 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SPARSEFIT: Few-shot Prompting with Sparse Fine-tuning for Jointly Generating Predictions and Natural Language Explanations
May 23, 2023
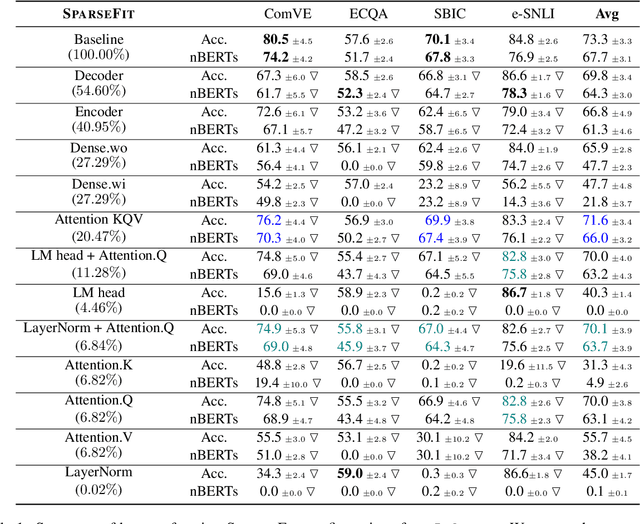
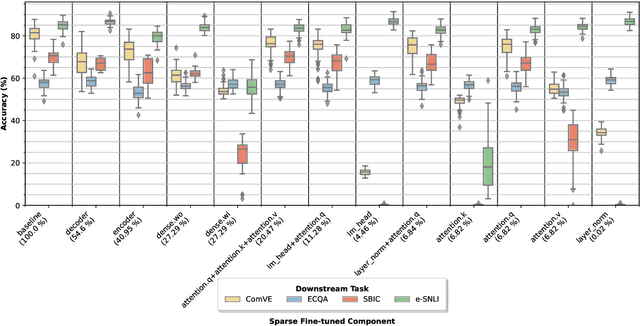
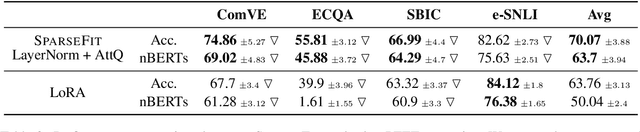
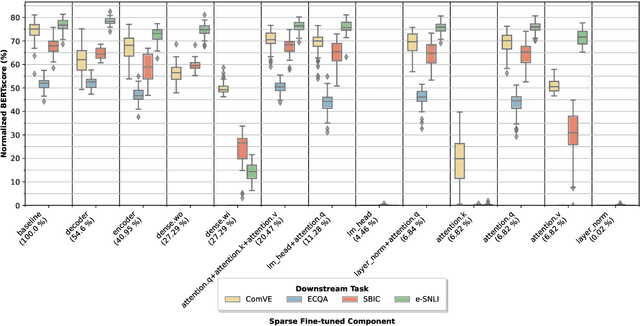
Explaining the decisions of neural models is crucial for ensuring their trustworthiness at deployment time. Using Natural Language Explanations (NLEs) to justify a model's predictions has recently gained increasing interest. However, this approach usually demands large datasets of human-written NLEs for the ground-truth answers, which are expensive and potentially infeasible for some applications. For models to generate high-quality NLEs when only a few NLEs are available, the fine-tuning of Pre-trained Language Models (PLMs) in conjunction with prompt-based learning recently emerged. However, PLMs typically have billions of parameters, making fine-tuning expensive. We propose SparseFit, a sparse few-shot fine-tuning strategy that leverages discrete prompts to jointly generate predictions and NLEs. We experiment with SparseFit on the T5 model and four datasets and compare it against state-of-the-art parameter-efficient fine-tuning techniques. We perform automatic and human evaluations to assess the quality of the model-generated NLEs, finding that fine-tuning only 6.8% of the model parameters leads to competitive results for both the task performance and the quality of the NLEs.
