 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A system for Human-AI collaboration for Online Customer Support
Jan 28, 2023
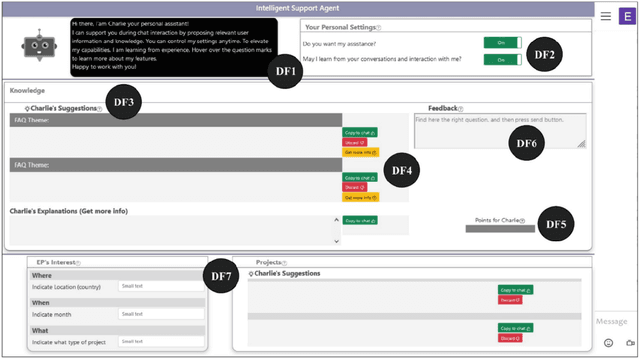
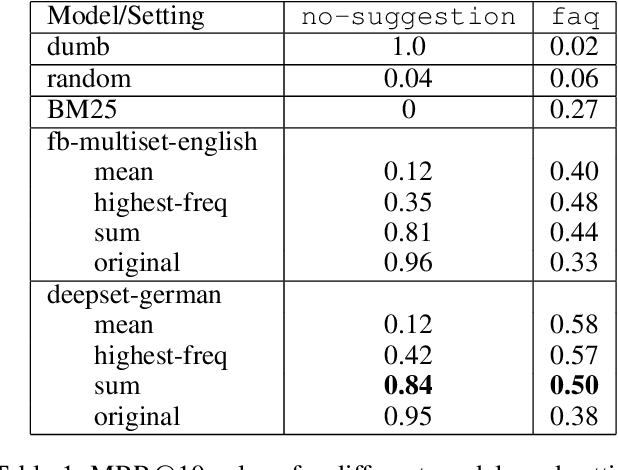
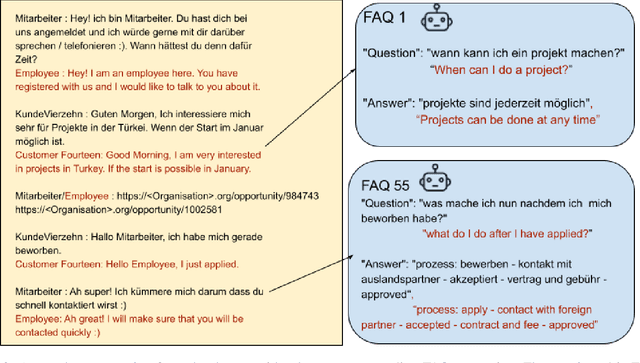
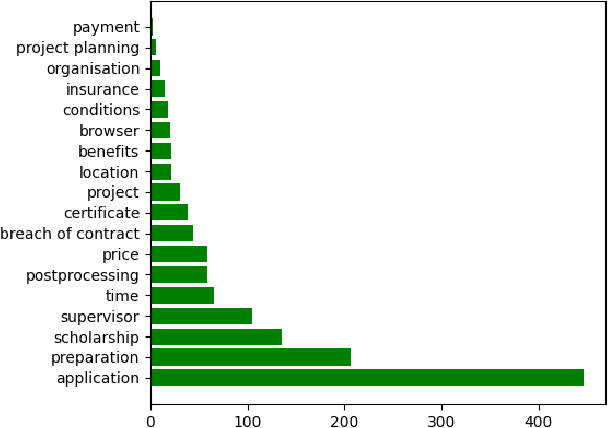
AI enabled chat bots have recently been put to use to answer customer service queries, however it is a common feedback of users that bots lack a personal touch and are often unable to understand the real intent of the user's question. To this end, it is desirable to have human involvement in the customer servicing process. In this work, we present a system where a human support agent collaborates in real-time with an AI agent to satisfactorily answer customer queries. We describe the user interaction elements of the solution, along with the machine learning techniques involved in the AI agent.
