 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Adaptive Policy to Employ Sharpness-Aware Minimization
Apr 28, 2023
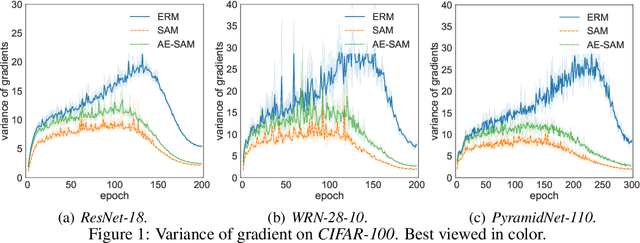
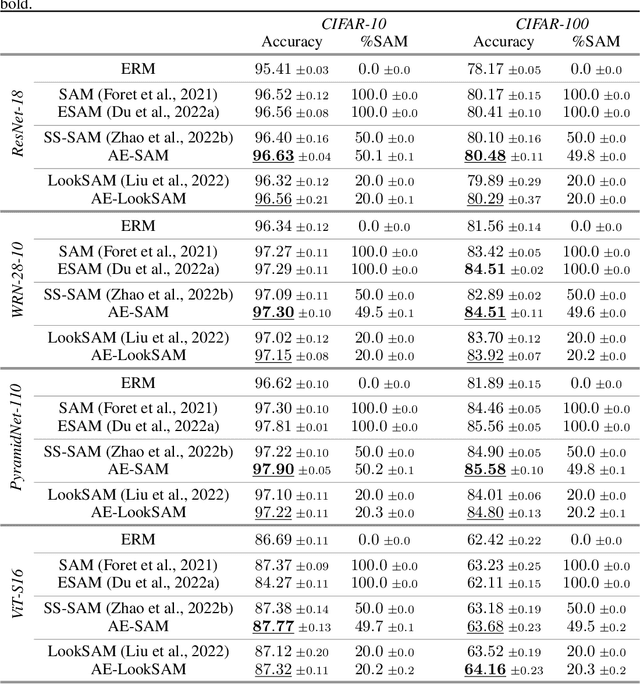
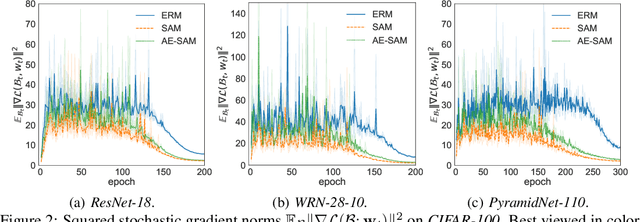
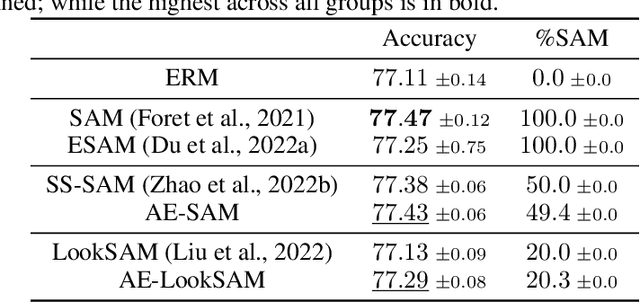
Sharpness-aware minimization (SAM), which searches for flat minima by min-max optimization, has been shown to be useful in improving model generalization. However, since each SAM update requires computing two gradients, its computational cost and training time are both doubled compared to standard empirical risk minimization (ERM). Recent state-of-the-arts reduce the fraction of SAM updates and thus accelerate SAM by switching between SAM and ERM updates randomly or periodically. In this paper, we design an adaptive policy to employ SAM based on the loss landscape geometry. Two efficient algorithms, AE-SAM and AE-LookSAM, are proposed. We theoretically show that AE-SAM has the same convergence rate as SAM. Experimental results on various datasets and architectures demonstrate the efficiency and effectiveness of the adaptive policy.
Pushing the Boundaries of Tractable Multiperspective Reasoning: A Deduction Calculus for Standpoint EL+
Apr 27, 2023
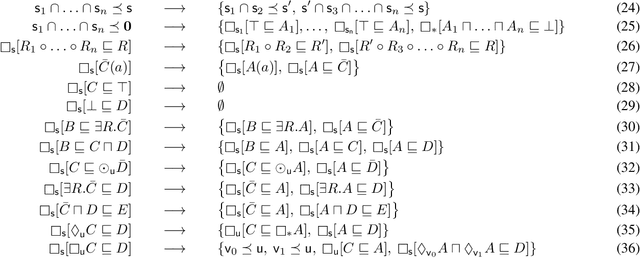

Standpoint EL is a multi-modal extension of the popular description logic EL that allows for the integrated representation of domain knowledge relative to diverse standpoints or perspectives. Advantageously, its satisfiability problem has recently been shown to be in PTime, making it a promising framework for large-scale knowledge integration. In this paper, we show that we can further push the expressivity of this formalism, arriving at an extended logic, called Standpoint EL+, which allows for axiom negation, role chain axioms, self-loops, and other features, while maintaining tractability. This is achieved by designing a satisfiability-checking deduction calculus, which at the same time addresses the need for practical algorithms. We demonstrate the feasibility of our calculus by presenting a prototypical Datalog implementation of its deduction rules.
