 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HCLAS-X: Hierarchical and Cascaded Lyrics Alignment System Using Multimodal Cross-Correlation
Jul 10, 2023
In this work, we address the challenge of lyrics alignment, which involves aligning the lyrics and vocal components of songs. This problem requires the alignment of two distinct modalities, namely text and audio. To overcome this challenge, we propose a model that is trained in a supervised manner, utilizing the cross-correlation matrix of latent representations between vocals and lyrics. Our system is designed in a hierarchical and cascaded manner. It predicts synced time first on a sentence-level and subsequently on a word-level. This design enables the system to process long sequences, as the cross-correlation uses quadratic memory with respect to sequence length. In our experiments, we demonstrate that our proposed system achieves a significant improvement in mean average error, showcasing its robustness in comparison to the previous state-of-the-art model. Additionally, we conduct a qualitative analysis of the system after successfully deploying it in several music streaming services.
RLTF: Reinforcement Learning from Unit Test Feedback
Jul 10, 2023
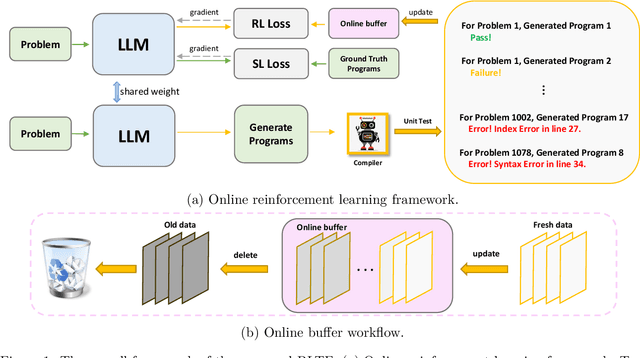

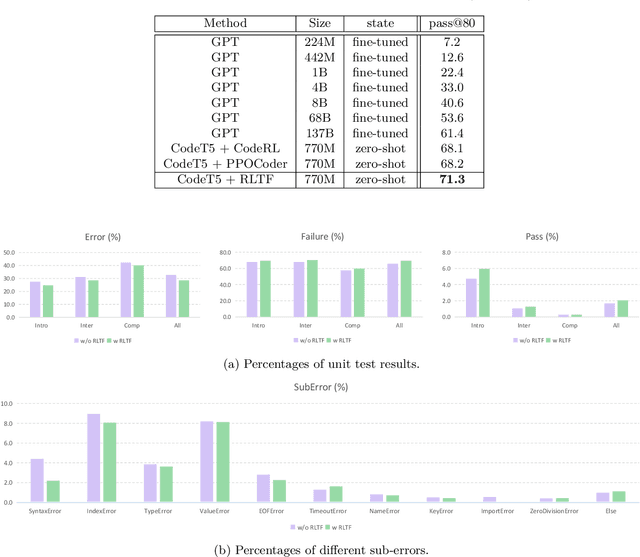
The goal of program synthesis, or code generation, is to generate executable code based on given descriptions. Recently, there has been an increasing number of studies employing reinforcement learning (RL) to improve the performance of large language models (LLMs) for code. However, these RL methods have only used offline frameworks, limiting their exploration of new sample spaces. Additionally, current approaches that utilize unit test signals are rather simple, not accounting for specific error locations within the code. To address these issues, we proposed RLTF, i.e., Reinforcement Learning from Unit Test Feedback, a novel online RL framework with unit test feedback of multi-granularity for refining code LLMs. Our approach generates data in real-time during training and simultaneously utilizes fine-grained feedback signals to guide the model towards producing higher-quality code. Extensive experiments show that RLTF achieves state-of-the-art performance on the APPS and the MBPP benchmarks. Our code can be found at: https://github.com/Zyq-scut/RLTF.
