 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated vision-based assistance tools in bronchoscopy: stenosis severity estimation
May 08, 2025Purpose: Subglottic stenosis refers to the narrowing of the subglottis, the airway between the vocal cords and the trachea. Its severity is typically evaluated by estimating the percentage of obstructed airway. This estimation can be obtained from CT data or through visual inspection by experts exploring the region. However, visual inspections are inherently subjective, leading to less consistent and robust diagnoses. No public methods or datasets are currently available for automated evaluation of this condition from bronchoscopy video. Methods: We propose a pipeline for automated subglottic stenosis severity estimation during the bronchoscopy exploration, without requiring the physician to traverse the stenosed region. Our approach exploits the physical effect of illumination decline in endoscopy to segment and track the lumen and obtain a 3D model of the airway. This 3D model is obtained from a single frame and is used to measure the airway narrowing. Results: Our pipeline is the first to enable automated and robust subglottic stenosis severity measurement using bronchoscopy images. The results show consistency with ground-truth estimations from CT scans and expert estimations, and reliable repeatability across multiple estimations on the same patient. Our evaluation is performed on our new Subglottic Stenosis Dataset of real bronchoscopy procedures data. Conclusion: We demonstrate how to automate evaluation of subglottic stenosis severity using only bronchoscopy. Our approach can assist with and shorten diagnosis and monitoring procedures, with automated and repeatable estimations and less exploration time, and save radiation exposure to patients as no CT is required. Additionally, we release the first public benchmark for subglottic stenosis severity assessment.
Sim2Real in endoscopy segmentation with a novel structure aware image translation
May 05, 2025Automatic segmentation of anatomical landmarks in endoscopic images can provide assistance to doctors and surgeons for diagnosis, treatments or medical training. However, obtaining the annotations required to train commonly used supervised learning methods is a tedious and difficult task, in particular for real images. While ground truth annotations are easier to obtain for synthetic data, models trained on such data often do not generalize well to real data. Generative approaches can add realistic texture to it, but face difficulties to maintain the structure of the original scene. The main contribution in this work is a novel image translation model that adds realistic texture to simulated endoscopic images while keeping the key scene layout information. Our approach produces realistic images in different endoscopy scenarios. We demonstrate these images can effectively be used to successfully train a model for a challenging end task without any real labeled data. In particular, we demonstrate our approach for the task of fold segmentation in colonoscopy images. Folds are key anatomical landmarks that can occlude parts of the colon mucosa and possible polyps. Our approach generates realistic images maintaining the shape and location of the original folds, after the image-style-translation, better than existing methods. We run experiments both on a novel simulated dataset for fold segmentation, and real data from the EndoMapper (EM) dataset. All our new generated data and new EM metadata is being released to facilitate further research, as no public benchmark is currently available for the task of fold segmentation.
DWA-3D: A Reactive Planner for Robust and Efficient Autonomous UAV Navigation
Sep 09, 2024



Despite the growing impact of Unmanned Aerial Vehicles (UAVs) across various industries, most of current available solutions lack for a robust autonomous navigation system to deal with the appearance of obstacles safely. This work presents an approach to perform autonomous UAV planning and navigation in scenarios in which a safe and high maneuverability is required, due to the cluttered environment and the narrow rooms to move. The system combines an RRT* global planner with a newly proposed reactive planner, DWA-3D, which is the extension of the well known DWA method for 2D robots. We provide a theoretical-empirical method for adjusting the parameters of the objective function to optimize, easing the classical difficulty for tuning them. An onboard LiDAR provides a 3D point cloud, which is projected on an Octomap in which the planning and navigation decisions are made. There is not a prior map; the system builds and updates the map online, from the current and the past LiDAR information included in the Octomap. Extensive real-world experiments were conducted to validate the system and to obtain a fine tuning of the involved parameters. These experiments allowed us to provide a set of values that ensure safe operation across all the tested scenarios. Just by weighting two parameters, it is possible to prioritize either horizontal path alignment or vertical (height) tracking, resulting in enhancing vertical or lateral avoidance, respectively. Additionally, our DWA-3D proposal is able to navigate successfully even in absence of a global planner or with one that does not consider the drone's size. Finally, the conducted experiments show that computation time with the proposed parameters is not only bounded but also remains stable around 40 ms, regardless of the scenario complexity.