Achieving Covert Communication in Large-Scale SWIPT-Enabled D2D Networks
Feb 16, 2023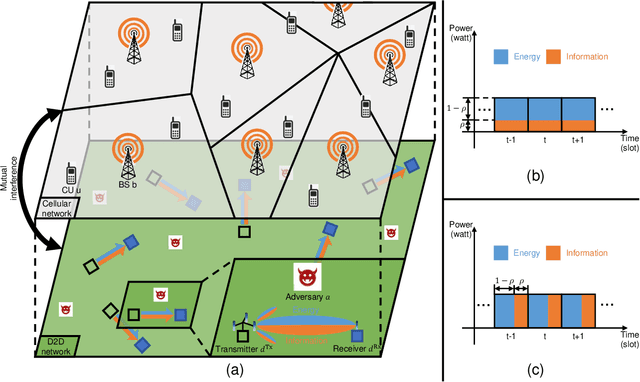
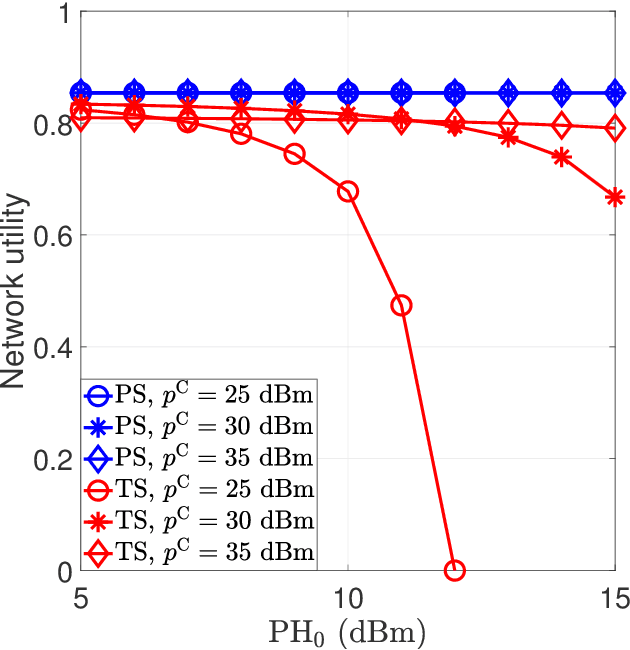
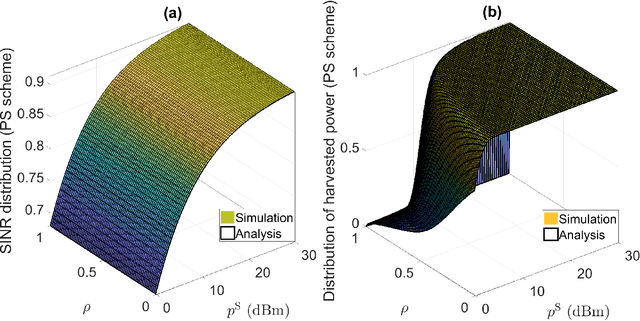
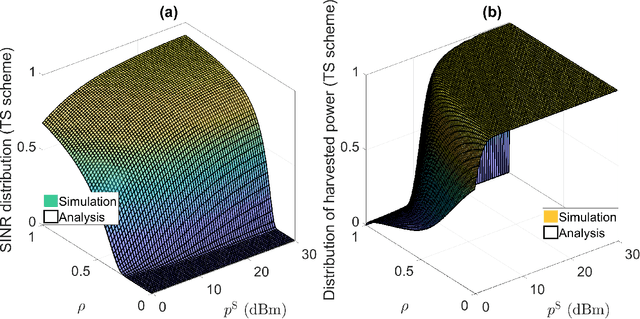
We aim to secure a large-scale device-to-device (D2D) network against adversaries. The D2D network underlays a downlink cellular network to reuse the cellular spectrum and is enabled for simultaneous wireless information and power transfer (SWIPT). In the D2D network, the transmitters communicate with the receivers, and the receivers extract information and energy from their received radio-frequency (RF) signals. In the meantime, the adversaries aim to detect the D2D transmission. The D2D network applies power control and leverages the cellular signal to achieve covert communication (i.e., hide the presence of transmissions) so as to defend against the adversaries. We model the interaction between the D2D network and adversaries by using a two-stage Stackelberg game. Therein, the adversaries are the followers minimizing their detection errors at the lower stage and the D2D network is the leader maximizing its network utility constrained by the communication covertness and power outage at the upper stage. Both power splitting (PS)-based and time switch (TS)-based SWIPT schemes are explored. We characterize the spatial configuration of the large-scale D2D network, adversaries, and cellular network by stochastic geometry. We analyze the adversary's detection error minimization problem and adopt the Rosenbrock method to solve it, where the obtained solution is the best response from the lower stage. Taking into account the best response from the lower stage, we develop a bi-level algorithm to solve the D2D network's constrained network utility maximization problem and obtain the Stackelberg equilibrium. We present numerical results to reveal interesting insights.
Wireless Picosecond Time Synchronization for Distributed Antenna Arrays
Jun 16, 2022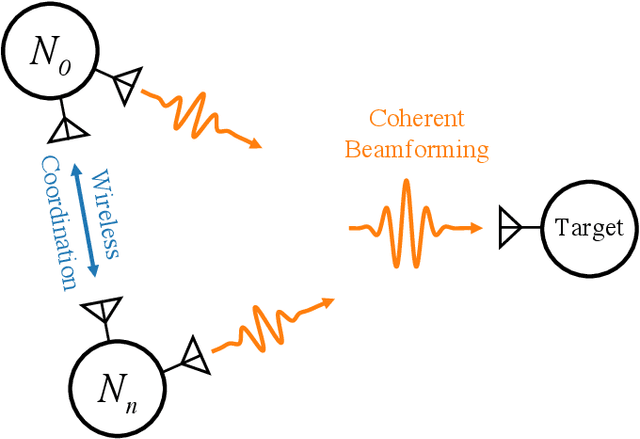
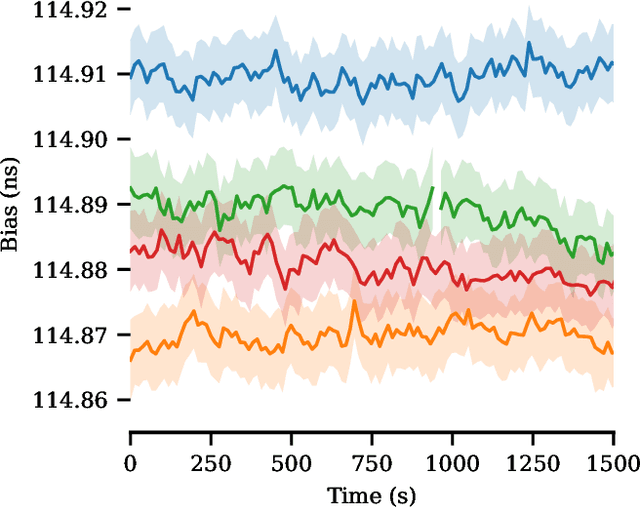
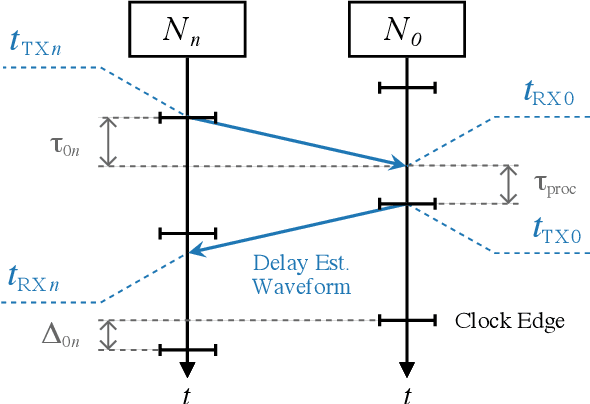
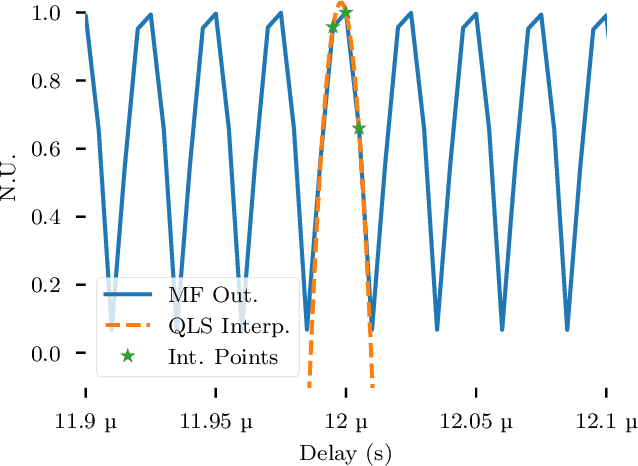