Optimal Robot Path Planning In a Collaborative Human-Robot Team with Intermittent Human Availability
Jul 10, 2023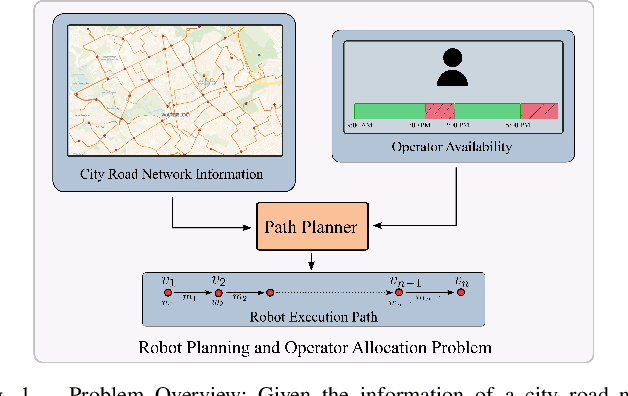
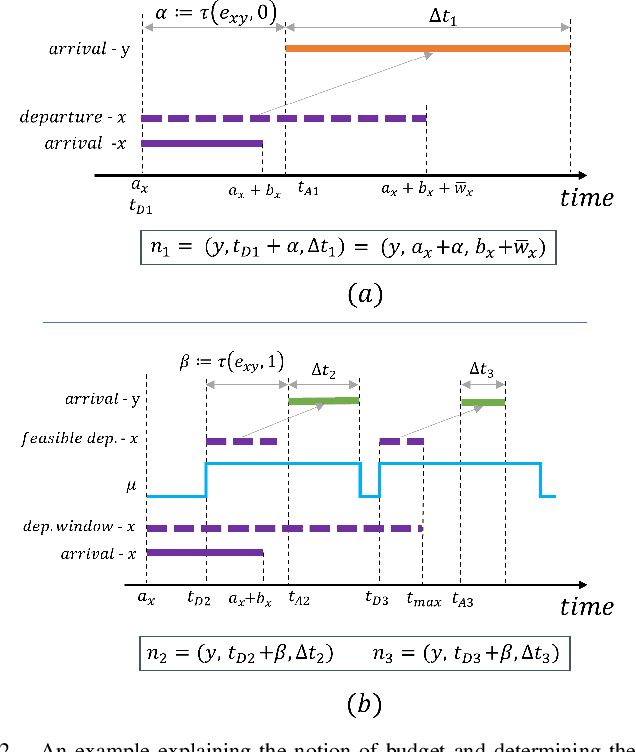
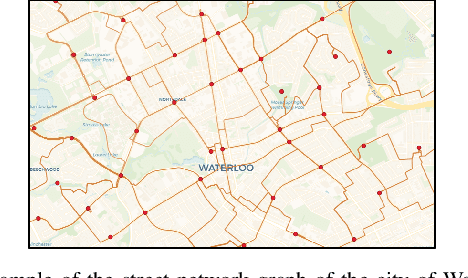
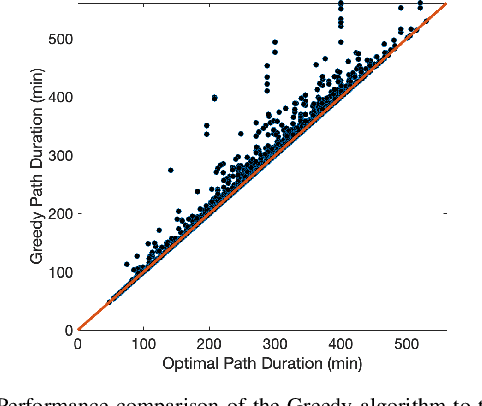
This paper presents a solution for the problem of optimal planning for a robot in a collaborative human-robot team, where the human supervisor is intermittently available to assist the robot in completing tasks more quickly. Specifically, we address the challenge of computing the fastest path between two configurations in an environment with time constraints on how long the robot can wait for assistance. To solve this problem, we propose a novel approach that utilizes the concepts of budget and critical departure times, which enables us to obtain optimal solutions while scaling to larger problem instances than existing methods. We demonstrate the effectiveness of our approach by comparing it with several baseline algorithms on a city road network and analyzing the quality of the solutions obtained. Our work contributes to the field of robot planning by addressing the critical issue of incorporating human assistance and environmental restrictions, which has significant implications for real-world applications.
