 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Hidden Markov Models Using Conditional Samples
Feb 28, 2023
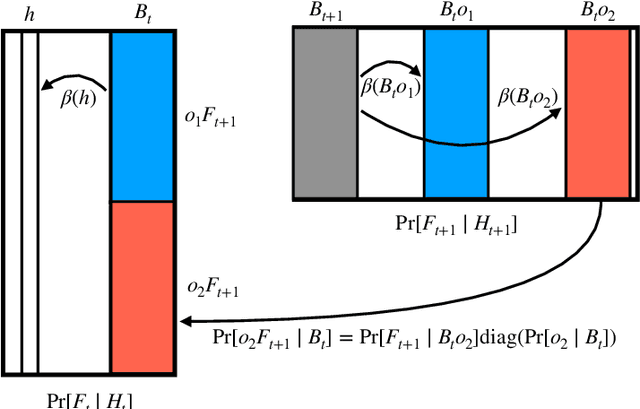
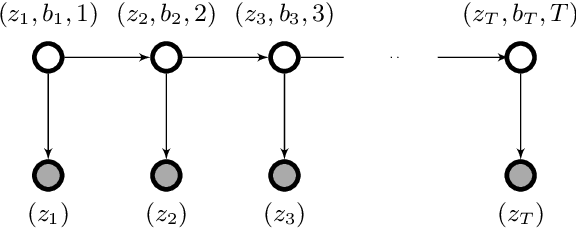
This paper is concerned with the computational complexity of learning the Hidden Markov Model (HMM). Although HMMs are some of the most widely used tools in sequential and time series modeling, they are cryptographically hard to learn in the standard setting where one has access to i.i.d. samples of observation sequences. In this paper, we depart from this setup and consider an interactive access model, in which the algorithm can query for samples from the conditional distributions of the HMMs. We show that interactive access to the HMM enables computationally efficient learning algorithms, thereby bypassing cryptographic hardness. Specifically, we obtain efficient algorithms for learning HMMs in two settings: (a) An easier setting where we have query access to the exact conditional probabilities. Here our algorithm runs in polynomial time and makes polynomially many queries to approximate any HMM in total variation distance. (b) A harder setting where we can only obtain samples from the conditional distributions. Here the performance of the algorithm depends on a new parameter, called the fidelity of the HMM. We show that this captures cryptographically hard instances and previously known positive results. We also show that these results extend to a broader class of distributions with latent low rank structure. Our algorithms can be viewed as generalizations and robustifications of Angluin's $L^*$ algorithm for learning deterministic finite automata from membership queries.
Learned Risk Metric Maps for Kinodynamic Systems
Feb 28, 2023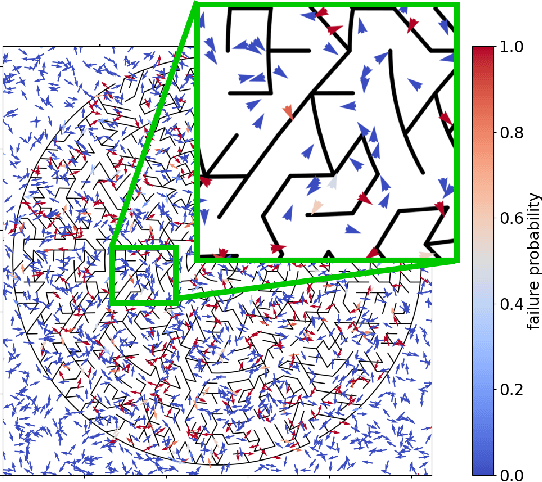
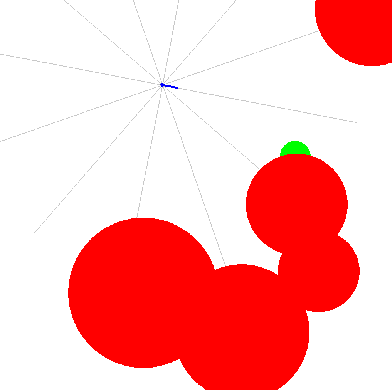

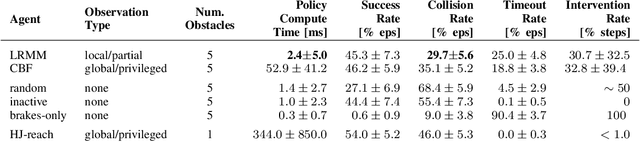
We present Learned Risk Metric Maps (LRMM) for real-time estimation of coherent risk metrics of high dimensional dynamical systems operating in unstructured, partially observed environments. LRMM models are simple to design and train -- requiring only procedural generation of obstacle sets, state and control sampling, and supervised training of a function approximator -- which makes them broadly applicable to arbitrary system dynamics and obstacle sets. In a parallel autonomy setting, we demonstrate the model's ability to rapidly infer collision probabilities of a fast-moving car-like robot driving recklessly in an obstructed environment; allowing