe motion artifacts. PHIMO approaches the performance of the state-of-the-art motion correction method, while substantially reducing the acquisition time by over 40%, facilitating clinical applicability. Our code is available at https://github.com/HannahEichhorn/PHIMO.
Token Alignment via Character Matching for Subword Completion
Mar 13, 2024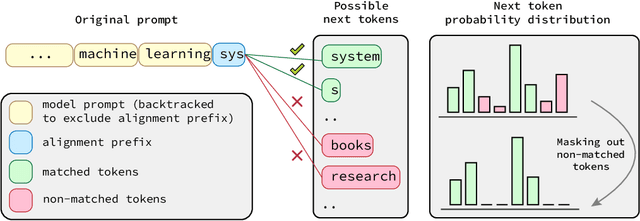
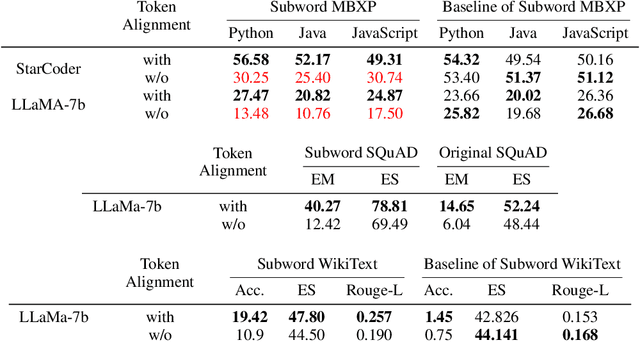

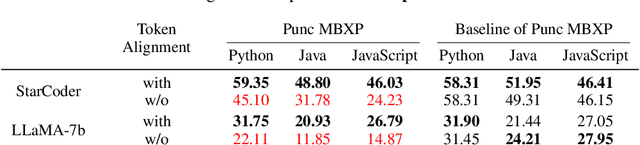
Generative models, widely utilized in various applications, can often struggle with prompts corresponding to partial tokens. This struggle stems from tokenization, where partial tokens fall out of distribution during inference, leading to incorrect or nonsensical outputs. This paper examines a technique to alleviate the tokenization artifact on text completion in generative models, maintaining performance even in regular non-subword cases. The method, termed token alignment, involves backtracking to the last complete tokens and ensuring the model's generation aligns with the prompt. This approach showcases marked improvement across many partial token scenarios, including nuanced cases like space-prefix and partial indentation, with only a minor time increase. The technique and analysis detailed in this paper contribute to the continuous advancement of generative models in handling partial inputs, bearing relevance for applications like code completion and text autocompletion.