AVOCADO: Adaptive Optimal Collision Avoidance driven by Opinion
Jun 29, 2024



We present AVOCADO (AdaptiVe Optimal Collision Avoidance Driven by Opinion), a novel navigation approach to address holonomic robot collision avoidance when the degree of cooperation of the other agents in the environment is unknown. AVOCADO departs from a Velocity Obstacle's formulation akin to the Optimal Reciprocal Collision Avoidance method. However, instead of assuming reciprocity, AVOCADO poses an adaptive control problem that aims at adapting in real-time to the cooperation degree of other robots and agents. Adaptation is achieved through a novel nonlinear opinion dynamics design that relies solely on sensor observations. As a by-product, based on the nonlinear opinion dynamics, we propose a novel method to avoid the deadlocks under geometrical symmetries among robots and agents. Extensive numerical simulations show that AVOCADO surpasses existing geometrical, learning and planning-based approaches in mixed cooperative/non-cooperative navigation environments in terms of success rate, time to goal and computational time. In addition, we conduct multiple real experiments that verify that AVOCADO is able to avoid collisions in environments crowded with other robots and humans.
RUMOR: Reinforcement learning for Understanding a Model of the Real World for Navigation in Dynamic Environments
Apr 25, 2024



Autonomous navigation in dynamic environments is a complex but essential task for autonomous robots, with recent deep reinforcement learning approaches showing promising results. However, the complexity of the real world makes it infeasible to train agents in every possible scenario configuration. Moreover, existing methods typically overlook factors such as robot kinodynamic constraints, or assume perfect knowledge of the environment. In this work, we present RUMOR, a novel planner for differential-drive robots that uses deep reinforcement learning to navigate in highly dynamic environments. Unlike other end-to-end DRL planners, it uses a descriptive robocentric velocity space model to extract the dynamic environment information, enhancing training effectiveness and scenario interpretation. Additionally, we propose an action space that inherently considers robot kinodynamics and train it in a simulator that reproduces the real world problematic aspects, reducing the gap between the reality and simulation. We extensively compare RUMOR with other state-of-the-art approaches, demonstrating a better performance, and provide a detailed analysis of the results. Finally, we validate RUMOR's performance in real-world settings by deploying it on a ground robot. Our experiments, conducted in crowded scenarios and unseen environments, confirm the algorithm's robustness and transferability.
SHINE: Social Homology Identification for Navigation in Crowded Environments
Apr 25, 2024Navigating mobile robots in social environments remains a challenging task due to the intricacies of human-robot interactions. Most of the motion planners designed for crowded and dynamic environments focus on choosing the best velocity to reach the goal while avoiding collisions, but do not explicitly consider the high-level navigation behavior (avoiding through the left or right side, letting others pass or passing before others, etc.). In this work, we present a novel motion planner that incorporates topology distinct paths representing diverse navigation strategies around humans. The planner selects the topology class that imitates human behavior the best using a deep neural network model trained on real-world human motion data, ensuring socially intelligent and contextually aware navigation. Our system refines the chosen path through an optimization-based local planner in real time, ensuring seamless adherence to desired social behaviors. In this way, we decouple perception and local planning from the decision-making process. We evaluate the prediction accuracy of the network with real-world data. In addition, we assess the navigation capabilities in both simulation and a real-world platform, comparing it with other state-of-the-art planners. We demonstrate that our planner exhibits socially desirable behaviors and shows a smooth and remarkable performance.
Improving robot navigation in crowded environments using intrinsic rewards
Feb 13, 2023



Autonomous navigation in crowded environments is an open problem with many applications, essential for the coexistence of robots and humans in the smart cities of the future. In recent years, deep reinforcement learning approaches have proven to outperform model-based algorithms. Nevertheless, even though the results provided are promising, the works are not able to take advantage of the capabilities that their models offer. They usually get trapped in local optima in the training process, that prevent them from learning the optimal policy. They are not able to visit and interact with every possible state appropriately, such as with the states near the goal or near the dynamic obstacles. In this work, we propose using intrinsic rewards to balance between exploration and exploitation and explore depending on the uncertainty of the states instead of on the time the agent has been trained, encouraging the agent to get more curious about unknown states. We explain the benefits of the approach and compare it with other exploration algorithms that may be used for crowd navigation. Many simulation experiments are performed modifying several algorithms of the state-of-the-art, showing that the use of intrinsic rewards makes the robot learn faster and reach higher rewards and success rates (fewer collisions) in shorter navigation times, outperforming the state-of-the-art.