the LRMM agent to intervene, take control of the vehicle, and avoid collisions. In this time-critical scenario, we show that LRMMs can evaluate risk metrics 20-100x times faster than alternative safety algorithms based on control barrier functions (CBFs) and Hamilton-Jacobi reachability (HJ-reach), leading to 5-15\% fewer obstacle collisions by the LRMM agent than CBFs and HJ-reach. This performance improvement comes in spite of the fact that the LRMM model only has access to local/partial observation of obstacles, whereas the CBF and HJ-reach agents are granted privileged/global information. We also show that our model can be equally well trained on a 12-dimensional quadrotor system operating in an obstructed indoor environment. The LRMM codebase is provided at https://github.com/mit-drl/pyrmm.
DFR-FastMOT: Detection Failure Resistant Tracker for Fast Multi-Object Tracking Based on Sensor Fusion
Feb 28, 2023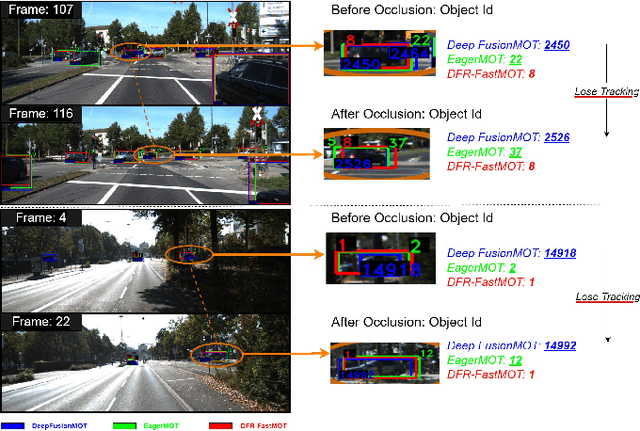
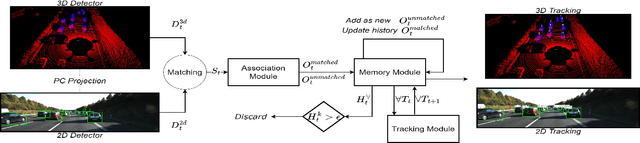

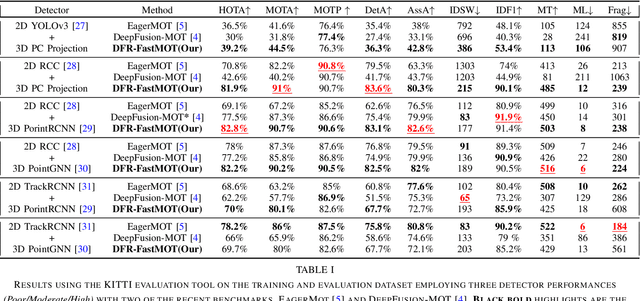
Persistent multi-object tracking (MOT) allows autonomous vehicles to navigate safely in highly dynamic environments. One of the well-known challenges in MOT is object occlusion when an object becomes unobservant for subsequent frames. The current MOT methods store objects information, like objects' trajectory, in internal memory to recover the objects after occlusions. However, they retain short-term memory to save computational time and avoid slowing down the MOT method. As a result, they lose track of objects in some occlusion scenarios, particularly long ones. In this paper, we propose DFR-FastMOT, a light MOT method that uses data from a camera and LiDAR sensors and relies on an algebraic formulation for object association and fusion. The formulation boosts the computational time and permits long-term memory that tackles more occlusion scenarios. Our method shows outstanding tracking performance over recent learning and non-learning benchmarks with about 3% and 4% margin in MOTA, respectively. Also, we conduct extensive experiments that simulate occlusion phenomena by employing detectors with various distortion levels. The proposed solution enables superior performance under various distortion levels in detection over current state-of-art methods. Our framework processes about 7,763 frames in 1.48 seconds, which is seven times faster than recent benchmarks. The framework will be available at https://github.com/MohamedNagyMostafa/DFR-FastMOT.
