 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reachability-Based Confidence-Aware Probabilistic Collision Detection in Highway Driving
Feb 14, 2023
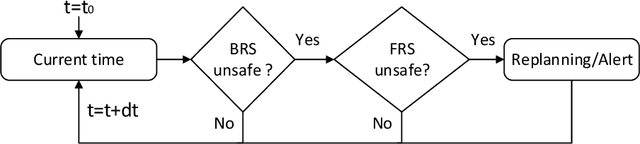

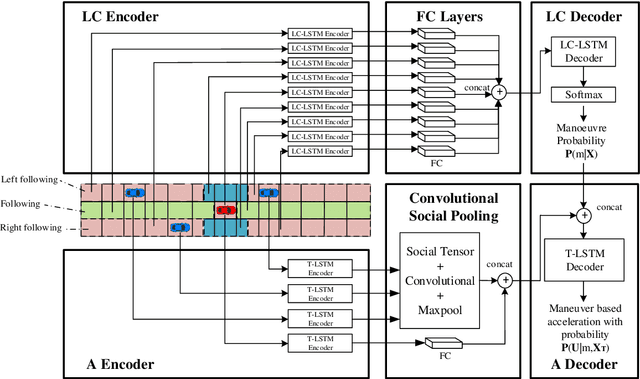
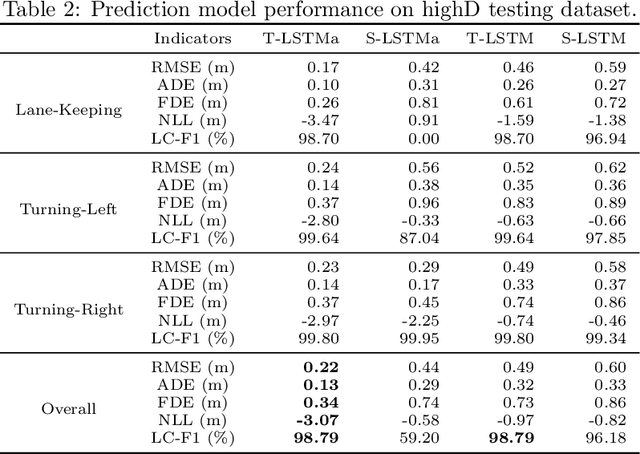
Risk assessment is a crucial component of collision warning and avoidance systems in intelligent vehicles. To accurately detect potential vehicle collisions, reachability-based formal approaches have been developed to ensure driving safety, but suffer from over-conservatism, potentially leading to false-positive risk events in complicated real-world applications. In this work, we combine two reachability analysis techniques, i.e., backward reachable set (BRS) and stochastic forward reachable set (FRS), and propose an integrated probabilistic collision detection framework in highway driving. Within the framework, we can firstly use a BRS to formally check whether a two-vehicle interaction is safe; otherwise, a prediction-based stochastic FRS is employed to estimate a collision probability at each future time step. In doing so, the framework can not only identify non-risky events with guaranteed safety, but also provide accurate collision risk estimation in safety-critical events. To construct the stochastic FRS, we develop a neural network-based acceleration model for surrounding vehicles, and further incorporate confidence-aware dynamic belief to improve the prediction accuracy. Extensive experiments are conducted to validate the performance of the acceleration prediction model based on naturalistic highway driving data, and the efficiency and effectiveness of the framework with the infused confidence belief are tested both in naturalistic and simulated highway scenarios. The proposed risk assessment framework is promising in real-world applications.
Heterogeneous Anomaly Detection for Software Systems via Semi-supervised Cross-modal Attention
Feb 14, 2023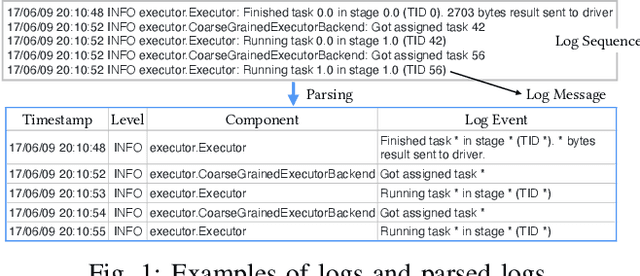
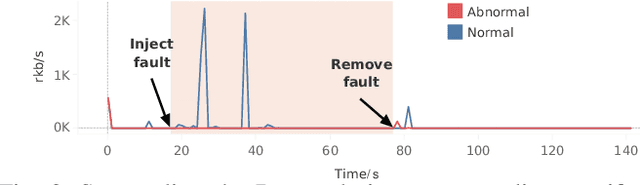
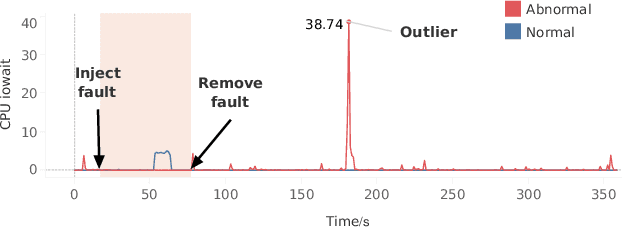
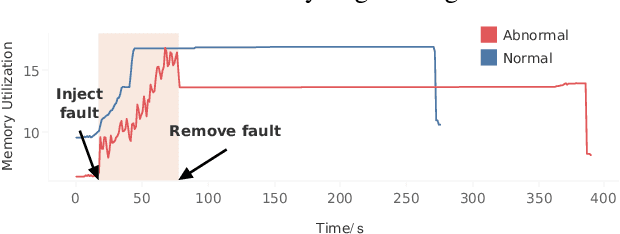