Augmenting Passage Representations with Query Generation for Enhanced Cross-Lingual Dense Retrieval
May 06, 2023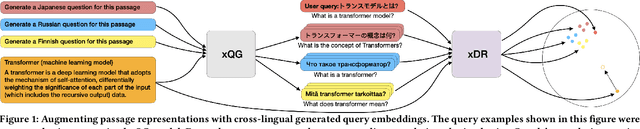
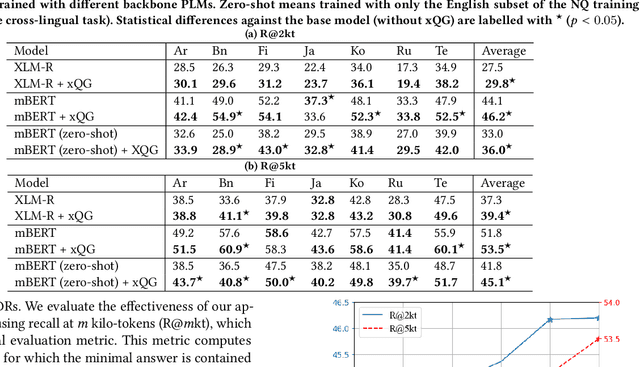
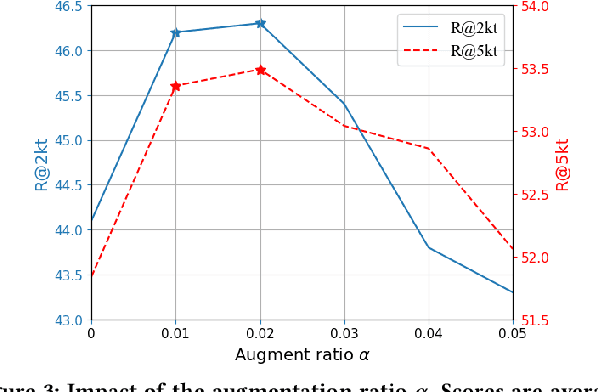
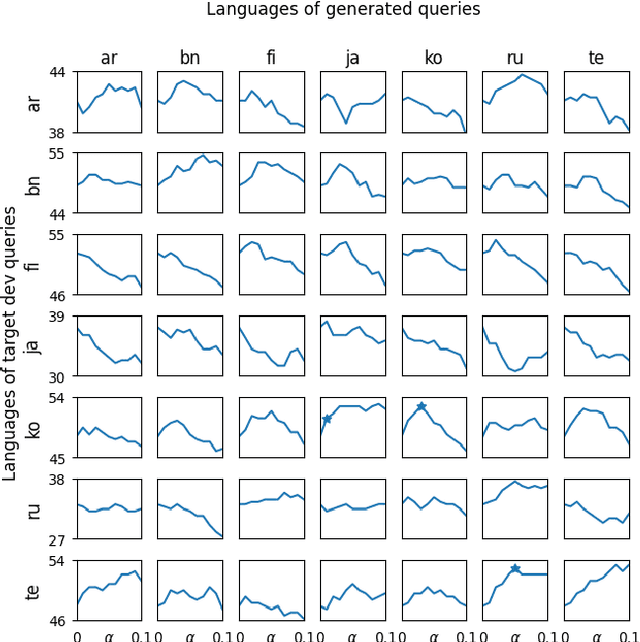
Effective cross-lingual dense retrieval methods that rely on multilingual pre-trained language models (PLMs) need to be trained to encompass both the relevance matching task and the cross-language alignment task. However, cross-lingual data for training is often scarcely available. In this paper, rather than using more cross-lingual data for training, we propose to use cross-lingual query generation to augment passage representations with queries in languages other than the original passage language. These augmented representations are used at inference time so that the representation can encode more information across the different target languages. Training of a cross-lingual query generator does not require additional training data to that used for the dense retriever. The query generator training is also effective because the pre-training task for the generator (T5 text-to-text training) is very similar to the fine-tuning task (generation of a query). The use of the generator does not increase query latency at inference and can be combined with any cross-lingual dense retrieval method. Results from experiments on a benchmark cross-lingual information retrieval dataset show that our approach can improve the effectiveness of existing cross-lingual dense retrieval methods. Implementation of our methods, along with all generated query files are made publicly available at https://github.com/ielab/xQG4xDR.
