 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Regret-Optimal Model-Free Reinforcement Learning for Discounted MDPs with Short Burn-In Time
May 24, 2023
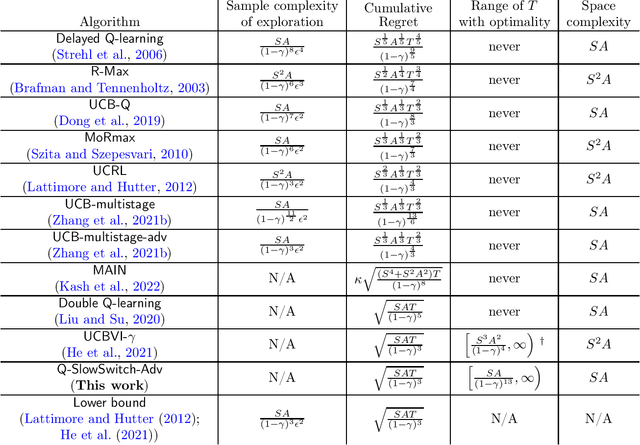
A crucial problem in reinforcement learning is learning the optimal policy. We study this in tabular infinite-horizon discounted Markov decision processes under the online setting. The existing algorithms either fail to achieve regret optimality or have to incur a high memory and computational cost. In addition, existing optimal algorithms all require a long burn-in time in order to achieve optimal sample efficiency, i.e., their optimality is not guaranteed unless sample size surpasses a high threshold. We address both open problems by introducing a model-free algorithm that employs variance reduction and a novel technique that switches the execution policy in a slow-yet-adaptive manner. This is the first regret-optimal model-free algorithm in the discounted setting, with the additional benefit of a low burn-in time.
Time-Frequency Warped Waveforms for Well-Contained Massive Machine Type Communications
May 01, 2023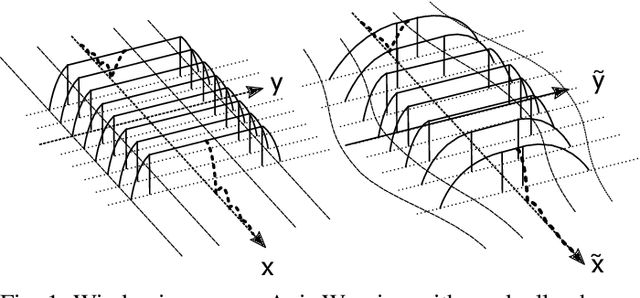
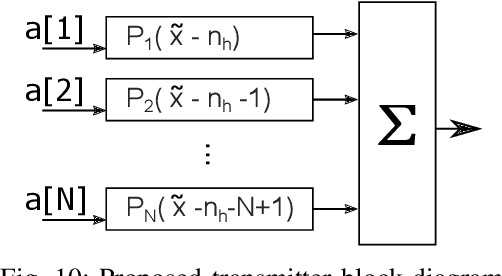
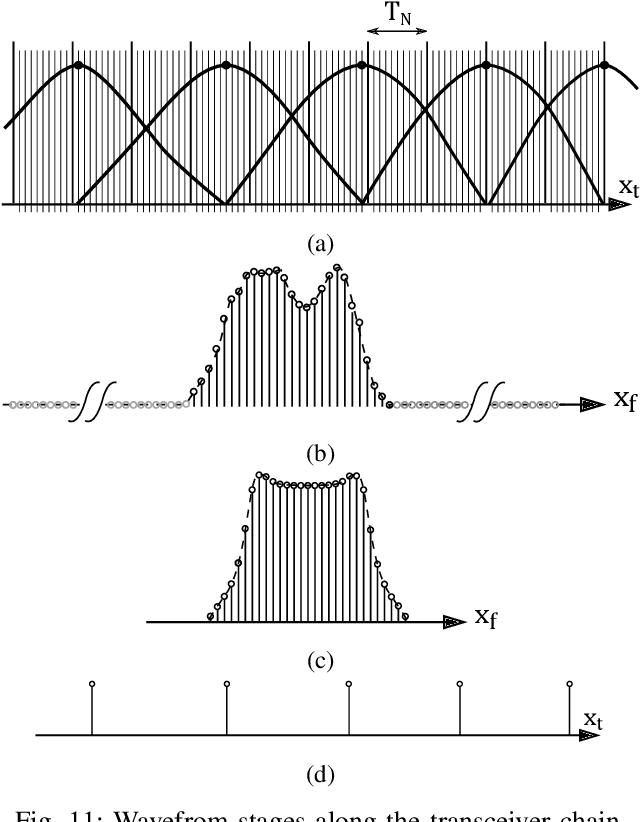
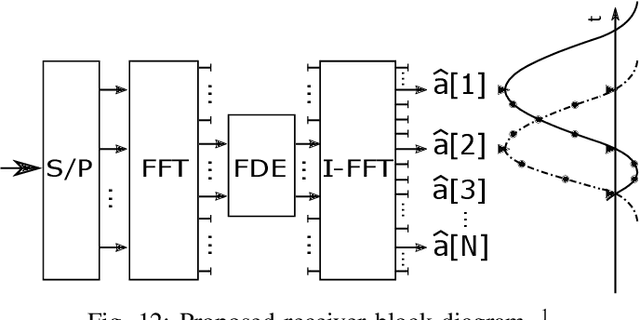
This paper proposes a novel time-frequency warped waveform for short symbols, massive machine-type communication (mMTC), and internet of things (IoT) applications. The waveform is composed of asymmetric raised cosine (RC) pulses to increase the signal containment in time and frequency domains. The waveform has low power tails in the time domain, hence better performance in the presence of delay spread and time offsets. The time-axis warping unitary transform is applied to control the waveform occupancy in time-frequency space and to compensate for the usage of high roll-off factor pulses at the symbol edges. The paper explains a step-by-step analysis for determining the roll-off factors profile and the warping functions. Gains are presented over the conventional Zero-tail Discrete Fourier Transform-spread-Orthogonal Frequency Division Multiplexing (ZT-DFT-s-OFDM), and Cyclic prefix (CP) DFT-s-OFDM schemes in the simulations section.