MASK-CNN-Transformer For Real-Time Multi-Label Weather Recognition
Apr 28, 2023Weather recognition is an essential support for many practical life applications, including traffic safety, environment, and meteorology. However, many existing related works cannot comprehensively describe weather conditions due to their complex co-occurrence dependencies. This paper proposes a novel multi-label weather recognition model considering these dependencies. The proposed model called MASK-Convolutional Neural Network-Transformer (MASK-CT) is based on the Transformer, the convolutional process, and the MASK mechanism. The model employs multiple convolutional layers to extract features from weather images and a Transformer encoder to calculate the probability of each weather condition based on the extracted features. To improve the generalization ability of MASK-CT, a MASK mechanism is used during the training phase. The effect of the MASK mechanism is explored and discussed. The Mask mechanism randomly withholds some information from one-pair training instances (one image and its corresponding label). There are two types of MASK methods. Specifically, MASK-I is designed and deployed on the image before feeding it into the weather feature extractor and MASK-II is applied to the image label. The Transformer encoder is then utilized on the randomly masked image features and labels. The experimental results from various real-world weather recognition datasets demonstrate that the proposed MASK-CT model outperforms state-of-the-art methods. Furthermore, the high-speed dynamic real-time weather recognition capability of the MASK-CT is evaluated.
The Human Auditory System and Audio
Jun 30, 2023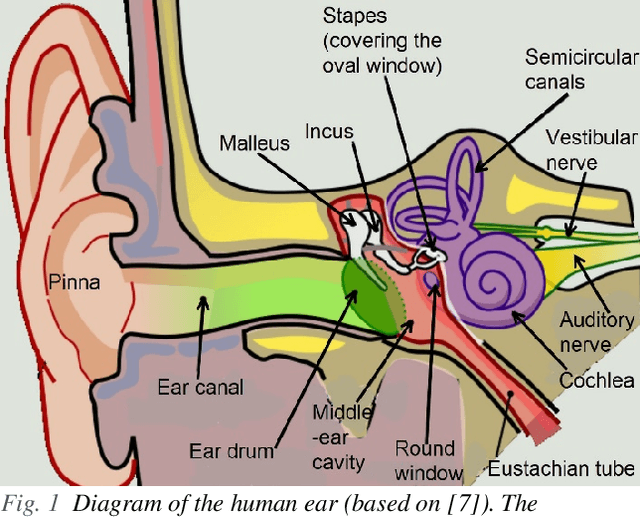
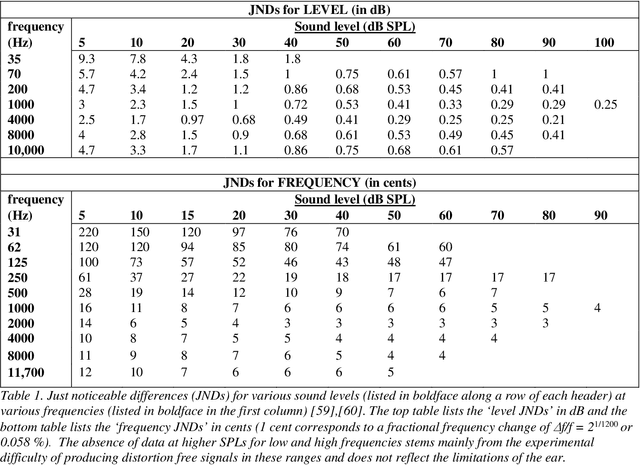
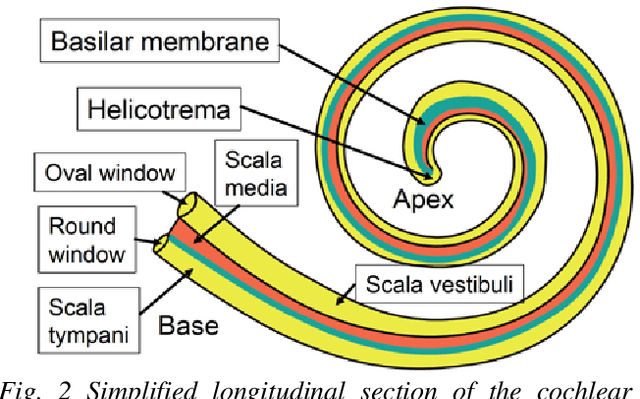
This work reviews the human auditory system, elucidating some of the specialized mechanisms and non-linear pathways along the chain of events between physical sound and its perception. Customary relationships between frequency, time, and phase--such as the uncertainty principle--that hold for linear systems, do not apply straightforwardly to the hearing process. Auditory temporal resolution for certain processes can be a hundredth of the period of the signal, and can extend down to the microseconds time scale. The astonishingly large number of variations that correspond to the neural excitation pattern of 30000 auditory nerve fibers, originating from 3500 inner hair cells, explicates the vast capacity of the auditory system for the resolution of sonic detail. And the ear is sensitive enough to detect a basilar-membrane amplitude at the level of a picometer, or about a hundred times smaller than an atom. This article surveys and provides new insights into some of the impressive capabilities of the human auditory system and explores their relationship to fidelity in reproduced sound.