Distributed antenna arrays have been proposed for many applications ranging from space-based observatories to automated vehicles. Achieving good performance in distributed antenna systems requires stringent synchronization at the wavelength and information level to ensure that the transmitted signals arrive coherently at the target, or that scattered and received signals can be appropriately processed via distributed algorithms. In this paper we address the challenge of high precision time synchronization to align the operations of elements in a distributed antenna array and to overcome time-varying bias between platforms due to oscillator drift. We use a spectrally sparse two-tone waveform, which obtains approximately optimal time estimation accuracy, in a two-way time transfer process. We also describe a technique for determining the true time delay using the ambiguous two-tone matched filter output, and we compare the time synchronization precision of the two-tone waveform with the more common linear frequency modulation (LFM) waveform. We experimentally demonstrate wireless time synchronization using a single pulse 40$\,$MHz two-tone waveform over a 90$\,$cm 5.8$\,$GHz wireless link in a laboratory setting, obtaining a timing precision of 2.26$\,$ps.
Languages are Rewards: Chain of Hindsight Finetuning using Human Feedback
Feb 13, 2023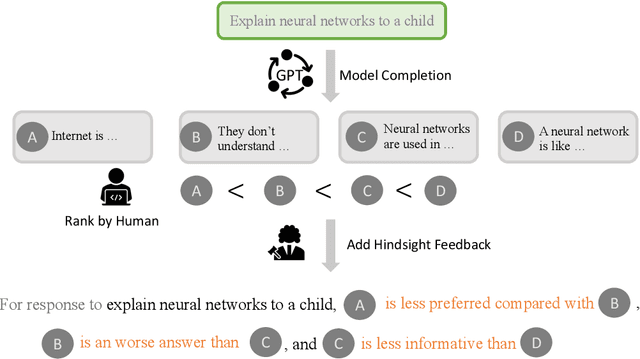
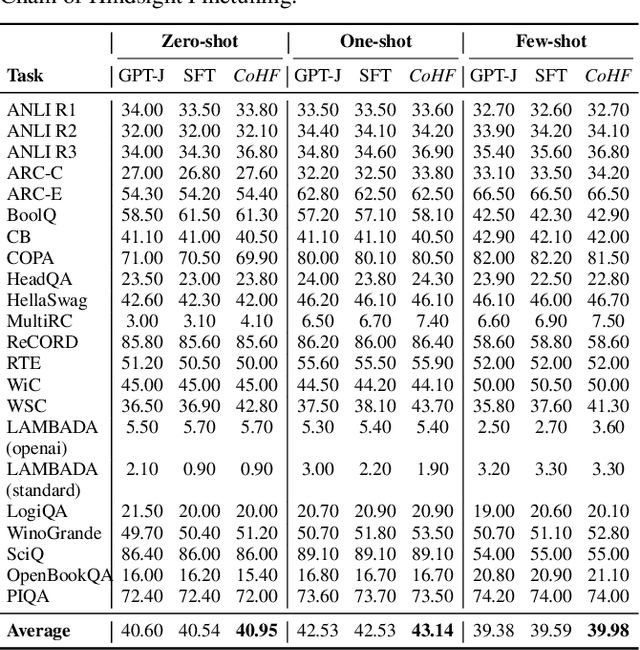
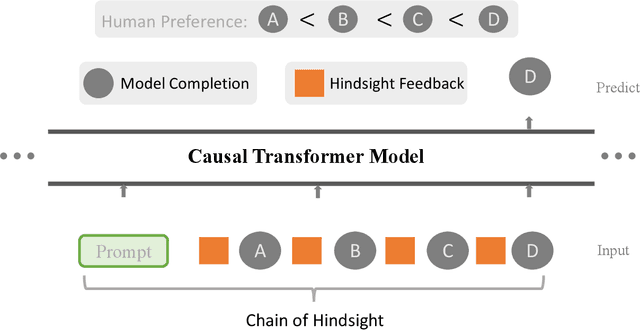
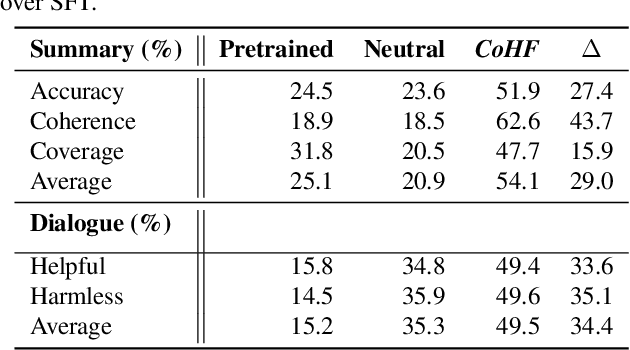
Learning from human preferences is important for language models to be helpful and useful for humans, and to align with human and social values. Existing works focus on supervised finetuning of pretrained models, based on curated model generations that are preferred by human labelers. Such works have achieved remarkable successes in understanding and following instructions (e.g., InstructGPT, ChatGPT, etc). However, to date, a key limitation of supervised finetuning is that it cannot learn from negative ratings; models are only trained on positive-rated data, which makes it data inefficient. Because collecting human feedback data is both time consuming and expensive, it is vital for the model to learn from all feedback, akin to the remarkable ability of humans to learn from diverse