Prompt and accurate detection of system anomalies is essential to ensure the reliability of software systems. Unlike manual efforts that exploit all available run-time information, existing approaches usually leverage only a single type of monitoring data (often logs or metrics) or fail to make effective use of the joint information among different types of data. Consequently, many false predictions occur. To better understand the manifestations of system anomalies, we conduct a systematical study on a large amount of heterogeneous data, i.e., logs and metrics. Our study demonstrates that logs and metrics can manifest system anomalies collaboratively and complementarily, and neither of them only is sufficient. Thus, integrating heterogeneous data can help recover the complete picture of a system's health status. In this context, we propose Hades, the first end-to-end semi-supervised approach to effectively identify system anomalies based on heterogeneous data. Our approach employs a hierarchical architecture to learn a global representation of the system status by fusing log semantics and metric patterns. It captures discriminative features and meaningful interactions from heterogeneous data via a cross-modal attention module, trained in a semi-supervised manner. We evaluate Hades extensively on large-scale simulated data and datasets from Huawei Cloud. The experimental results present the effectiveness of our model in detecting system anomalies. We also release the code and the annotated dataset for replication and future research.
Improved Text Classification via Test-Time Augmentation
Jun 27, 2022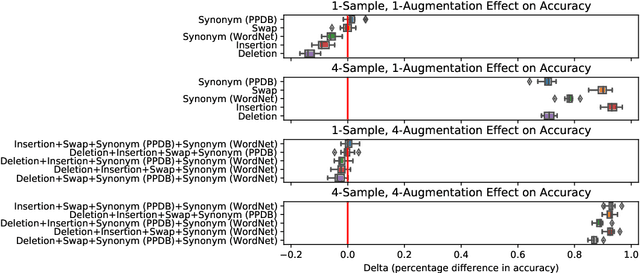

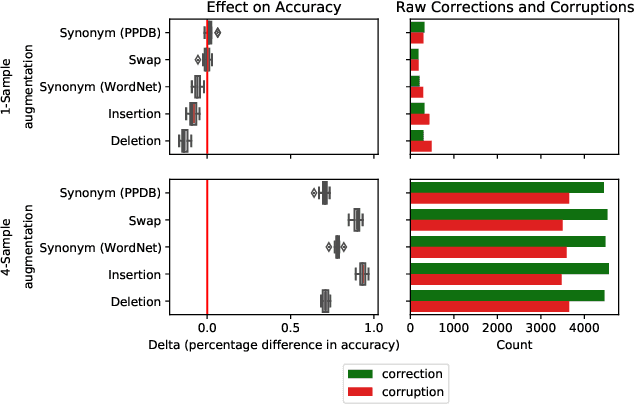
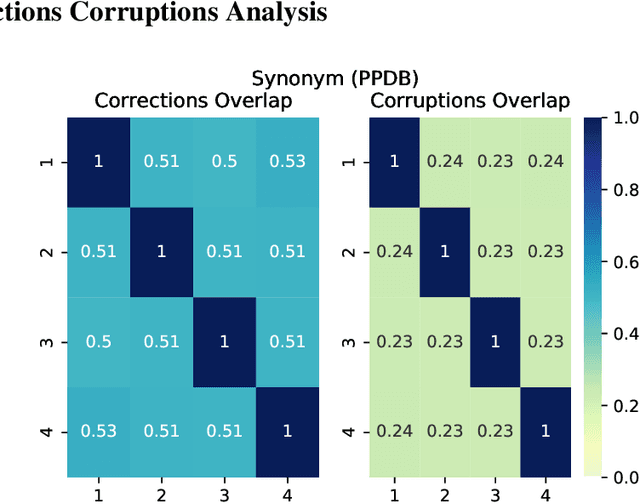
Test-time augmentation -- the aggregation of predictions across transformed examples of test inputs -- is an established technique to improve the performance of image classification models. Importantly, TTA can be used to improve model performance post-hoc, without additional training. Although test-time augmentation (TTA) can be applied to any data modality, it has seen limited adoption in NLP due in part to the difficulty of identifying label-preserving transformations. In this paper, we present augmentation policies that yield significant accuracy improvements with language models. A key finding is that augmentation policy design -- for instance, the number of samples generated from a single, non-deterministic augmentation -- has a considerable impact on the benefit of TTA. Experiments across a binary classification task and dataset show that test-time augmentation can deliver consistent improvements over current state-of-the-art approaches.