Randomized Control of Wireless Temporal Coherence via Reconfigurable Intelligent Surface
Jan 31, 2023
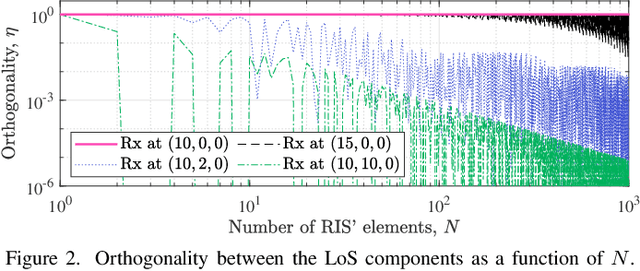
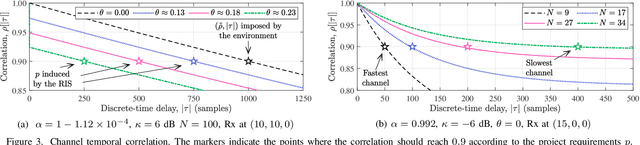
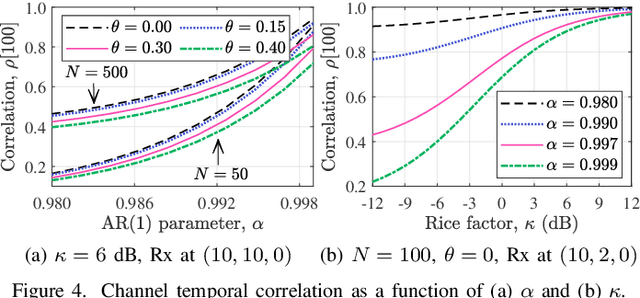
A reconfigurable intelligent surface (RIS) can shape the wireless propagation channel by inducing controlled phase shift variations to the impinging signals. Multiple works have considered the use of RIS by time-varying configurations of reflection coefficients. In this work we use the RIS to control the channel coherence time and introduce a generalized discrete-time-varying channel model for RIS-aided systems. We characterize the temporal variation of channel correlation by assuming that a configuration of RIS' elements changes at every time step. The analysis converges to a randomized framework to control the channel coherence time by setting the number of RIS' elements and their phase shifts. The main result is a framework for a flexible block-fading model, where the number of samples within a coherence block can be dynamically adapted.
ART: Automatic multi-step reasoning and tool-use for large language models
Mar 16, 2023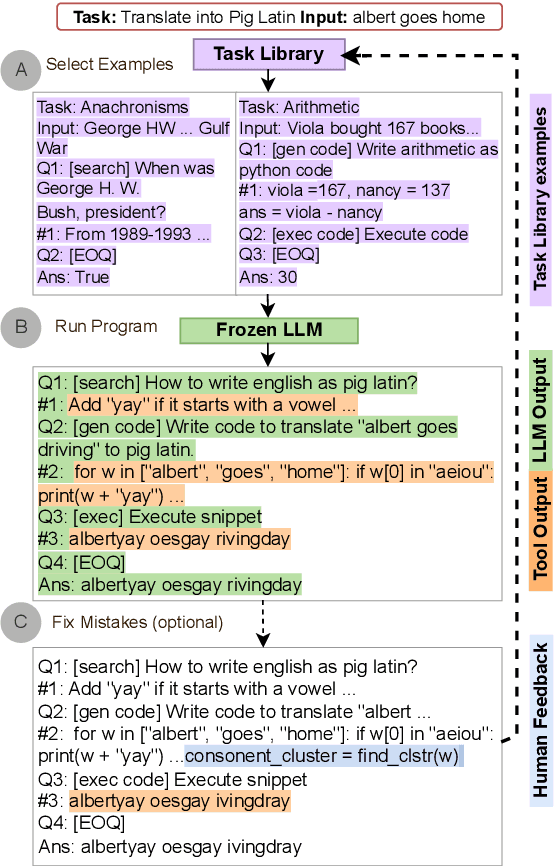
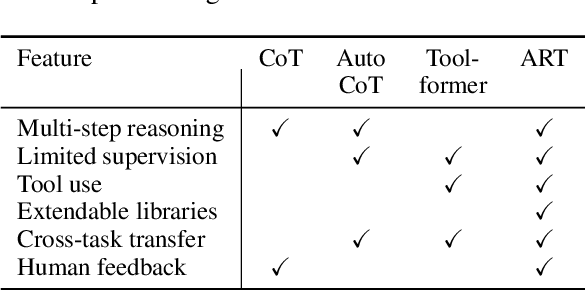
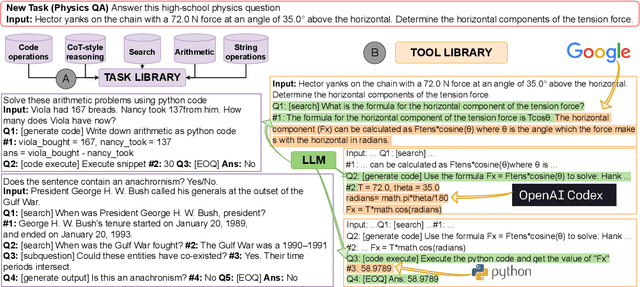
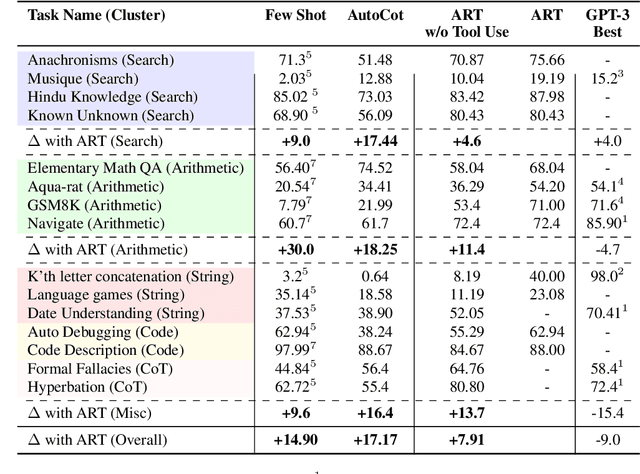
Large language models (LLMs) can perform complex reasoning in few- and zero-shot settings by generating intermediate chain of thought (CoT) reasoning steps. Further, each reasoning step can rely on external tools to support computation beyond the core LLM capabilities (e.g. search/running code). Prior work on CoT prompting and tool use typically requires hand-crafting task-specific demonstrations and carefully scripted interleaving of model generations with tool use. We introduce Automatic Reasoning and Tool-use (ART), a framework that uses frozen LLMs to automatically generate intermediate reasoning steps as a program. Given a new task to solve, ART selects demonstrations of multi-step reasoning and tool use from a task library. At test time, ART seamlessly pauses generation whenever external tools are called, and integrates their output before resuming generation. ART achieves a substantial improvement over few-shot prompting and automatic CoT on unseen tasks in the BigBench and MMLU benchmarks, and matches performance of hand-crafted CoT prompts on a majority of these tasks. ART is also extensible, and makes it easy for humans to improve performance by correcting errors in task-specific programs or incorporating new tools, which we demonstrate by drastically improving performance on select tasks with minimal human intervention.