feedback. In this work, we propose a novel technique called Hindsight Finetuning for making language models learn from diverse human feedback. In fact, our idea is motivated by how humans learn from hindsight experience. We condition the model on a sequence of model generations paired with hindsight feedback, and finetune the model to predict the most preferred output. By doing so, models can learn to identify and correct negative attributes or errors. Applying the method to GPT-J, we observe that it significantly improves results on summarization and dialogue tasks using the same amount of human feedback.
Improving robot navigation in crowded environments using intrinsic rewards
Feb 13, 2023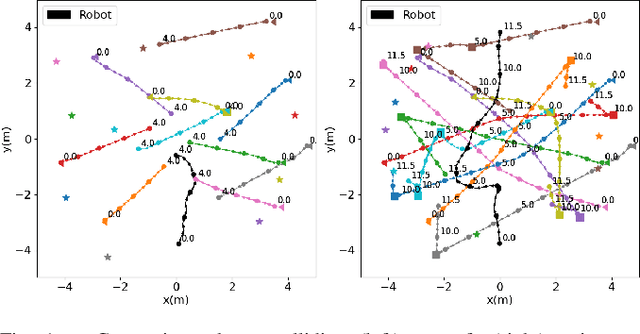
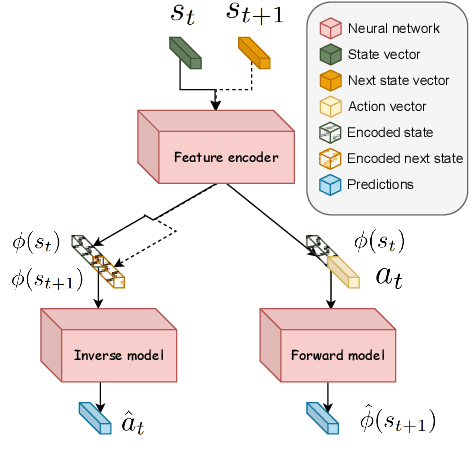
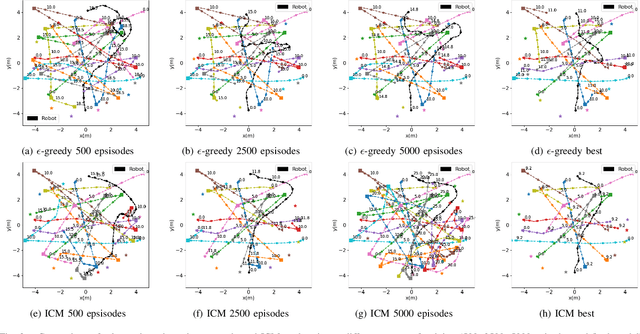
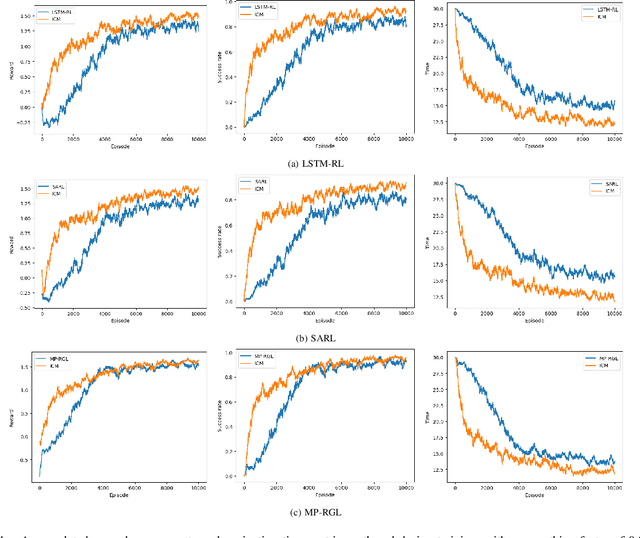
Autonomous navigation in crowded environments is an open problem with many applications, essential for the coexistence of robots and humans in the smart cities of the future. In recent years, deep reinforcement learning approaches have proven to outperform model-based algorithms. Nevertheless, even though the results provided are promising, the works are not able to take advantage of the capabilities that their models offer. They usually get trapped in local optima in the training process, that prevent them from learning the optimal policy. They are not able to visit and interact with every possible state appropriately, such as with the states near the goal or near the dynamic obstacles. In this work, we propose using intrinsic rewards to balance between exploration and exploitation and explore depending on the uncertainty of the states instead of on the time the agent has been trained, encouraging the agent to get more curious about unknown states. We explain the benefits of the approach and compare it with other exploration algorithms that may be used for crowd navigation. Many simulation experiments are performed modifying several algorithms of the state-of-the-art, showing that the use of intrinsic rewards makes the robot learn faster and reach higher rewards and success rates (fewer collisions) in shorter navigation times, outperforming the state-of-the-art.