Log Summarisation for Defect Evolution Analysis
Mar 13, 2024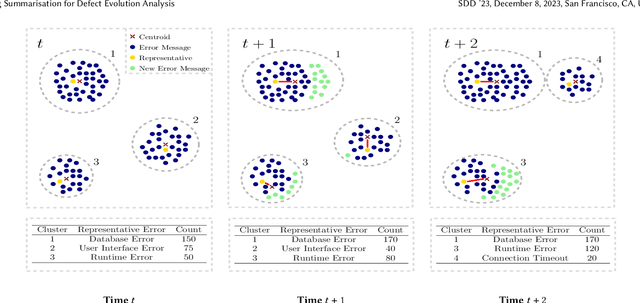
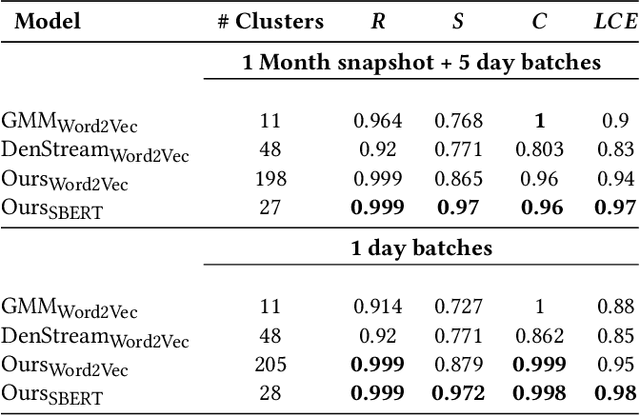
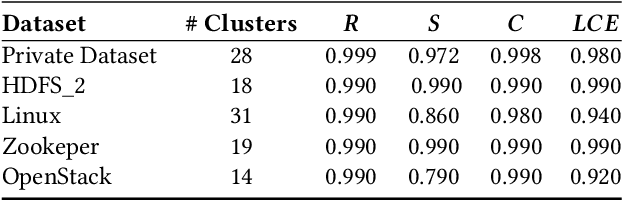
Log analysis and monitoring are essential aspects in software maintenance and identifying defects. In particular, the temporal nature and vast size of log data leads to an interesting and important research question: How can logs be summarised and monitored over time? While this has been a fundamental topic of research in the software engineering community, work has typically focused on heuristic-, syntax-, or static-based methods. In this work, we suggest an online semantic-based clustering approach to error logs that dynamically updates the log clusters to enable monitoring code error life-cycles. We also introduce a novel metric to evaluate the performance of temporal log clusters. We test our system and evaluation metric with an industrial dataset and find that our solution outperforms similar systems. We hope that our work encourages further temporal exploration in defect datasets.
A Mixed-Integer Conic Program for the Moving-Target Traveling Salesman Problem based on a Graph of Convex Sets