Self-Supervised Gaussian Regularization of Deep Classifiers for Mahalanobis-Distance-Based Uncertainty Estimation
May 23, 2023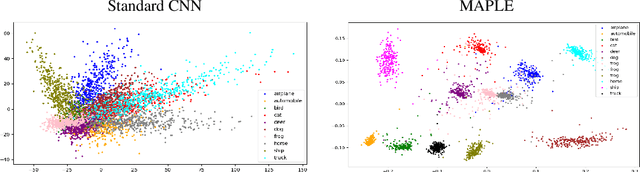
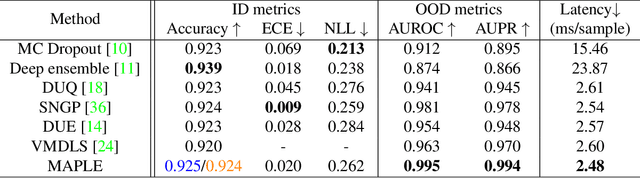
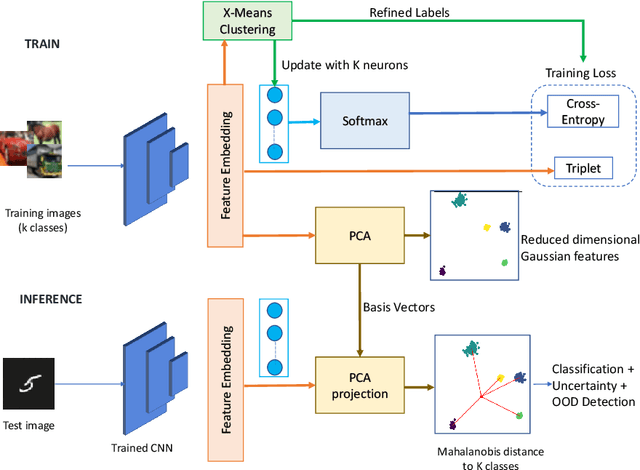
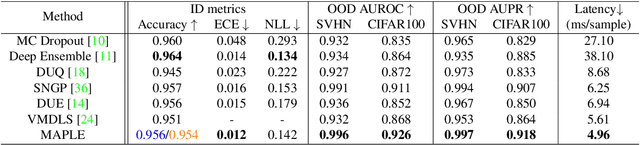
Recent works show that the data distribution in a network's latent space is useful for estimating classification uncertainty and detecting Out-of-distribution (OOD) samples. To obtain a well-regularized latent space that is conducive for uncertainty estimation, existing methods bring in significant changes to model architectures and training procedures. In this paper, we present a lightweight, fast, and high-performance regularization method for Mahalanobis distance-based uncertainty prediction, and that requires minimal changes to the network's architecture. To derive Gaussian latent representation favourable for Mahalanobis Distance calculation, we introduce a self-supervised representation learning method that separates in-class representations into multiple Gaussians. Classes with non-Gaussian representations are automatically identified and dynamically clustered into multiple new classes that are approximately Gaussian. Evaluation on standard OOD benchmarks shows that our method achieves state-of-the-art results on OOD detection with minimal inference time, and is very competitive on predictive probability calibration. Finally, we show the applicability of our method to a real-life computer vision use case on microorganism classification.
Real-Time Digital Twins: Vision and Research Directions for 6G and Beyond
Jan 26, 2023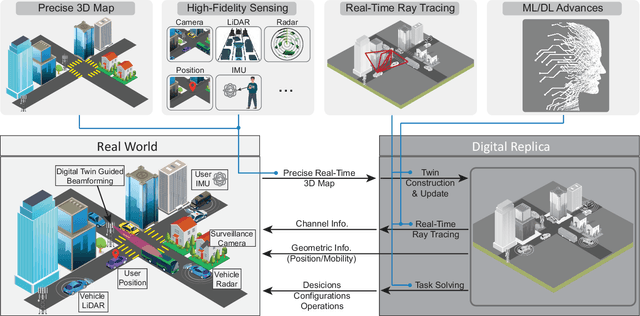
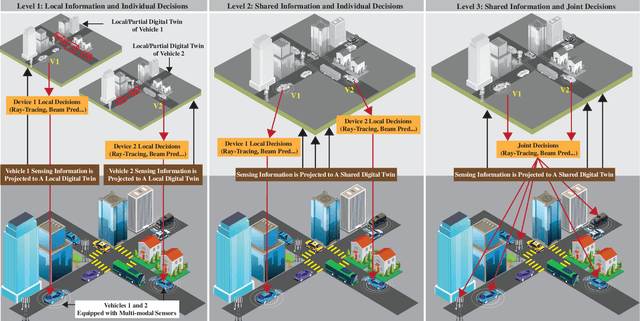
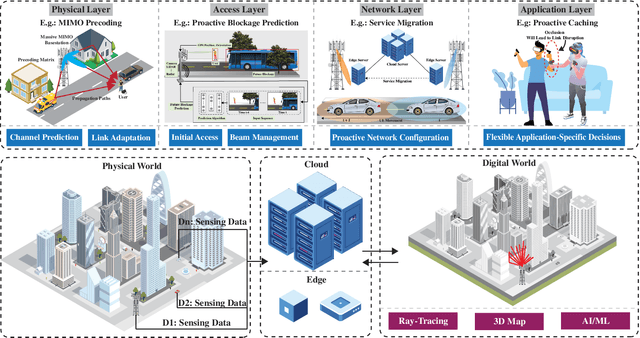
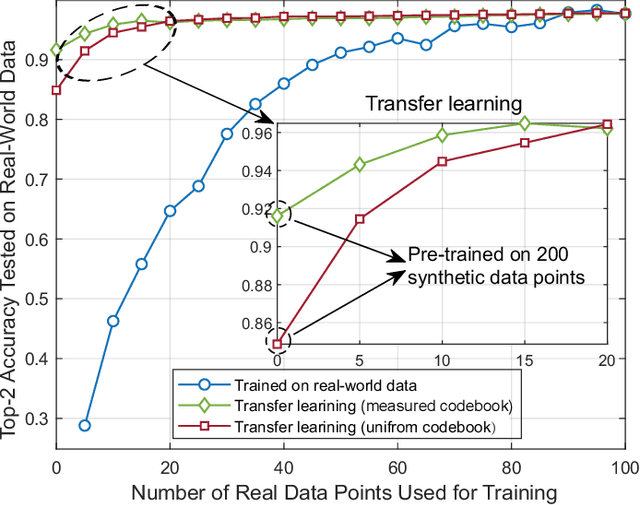