Age-Based Cache Updating Under Timestomping
Jul 18, 2023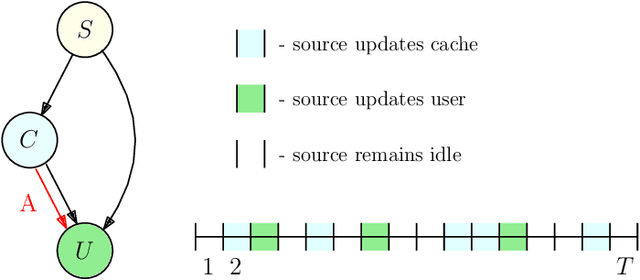
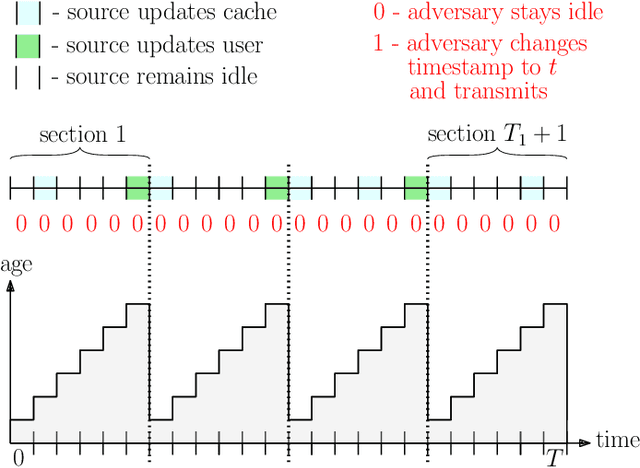
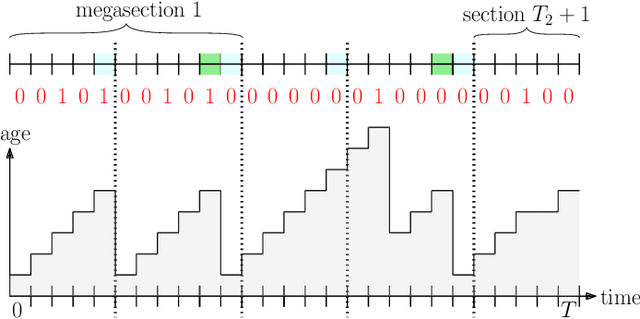
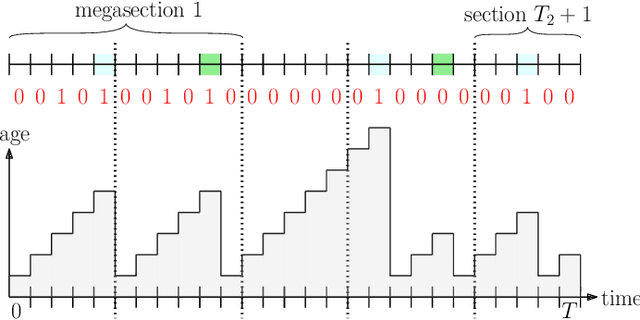
We consider a slotted communication system consisting of a source, a cache, a user and a timestomping adversary. The time horizon consists of total $T$ time slots, such that the source transmits update packets to the user directly over $T_{1}$ time slots and to the cache over $T_{2}$ time slots. We consider $T_{1}\ll T_{2}$, $T_{1}+T_{2} < T$, such that the source transmits to the user once between two consecutive cache updates. Update packets are marked with timestamps corresponding to their generation times at the source. All nodes have a buffer size of one and store the packet with the latest timestamp to minimize their age of information. In this setting, we consider the presence of an oblivious adversary that fully controls the communication link between the cache and the user. The adversary manipulates the timestamps of outgoing packets from the cache to the user, with the goal of bringing staleness at the user node. At each time slot, the adversary can choose to either forward the cached packet to the user, after changing its timestamp to current time $t$, thereby rebranding an old packet as a fresh packet and misleading the user into accepting it, or stay idle. The user compares the timestamps of every received packet with the latest packet in its possession to keep the fresher one and discard the staler packet. If the user receives update packets from both cache and source in a time slot, then the packet from source prevails. The goal of the source is to design an algorithm to minimize the average age at the user, and the goal of the adversary is to increase the average age at the user. We formulate this problem in an online learning setting and provide a fundamental lower bound on the competitive ratio for this problem. We further propose a deterministic algorithm with a provable guarantee on its competitive ratio.