Model Based Explanations of Concept Drift
Mar 16, 2023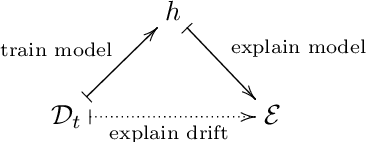
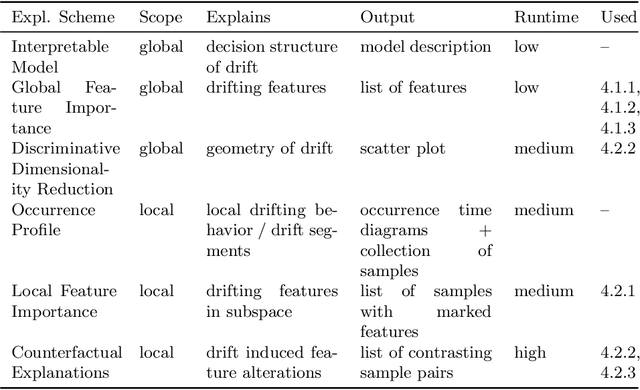
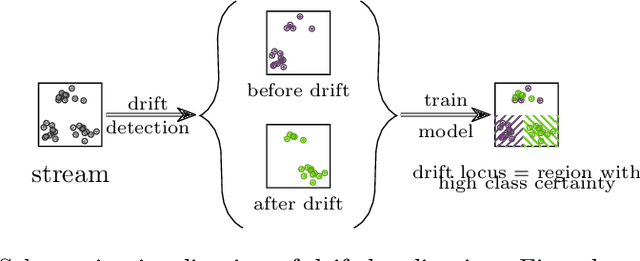
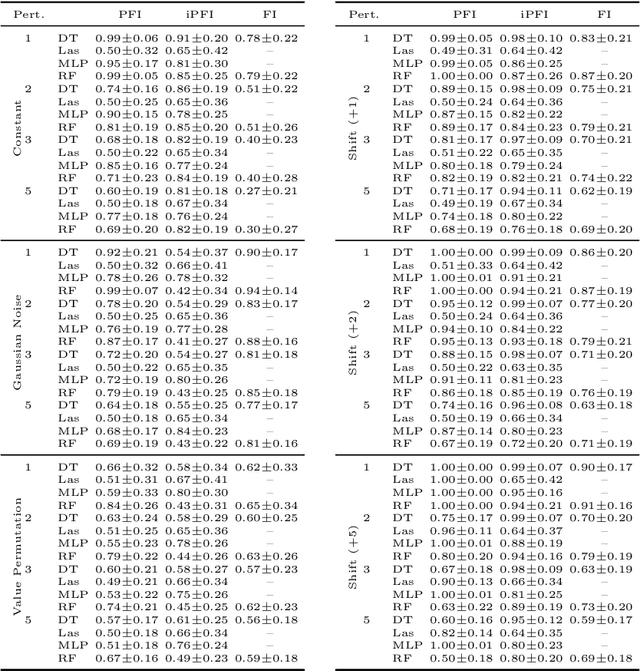
The notion of concept drift refers to the phenomenon that the distribution generating the observed data changes over time. If drift is present, machine learning models can become inaccurate and need adjustment. While there do exist methods to detect concept drift or to adjust models in the presence of observed drift, the question of explaining drift, i.e., describing the potentially complex and high dimensional change of distribution in a human-understandable fashion, has hardly been considered so far. This problem is of importance since it enables an inspection of the most prominent characteristics of how and where drift manifests itself. Hence, it enables human understanding of the change and it increases acceptance of life-long learning models. In this paper, we present a novel technology characterizing concept drift in terms of the characteristic change of spatial features based on various explanation techniques. To do so, we propose a methodology to reduce the explanation of concept drift to an explanation of models that are trained in a suitable way extracting relevant information regarding the drift. This way a large variety of explanation schemes is available. Thus, a suitable method can be selected for the problem of drift explanation at hand. We outline the potential of this approach and demonstrate its usefulness in several examples.