This article presents a vision where \textit{real-time} digital twins of the physical wireless environments are continuously updated using multi-modal sensing data from the distributed infrastructure and user devices, and are used to make communication and sensing decisions. This vision is mainly enabled by the advances in precise 3D maps, multi-modal sensing, ray-tracing computations, and machine/deep learning. This article details this vision, explains the different approaches for constructing and utilizing these real-time digital twins, discusses the applications and open problems, and presents a research platform that can be used to investigate various digital twin research directions.
Explicitly Solvable Continuous-time Inference for Partially Observed Markov Processes
Jan 02, 2023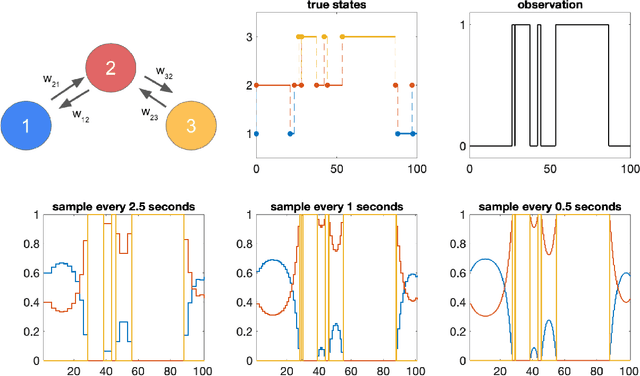

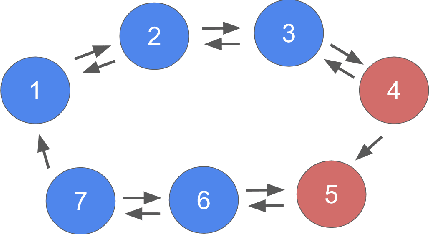
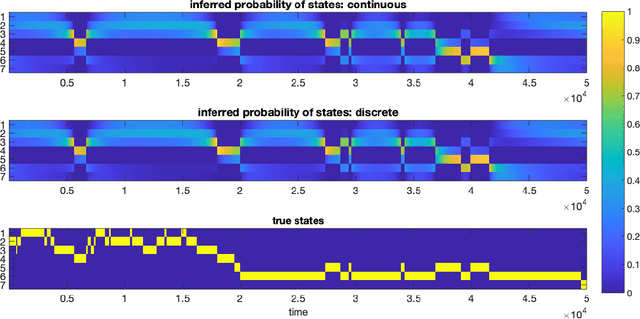
Many natural and engineered systems can be modeled as discrete state Markov processes. Often, only a subset of states are directly observable. Inferring the conditional probability that a system occupies a particular hidden state, given the partial observation, is a problem with broad application. In this paper, we introduce a continuous-time formulation of the sum-product algorithm, which is a well-known discrete-time method for finding the hidden states' conditional probabilities, given a set of finite, discrete-time observations. From our new formulation, we can explicitly solve for the conditional probability of occupying any state, given the transition rates and observations within a finite time window. We apply our algorithm to a realistic model of the cystic fibrosis transmembrane conductance regulator (CFTR) protein for exact inference of the conditional occupancy probability, given a finite time series of partial observations.