Improving Autonomous Separation Assurance through Distributed Reinforcement Learning with Attention Networks
Aug 09, 2023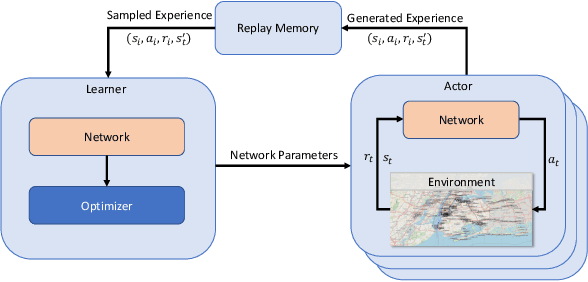
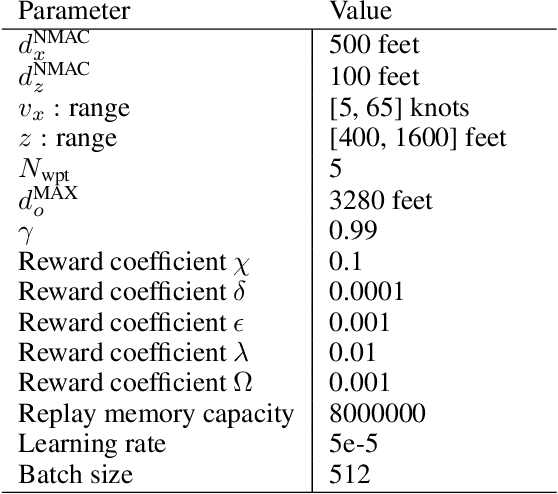


Advanced Air Mobility (AAM) introduces a new, efficient mode of transportation with the use of vehicle autonomy and electrified aircraft to provide increasingly autonomous transportation between previously underserved markets. Safe and efficient navigation of low altitude aircraft through highly dense environments requires the integration of a multitude of complex observations, such as surveillance, knowledge of vehicle dynamics, and weather. The processing and reasoning on these observations pose challenges due to the various sources of uncertainty in the information while ensuring cooperation with a variable number of aircraft in the airspace. These challenges coupled with the requirement to make safety-critical decisions in real-time rule out the use of conventional separation assurance techniques. We present a decentralized reinforcement learning framework to provide autonomous self-separation capabilities within AAM corridors with the use of speed and vertical maneuvers. The problem is formulated as a Markov Decision Process and solved by developing a novel extension to the sample-efficient, off-policy soft actor-critic (SAC) algorithm. We introduce the use of attention networks for variable-length observation processing and a distributed computing architecture to achieve high training sample throughput as compared to existing approaches. A comprehensive numerical study shows that the proposed framework can ensure safe and efficient separation of aircraft in high density, dynamic environments with various sources of uncertainty.