On Controller Tuning with Time-Varying Bayesian Optimization
Jul 22, 2022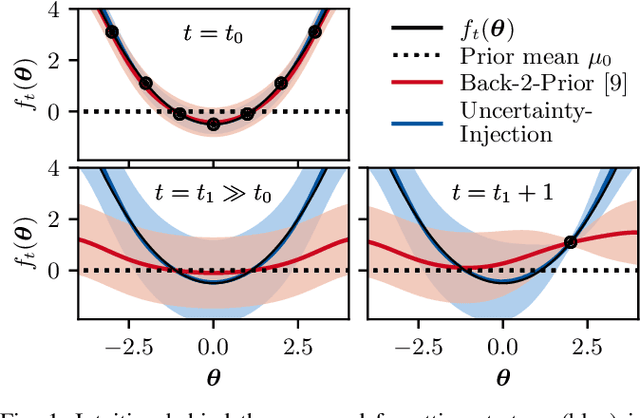
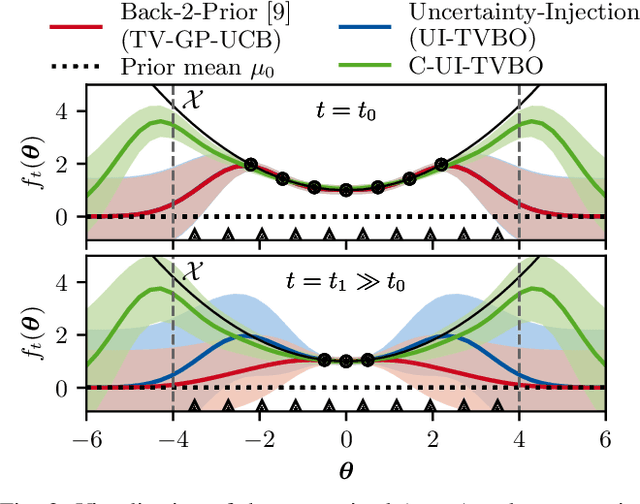
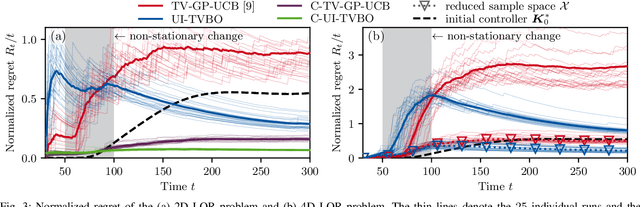
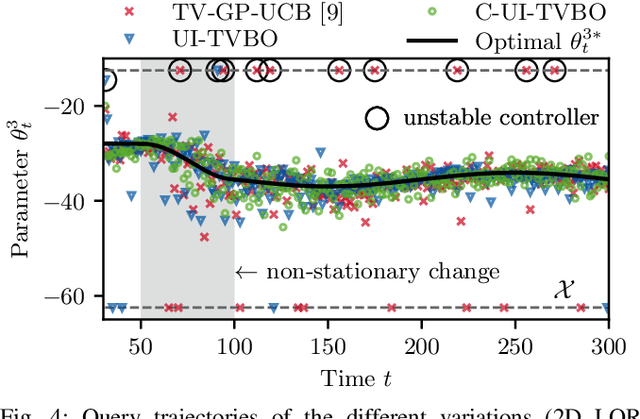
Changing conditions or environments can cause system dynamics to vary over time. To ensure optimal control performance, controllers should adapt to these changes. When the underlying cause and time of change is unknown, we need to rely on online data for this adaptation. In this paper, we will use time-varying Bayesian optimization (TVBO) to tune controllers online in changing environments using appropriate prior knowledge on the control objective and its changes. Two properties are characteristic of many online controller tuning problems: First, they exhibit incremental and lasting changes in the objective due to changes to the system dynamics, e.g., through wear and tear. Second, the optimization problem is convex in the tuning parameters. Current TVBO methods do not explicitly account for these properties, resulting in poor tuning performance and many unstable controllers through over-exploration of the parameter space. We propose a novel TVBO forgetting strategy using Uncertainty-Injection (UI), which incorporates the assumption of incremental and lasting changes. The control objective is modeled as a spatio-temporal Gaussian process (GP) with UI through a Wiener process in the temporal domain. Further, we explicitly model the convexity assumptions in the spatial dimension through GP models with linear inequality constraints. In numerical experiments, we show that our model outperforms the state-of-the-art method in TVBO, exhibiting reduced regret and fewer unstable parameter configurations.