TR3D: Towards Real-Time Indoor 3D Object Detection
Feb 08, 2023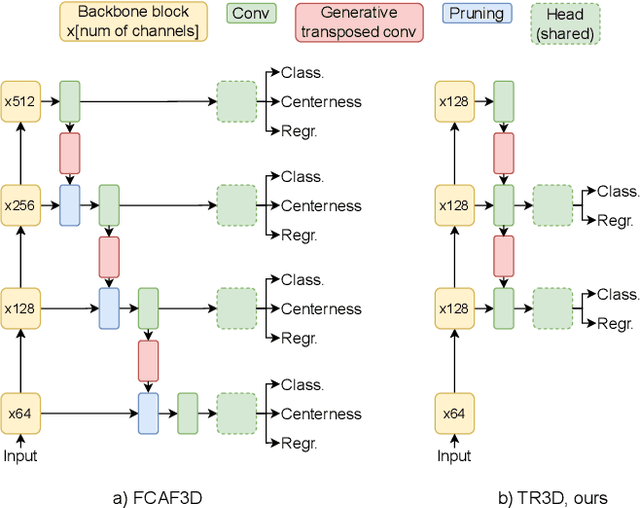
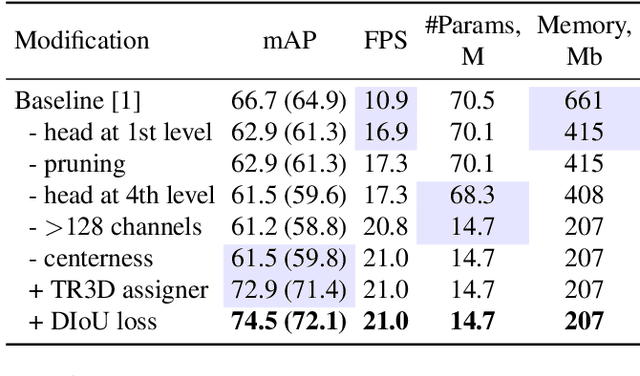

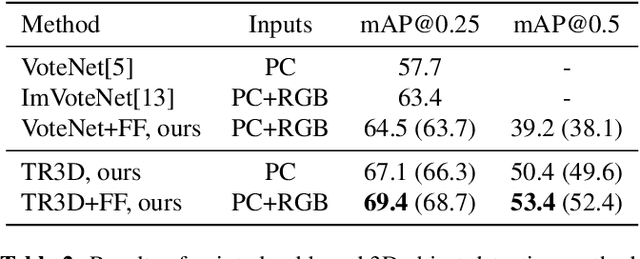
Recently, sparse 3D convolutions have changed 3D object detection. Performing on par with the voting-based approaches, 3D CNNs are memory-efficient and scale to large scenes better. However, there is still room for improvement. With a conscious, practice-oriented approach to problem-solving, we analyze the performance of such methods and localize the weaknesses. Applying modifications that resolve the found issues one by one, we end up with TR3D: a fast fully-convolutional 3D object detection model trained end-to-end, that achieves state-of-the-art results on the standard benchmarks, ScanNet v2, SUN RGB-D, and S3DIS. Moreover, to take advantage of both point cloud and RGB inputs, we introduce an early fusion of 2D and 3D features. We employ our fusion module to make conventional 3D object detection methods multimodal and demonstrate an impressive boost in performance. Our model with early feature fusion, which we refer to as TR3D+FF, outperforms existing 3D object detection approaches on the SUN RGB-D dataset. Overall, besides being accurate, both TR3D and TR3D+FF models are lightweight, memory-efficient, and fast, thereby marking another milestone on the way toward real-time 3D object detection. Code is available at https://github.com/SamsungLabs/tr3d .
