 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploiting Diffusion Prior for Real-World Image Super-Resolution
May 11, 2023
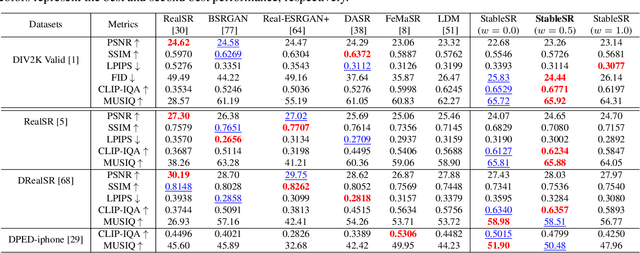
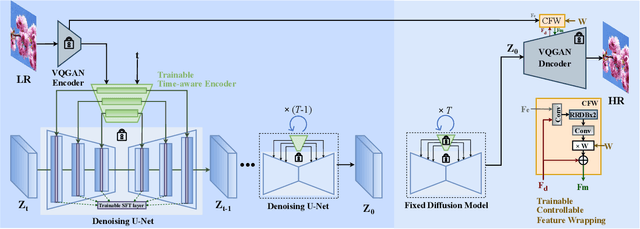
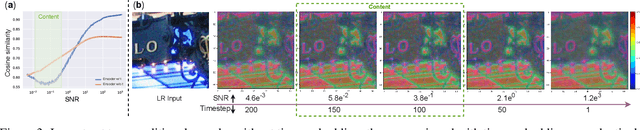

We present a novel approach to leverage prior knowledge encapsulated in pre-trained text-to-image diffusion models for blind super-resolution (SR). Specifically, by employing our time-aware encoder, we can achieve promising restoration results without altering the pre-trained synthesis model, thereby preserving the generative prior and minimizing training cost. To remedy the loss of fidelity caused by the inherent stochasticity of diffusion models, we introduce a controllable feature wrapping module that allows users to balance quality and fidelity by simply adjusting a scalar value during the inference process. Moreover, we develop a progressive aggregation sampling strategy to overcome the fixed-size constraints of pre-trained diffusion models, enabling adaptation to resolutions of any size. A comprehensive evaluation of our method using both synthetic and real-world benchmarks demonstrates its superiority over current state-of-the-art approaches.
Client Recruitment for Federated Learning in ICU Length of Stay Prediction
Apr 28, 2023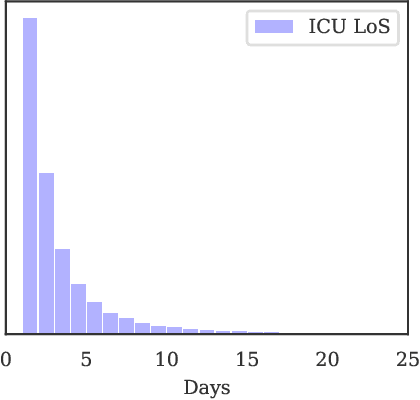
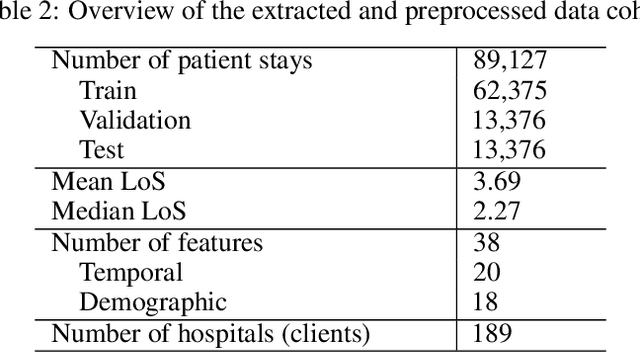
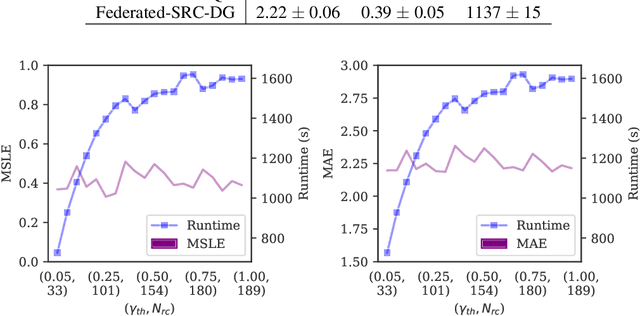

Machine and deep learning methods for medical and healthcare applications have shown significant progress and performance improvement in recent years. These methods require vast amounts of training data which are available in the medical sector, albeit decentralized. Medical institutions generate vast amounts of data for which sharing and centralizing remains a challenge as the result of data and privacy regulations. The federated learning technique is well-suited to tackle these challenges. However, federated learning comes with a new set of open problems related to communication overhead, efficient parameter aggregation, client selection strategies and more. In this work, we address the step prior to the initiation of a federated network for model training, client recruitment. By intelligently recruiting clients, communication overhead and overall cost of training can be reduced without sacrificing predictive performance. Client recruitment aims at pre-excluding potential clients from partaking in the federation based on a set of criteria indicative of their eventual contributions to the federation. In this work, we propose a client recruitment approach using only the output distribution and sample size at the client site. We show how a subset of clients can be recruited without sacrificing model performance whilst, at the same time, significantly improving computation time. By applying the recruitment approach to the training of federated models for accurate patient Length of Stay prediction using data from 189 Intensive Care Units, we show how the models trained in federations made up from recruited clients significantly outperform federated models trained with the standard procedure in terms of predictive power and training time.