Mar 11, 2024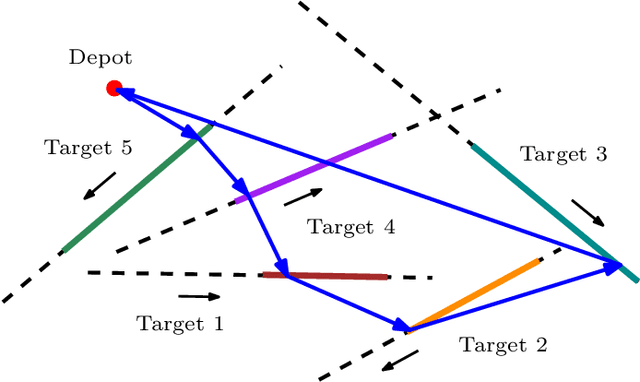
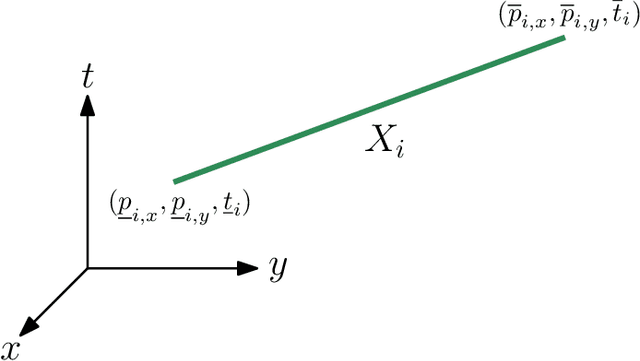
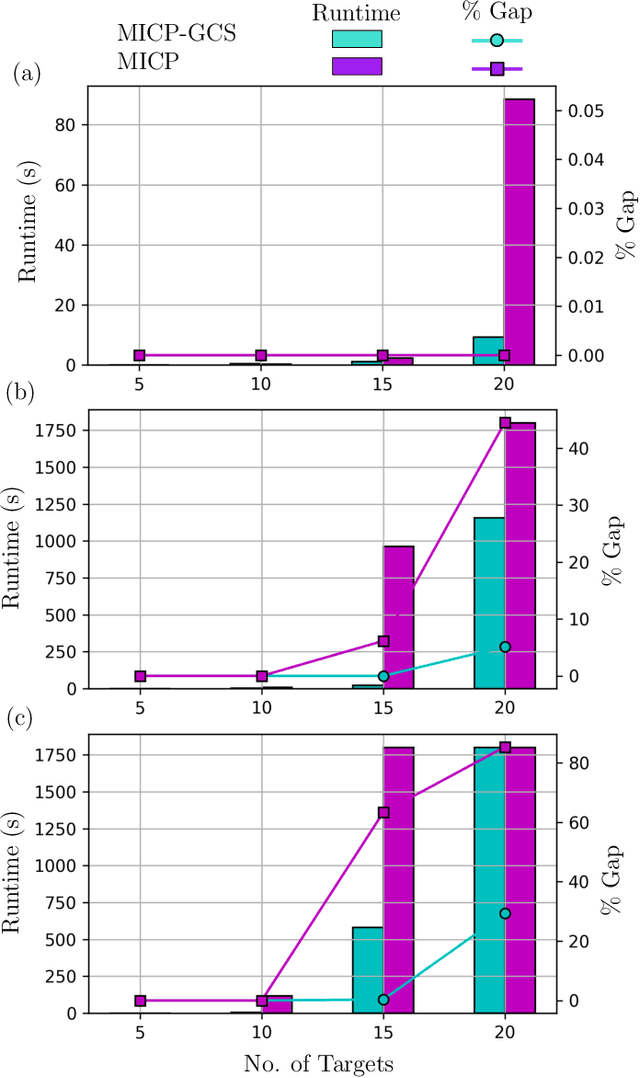
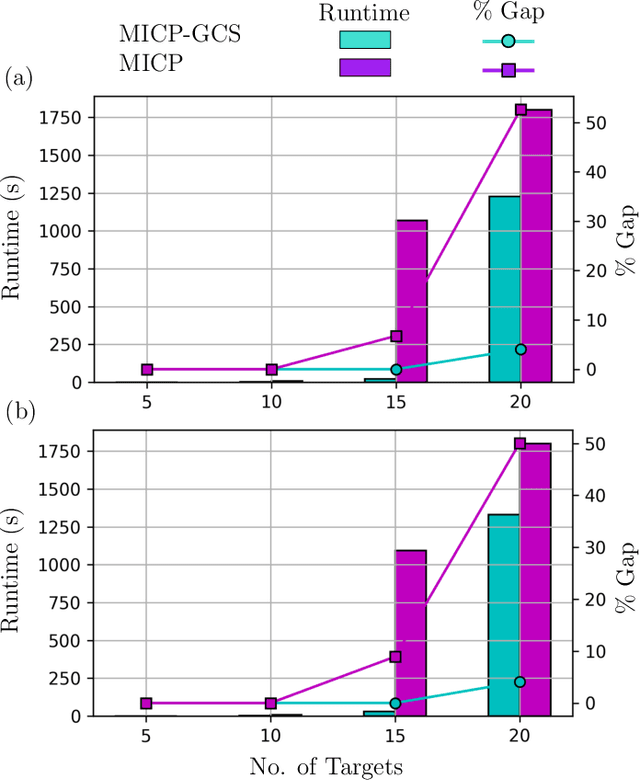
This paper introduces a new formulation that finds the optimum for the Moving-Target Traveling Salesman Problem (MT-TSP), which seeks to find a shortest path for an agent, that starts at a depot, visits a set of moving targets exactly once within their assigned time-windows, and returns to the depot. The formulation relies on the key idea that when the targets move along lines, their trajectories become convex sets within the space-time coordinate system. The problem then reduces to finding the shortest path within a graph of convex sets, subject to some speed constraints. We compare our formulation with the current state-of-the-art Mixed Integer Conic Program (MICP) solver for the MT-TSP. The experimental results show that our formulation outperforms the MICP for instances with up to 20 targets, with up to two orders of magnitude reduction in runtime, and up to a 60\% tighter optimality gap. We also show that the solution cost from the convex relaxation of our formulation provides significantly tighter lower bounds for the MT-TSP than the ones from the MICP.