Deep Temporal Contrastive Clustering
Dec 29, 2022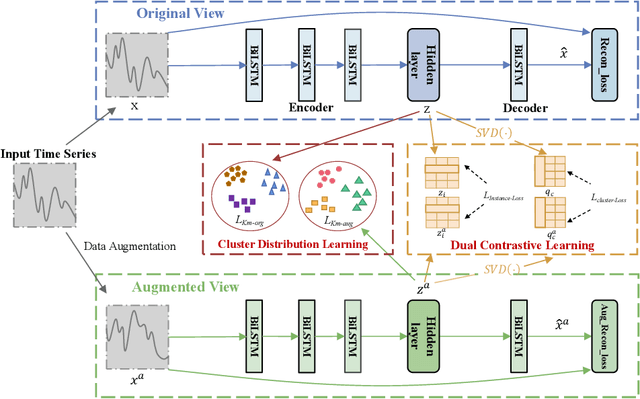
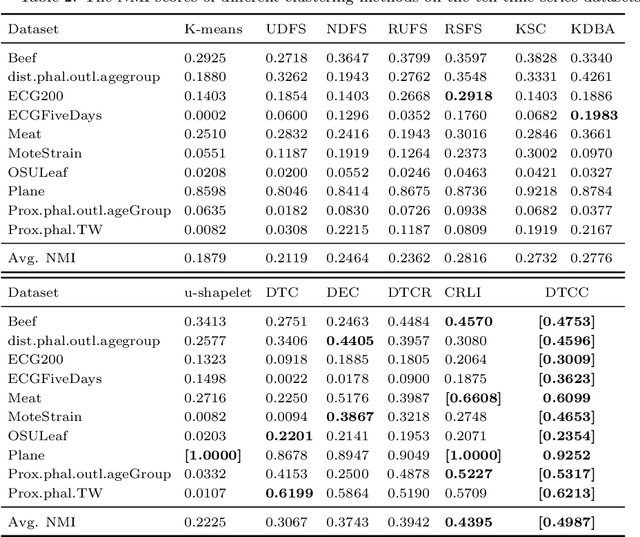
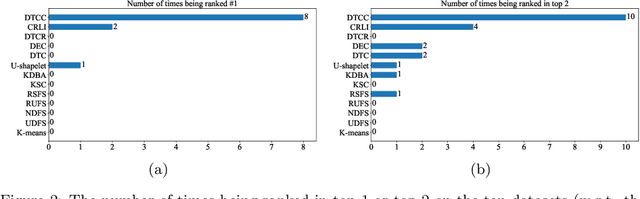
Recently the deep learning has shown its advantage in representation learning and clustering for time series data. Despite the considerable progress, the existing deep time series clustering approaches mostly seek to train the deep neural network by some instance reconstruction based or cluster distribution based objective, which, however, lack the ability to exploit the sample-wise (or augmentation-wise) contrastive information or even the higher-level (e.g., cluster-level) contrastiveness for learning discriminative and clustering-friendly representations. In light of this, this paper presents a deep temporal contrastive clustering (DTCC) approach, which for the first time, to our knowledge, incorporates the contrastive learning paradigm into the deep time series clustering research. Specifically, with two parallel views generated from the original time series and their augmentations, we utilize two identical auto-encoders to learn the corresponding representations, and in the meantime perform the cluster distribution learning by incorporating a k-means objective. Further, two levels of contrastive learning are simultaneously enforced to capture the instance-level and cluster-level contrastive information, respectively. With the reconstruction loss of the auto-encoder, the cluster distribution loss, and the two levels of contrastive losses jointly optimized, the network architecture is trained in a self-supervised manner and the clustering result can thereby be obtained. Experiments on a variety of time series datasets demonstrate the superiority of our DTCC approach over the state-of-the-art.
Brainomaly: Unsupervised Neurologic Disease Detection Utilizing Unannotated T1-weighted Brain MR Images
Feb 18, 2023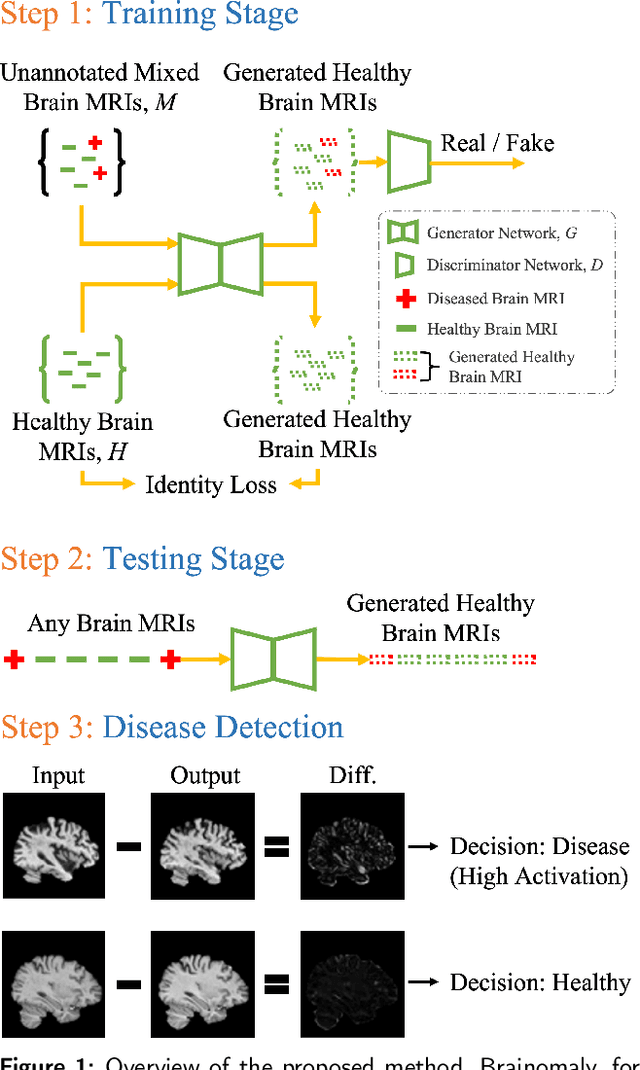