Making Changes in Webpages Discoverable: A Change-Text Search Interface for Web Archives
Apr 30, 2023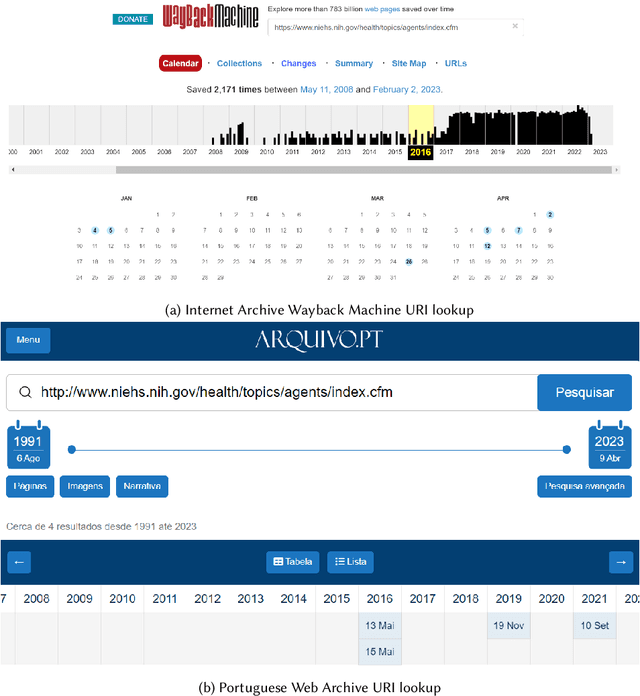

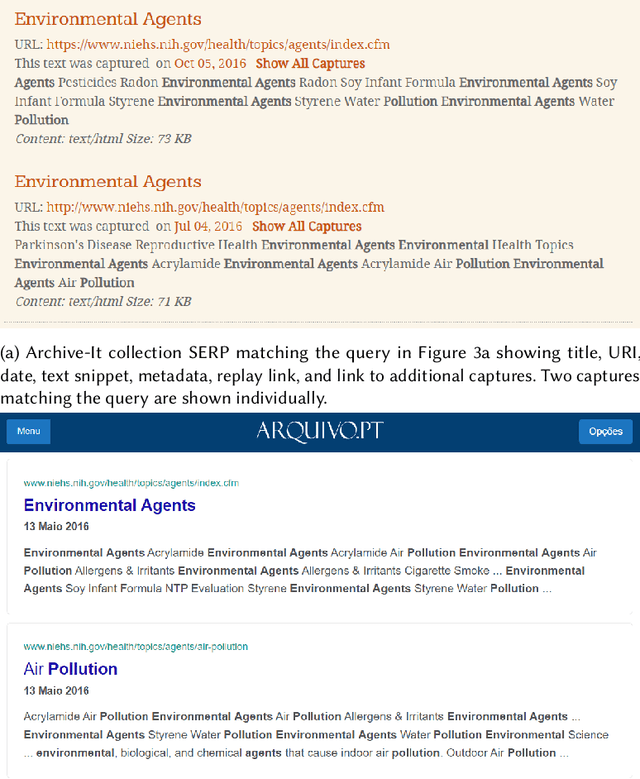

Webpages change over time, and web archives hold copies of historical versions of webpages. Users of web archives, such as journalists, want to find and view changes on webpages over time. However, the current search interfaces for web archives do not support this task. For the web archives that include a full-text search feature, multiple versions of the same webpage that match the search query are shown individually without enumerating changes, or are grouped together in a way that hides changes. We present a change text search engine that allows users to find changes in webpages. We describe the implementation of the search engine backend and frontend, including a tool that allows users to view the changes between two webpage versions in context as an animation. We evaluate the search engine with U.S. federal environmental webpages that changed between 2016 and 2020. The change text search results page can clearly show when terms and phrases were added or removed from webpages. The inverted index can also be queried to identify salient and frequently deleted terms in a corpus.