Deep reinforcement learning oriented for real world dynamic scenarios
Oct 20, 2022
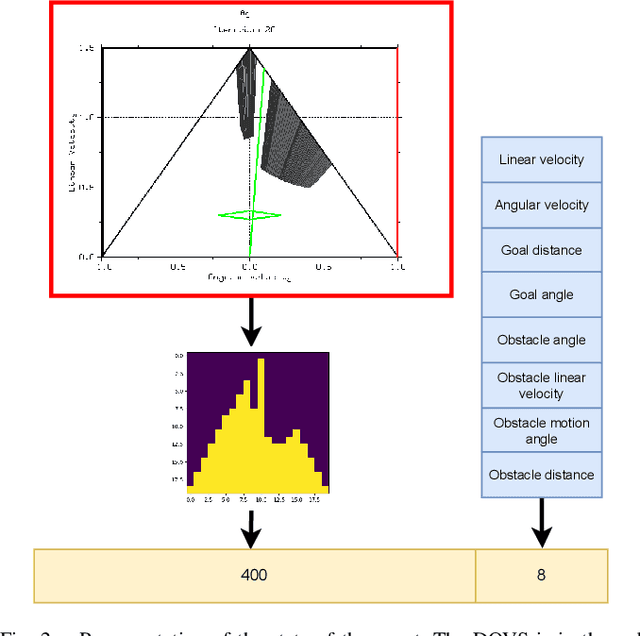
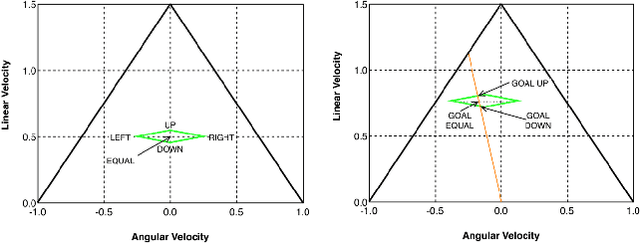
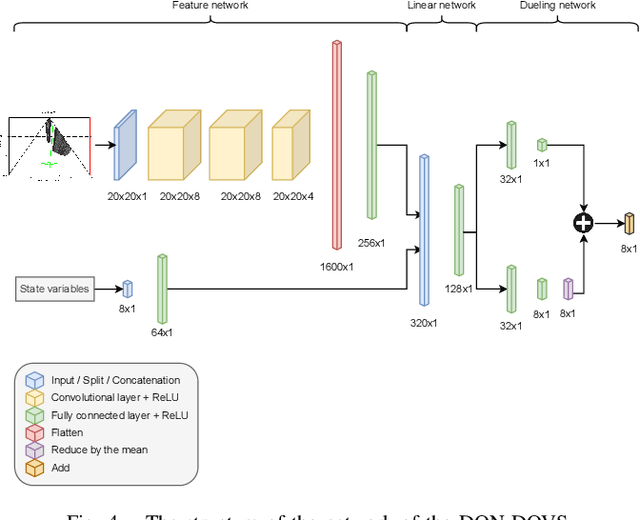
Autonomous navigation in dynamic environments is a complex but essential task for autonomous robots. Recent deep reinforcement learning approaches show promising results to solve the problem, but it is not solved yet, as they typically assume no robot kinodynamic restrictions, holonomic movement or perfect environment knowledge. Moreover, most algorithms fail in the real world due to the inability to generate real-world training data for the huge variability of possible scenarios. In this work, we present a novel planner, DQN-DOVS, that uses deep reinforcement learning on a descriptive robocentric velocity space model to navigate in highly dynamic environments. It is trained using a smart curriculum learning approach on a simulator that faithfully reproduces the real world, reducing the gap between the reality and simulation. We test the resulting algorithm in scenarios with different number of obstacles and compare it with many state-of-the-art approaches, obtaining a better performance. Finally, we try the algorithm in a ground robot, using the same setup as in the simulation experiments.