Indoor Localization with Robust Global Channel Charting: A Time-Distance-Based Approach
Oct 07, 2022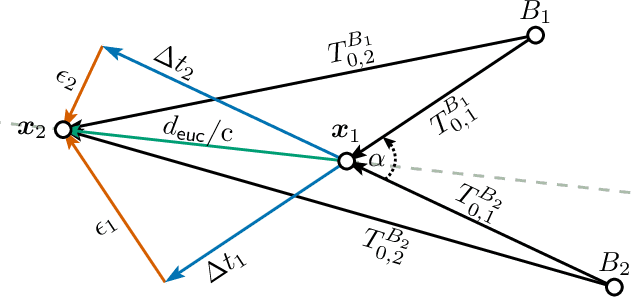
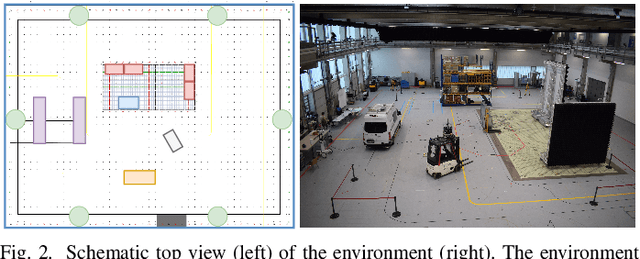
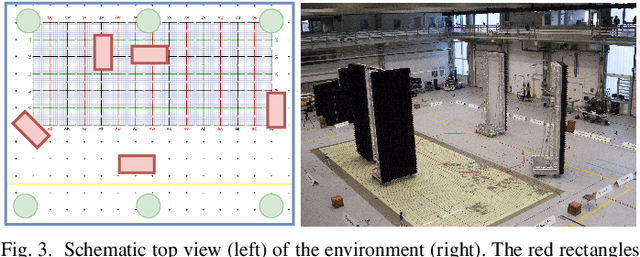
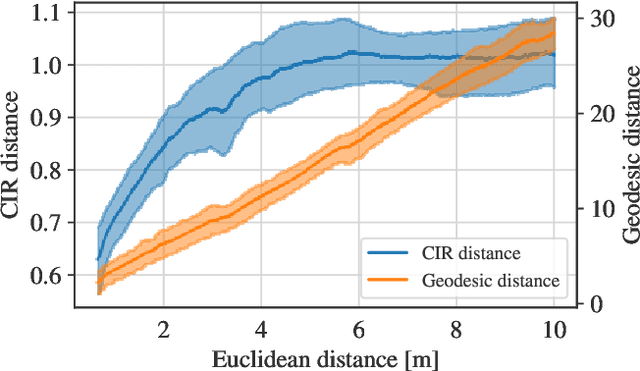
Fingerprinting-based positioning significantly improves the indoor localization performance in non-line-of-sight-dominated areas. However, its deployment and maintenance is cost-intensive as it needs ground-truth reference systems for both the initial training and the adaption to environmental changes. In contrast, channel charting (CC) works without explicit reference information and only requires the spatial correlations of channel state information (CSI). While CC has shown promising results in modelling the geometry of the radio environment, a deeper insight into CC for localization using multi-anchor large-bandwidth measurements is still pending. We contribute a novel distance metric for time-synchronized single-input/single-output CSIs that approaches a linear correlation to the Euclidean distance. This allows to learn the environment's global geometry without annotations. To efficiently optimize the global channel chart we approximate the metric with a Siamese neural network. This enables full CC-assisted fingerprinting and positioning only using a linear transformation from the chart to the real-world coordinates. We compare our approach to the state-of-the-art of CC on two different real-world data sets recorded with a 5G and UWB radio setup. Our approach outperforms others with localization accuracies of 0.69m for the UWB and 1.4m for the 5G setup. We show that CC-assisted fingerprinting enables highly accurate localization and reduces (or eliminates) the need for annotated training data.