Accelerating Convergence in Global Non-Convex Optimization with Reversible Diffusion
May 19, 2023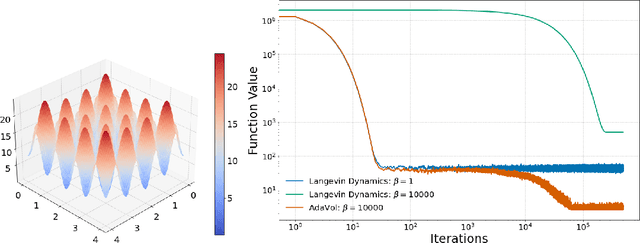
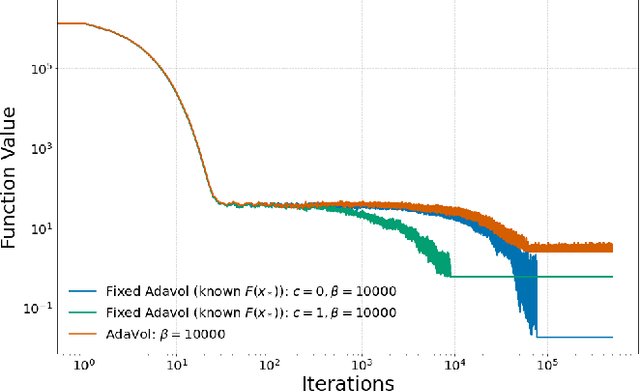
Langevin Dynamics has been extensively employed in global non-convex optimization due to the concentration of its stationary distribution around the global minimum of the potential function at low temperatures. In this paper, we propose to utilize a more comprehensive class of stochastic processes, known as reversible diffusion, and apply the Euler-Maruyama discretization for global non-convex optimization. We design the diffusion coefficient to be larger when distant from the optimum and smaller when near, thus enabling accelerated convergence while regulating discretization error, a strategy inspired by landscape modifications. Our proposed method can also be seen as a time change of Langevin Dynamics, and we prove convergence with respect to KL divergence, investigating the trade-off between convergence speed and discretization error. The efficacy of our proposed method is demonstrated through numerical experiments.
Traffic Forecasting on New Roads Unseen in the Training Data Using Spatial Contrastive Pre-Training
May 09, 2023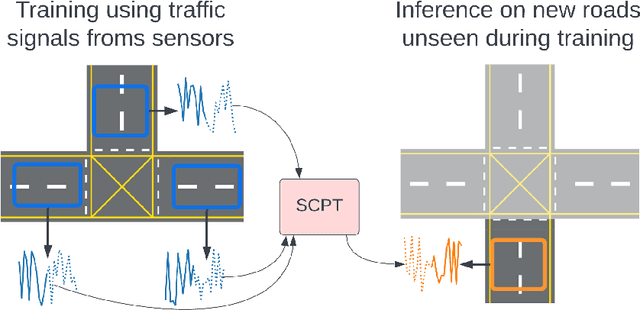
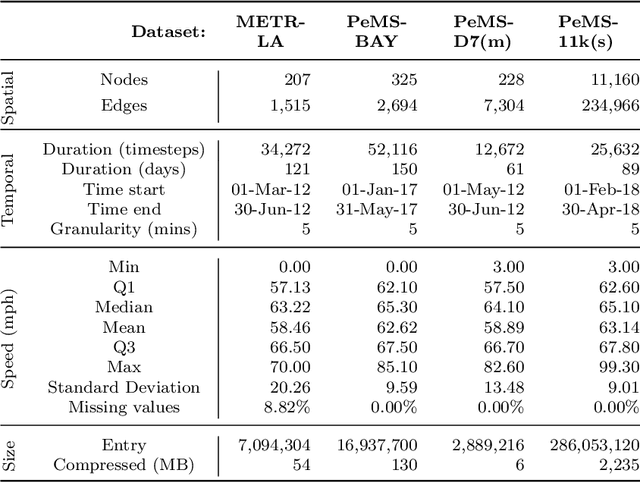
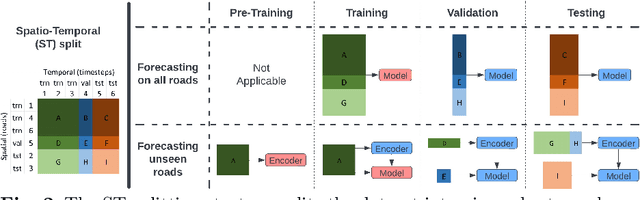
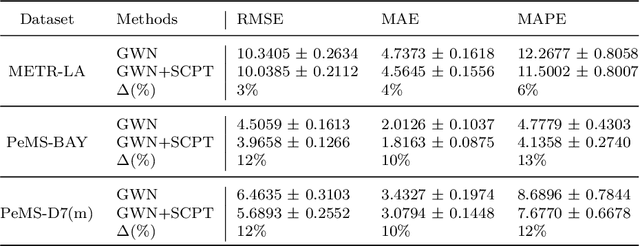
New roads are being constructed all the time. However, the capabilities of previous deep forecasting models to generalize to new roads not seen in the training data (unseen roads) are rarely explored. In this paper, we introduce a novel setup called a spatio-temporal (ST) split to evaluate the models' capabilities to generalize to