Multi-step planning with learned effects of (possibly partial) action executions
Mar 16, 2023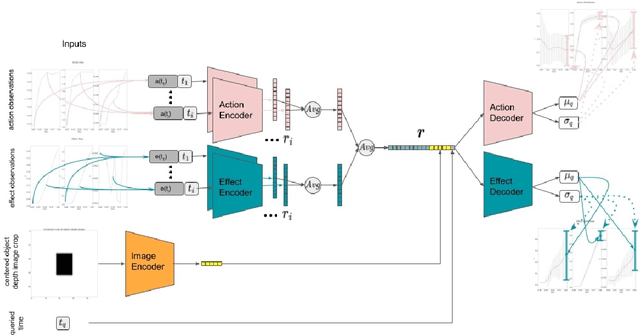
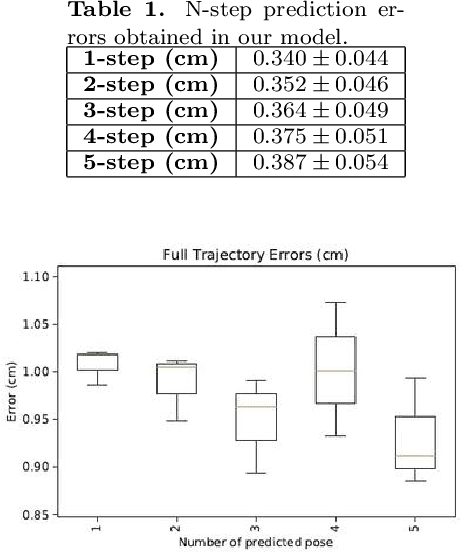
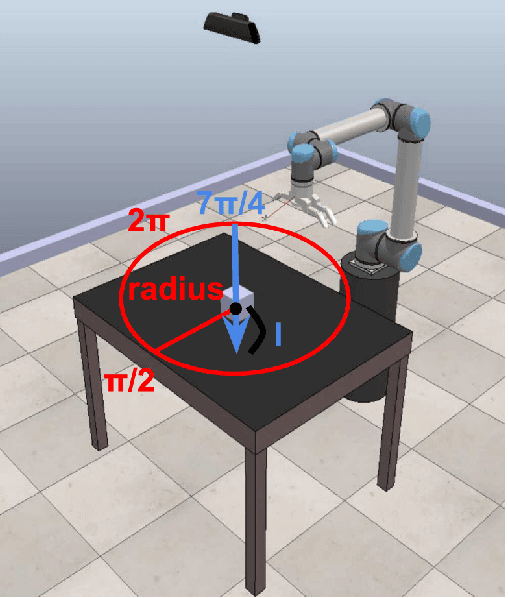
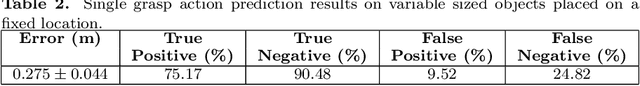
In this paper, we propose an affordance model, which is built on Conditional Neural Processes, that can predict effect trajectories given objects, action or effect information at any time. Affordances are represented in a latent representation that combines object, action and effect channels. This model allows us to make predictions of intermediate effects expected to be obtained from partial action executions, and this capability is used to make multi-step plans that include partial actions in order to achieve goals. We first show that our model can make accurate continuous effect predictions. We compared our model with a recent LSTM-based effect predictor using an existing dataset that includes lever-up actions. Next, we showed that our model can generate accurate effect predictions for push and grasp actions. Finally, we showed that our system can generate successful multi-step plans in order to bring objects to desired positions. Importantly, the proposed system generated more accurate and effective plans with partial action executions compared to plans that only consider full action executions. Although continuous effect prediction and multi-step planning based on learning affordances have been studied in the literature, continuous affordance and effect predictions have not been utilized in making accurate and fine-grained plans.