Test-Time Adaptation via Conjugate Pseudo-labels
Jul 20, 2022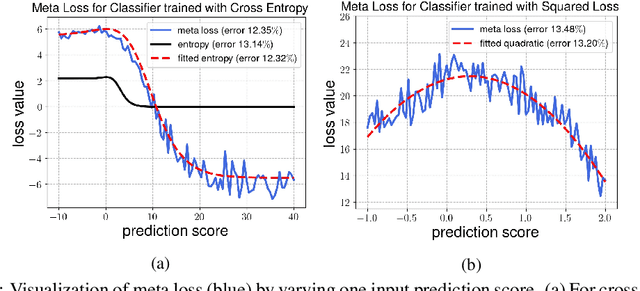
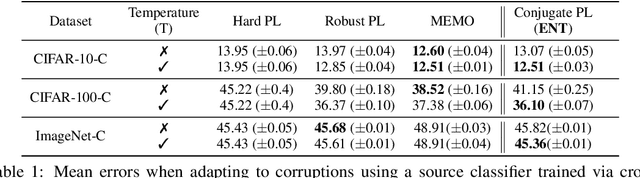
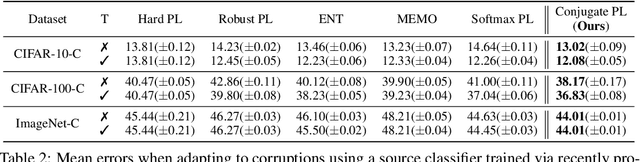
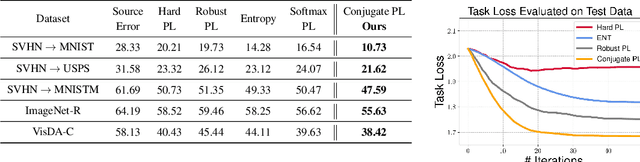
Test-time adaptation (TTA) refers to adapting neural networks to distribution shifts, with access to only the unlabeled test samples from the new domain at test-time. Prior TTA methods optimize over unsupervised objectives such as the entropy of model predictions in TENT [Wang et al., 2021], but it is unclear what exactly makes a good TTA loss. In this paper, we start by presenting a surprising phenomenon: if we attempt to meta-learn the best possible TTA loss over a wide class of functions, then we recover a function that is remarkably similar to (a temperature-scaled version of) the softmax-entropy employed by TENT. This only holds, however, if the classifier we are adapting is trained via cross-entropy; if trained via squared loss, a different best TTA loss emerges. To explain this phenomenon, we analyze TTA through the lens of the training losses's convex conjugate. We show that under natural conditions, this (unsupervised) conjugate function can be viewed as a good local approximation to the original supervised loss and indeed, it recovers the best losses found by meta-learning. This leads to a generic recipe that can be used to find a good TTA loss for any given supervised training loss function of a general class. Empirically, our approach consistently dominates other baselines over a wide range of benchmarks. Our approach is particularly of interest when applied to classifiers trained with novel loss functions, e.g., the recently-proposed PolyLoss, where it differs substantially from (and outperforms) an entropy-based loss. Further, we show that our approach can also be interpreted as a kind of self-training using a very specific soft label, which we refer to as the conjugate pseudolabel. Overall, our method provides a broad framework for better understanding and improving test-time adaptation. Code is available at https://github.com/locuslab/tta_conjugate.
Stop Wasting My Time! Saving Days of ImageNet and BERT Training with Latest Weight Averaging