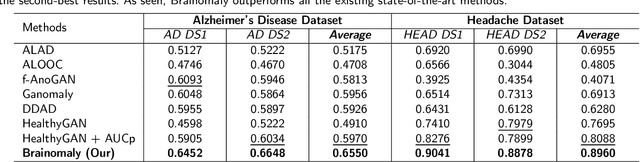
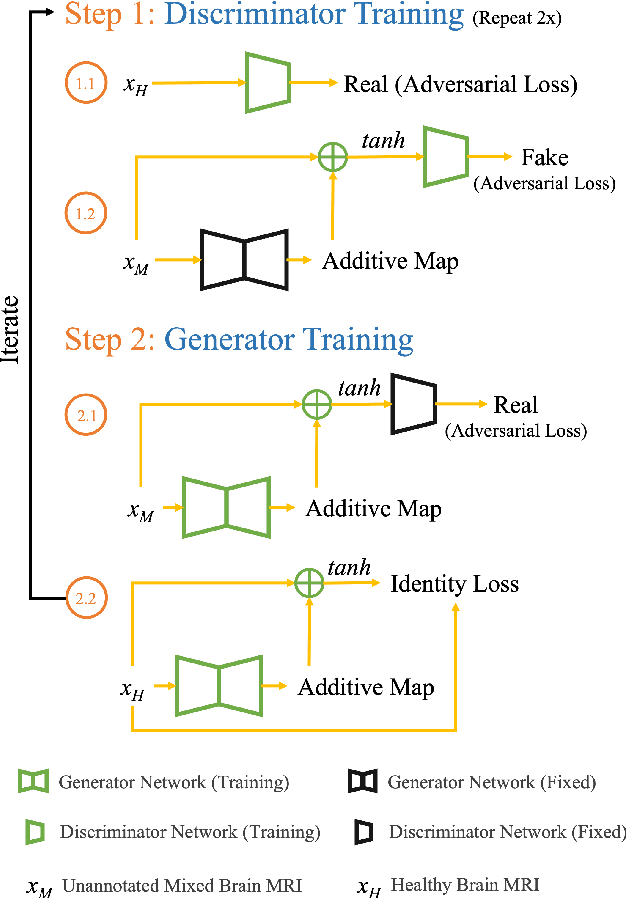
Deep neural networks have revolutionized the field of supervised learning by enabling accurate predictions through learning from large annotated datasets. However, acquiring large annotated medical imaging datasets is a challenging task, especially for rare diseases, due to the high cost, time, and effort required for annotation. In these scenarios, unsupervised disease detection methods, such as anomaly detection, can save significant human effort. A typically used approach for anomaly detection is to learn the images from healthy subjects only, assuming the model will detect the images from diseased subjects as outliers. However, in many real-world scenarios, unannotated datasets with a mix of healthy and diseased individuals are available. Recent studies have shown improvement in unsupervised disease/anomaly detection using such datasets of unannotated images from healthy and diseased individuals compared to datasets that only include images from healthy individuals. A major issue remains unaddressed in these studies, which is selecting the best model for inference from a set of trained models without annotated samples. To address this issue, we propose Brainomaly, a GAN-based image-to-image translation method for neurologic disease detection using unannotated T1-weighted brain MRIs of individuals with neurologic diseases and healthy subjects. Brainomaly is trained to remove the diseased regions from the input brain MRIs and generate MRIs of corresponding healthy brains. Instead of generating the healthy images directly, Brainomaly generates an additive map where each voxel indicates the amount of changes required to make the input image look healthy. In addition, Brainomaly uses a pseudo-AUC metric for inference model selection, which further improves the detection performance. Our Brainomaly outperforms existing state-of-the-art methods by large margins.