Multi-Fidelity Bayesian Optimization With Across-Task Transferable Max-Value Entropy Search
Mar 14, 2024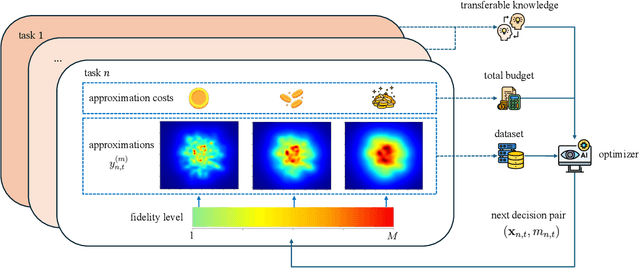
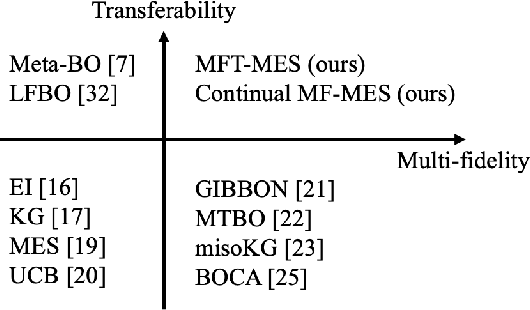
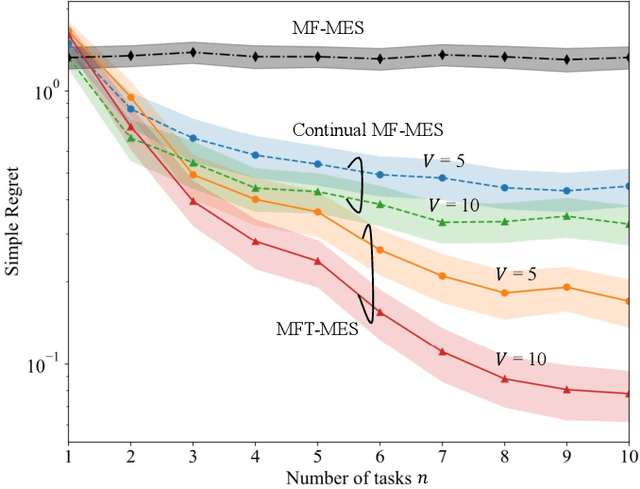
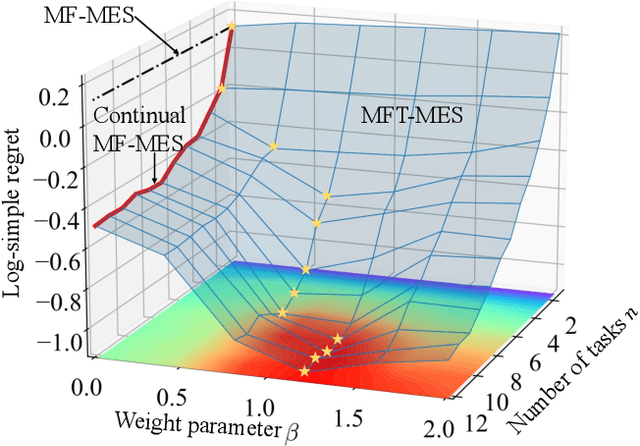
In many applications, ranging from logistics to engineering, a designer is faced with a sequence of optimization tasks for which the objectives are in the form of black-box functions that are costly to evaluate. For example, the designer may need to tune the hyperparameters of neural network models for different learning tasks over time. Rather than evaluating the objective function for each candidate solution, the designer may have access to approximations of the objective functions, for which higher-fidelity evaluations entail a larger cost. Existing multi-fidelity black-box optimization strategies select candidate solutions and fidelity levels with the goal of maximizing the information accrued about the optimal value or solution for the current task. Assuming that successive optimization tasks are related, this paper introduces a novel information-theoretic acquisition function that balances the need to acquire information about the current task with the goal of collecting information transferable to future tasks. The proposed method includes shared inter-task latent variables, which are transferred across tasks by implementing particle-based variational Bayesian updates. Experimental results across synthetic and real-world examples reveal that the proposed provident acquisition strategy that caters to future tasks can significantly improve the optimization efficiency as soon as a sufficient number of tasks is processed.