Sep 29, 2022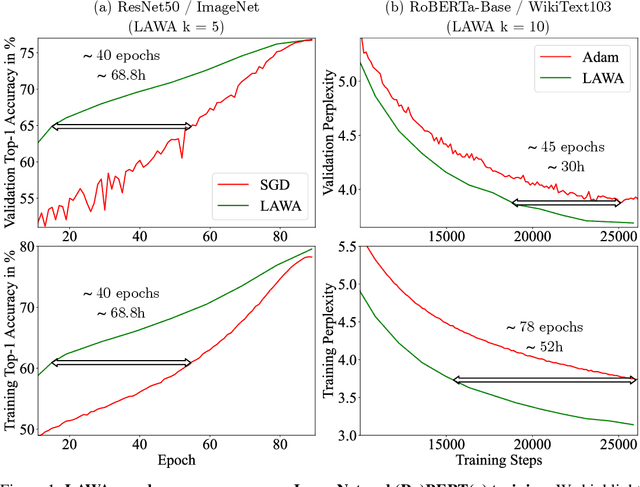
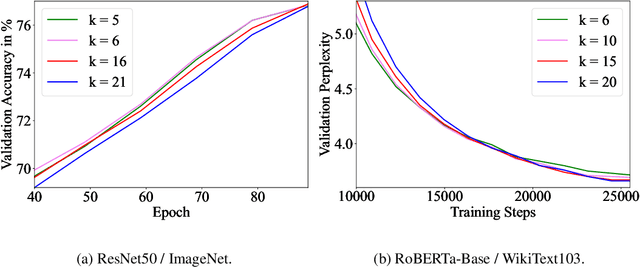
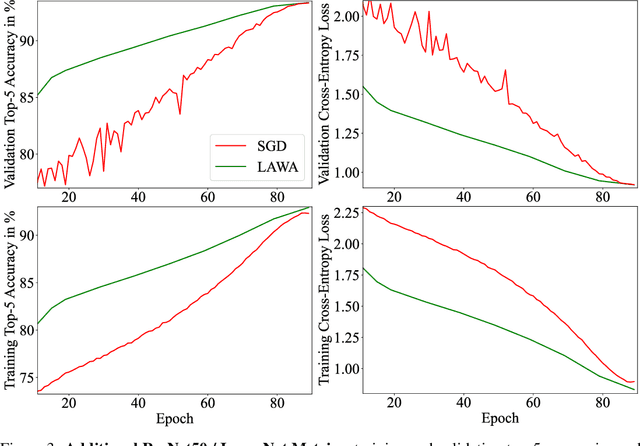
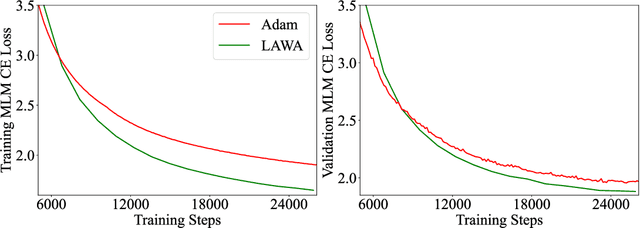
Training vision or language models on large datasets can take days, if not weeks. We show that averaging the weights of the k latest checkpoints, each collected at the end of an epoch, can speed up the training progression in terms of loss and accuracy by dozens of epochs, corresponding to time savings up to ~68 and ~30 GPU hours when training a ResNet50 on ImageNet and RoBERTa-Base model on WikiText-103, respectively. We also provide the code and model checkpoint trajectory to reproduce the results and facilitate research on reusing historical weights for faster convergence.
A Multi-Resolution Framework for U-Nets with Applications to Hierarchical VAEs
Jan 19, 2023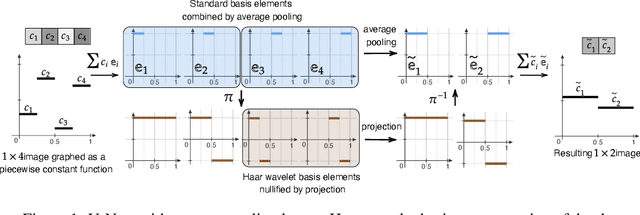
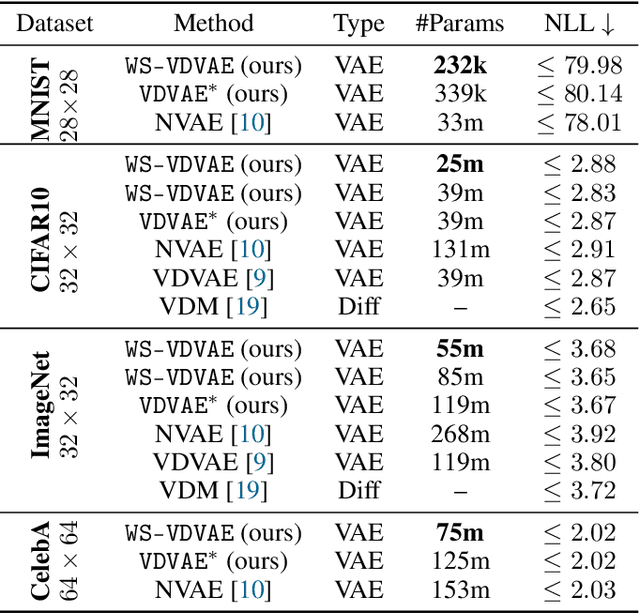
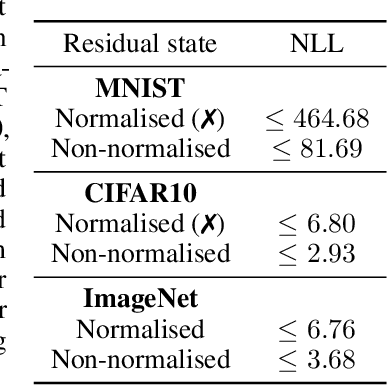
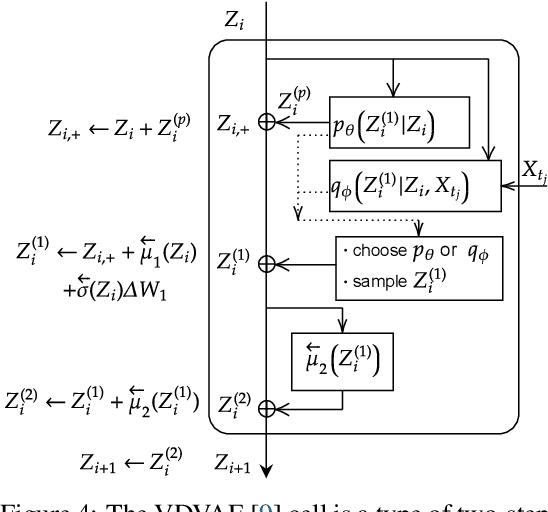
U-Net architectures are ubiquitous in state-of-the-art deep learning, however their regularisation properties and relationship to wavelets are understudied. In this paper, we formulate a multi-resolution framework which identifies U-Nets as finite-dimensional truncations of models on an infinite-dimensional function space. We provide theoretical results which prove that average pooling corresponds to projection within the space of square-integrable functions and show that U-Nets with average pooling implicitly learn a Haar wavelet basis representation of the data. We then leverage our framework to identify state-of-the-art hierarchical VAEs (HVAEs), which have a U-Net architecture, as a type of two-step forward Euler discretisation of multi-resolution diffusion processes which flow from a point mass, introducing sampling instabilities. We also demonstrate that HVAEs learn a representation of time which allows for improved parameter efficiency through weight-sharing. We use this observation to achieve state-of-the-art HVAE performance with half the number of parameters of existing models, exploiting the properties of our continuous-time formulation.