Reliable Learning for Test-time Attacks and Distribution Shift
Apr 06, 2023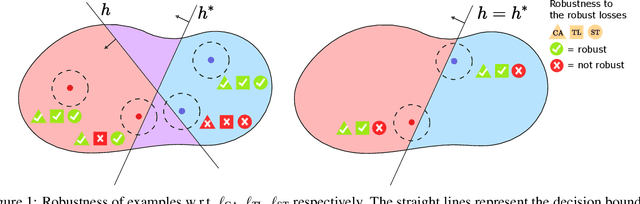
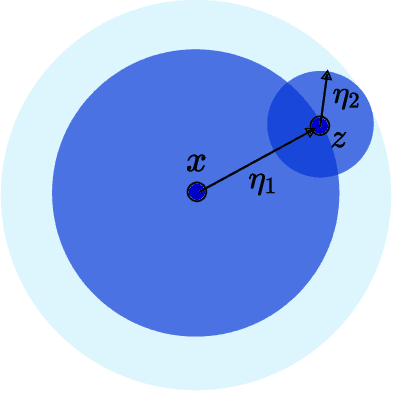
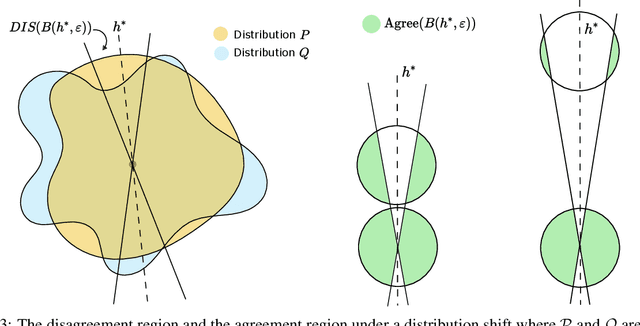
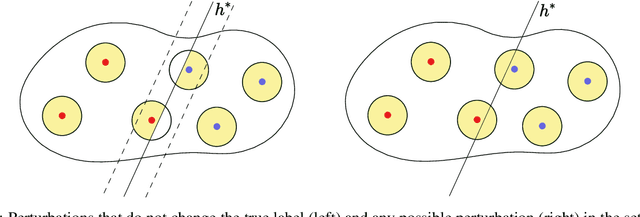
Machine learning algorithms are often used in environments which are not captured accurately even by the most carefully obtained training data, either due to the possibility of `adversarial' test-time attacks, or on account of `natural' distribution shift. For test-time attacks, we introduce and analyze a novel robust reliability guarantee, which requires a learner to output predictions along with a reliability radius $\eta$, with the meaning that its prediction is guaranteed to be correct as long as the adversary has not perturbed the test point farther than a distance $\eta$. We provide learners that are optimal in the sense that they always output the best possible reliability radius on any test point, and we characterize the reliable region, i.e. the set of points where a given reliability radius is attainable. We additionally analyze reliable learners under distribution shift, where the test points may come from an arbitrary distribution Q different from the training distribution P. For both cases, we bound the probability mass of the reliable region for several interesting examples, for linear separators under nearly log-concave and s-concave distributions, as well as for smooth boundary classifiers under smooth probability distributions.