Propagate And Calibrate: Real-time Passive Non-line-of-sight Tracking
Mar 27, 2023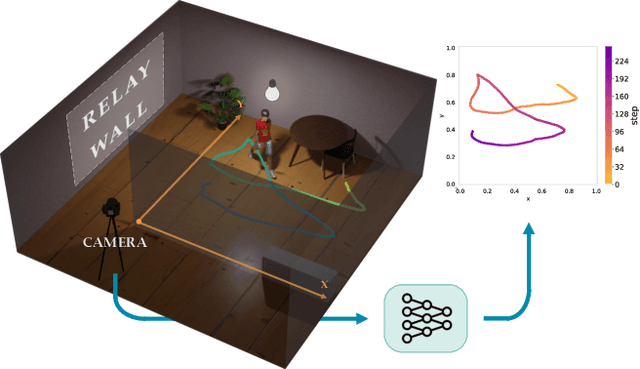
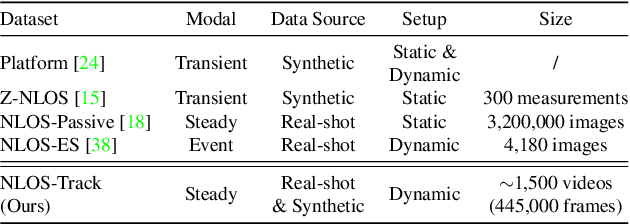
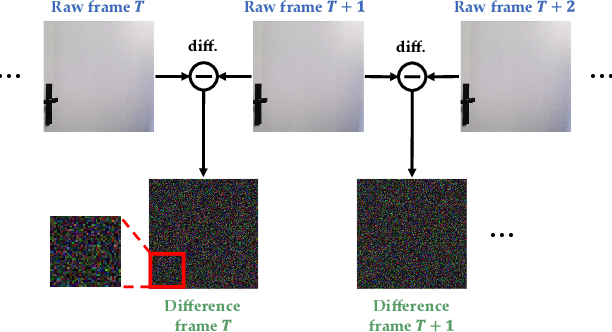
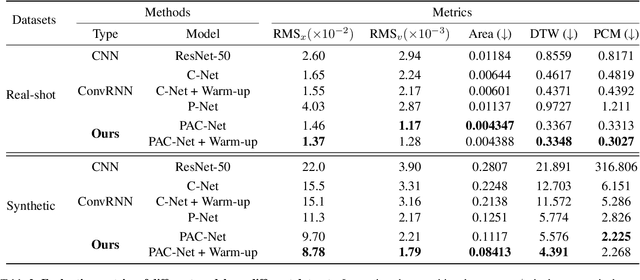
Non-line-of-sight (NLOS) tracking has drawn increasing attention in recent years, due to its ability to detect object motion out of sight. Most previous works on NLOS tracking rely on active illumination, e.g., laser, and suffer from high cost and elaborate experimental conditions. Besides, these techniques are still far from practical application due to oversimplified settings. In contrast, we propose a purely passive method to track a person walking in an invisible room by only observing a relay wall, which is more in line with real application scenarios, e.g., security. To excavate imperceptible changes in videos of the relay wall, we introduce difference frames as an essential carrier of temporal-local motion messages. In addition, we propose PAC-Net, which consists of alternating propagation and calibration, making it capable of leveraging both dynamic and static messages on a frame-level granularity. To evaluate the proposed method, we build and publish the first dynamic passive NLOS tracking dataset, NLOS-Track, which fills the vacuum of realistic NLOS datasets. NLOS-Track contains thousands of NLOS video clips and corresponding trajectories. Both real-shot and synthetic data are included. Our codes and dataset are available at https://againstentropy.github.io/NLOS-Track/.