Async-HFL: Efficient and Robust Asynchronous Federated Learning in Hierarchical IoT Networks
Jan 17, 2023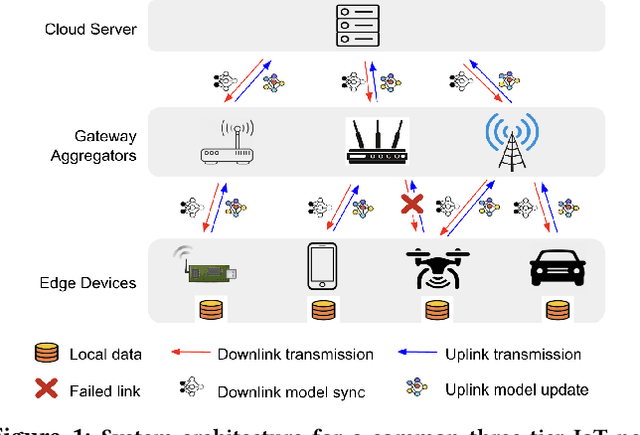
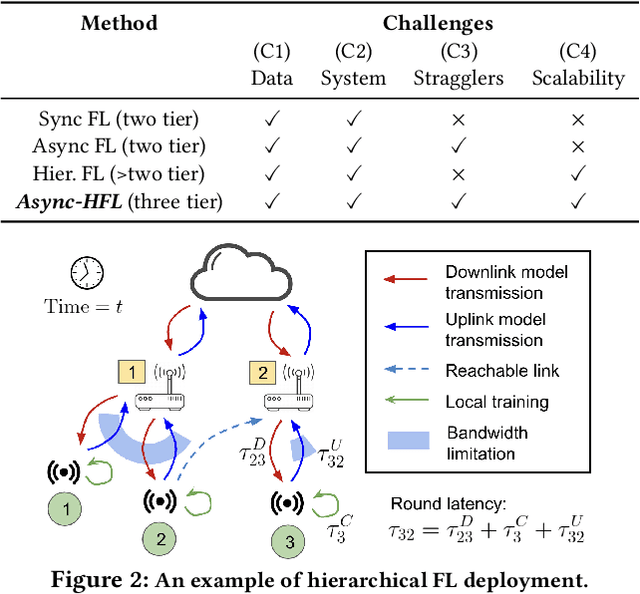
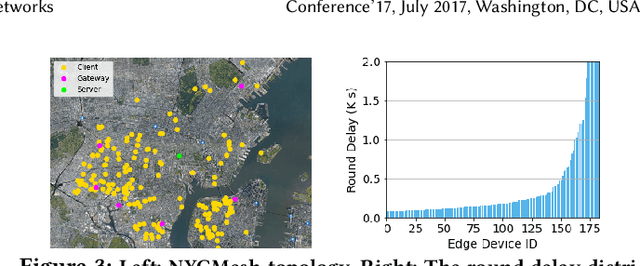

Federated Learning (FL) has gained increasing interest in recent years as a distributed on-device learning paradigm. However, multiple challenges remain to be addressed for deploying FL in real-world Internet-of-Things (IoT) networks with hierarchies. Although existing works have proposed various approaches to account data heterogeneity, system heterogeneity, unexpected stragglers and scalibility, none of them provides a systematic solution to address all of the challenges in a hierarchical and unreliable IoT network. In this paper, we propose an asynchronous and hierarchical framework (Async-HFL) for performing FL in a common three-tier IoT network architecture. In response to the largely varied delays, Async-HFL employs asynchronous aggregations at both the gateway and the cloud levels thus avoids long waiting time. To fully unleash the potential of Async-HFL in converging speed under system heterogeneities and stragglers, we design device selection at the gateway level and device-gateway association at the cloud level. Device selection chooses edge devices to trigger local training in real-time while device-gateway association determines the network topology periodically after several cloud epochs, both satisfying bandwidth limitation. We evaluate Async-HFL's convergence speedup using large-scale simulations based on ns-3 and a network topology from NYCMesh. Our results show that Async-HFL converges 1.08-1.31x faster in wall-clock time and saves up to 21.6% total communication cost compared to state-of-the-art asynchronous FL algorithms (with client selection). We further validate Async-HFL on a physical deployment and observe robust convergence under unexpected stragglers.
Full-Waveform Modeling for Time-of-Flight Measurements based on Arrival Time of Photons
Aug 03, 2022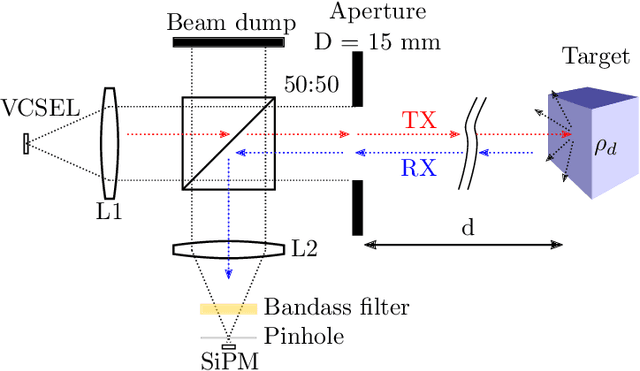
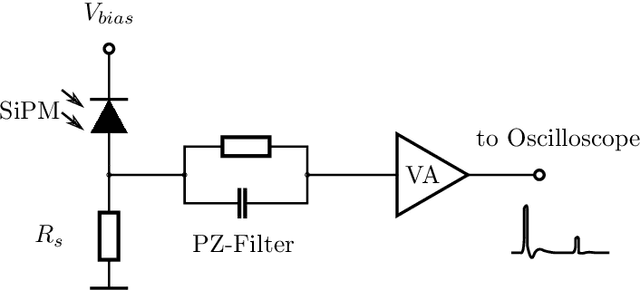
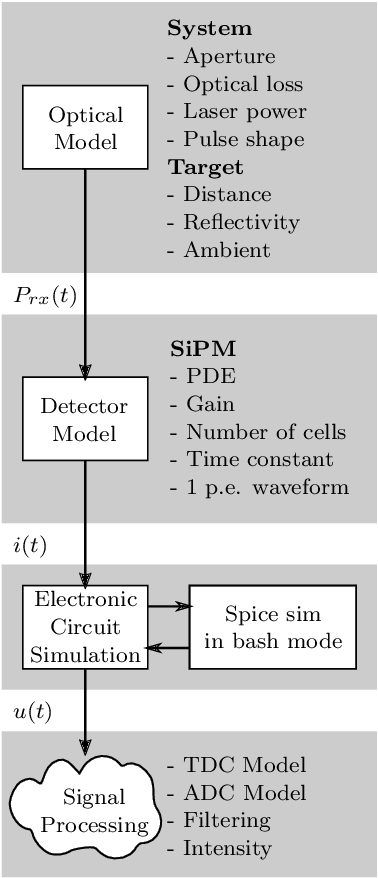
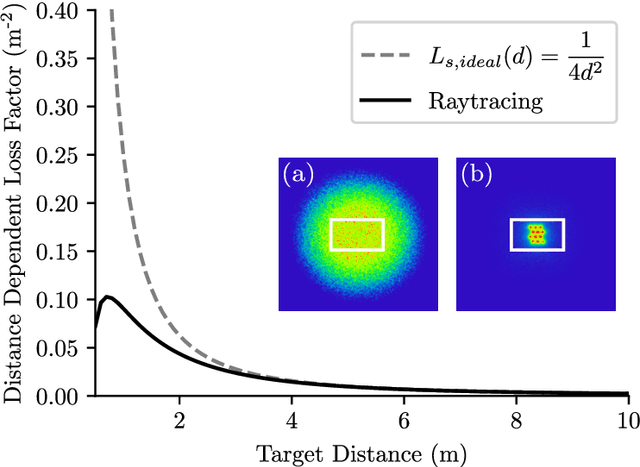