Symbolic Regression on FPGAs for Fast Machine Learning Inference
May 06, 2023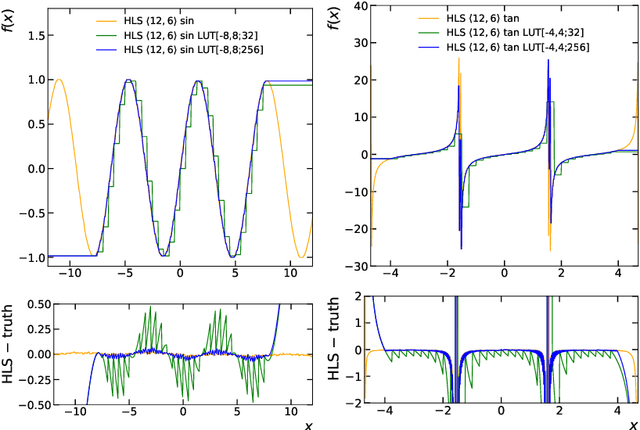


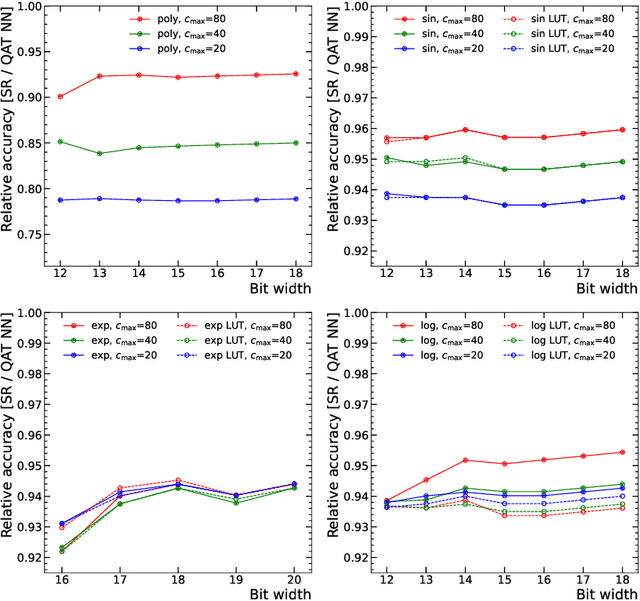
The high-energy physics community is investigating the feasibility of deploying machine-learning-based solutions on Field-Programmable Gate Arrays (FPGAs) to improve physics sensitivity while meeting data processing latency limitations. In this contribution, we introduce a novel end-to-end procedure that utilizes a machine learning technique called symbolic regression (SR). It searches equation space to discover algebraic relations approximating a dataset. We use PySR (software for uncovering these expressions based on evolutionary algorithm) and extend the functionality of hls4ml (a package for machine learning inference in FPGAs) to support PySR-generated expressions for resource-constrained production environments. Deep learning models often optimise the top metric by pinning the network size because vast hyperparameter space prevents extensive neural architecture search. Conversely, SR selects a set of models on the Pareto front, which allows for optimising the performance-resource tradeoff directly. By embedding symbolic forms, our implementation can dramatically reduce the computational resources needed to perform critical tasks. We validate our procedure on a physics benchmark: multiclass classification of jets produced in simulated proton-proton collisions at the CERN Large Hadron Collider, and show that we approximate a 3-layer neural network with an inference model that has as low as 5 ns execution time (a reduction by a factor of 13) and over 90% approximation accuracy.