Twinning Commercial Radio Waveforms in the Colosseum Wireless Network Emulator
Aug 09, 2023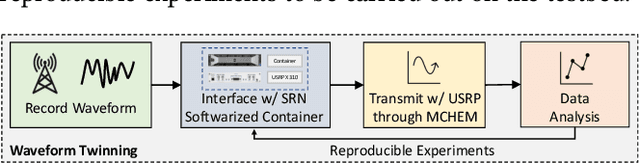

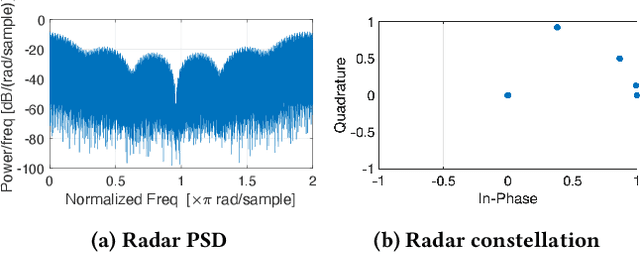
Because of the ever-growing amount of wireless consumers, spectrum-sharing techniques have been increasingly common in the wireless ecosystem, with the main goal of avoiding harmful interference to coexisting communication systems. This is even more important when considering systems-such as nautical and aerial fleet radars-in which incumbent radios operate mission-critical communication links. To study, develop, and validate these solutions, adequate platforms, such as the Colosseum wireless network emulator, are key as they enable experimentation with spectrum-sharing heterogeneous radio technologies in controlled environments. In this work, we demonstrate how Colosseum can be used to twin commercial radio waveforms to evaluate the coexistence of such technologies in complex wireless propagation environments. To this aim, we create a high-fidelity spectrum-sharing scenario on Colosseum to evaluate the impact of twinned commercial radar waveforms on a cellular network operating in the CBRS band. Then, we leverage IQ samples collected on the testbed to train a machine learning agent that runs at the base station to detect the presence of incumbent radar transmissions and vacate the bandwidth to avoid causing them harmful interference. Our results show an average detection accuracy of 88%, with accuracy above 90% in SNR regimes above 0 dB and SINR regimes above -20 dB, and with an average detection time of 137 ms.
DuETT: Dual Event Time Transformer for Electronic Health Records
Apr 25, 2023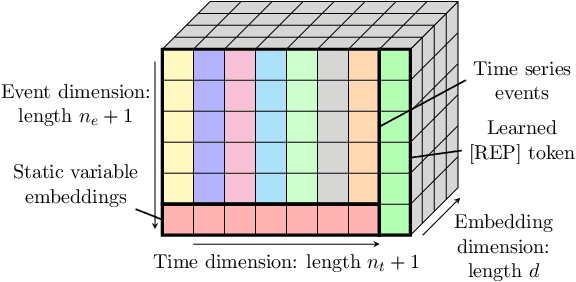
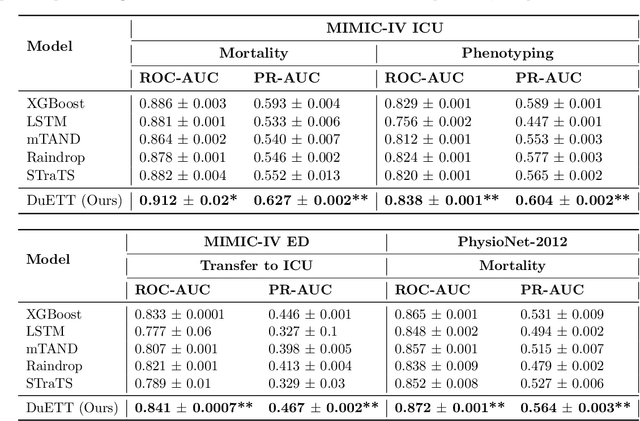
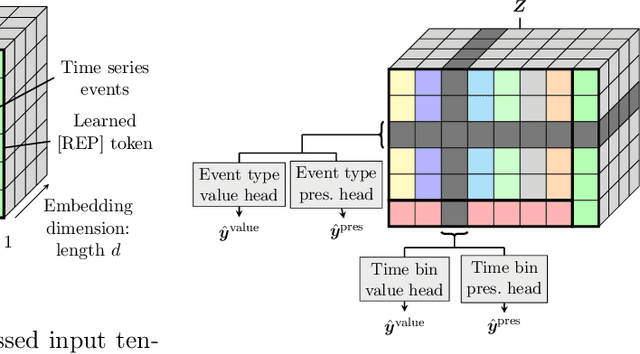
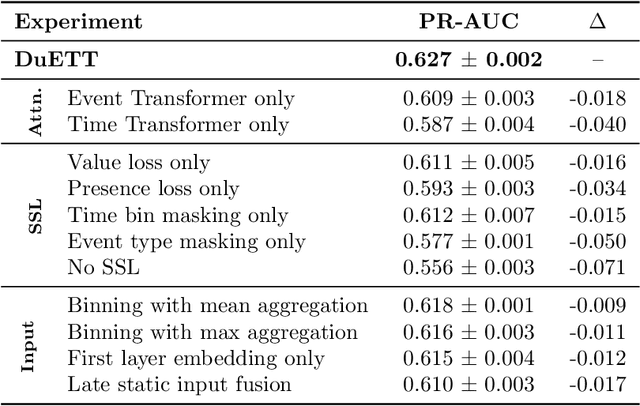
Electronic health records (EHRs) recorded in hospital settings typically contain a wide range of numeric time series data that is characterized by high sparsity and irregular observations. Effective modelling for such data must exploit its time series nature, the semantic relationship between different types of observations, and information in the sparsity structure of the data. Self-supervised Transformers have shown outstanding performance in a variety of structured