Modern LiDAR sensors find increasing use in safety-critical applications. Therefore, highly accurate modeling of the system's behavior under demanding environmental conditions is necessary. In this paper, we present a modular structure to accurately simulate the amplified raw detector signal of a direct time-of-flight LiDAR system for coaxial transmitter-receiver optics. Our model describes, a measurement system based on standard optical components and a detector able of converting single photons to an electrical signal. To verify the model's predictions, single-point measurements for targets of different reflectivity at defined distances were performed. Statistical analysis shows an R-squared value greater than 0.990 for simulated and measured signal amplitude levels. Noise modeling shows good accordance with the performed measurements for different target irradiance levels. The presented results have a guiding significance in the modeling of the complex signal processing chain of LiDAR systems, as it enables the prediction of key parameters of the system early in the development process. Hence, unnecessary costs by design flaws can be mitigated. The modular structure allows easy adaption for arbitrary LiDAR systems.
Estimating Latent Population Flows from Aggregated Data via Inversing Multi-Marginal Optimal Transport
Dec 30, 2022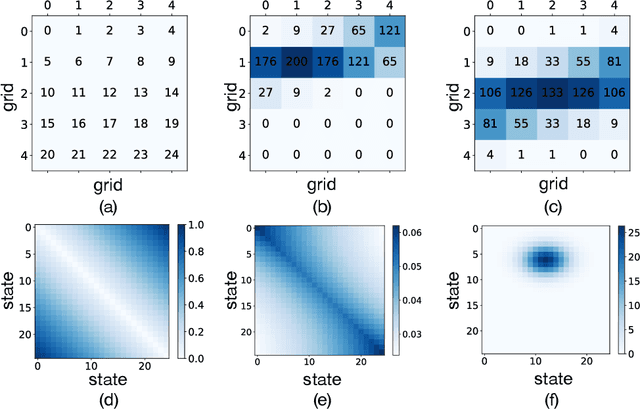
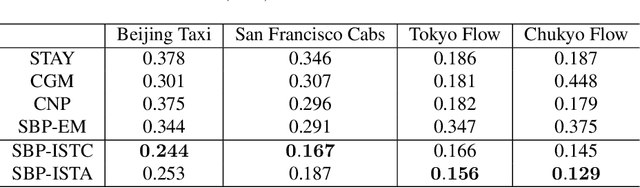
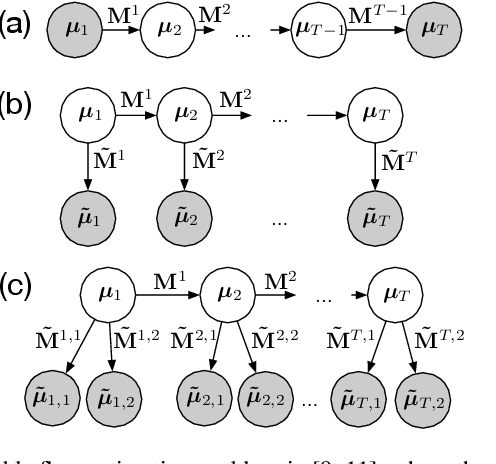
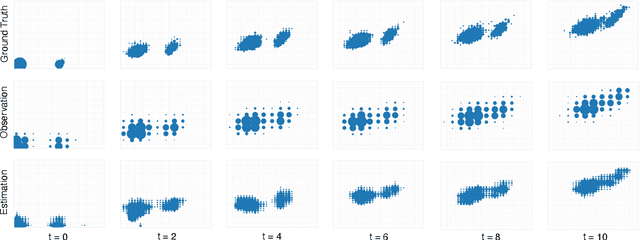
We study the problem of estimating latent population flows from aggregated count data. This problem arises when individual trajectories are not available due to privacy issues or measurement fidelity. Instead, the aggregated observations are measured over discrete-time points, for estimating the population flows among states. Most related studies tackle the problems by learning the transition parameters of a time-homogeneous Markov process. Nonetheless, most real-world population flows can be influenced by various uncertainties such as traffic jam and weather conditions. Thus, in many cases, a time-homogeneous Markov model is a poor approximation