Variational Nonlinear Kalman Filtering with Unknown Process Noise Covariance
May 06, 2023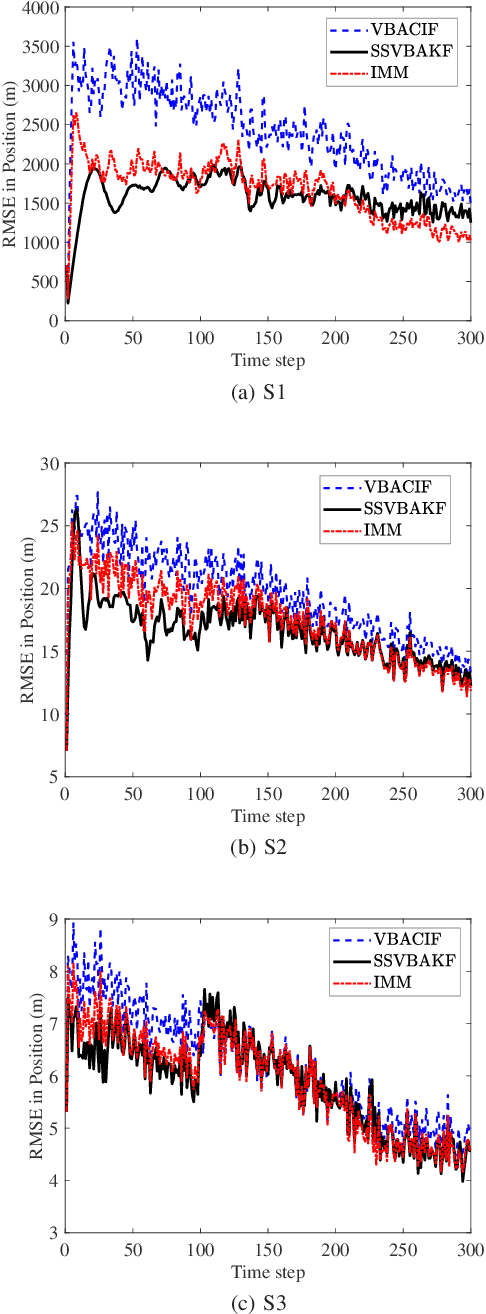
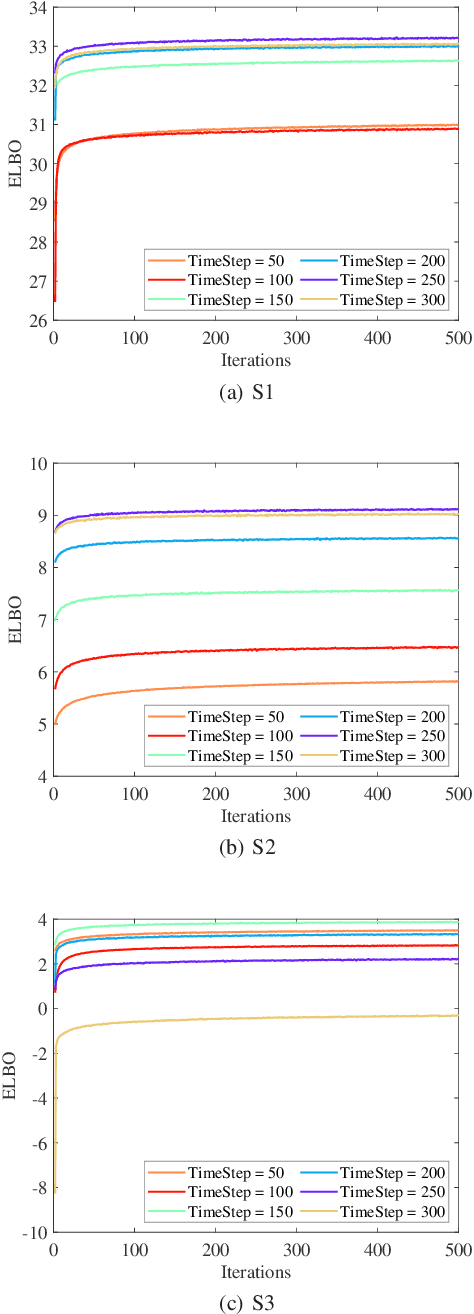
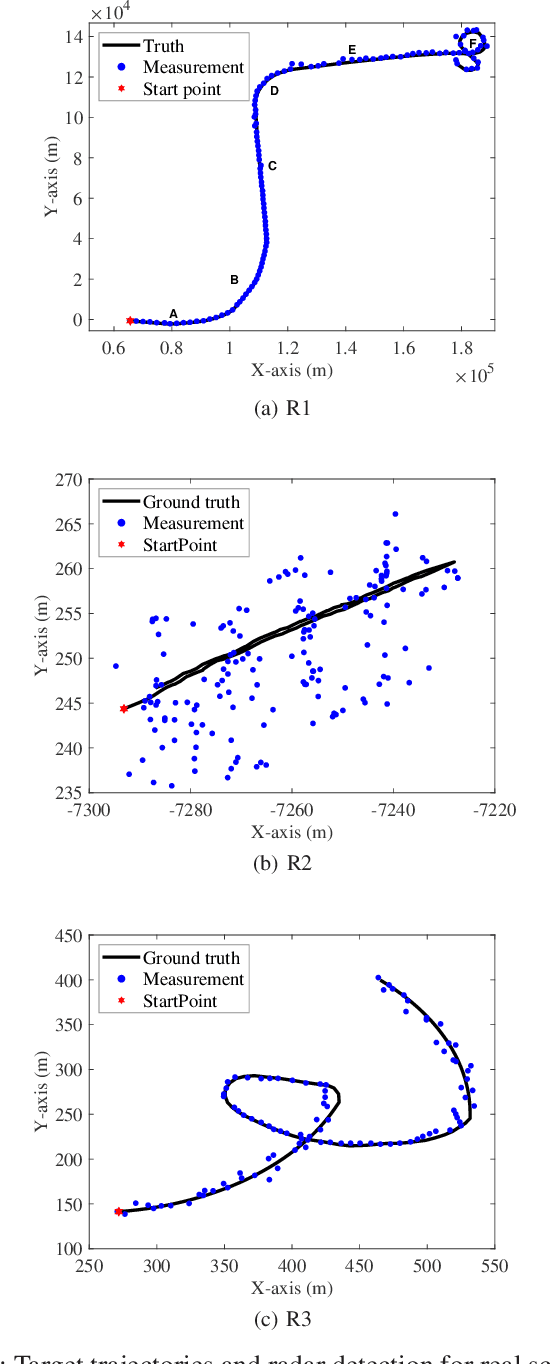
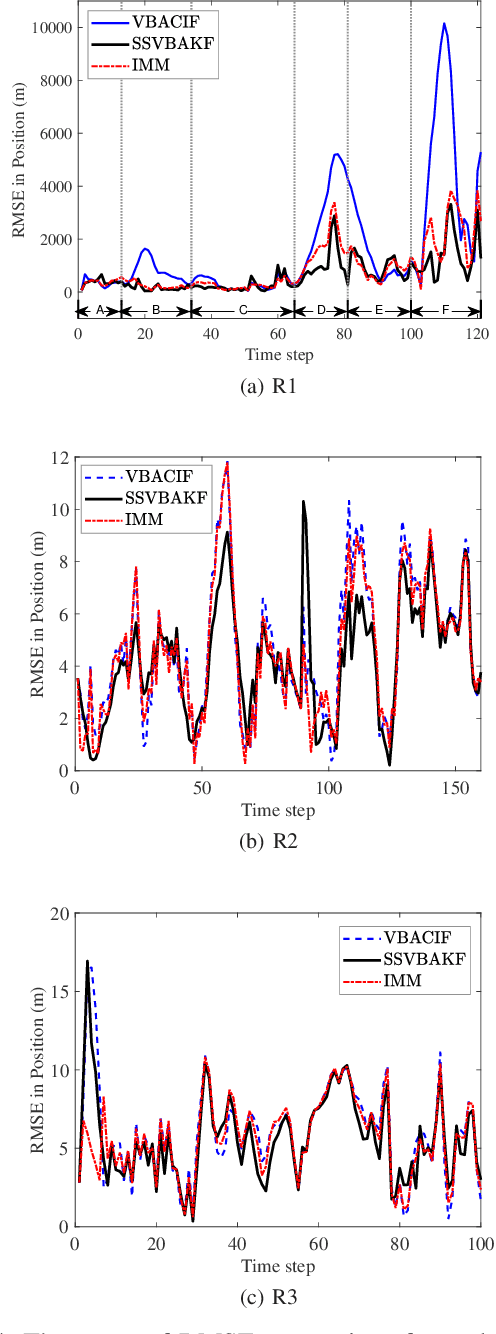
Motivated by the maneuvering target tracking with sensors such as radar and sonar, this paper considers the joint and recursive estimation of the dynamic state and the time-varying process noise covariance in nonlinear state space models. Due to the nonlinearity of the models and the non-conjugate prior, the state estimation problem is generally intractable as it involves integrals of general nonlinear functions and unknown process noise covariance, resulting in the posterior probability distribution functions lacking closed-form solutions. This paper presents a recursive solution for joint nonlinear state estimation and model parameters identification based on the approximate Bayesian inference principle. The stochastic search variational inference is adopted to offer a flexible, accurate, and effective approximation of the posterior distributions. We make two contributions compared to existing variational inference-based noise adaptive filtering methods. First, we introduce an auxiliary latent variable to decouple the latent variables of dynamic state and process noise covariance, thereby improving the flexibility of the posterior inference. Second, we split the variational lower bound optimization into conjugate and non-conjugate parts, whereas the conjugate terms are directly optimized that admit a closed-form solution and the non-conjugate terms are optimized by natural gradients, achieving the trade-off between inference speed and accuracy. The performance of the proposed method is verified on radar target tracking applications by both simulated and real-world data.