Mitigating Cold-start Forecasting using Cold Causal Demand Forecasting Model
Jun 15, 2023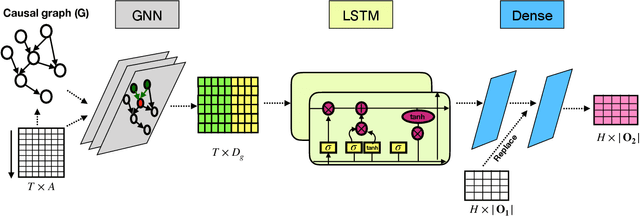
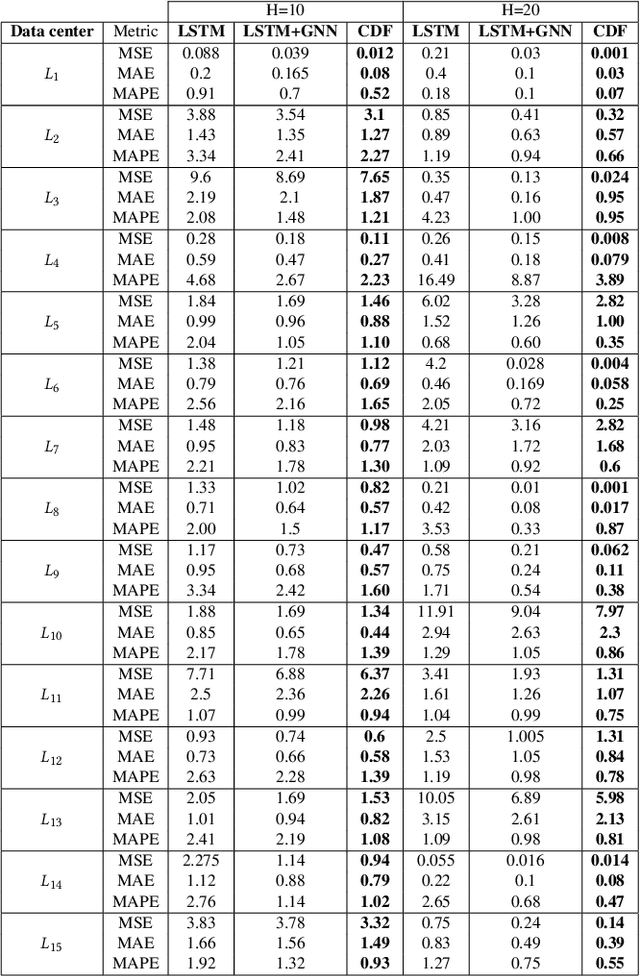
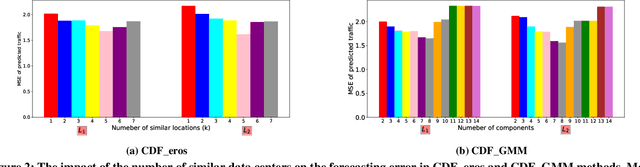
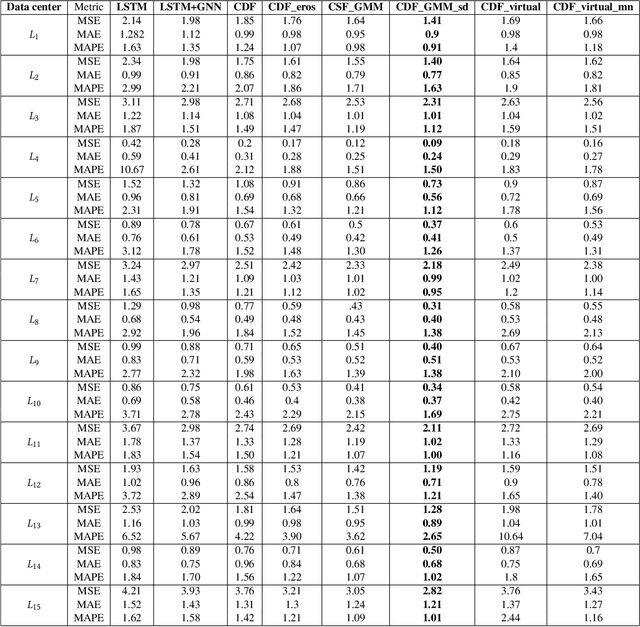
Forecasting multivariate time series data, which involves predicting future values of variables over time using historical data, has significant practical applications. Although deep learning-based models have shown promise in this field, they often fail to capture the causal relationship between dependent variables, leading to less accurate forecasts. Additionally, these models cannot handle the cold-start problem in time series data, where certain variables lack historical data, posing challenges in identifying dependencies among variables. To address these limitations, we introduce the Cold Causal Demand Forecasting (CDF-cold) framework that integrates causal inference with deep learning-based models to enhance the forecasting accuracy of multivariate time series data affected by the cold-start problem. To validate the effectiveness of the proposed approach, we collect 15 multivariate time-series datasets containing the network traffic of different Google data centers. Our experiments demonstrate that the CDF-cold framework outperforms state-of-the-art forecasting models in predicting future values of multivariate time series data.