Gate Recurrent Unit Network based on Hilbert-Schmidt Independence Criterion for State-of-Health Estimation
Mar 16, 2023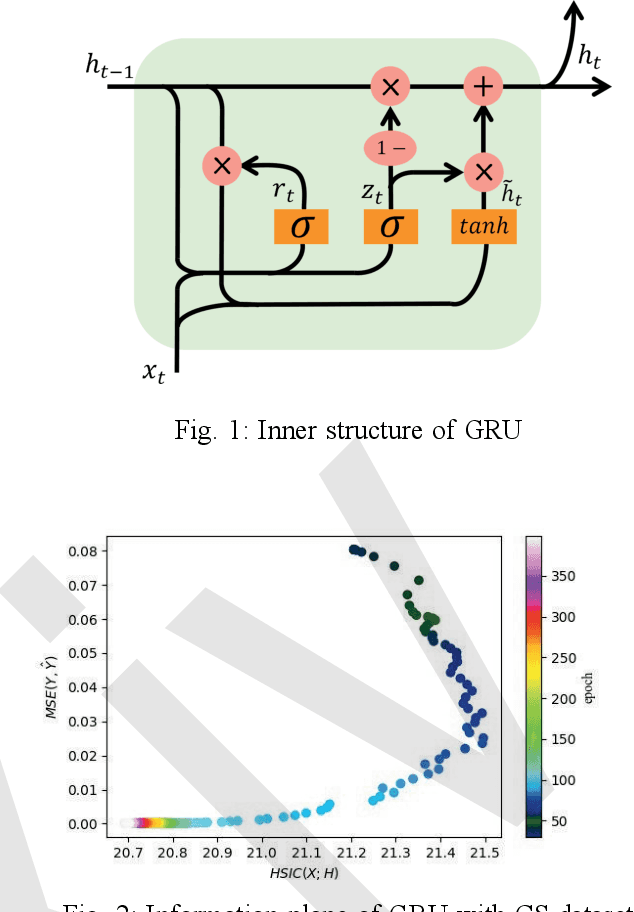
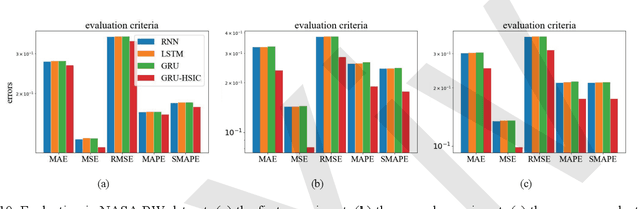
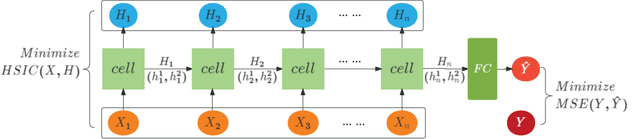
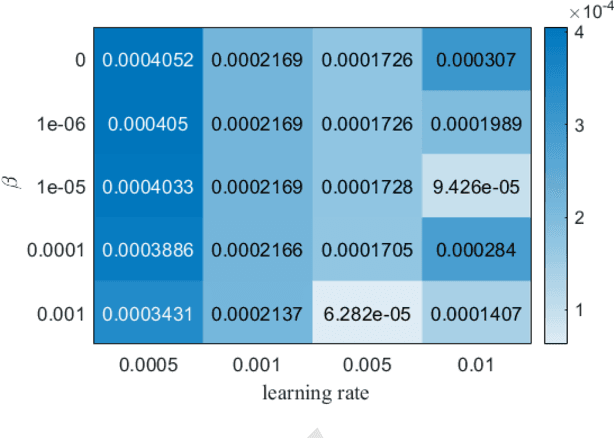
State-of-health (SOH) estimation is a key step in ensuring the safe and reliable operation of batteries. Due to issues such as varying data distribution and sequence length in different cycles, most existing methods require health feature extraction technique, which can be time-consuming and labor-intensive. GRU can well solve this problem due to the simple structure and superior performance, receiving widespread attentions. However, redundant information still exists within the network and impacts the accuracy of SOH estimation. To address this issue, a new GRU network based on Hilbert-Schmidt Independence Criterion (GRU-HSIC) is proposed. First, a zero masking network is used to transform all battery data measured with varying lengths every cycle into sequences of the same length, while still retaining information about the original data size in each cycle. Second, the Hilbert-Schmidt Independence Criterion (HSIC) bottleneck, which evolved from Information Bottleneck (IB) theory, is extended to GRU to compress the information from hidden layers. To evaluate the proposed method, we conducted experiments on datasets from the Center for Advanced Life Cycle Engineering (CALCE) of the University of Maryland and NASA Ames Prognostics Center of Excellence. Experimental results demonstrate that our model achieves higher accuracy than other recurrent models.