Maintaining Stability and Plasticity for Predictive Churn Reduction
May 06, 2023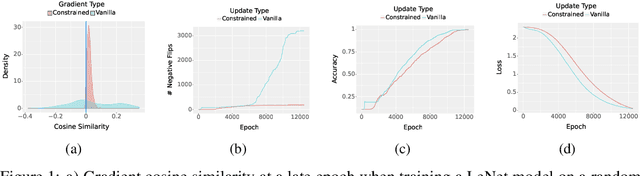
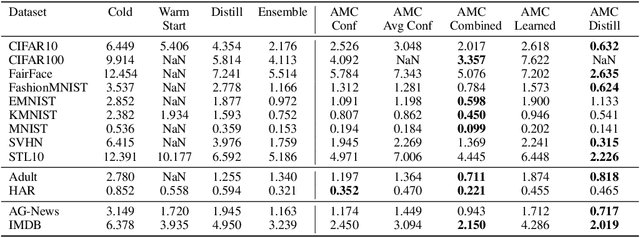
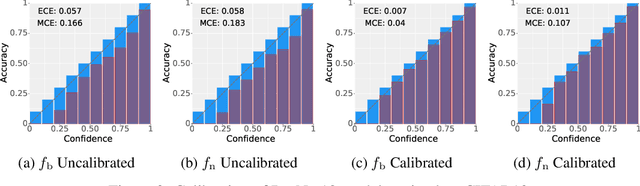

Deployed machine learning models should be updated to take advantage of a larger sample size to improve performance, as more data is gathered over time. Unfortunately, even when model updates improve aggregate metrics such as accuracy, they can lead to errors on samples that were correctly predicted by the previous model causing per-sample regression in performance known as predictive churn. Such prediction flips erode user trust thereby reducing the effectiveness of the human-AI team as a whole. We propose a solution called Accumulated Model Combination (AMC) based keeping the previous and current model version, and generating a meta-output using the prediction of the two models. AMC is a general technique and we propose several instances of it, each having their own advantages depending on the model and data properties. AMC requires minimal additional computation and changes to training procedures. We motivate the need for AMC by showing the difficulty of making a single model consistent with its own predictions throughout training thereby revealing an implicit stability-plasticity tradeoff when training a single model. We demonstrate the effectiveness of AMC on a variety of modalities including computer vision, text, and tabular datasets comparing against state-of-the-art churn reduction methods, and showing superior churn reduction ability compared to all existing methods while being more efficient than ensembles.
Matrix Profile XXVII: A Novel Distance Measure for Comparing Long Time Series
Dec 09, 2022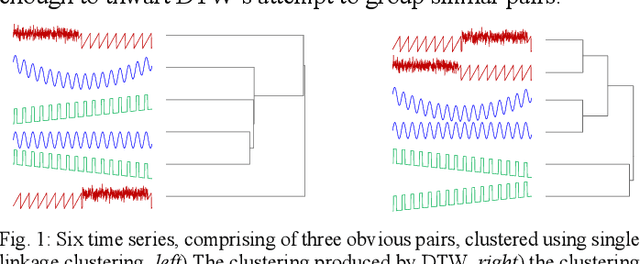
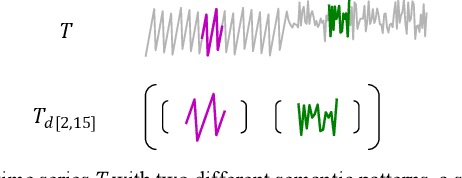
The most useful data mining primitives are distance measures. With an effective distance measure, it is possible to perform classification, clustering, anomaly detection, segmentation, etc. For single-event time series Euclidean Distance and Dynamic Time Warping distance are known to be extremely effective. However, for time series containing cyclical behaviors, the semantic meaningfulness of such comparisons is less clear. For example, on two separate days the telemetry from an athlete workout routine might be very similar. The second day may change the order in of performing push-ups and squats, adding repetitions of pull-ups, or completely omitting dumbbell curls. Any of these minor changes would defeat existing time series distance measures. Some bag-of-features methods have been proposed to address this problem, but we argue that in many cases, similarity is intimately tied to the shapes of subsequences within these longer time series. In such cases, summative features will lack discrimination ability. In this work we introduce PRCIS, which stands for Pattern Representation Comparison in Series. PRCIS is a distance measure for long time series, which exploits recent progress in our ability to summarize time series with dictionaries. We will demonstrate the utility of our ideas on diverse tasks and datasets.