unseen roads. In this setup, the models are trained on data from a sample of roads, but tested on roads not seen in the training data. Moreover, we also present a novel framework called Spatial Contrastive Pre-Training (SCPT) where we introduce a spatial encoder module to extract latent features from unseen roads during inference time. This spatial encoder is pre-trained using contrastive learning. During inference, the spatial encoder only requires two days of traffic data on the new roads and does not require any re-training. We also show that the output from the spatial encoder can be used effectively to infer latent node embeddings on unseen roads during inference time. The SCPT framework also incorporates a new layer, named the spatially gated addition (SGA) layer, to effectively combine the latent features from the output of the spatial encoder to existing backbones. Additionally, since there is limited data on the unseen roads, we argue that it is better to decouple traffic signals to trivial-to-capture periodic signals and difficult-to-capture Markovian signals, and for the spatial encoder to only learn the Markovian signals. Finally, we empirically evaluated SCPT using the ST split setup on four real-world datasets. The results showed that adding SCPT to a backbone consistently improves forecasting performance on unseen roads. More importantly, the improvements are greater when forecasting further into the future.
Validation of an ECAPA-TDNN system for Forensic Automatic Speaker Recognition under case work conditions
May 18, 2023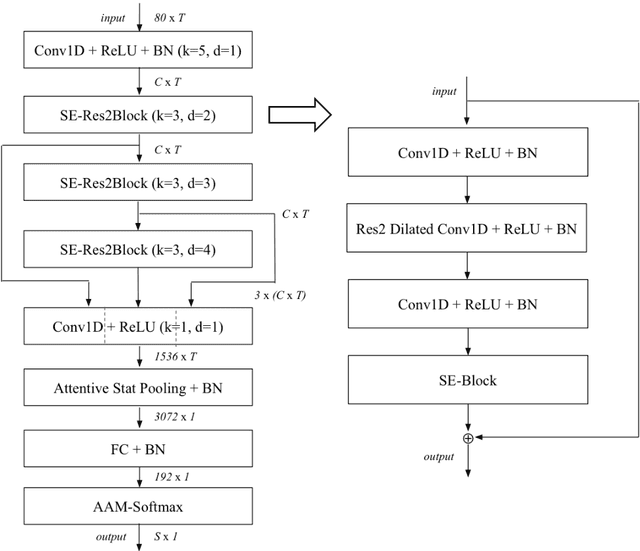
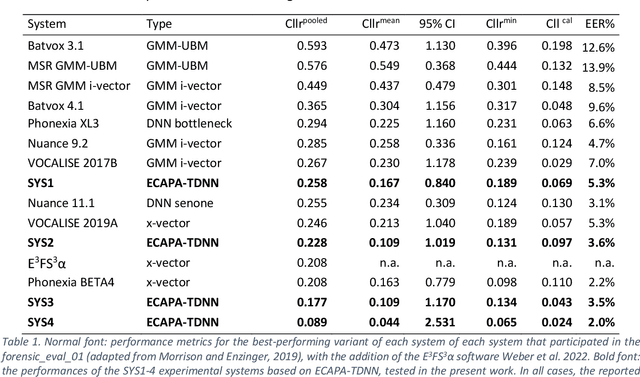
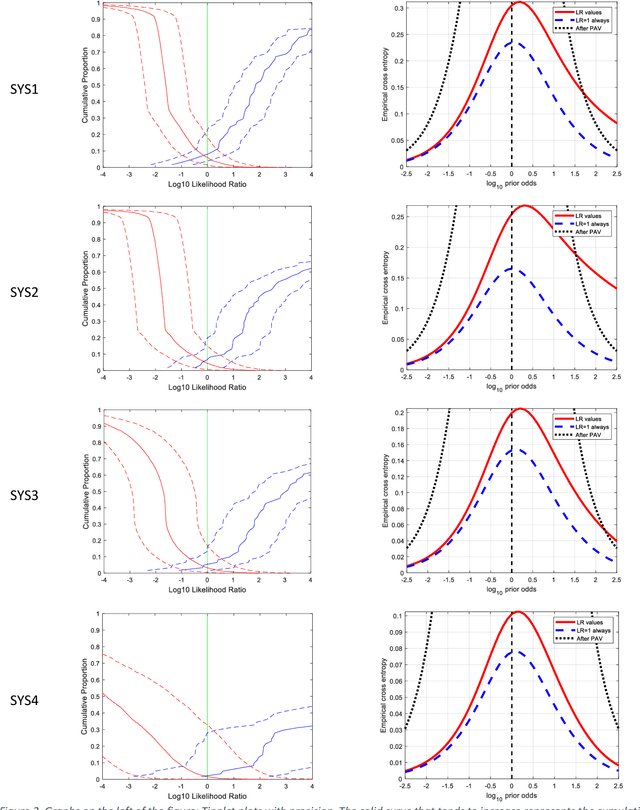
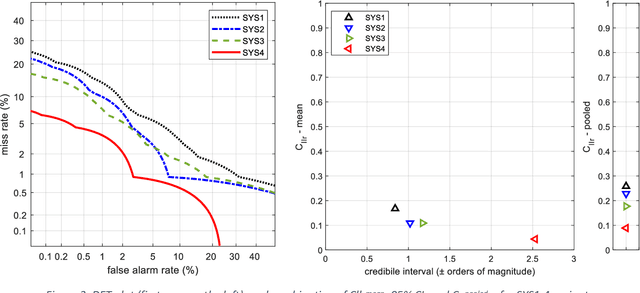