of the much more complex population flows. To circumvent this difficulty, we resort to a multi-marginal optimal transport (MOT) formulation that can naturally represent aggregated observations with constrained marginals, and encode time-dependent transition matrices by the cost functions. In particular, we propose to estimate the transition flows from aggregated data by learning the cost functions of the MOT framework, which enables us to capture time-varying dynamic patterns. The experiments demonstrate the improved accuracy of the proposed algorithms than the related methods in estimating several real-world transition flows.
Maneuver Decision-Making For Autonomous Air Combat Through Curriculum Learning And Reinforcement Learning With Sparse Rewards
Feb 12, 2023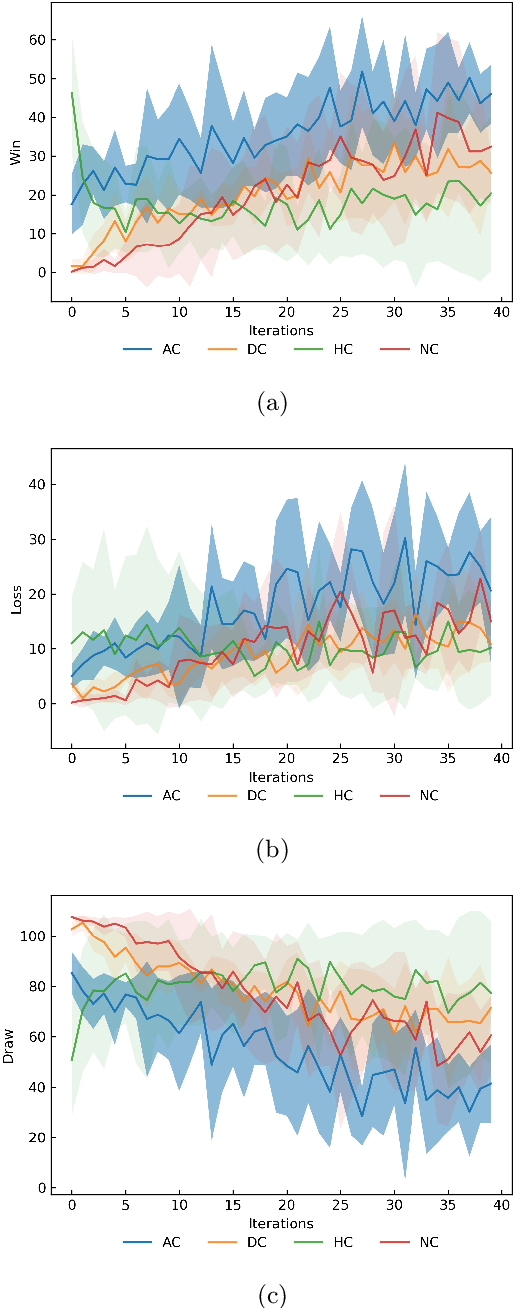
Reinforcement learning is an effective way to solve the decision-making problems. It is a meaningful and valuable direction to investigate autonomous air combat maneuver decision-making method based on reinforcement learning. However, when using reinforcement learning to solve the decision-making problems with sparse rewards, such as air combat maneuver decision-making, it costs too much time for training and the performance of the trained agent may not be satisfactory. In order to solve these problems, the method based on curriculum learning is proposed. First, three curricula of air combat maneuver decision-making are designed: angle curriculum, distance curriculum and hybrid curriculum. These courses are used to train air combat agents respectively, and compared with the original method without any curriculum. The training results show that angle curriculum can increase the speed and stability of training, and improve the performance of the agent; distance curriculum can increase the speed and stability of agent training; hybrid curriculum has a negative impact on training, because it makes the agent get stuck at local optimum. The simulation results show that after training, the agent can handle the situations where targets come from different directions, and the maneuver decision results are consistent with the characteristics of missile.