tasks in NLP and computer vision. But multivariate time series data contains structured relationships over two dimensions: time and recorded event type, and straightforward applications of Transformers to time series data do not leverage this distinct structure. The quadratic scaling of self-attention layers can also significantly limit the input sequence length without appropriate input engineering. We introduce the DuETT architecture, an extension of Transformers designed to attend over both time and event type dimensions, yielding robust representations from EHR data. DuETT uses an aggregated input where sparse time series are transformed into a regular sequence with fixed length; this lowers the computational complexity relative to previous EHR Transformer models and, more importantly, enables the use of larger and deeper neural networks. When trained with self-supervised prediction tasks, that provide rich and informative signals for model pre-training, our model outperforms state-of-the-art deep learning models on multiple downstream tasks from the MIMIC-IV and PhysioNet-2012 EHR datasets.
Towards practical reinforcement learning for tokamak magnetic control
Jul 21, 2023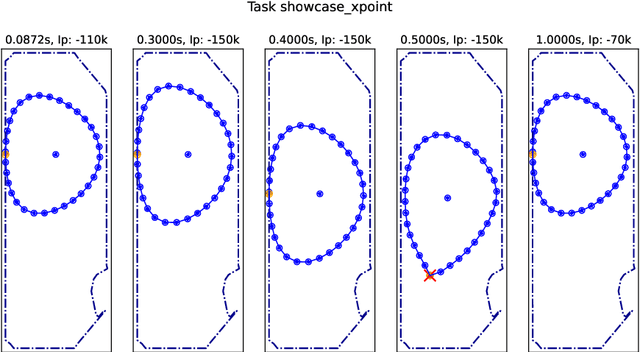


Reinforcement learning (RL) has shown promising results for real-time control systems, including the domain of plasma magnetic control. However, there are still significant drawbacks compared to traditional feedback control approaches for magnetic confinement. In this work, we address key drawbacks of the RL method; achieving higher control accuracy for desired plasma properties, reducing the steady-state error, and decreasing the required time to learn new tasks. We build on top of \cite{degrave2022magnetic}, and present algorithmic improvements to the agent architecture and training procedure. We present simulation results that show up to 65\% improvement in shape accuracy, achieve substantial reduction in the long-term bias of the plasma current, and additionally reduce the training time required to learn new tasks by a factor of 3 or more. We present new experiments using the upgraded RL-based controllers on the TCV tokamak, which validate the simulation results achieved, and point the way towards routinely achieving accurate discharges using the RL approach.