A Secure Dual-Function Radar Communication System via Time-Modulated Arrays
Feb 05, 2023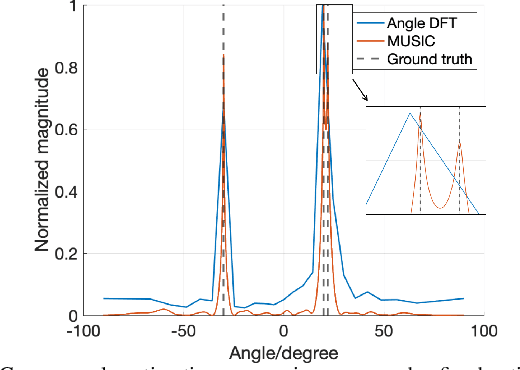
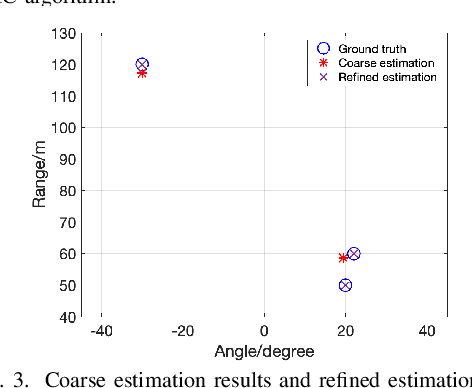
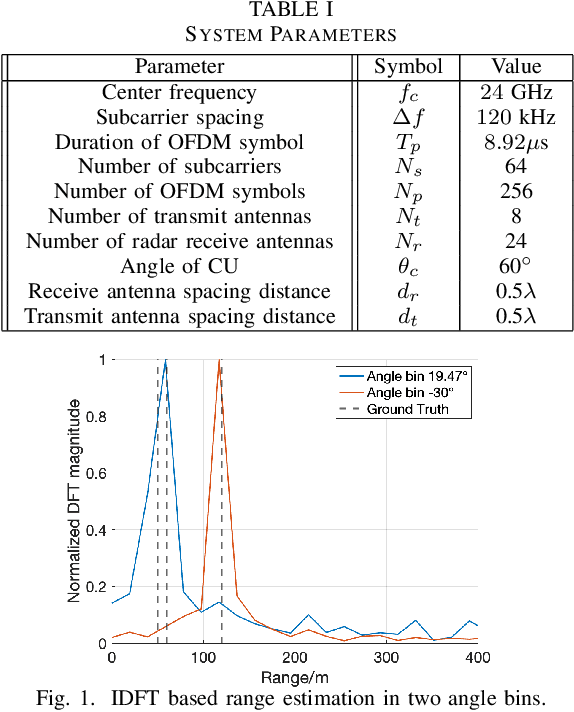
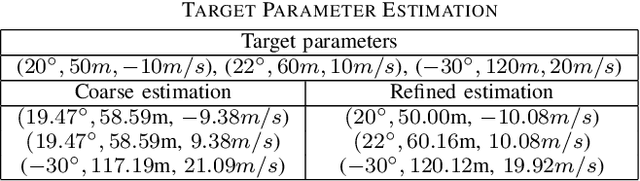
Dual-function radar-communication (DFRC) systems offer high spectral, hardware and power efficiency, as such are prime candidates for 6G wireless systems. DFRC systems use the same waveform for simultaneously probing the surroundings and communicating with other equipment. By exposing the communication information to potential targets, DFRC systems are vulnerable to eavesdropping. In this work, we propose to mitigate the problem by leveraging directional modulation (DM) enabled by a time-modulated array (TMA) that transmits OFDM waveforms. DM can scramble the signal in all directions except the directions of the legitimate user. However, the signal reflected by the targets is also scrambled, thus complicating the extraction of target parameters. We propose a novel, low-complexity target estimation method that estimates the target parameters based on the scrambled received symbols. We also propose a novel method to refine the obtained target estimates at the cost of increased complexity. With the proposed refinement algorithm, the proposed DFRC system can securely communicate with users while having high-precision sensing functionality.