Exploring Distributional Shifts in Large Language Models for Code Analysis
Mar 16, 2023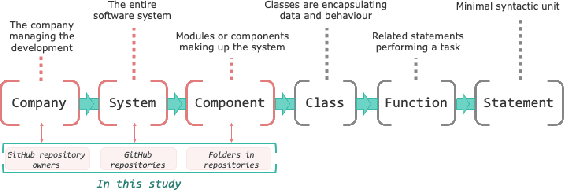
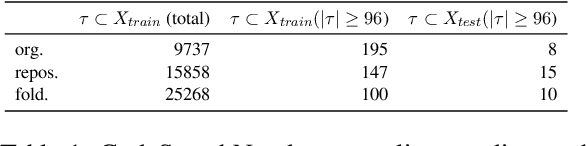
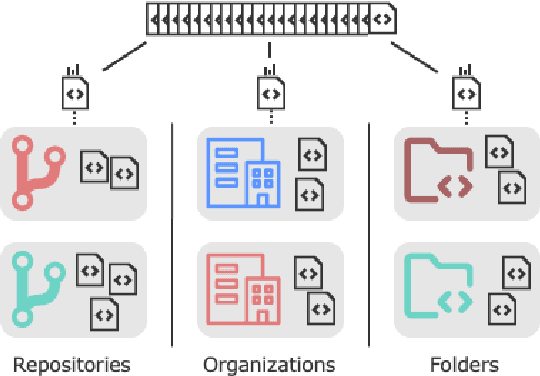
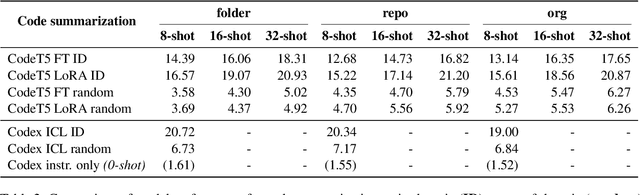
We systematically study the capacity of two large language models for code - CodeT5 and Codex - to generalize to out-of-domain data. In this study, we consider two fundamental applications - code summarization, and code generation. We split data into domains following its natural boundaries - by an organization, by a project, and by a module within the software project. This makes recognition of in-domain vs out-of-domain data at the time of deployment trivial. We establish that samples from each new domain present both models with a significant challenge of distribution shift. We study how well different established methods can adapt models to better generalize to new domains. Our experiments show that while multitask learning alone is a reasonable baseline, combining it with few-shot finetuning on examples retrieved from training data can achieve very strong performance. In fact, according to our experiments, this solution can outperform direct finetuning for very low-data scenarios. Finally, we consider variations of this approach to create a more broadly applicable method to adapt to multiple domains at once. We find that in the case of code generation, a model adapted to multiple domains simultaneously performs on par with those adapted to each domain individually.
Practical Knowledge Distillation: Using DNNs to Beat DNNs
Feb 23, 2023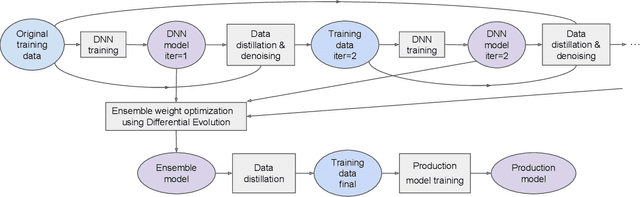
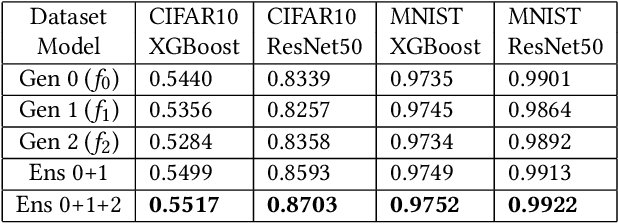
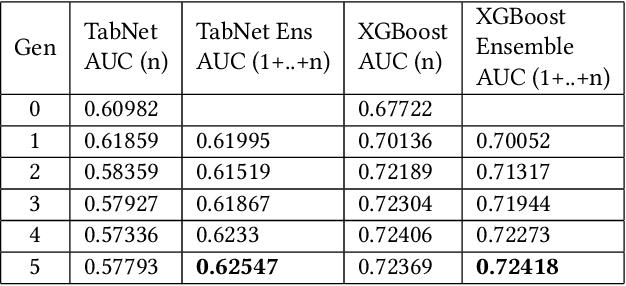

For tabular data sets, we explore data and model distillation, as well as data denoising. These techniques improve both gradient-boosting models and a specialized DNN architecture. While gradient boosting is known to outperform DNNs on tabular data, we close the gap for datasets with 100K+ rows and give DNNs an advantage on small data sets. We extend these results with input-data distillation and optimized ensembling to help DNN performance match or exceed that of gradient boosting. As a theoretical justification of our practical method, we prove its equivalence to classical cross-entropy knowledge distillation. We also qualitatively explain the superiority of DNN ensembles over XGBoost on small data sets. For an industry end-to-end real-time ML platform with 4M production inferences per second, we develop a model-training workflow based on data sampling that distills ensembles of models into a single gradient-boosting model favored for high-performance real-time inference, without performance loss. Empirical evaluation shows that the proposed combination of methods consistently improves model accuracy over prior best models across several production applications deployed worldwide.