EndoMapper dataset of complete calibrated endoscopy procedures
Apr 29, 2022


Computer-assisted systems are becoming broadly used in medicine. In endoscopy, most research focuses on automatic detection of polyps or other pathologies, but localization and navigation of the endoscope is completely performed manually by physicians. To broaden this research and bring spatial Artificial Intelligence to endoscopies, data from complete procedures are needed. This data will be used to build a 3D mapping and localization systems that can perform special task like, for example, detect blind zones during exploration, provide automatic polyp measurements, guide doctors to a polyp found in a previous exploration and retrieve previous images of the same area aligning them for easy comparison. These systems will provide an improvement in the quality and precision of the procedures while lowering the burden on the physicians. This paper introduces the Endomapper dataset, the first collection of complete endoscopy sequences acquired during regular medical practice, including slow and careful screening explorations, making secondary use of medical data. Its original purpose is to facilitate the development and evaluation of VSLAM (Visual Simultaneous Localization and Mapping) methods in real endoscopy data. The first release of the dataset is composed of 59 sequences with more than 15 hours of video. It is also the first endoscopic dataset that includes both the computed geometric and photometric endoscope calibration with the original calibration videos. Meta-data and annotations associated to the dataset varies from anatomical landmark and description of the procedure labeling, tools segmentation masks, COLMAP 3D reconstructions, simulated sequences with groundtruth and meta-data related to special cases, such as sequences from the same patient. This information will improve the research in endoscopic VSLAM, as well as other research lines, and create new research lines.
3D-MiniNet: Learning a 2D Representation from Point Clouds for Fast and Efficient 3D LIDAR Semantic Segmentation
Feb 27, 2020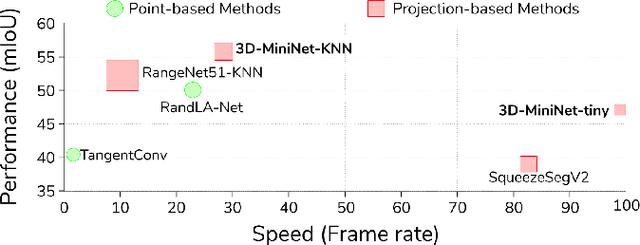
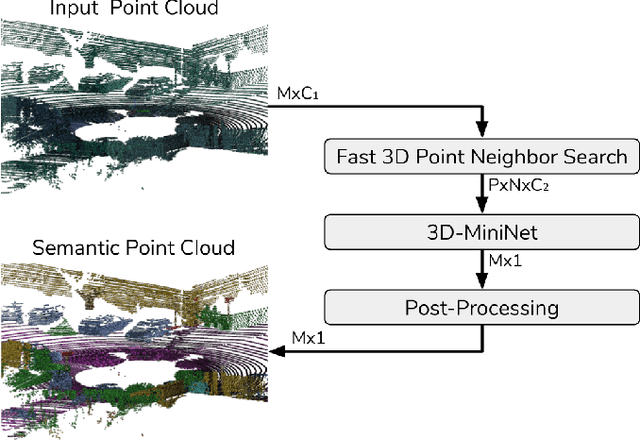
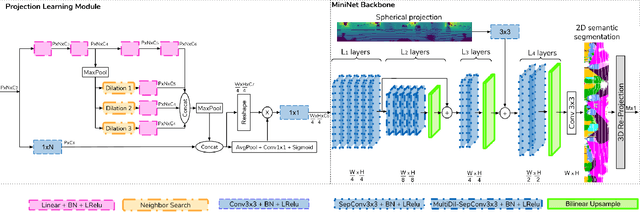

LIDAR semantic segmentation, which assigns a semantic label to each 3D point measured by the LIDAR, is becoming an essential task for many robotic applications such as autonomous driving. Fast and efficient semantic segmentation methods are needed to match the strong computational and temporal restrictions of many of these real-world applications. This work presents 3D-MiniNet, a novel approach for LIDAR semantic segmentation that combines 3D and 2D learning layers. It first learns a 2D representation from the raw points through a novel projection which extracts local and global information from the 3D data. This representation is fed to an efficient 2D Fully Convolutional Neural Network (FCNN) that produces a 2D semantic segmentation. These 2D semantic labels are re-projected back to the 3D space and enhanced through a post-processing module. The main novelty in our strategy relies on the projection learning module. Our detailed ablation study shows how each component contributes to the final performance of 3D-MiniNet. We validate our approach on well known public benchmarks (SemanticKITTI and KITTI), where 3D-MiniNet gets state-of-the-art results while being faster and more parameter-efficient than previous methods.