DeepAqua: Self-Supervised Semantic Segmentation of Wetlands from SAR Images using Knowledge Distillation
May 02, 2023
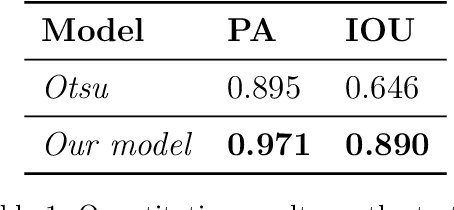

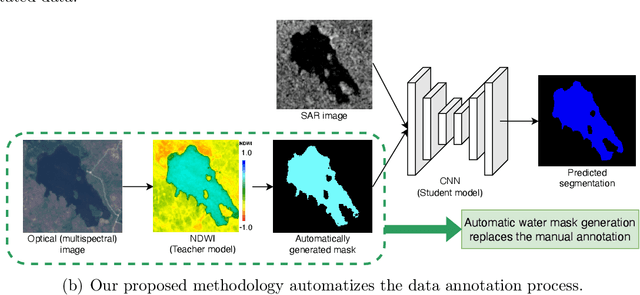
Remote sensing has significantly advanced water detection by applying semantic segmentation techniques to satellite imagery. However, semantic segmentation remains challenging due to the substantial amount of annotated data required. This is particularly problematic in wetland detection, where water extent varies over time and space, necessitating multiple annotations for the same area. In this paper, we present DeepAqua, a self-supervised deep learning model that leverages knowledge distillation to eliminate the need for manual annotations during the training phase. DeepAqua utilizes the Normalized Difference Water Index (NDWI) as a teacher model to train a Convolutional Neural Network (CNN) for segmenting water from Synthetic Aperture Radar (SAR) images. To train the student model, we exploit cases where optical- and radar-based water masks coincide, enabling the detection of both open and vegetated water surfaces. Our model represents a significant advancement in computer vision techniques by effectively training semantic segmentation models without any manually annotated data. This approach offers a practical solution for monitoring wetland water extent changes without needing ground truth data, making it highly adaptable and scalable for wetland conservation efforts.
Machine-Learned Invertible Coarse Graining for Multiscale Molecular Modeling
May 02, 2023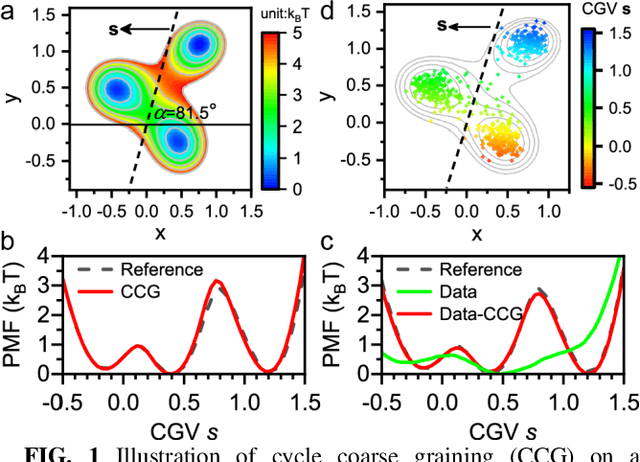
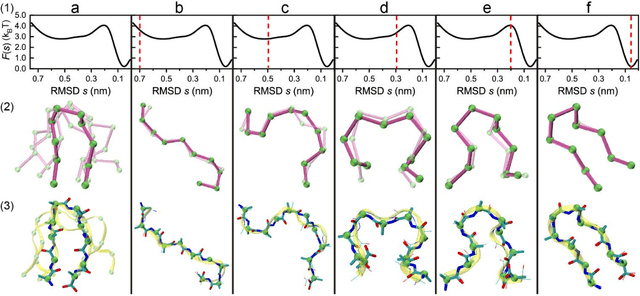
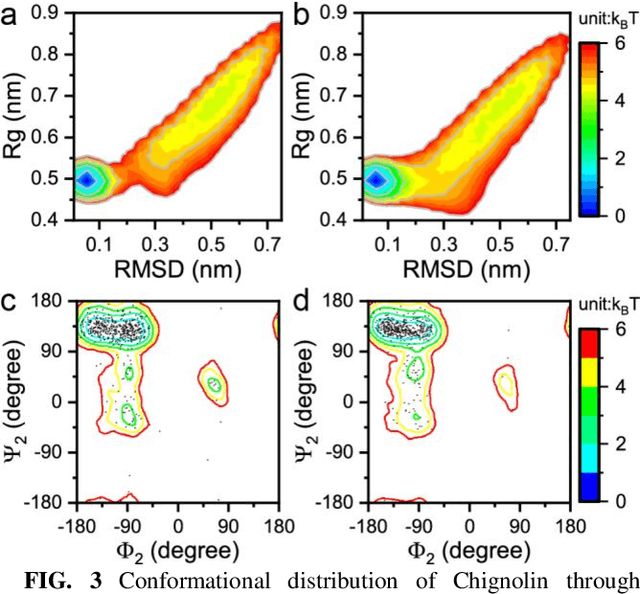
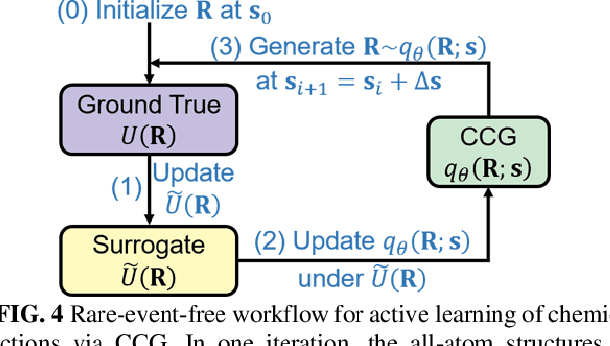
Multiscale molecular modeling is widely applied in scientific research of molecular properties over large time and length scales. Two specific challenges are commonly present in multiscale modeling, provided that information between the coarse and fine representations of molecules needs to be properly exchanged: One is to construct coarse grained (CG) models by passing information from the fine to coarse