Different variants of a Forensic Automatic Speaker Recognition (FASR) system based on Emphasized Channel Attention, Propagation and Aggregation in Time Delay Neural Network (ECAPA-TDNN) are tested under conditions reflecting those of a real forensic voice comparison case, according to the forensic_eval_01 evaluation campaign settings. Using this recent neural model as an embedding extraction block, various normalization strategies at the level of embeddings and scores allow us to observe the variations in system performance, in terms of discriminating power, accuracy and precision metrics. From the achieved results it is possible to state that ECAPA-TDNN can be very successfully used as a base component of a FASR system, managing to surpass the previous state of the art, at least in the context of the considered operating conditions.
Re-thinking Data Availablity Attacks Against Deep Neural Networks
May 18, 2023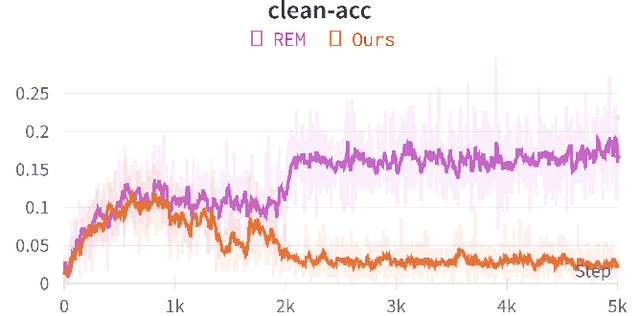
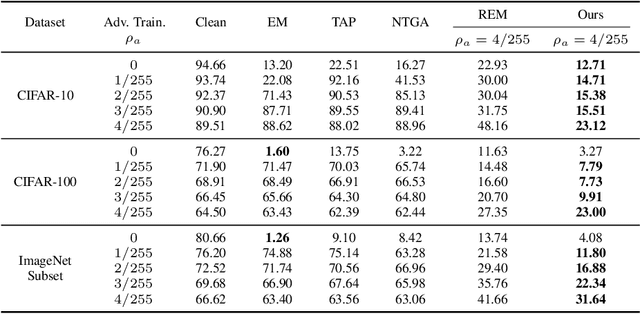
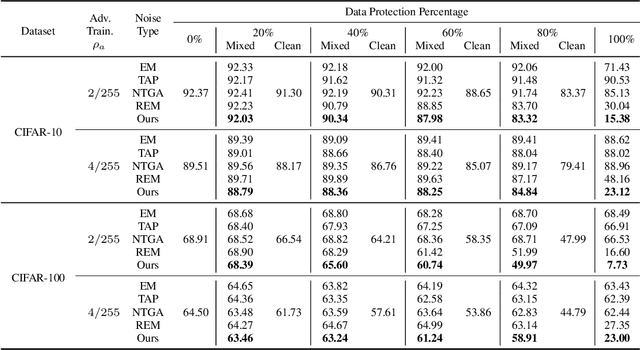
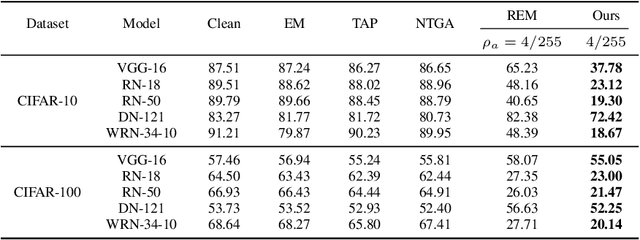
The unauthorized use of personal data for commercial purposes and the clandestine acquisition of private data for training machine learning models continue to raise concerns. In response to these issues, researchers have proposed availability attacks that aim to render data unexploitable. However, many current attack methods are rendered ineffective by adversarial training. In this paper, we re-examine the concept of unlearnable examples and discern that the existing robust error-minimizing noise presents an inaccurate optimization objective. Building on these observations, we introduce a novel optimization paradigm that yields improved protection results with reduced computational time requirements. We have conducted extensive experiments to substantiate the soundness of our approach. Moreover, our method establishes a robust foundation for future research in this area.