Modelling Concurrency Bugs Using Machine Learning
May 08, 2023Artificial Intelligence has gained a lot of traction in the recent years, with machine learning notably starting to see more applications across a varied range of fields. One specific machine learning application that is of interest to us is that of software safety and security, especially in the context of parallel programs. The issue of being able to detect concurrency bugs automatically has intrigued programmers for a long time, as the added layer of complexity makes concurrent programs more prone to failure. The development of such automatic detection tools provides considerable benefits to programmers in terms of saving time while debugging, as well as reducing the number of unexpected bugs. We believe machine learning may help achieve this goal by providing additional advantages over current approaches, in terms of both overall tool accuracy as well as programming language flexibility. However, due to the presence of numerous challenges specific to the machine learning approach (correctly labelling a sufficiently large dataset, finding the best model types/architectures and so forth), we have to approach each issue of developing such a tool separately. Therefore, the focus of this project is on comparing both common and recent machine learning approaches. We abstract away the complexity of procuring a labelled dataset of concurrent programs under the form of a synthetic dataset that we define and generate with the scope of simulating real-life (concurrent) programs. We formulate hypotheses about fundamental limits of various machine learning model types which we then validate by running extensive tests on our synthetic dataset. We hope that our findings provide more insight in the advantages and disadvantages of various model types when modelling programs using machine learning, as well as any other related field (e.g. NLP).
On the Susceptibility and Robustness of Time Series Models through Adversarial Attack and Defense
Jan 09, 2023
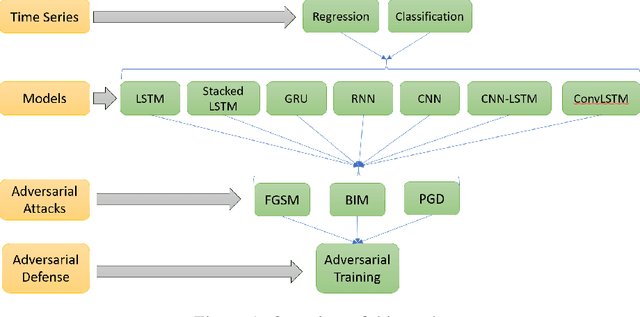
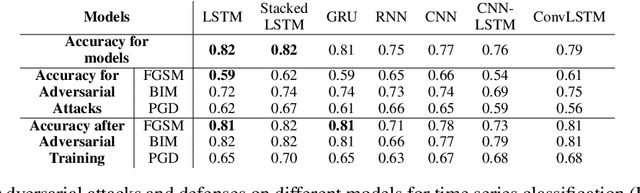
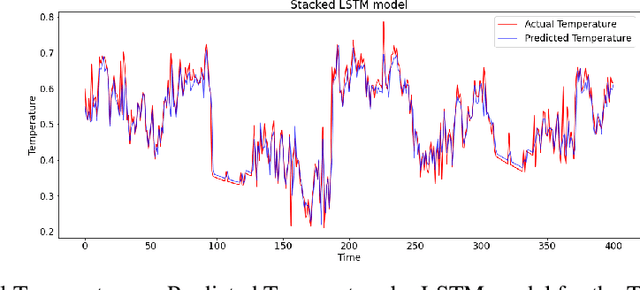
Under adversarial attacks, time series regression and classification are vulnerable. Adversarial defense, on the other hand, can make the models more resilient. It is important to evaluate how vulnerable different time series models are to attacks and how well they recover using defense. The sensitivity to various attacks and the robustness using the defense of several time series models are investigated in this study. Experiments are run on seven-time series models with three adversarial attacks and one adversarial defense. According to the findings, all models, particularly GRU and RNN, appear to be vulnerable. LSTM and GRU also have better defense recovery. FGSM exceeds the competitors in terms of attacks. PGD attacks are more difficult to recover from than other sorts of attacks.
An Algorithm For Adversary Aware Decentralized Networked MARL
May 09, 2023Decentralized multi-agent reinforcement learning (MARL) algorithms have become popular in the literature since it allows heterogeneous agents to have their own reward functions as opposed to canonical multi-agent Markov Decision Process (MDP) settings which assume common reward functions over all agents. In this work, we follow the existing work on collaborative MARL where agents in a connected time varying network can exchange information among each other in order to reach a consensus. We introduce vulnerabilities in the consensus updates of existing MARL algorithms where agents can deviate from their usual consensus update, who we term as adversarial agents. We then proceed to provide an algorithm that allows non-adversarial agents to reach a consensus in the presence of adversaries under a constrained setting.