Population Age Group Sensitivity for COVID-19 Infections with Deep Learning
Jul 03, 2023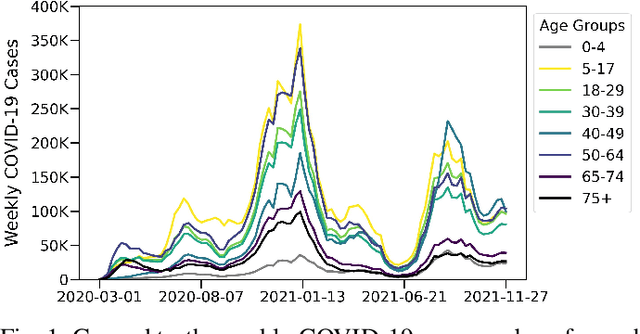
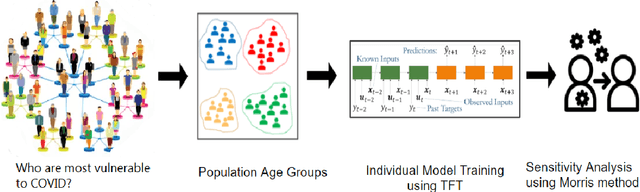
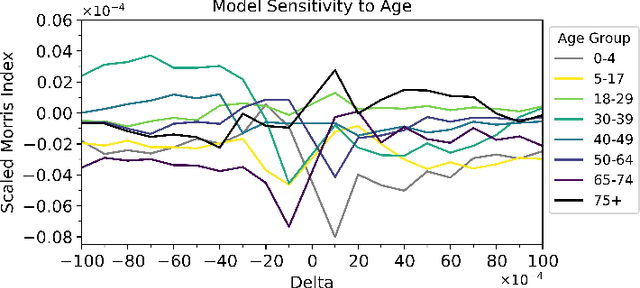
The COVID-19 pandemic has created unprecedented challenges for governments and healthcare systems worldwide, highlighting the critical importance of understanding the factors that contribute to virus transmission. This study aimed to identify the most influential age groups in COVID-19 infection rates at the US county level using the Modified Morris Method and deep learning for time series. Our approach involved training the state-of-the-art time-series model Temporal Fusion Transformer on different age groups as a static feature and the population vaccination status as the dynamic feature. We analyzed the impact of those age groups on COVID-19 infection rates by perturbing individual input features and ranked them based on their Morris sensitivity scores, which quantify their contribution to COVID-19 transmission rates. The findings are verified using ground truth data from the CDC and US Census, which provide the true infection rates for each age group. The results suggest that young adults were the most influential age group in COVID-19 transmission at the county level between March 1, 2020, and November 27, 2021. Using these results can inform public health policies and interventions, such as targeted vaccination strategies, to better control the spread of the virus. Our approach demonstrates the utility of feature sensitivity analysis in identifying critical factors contributing to COVID-19 transmission and can be applied in other public health domains.