levels; the other is to restore finer molecular details given CG configurations. Although these two problems are commonly addressed independently, in this work, we present a theory connecting them, and develop a methodology called Cycle Coarse Graining (CCG) to solve both problems in a unified manner. In CCG, reconstruction can be achieved via a tractable optimization process, leading to a general method to retrieve fine details from CG simulations, which in turn, delivers a new solution to the CG problem, yielding an efficient way to calculate free energies in a rare-event-free manner. CCG thus provides a systematic way for multiscale molecular modeling, where the finer details of CG simulations can be efficiently retrieved, and the CG models can be improved consistently.
Self-supervised learning for infant cry analysis
May 02, 2023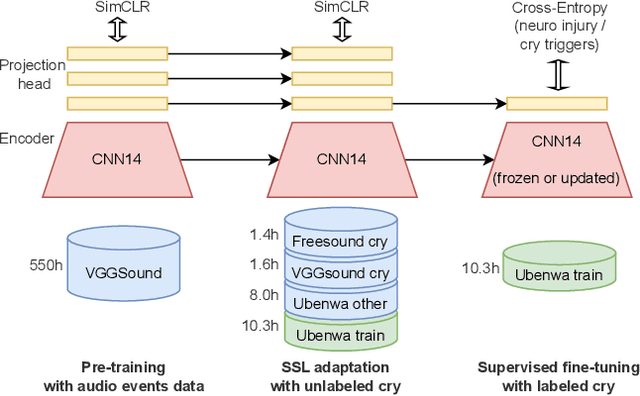
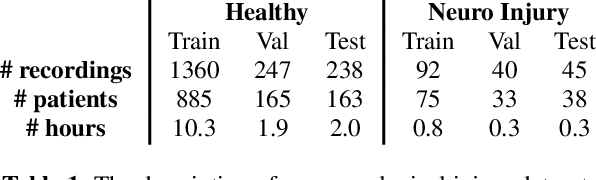

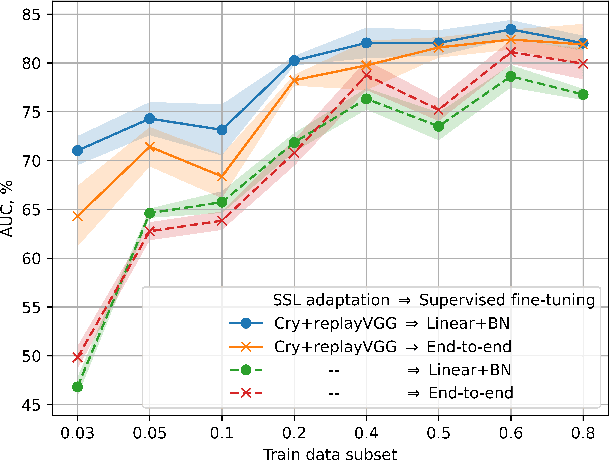
In this paper, we explore self-supervised learning (SSL) for analyzing a first-of-its-kind database of cry recordings containing clinical indications of more than a thousand newborns. Specifically, we target cry-based detection of neurological injury as well as identification of cry triggers such as pain, hunger, and discomfort. Annotating a large database in the medical setting is expensive and time-consuming, typically requiring the collaboration of several experts over years. Leveraging large amounts of unlabeled audio data to learn useful representations can lower the cost of building robust models and, ultimately, clinical solutions. In this work, we experiment with self-supervised pre-training of a convolutional neural network on large audio datasets. We show that pre-training with SSL contrastive loss (SimCLR) performs significantly better than supervised pre-training for both neuro injury and cry triggers. In addition, we demonstrate further performance gains through SSL-based domain adaptation using unlabeled infant cries. We also show that using such SSL-based pre-training for adaptation to cry sounds decreases the need for labeled data of the overall system.