Effective Medical Code Prediction via Label Internal Alignment
May 09, 2023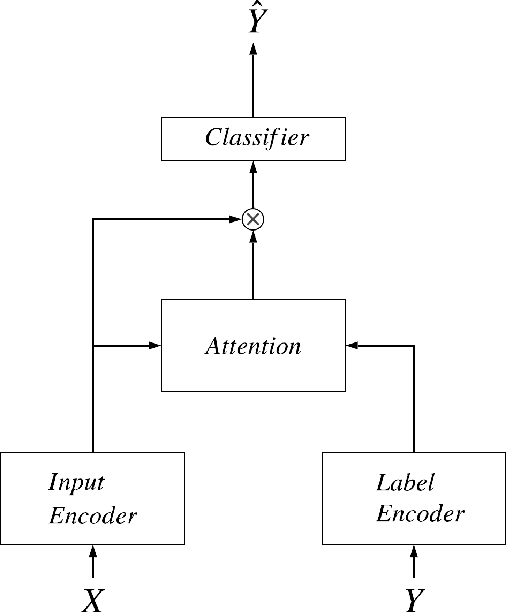
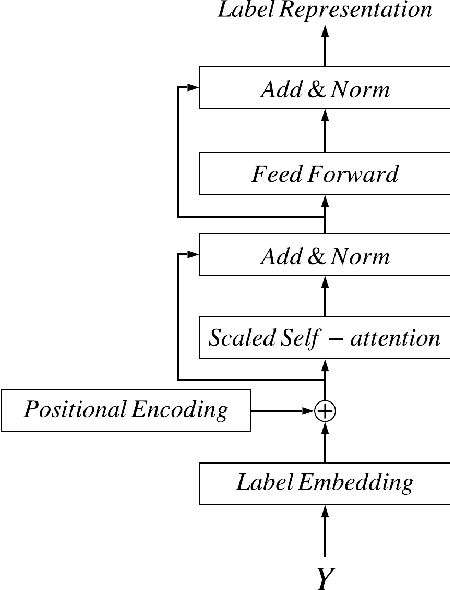
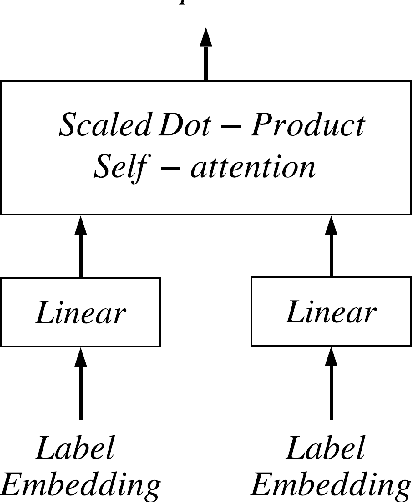
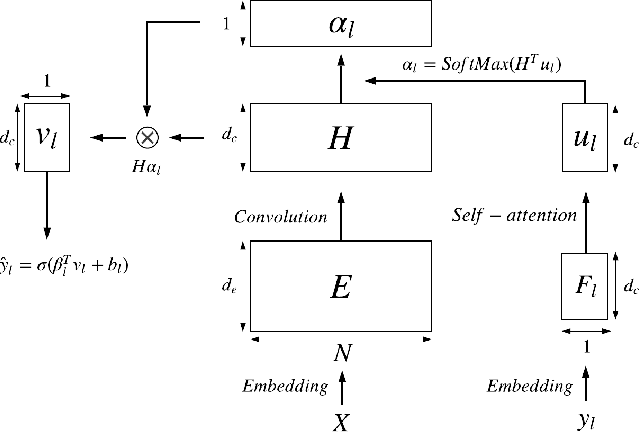
The clinical notes are usually typed into the system by physicians. They are typically required to be marked by standard medical codes, and each code represents a diagnosis or medical treatment procedure. Annotating these notes is time consuming and prone to error. In this paper, we proposed a multi-view attention based Neural network to predict medical codes from clinical texts. Our method incorporates three aspects of information, the semantic context of the clinical text, the relationship among the label (medical codes) space, and the alignment between each pair of a clinical text and medical code. Our method is verified to be effective on the open source dataset. The experimental result shows that our method achieves better performance against the prior state-of-art on multiple metrics.