Energy-Efficient Mining for Blockchain-Enabled IoT Applications. An Optimal Multiple-Stopping Time Approach
May 09, 2023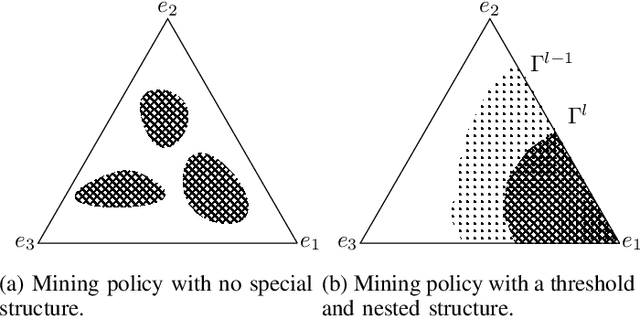
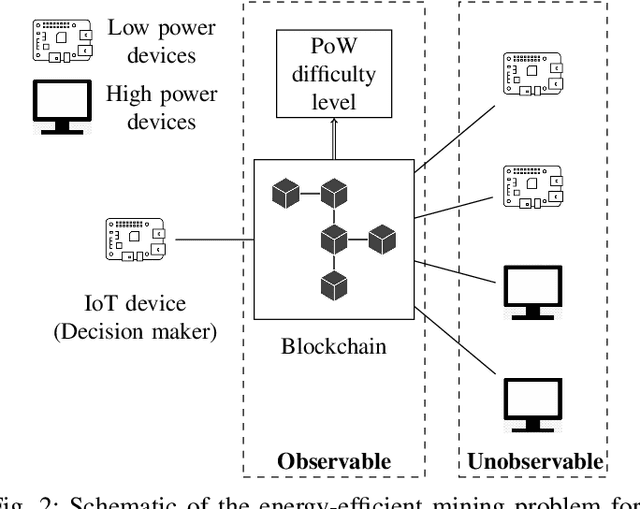

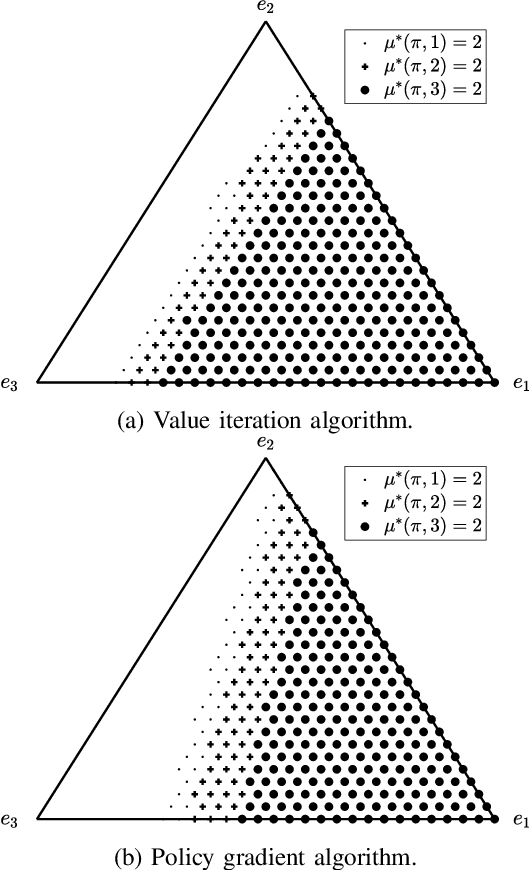
What are the optimal times for an Internet of Things (IoT) device to act as a blockchain miner? The aim is to minimize the energy consumed by low-power IoT devices that log their data into a secure (tamper-proof) distributed ledger. We formulate the energy-efficient blockchain mining for IoT devices as a multiple-stopping time partially observed Markov decision process (POMDP) to maximize the probability of adding a block in the blockchain; we also present a model to optimize the number of stops (mining instants). In general, POMDPs are computationally intractable to solve, but we show mathematically using submodularity that the optimal mining policy has a useful structure: 1) it is monotone in belief space, and 2) it exhibits a threshold structure, which divides the belief space into two connected sets. Exploiting the structural results, we formulate a computationally-efficient linear mining policy for the blockchain-enabled IoT device. We present a policy gradient technique to optimize the parameters of the linear mining policy. Finally, we use synthetic and real Bitcoin datasets to study the performance of our proposed mining policy. We demonstrate the energy efficiency achieved by the optimal linear mining policy in contrast to other heuristic strategies.