Brain MRI Segmentation using Template-Based Training and Visual Perception Augmentation
Aug 04, 2023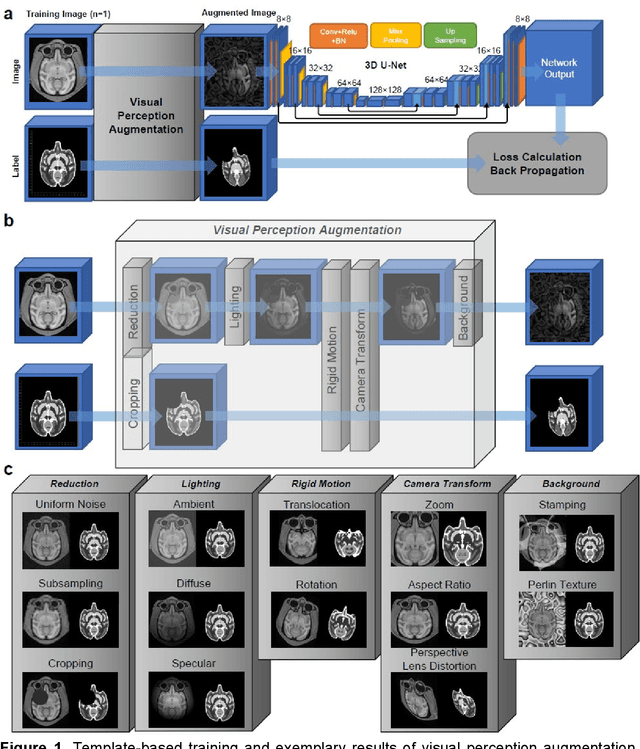
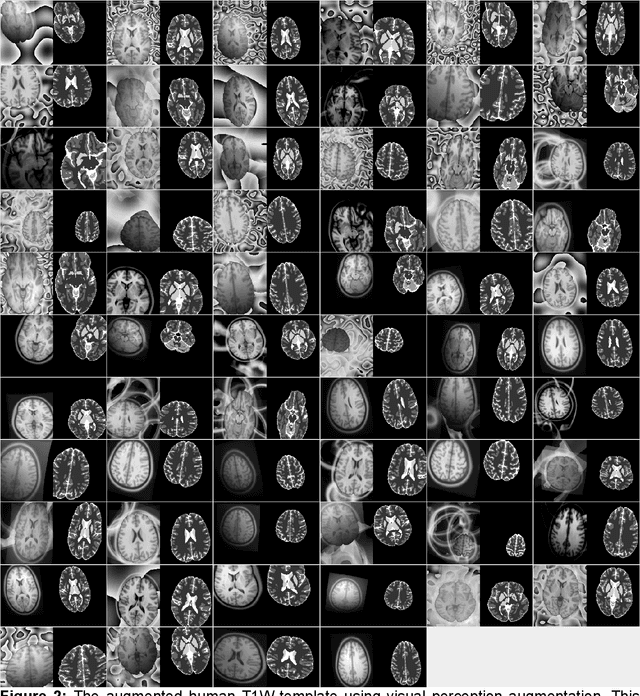
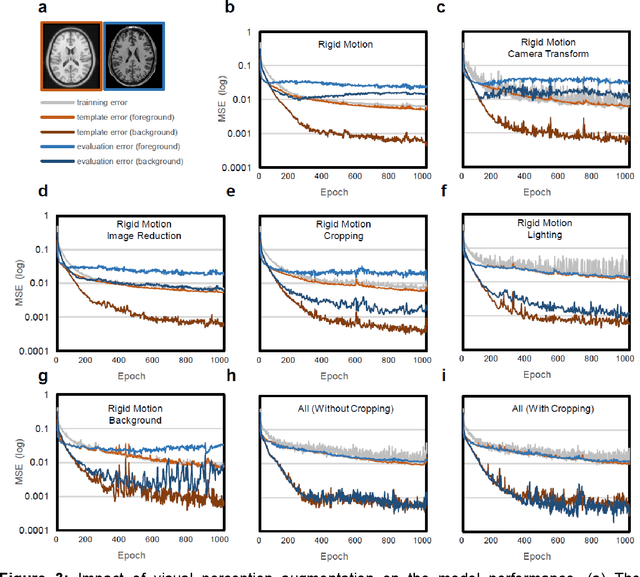
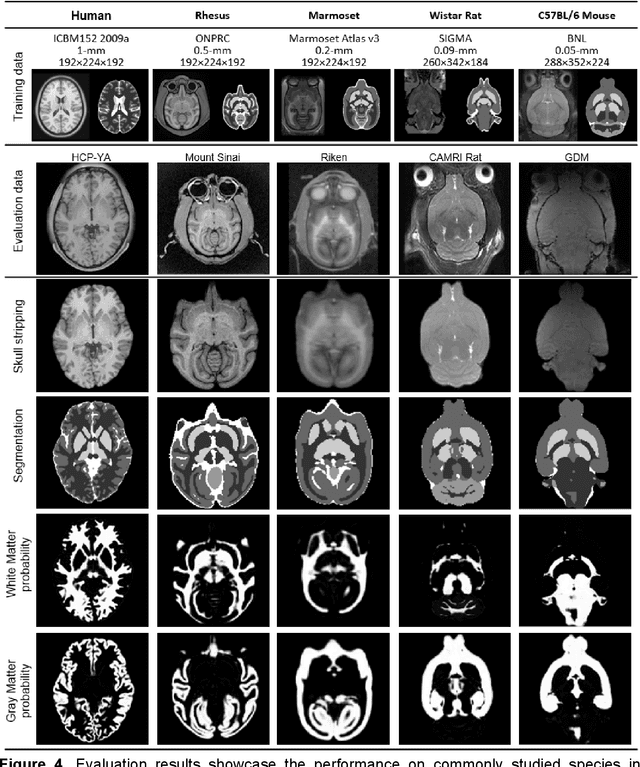
Deep learning models usually require sufficient training data to achieve high accuracy, but obtaining labeled data can be time-consuming and labor-intensive. Here we introduce a template-based training method to train a 3D U-Net model from scratch using only one population-averaged brain MRI template and its associated segmentation label. The process incorporated visual perception augmentation to enhance the model's robustness in handling diverse image inputs and mitigating overfitting. Leveraging this approach, we trained 3D U-Net models for mouse, rat, marmoset, rhesus, and human brain MRI to achieve segmentation tasks such as skull-stripping, brain segmentation, and tissue probability mapping. This tool effectively addresses the limited availability of training data and holds significant potential for expanding deep learning applications in image analysis, providing researchers with a unified solution to train deep neural networks with only one image sample.