Short-time SSVEP data extension by a novel generative adversarial networks based framework
Jan 18, 2023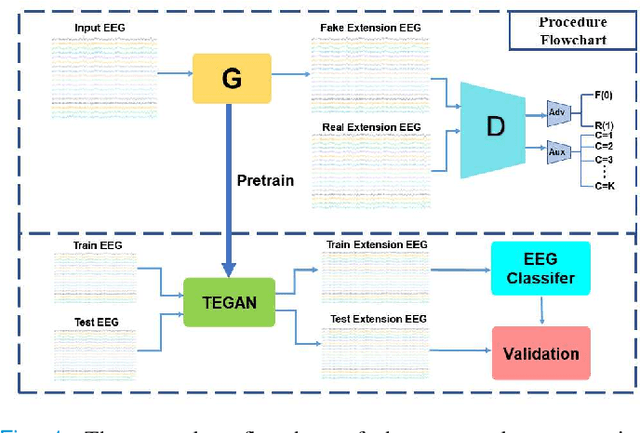
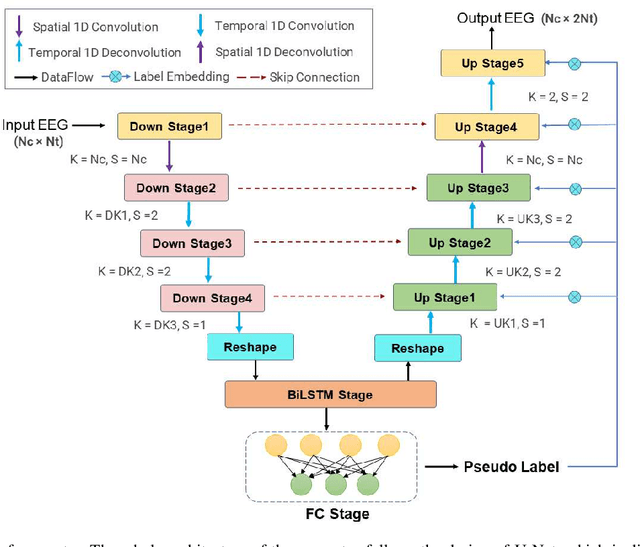

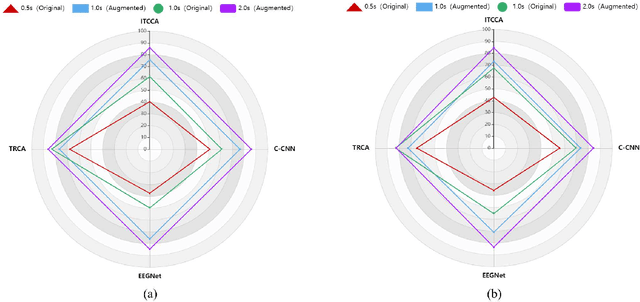
Steady-state visual evoked potentials (SSVEPs) based brain-computer interface (BCI) has received considerable attention due to its high transfer rate and available quantity of targets. However, the performance of frequency identification methods heavily hinges on the amount of user calibration data and data length, which hinders the deployment in real-world applications. Recently, generative adversarial networks (GANs)-based data generation methods have been widely adopted to create supplementary synthetic electroencephalography (EEG) data, holds promise to address these issues. In this paper, we proposed a GAN-based end-to-end signal transformation network for data length window extension, termed as TEGAN. TEGAN transforms short-time SSVEP signals into long-time artificial SSVEP signals. By incorporating a novel U-Net generator architecture and auxiliary classifier into the network design, the TEGAN could produce conditioned features in the synthetic data. Additionally, to regularize the training process of GAN, we introduced a two-stage training strategy and the LeCam-divergence regularization term during the network implementation. The proposed TEGAN was evaluated on two public SSVEP datasets. With the assistance of TEGAN, the performance of traditional frequency recognition methods and deep learning-based methods have been significantly improved under limited calibration data. This study substantiates the feasibility of the proposed method to extend the data length for short-time SSVEP signals to develop a high-performance BCI system. The proposed GAN-based methods have the great potential of shortening the calibration time for various real-world BCI-based applications, while the novelty of our augmentation strategies shed some value light on understanding the subject-invariant properties of SSVEPs.