Real Time Bearing Fault Diagnosis Based on Convolutional Neural Network and STM32 Microcontroller
Apr 14, 2023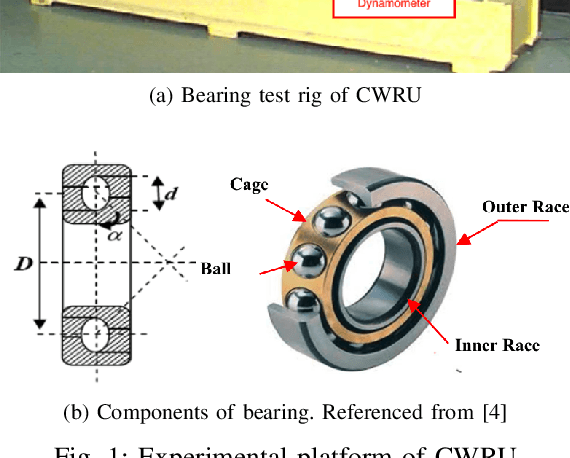
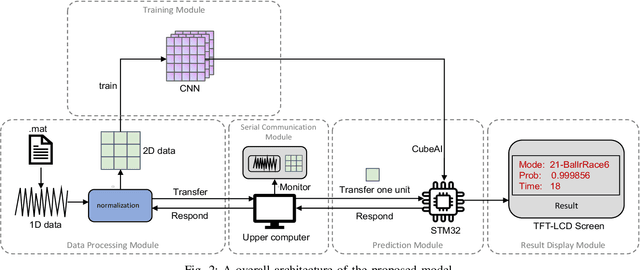
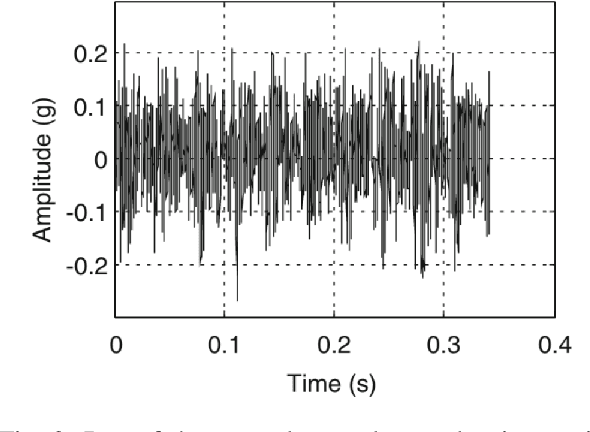
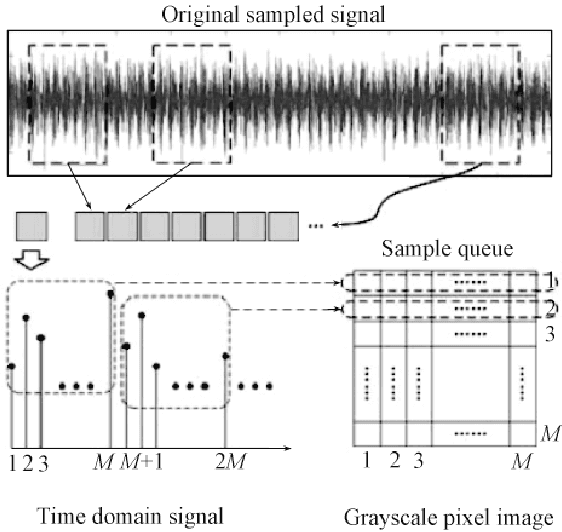
With the rapid development of big data and edge computing, many researchers focus on improving the accuracy of bearing fault classification using deep learning models, and implementing the deep learning classification model on limited resource platforms such as STM32. To this end, this paper realizes the identification of bearing fault vibration signal based on convolutional neural network, the fault identification accuracy of the optimised model can reach 98.9%. In addition, this paper successfully applies the convolutional neural network model to STM32H743VI microcontroller, the running time of each diagnosis is 19ms. Finally, a complete real-time communication framework between the host computer and the STM32 is designed, which can perfectly complete the data transmission through the serial port and display the diagnosis results on the TFT-LCD screen.