EgPDE-Net: Building Continuous Neural Networks for Time Series Prediction with Exogenous Variables
Aug 03, 2022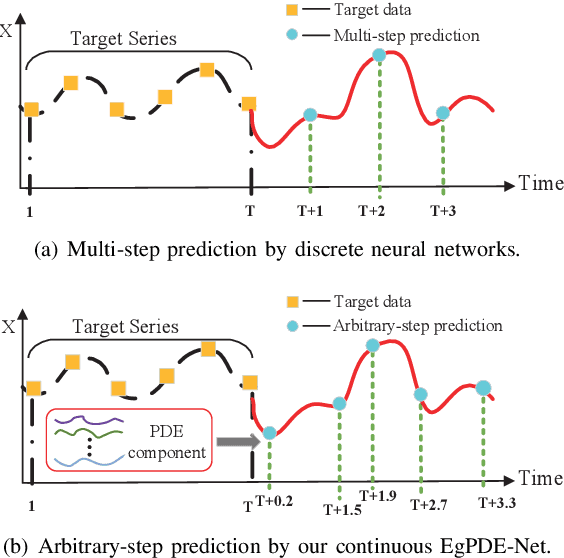
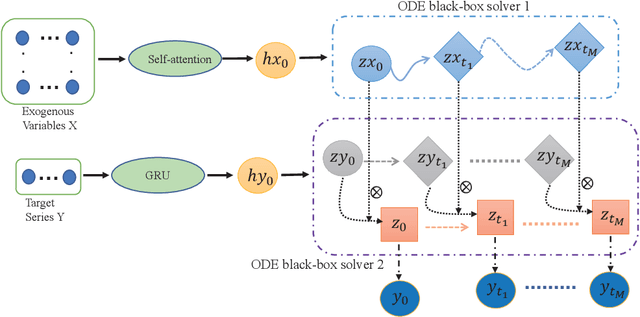
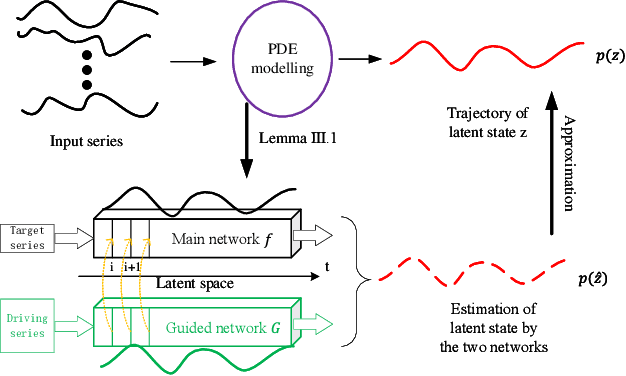
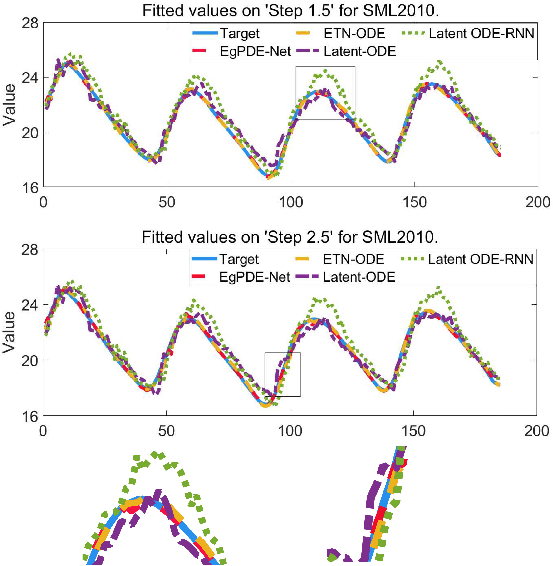
While exogenous variables have a major impact on performance improvement in time series analysis, inter-series correlation and time dependence among them are rarely considered in the present continuous methods. The dynamical systems of multivariate time series could be modelled with complex unknown partial differential equations (PDEs) which play a prominent role in many disciplines of science and engineering. In this paper, we propose a continuous-time model for arbitrary-step prediction to learn an unknown PDE system in multivariate time series whose governing equations are parameterised by self-attention and gated recurrent neural networks. The proposed model, \underline{E}xogenous-\underline{g}uided \underline{P}artial \underline{D}ifferential \underline{E}quation Network (EgPDE-Net), takes account of the relationships among the exogenous variables and their effects on the target series. Importantly, the model can be reduced into a regularised ordinary differential equation (ODE) problem with special designed regularisation guidance, which makes the PDE problem tractable to obtain numerical solutions and feasible to predict multiple future values of the target series at arbitrary time points. Extensive experiments demonstrate that our proposed model could achieve competitive accuracy over strong baselines: on average, it outperforms the best baseline by reducing $9.85\%$ on RMSE and $13.98\%$ on MAE for arbitrary-step prediction.