Lightweight Endoscopic Depth Estimation with CNN-Transformer Encoder
Aug 04, 2023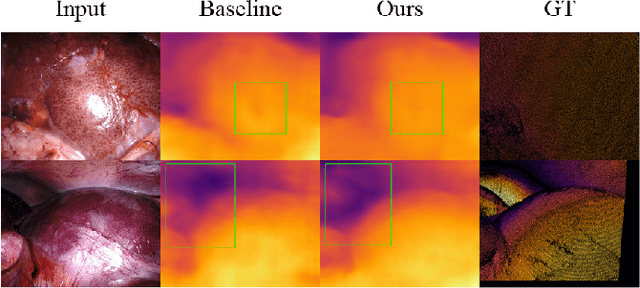
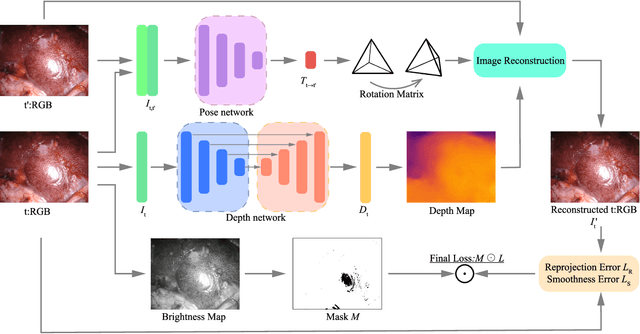
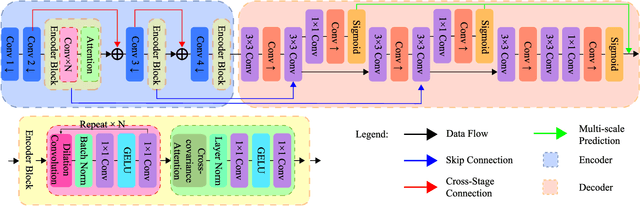
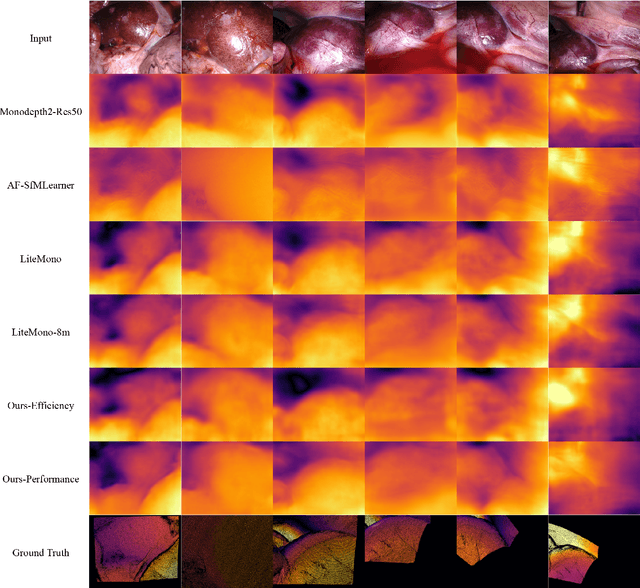
In this study, we tackle the key challenges concerning accuracy and robustness in depth estimation for endoscopic imaging, with a particular emphasis on real-time inference and the impact of reflections. We propose an innovative lightweight solution that integrates Convolutional Neural Networks (CNN) and Transformers to predict multi-scale depth maps. Our approach includes optimizing the network architecture, incorporating multi-scale dilated convolution, and a multi-channel attention mechanism. We also introduce a statistical confidence boundary mask to minimize the impact of reflective areas. Moreover, we propose a novel complexity evaluation metric that considers network parameter size, floating-point operations, and inference frames per second. Our research aims to enhance the efficiency and safety of laparoscopic surgery significantly. We comprehensively evaluate our proposed method and compare it with existing solutions. The results demonstrate that our method ensures depth estimation accuracy while being lightweight.
