 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Can Emerge in Tabular Foundation Models From a Single Table
Nov 12, 2025



Deep tabular modelling increasingly relies on in-context learning where, during inference, a model receives a set of $(x,y)$ pairs as context and predicts labels for new inputs without weight updates. We challenge the prevailing view that broad generalization here requires pre-training on large synthetic corpora (e.g., TabPFN priors) or a large collection of real data (e.g., TabDPT training datasets), discovering that a relatively small amount of data suffices for generalization. We find that simple self-supervised pre-training on just a \emph{single} real table can produce surprisingly strong transfer across heterogeneous benchmarks. By systematically pre-training and evaluating on many diverse datasets, we analyze what aspects of the data are most important for building a Tabular Foundation Model (TFM) generalizing across domains. We then connect this to the pre-training procedure shared by most TFMs and show that the number and quality of \emph{tasks} one can construct from a dataset is key to downstream performance.
TabDPT: Scaling Tabular Foundation Models
Oct 23, 2024



The challenges faced by neural networks on tabular data are well-documented and have hampered the progress of tabular foundation models. Techniques leveraging in-context learning (ICL) have shown promise here, allowing for dynamic adaptation to unseen data. ICL can provide predictions for entirely new datasets without further training or hyperparameter tuning, therefore providing very fast inference when encountering a novel task. However, scaling ICL for tabular data remains an issue: approaches based on large language models cannot efficiently process numeric tables, and tabular-specific techniques have not been able to effectively harness the power of real data to improve performance and generalization. We are able to overcome these challenges by training tabular-specific ICL-based architectures on real data with self-supervised learning and retrieval, combining the best of both worlds. Our resulting model -- the Tabular Discriminative Pre-trained Transformer (TabDPT) -- achieves state-of-the-art performance on the CC18 (classification) and CTR23 (regression) benchmarks with no task-specific fine-tuning, demonstrating the adapatability and speed of ICL once the model is pre-trained. TabDPT also demonstrates strong scaling as both model size and amount of available data increase, pointing towards future improvements simply through the curation of larger tabular pre-training datasets and training larger models.
MultiResFormer: Transformer with Adaptive Multi-Resolution Modeling for General Time Series Forecasting
Nov 30, 2023