Uncovering Adversarial Risks of Test-Time Adaptation
Jan 29, 2023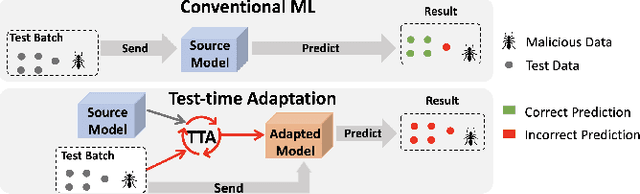
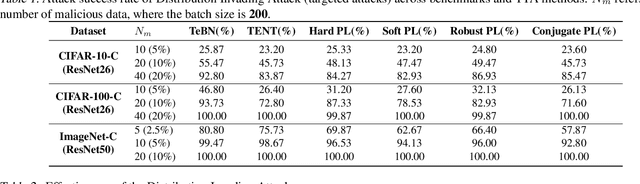
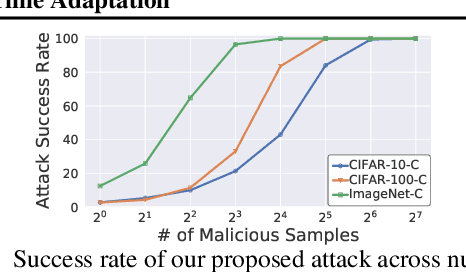
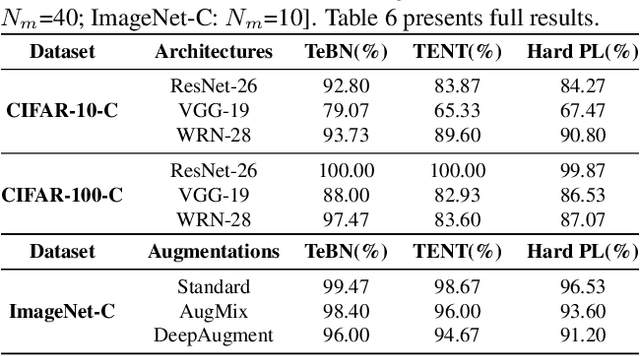
Recently, test-time adaptation (TTA) has been proposed as a promising solution for addressing distribution shifts. It allows a base model to adapt to an unforeseen distribution during inference by leveraging the information from the batch of (unlabeled) test data. However, we uncover a novel security vulnerability of TTA based on the insight that predictions on benign samples can be impacted by malicious samples in the same batch. To exploit this vulnerability, we propose Distribution Invading Attack (DIA), which injects a small fraction of malicious data into the test batch. DIA causes models using TTA to misclassify benign and unperturbed test data, providing an entirely new capability for adversaries that is infeasible in canonical machine learning pipelines. Through comprehensive evaluations, we demonstrate the high effectiveness of our attack on multiple benchmarks across six TTA methods. In response, we investigate two countermeasures to robustify the existing insecure TTA implementations, following the principle of "security by design". Together, we hope our findings can make the community aware of the utility-security tradeoffs in deploying TTA and provide valuable insights for developing robust TTA approaches.