Efficient Monaural Speech Enhancement using Spectrum Attention Fusion
Aug 04, 2023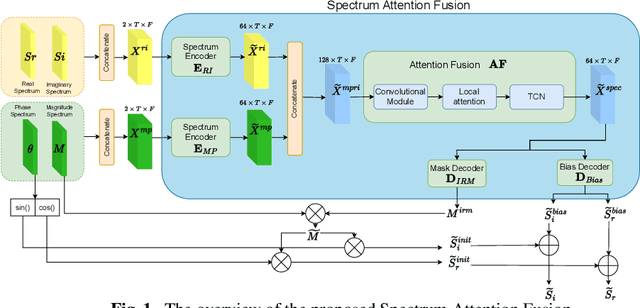
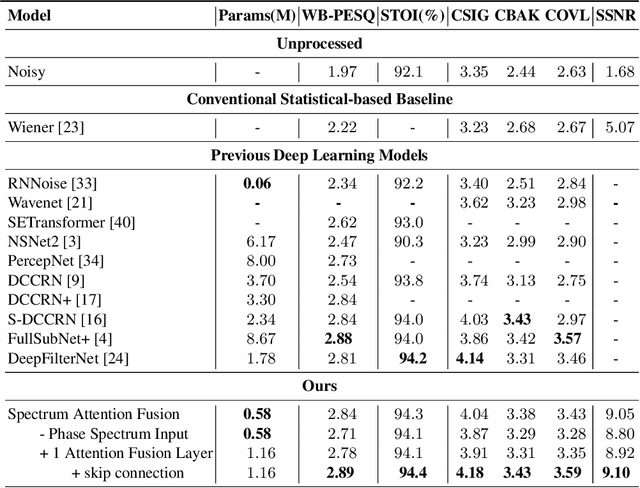
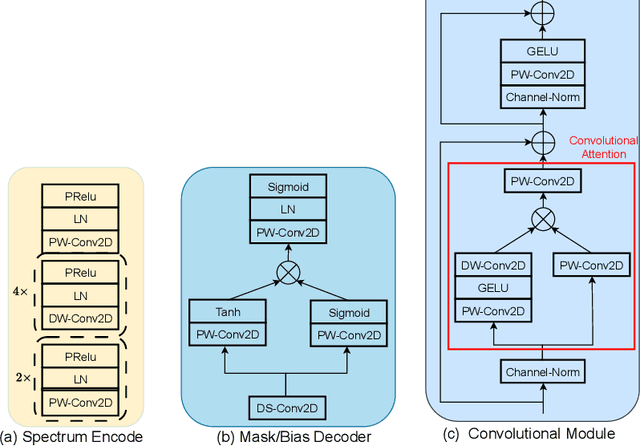
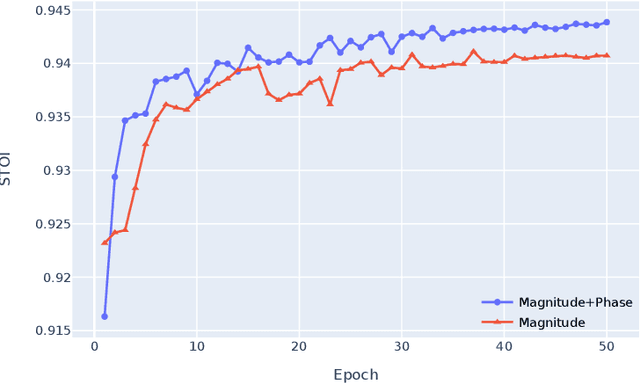
Speech enhancement is a demanding task in automated speech processing pipelines, focusing on separating clean speech from noisy channels. Transformer based models have recently bested RNN and CNN models in speech enhancement, however at the same time they are much more computationally expensive and require much more high quality training data, which is always hard to come by. In this paper, we present an improvement for speech enhancement models that maintains the expressiveness of self-attention while significantly reducing model complexity, which we have termed Spectrum Attention Fusion. We carefully construct a convolutional module to replace several self-attention layers in a speech Transformer, allowing the model to more efficiently fuse spectral features. Our proposed model is able to achieve comparable or better results against SOTA models but with significantly smaller parameters (0.58M) on the Voice Bank + DEMAND dataset.