Transformer-based models have greatly pushed the boundaries of time series forecasting recently. Existing methods typically encode time series data into $\textit{patches}$ using one or a fixed set of patch lengths. This, however, could result in a lack of ability to capture the variety of intricate temporal dependencies present in real-world multi-periodic time series. In this paper, we propose MultiResFormer, which dynamically models temporal variations by adaptively choosing optimal patch lengths. Concretely, at the beginning of each layer, time series data is encoded into several parallel branches, each using a detected periodicity, before going through the transformer encoder block. We conduct extensive evaluations on long- and short-term forecasting datasets comparing MultiResFormer with state-of-the-art baselines. MultiResFormer outperforms patch-based Transformer baselines on long-term forecasting tasks and also consistently outperforms CNN baselines by a large margin, while using much fewer parameters than these baselines.
DuETT: Dual Event Time Transformer for Electronic Health Records
Apr 25, 2023Electronic health records (EHRs) recorded in hospital settings typically contain a wide range of numeric time series data that is characterized by high sparsity and irregular observations. Effective modelling for such data must exploit its time series nature, the semantic relationship between different types of observations, and information in the sparsity structure of the data. Self-supervised Transformers have shown outstanding performance in a variety of structured tasks in NLP and computer vision. But multivariate time series data contains structured relationships over two dimensions: time and recorded event type, and straightforward applications of Transformers to time series data do not leverage this distinct structure. The quadratic scaling of self-attention layers can also significantly limit the input sequence length without appropriate input engineering. We introduce the DuETT architecture, an extension of Transformers designed to attend over both time and event type dimensions, yielding robust representations from EHR data. DuETT uses an aggregated input where sparse time series are transformed into a regular sequence with fixed length; this lowers the computational complexity relative to previous EHR Transformer models and, more importantly, enables the use of larger and deeper neural networks. When trained with self-supervised prediction tasks, that provide rich and informative signals for model pre-training, our model outperforms state-of-the-art deep learning models on multiple downstream tasks from the MIMIC-IV and PhysioNet-2012 EHR datasets.
A Framework for Neural Network Pruning Using Gibbs Distributions
Jun 08, 2020
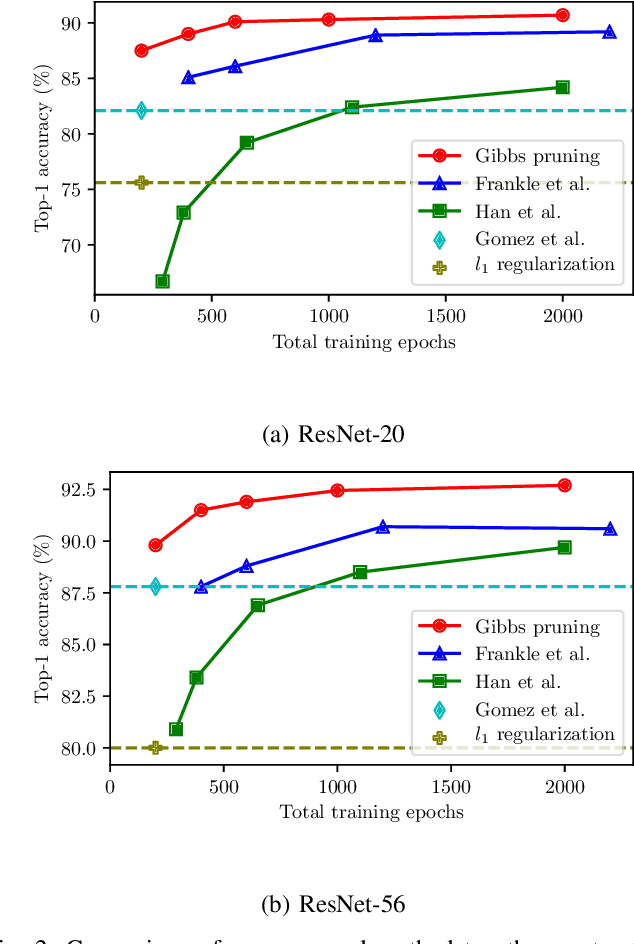
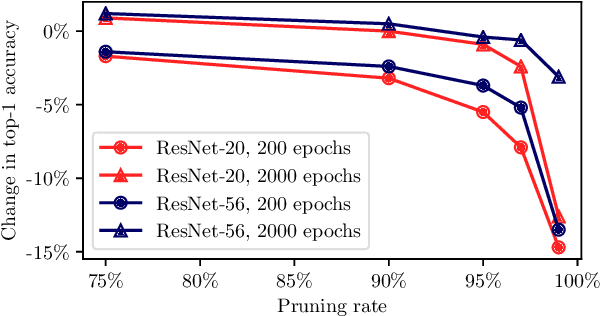
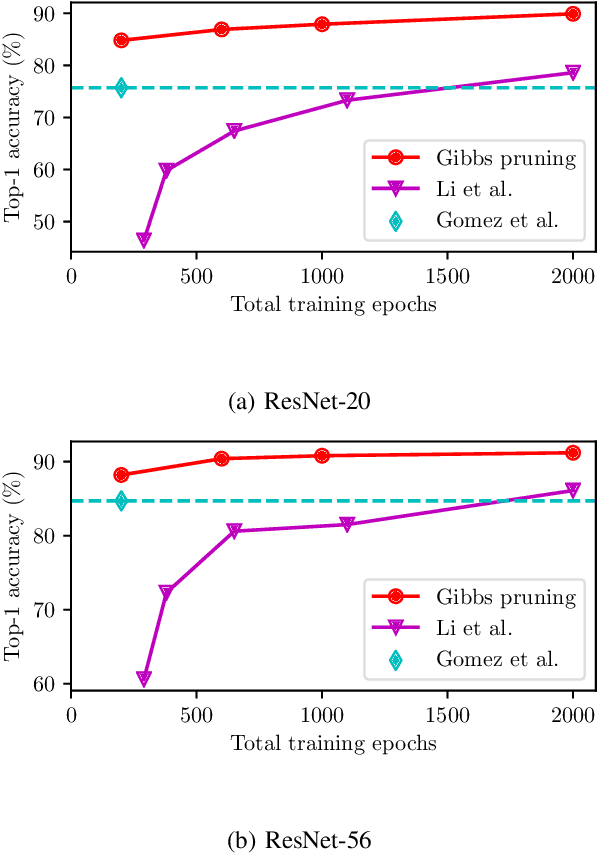
Neural network pruning is an important technique for creating efficient machine learning models that can run on edge devices. We propose a new, highly flexible approach to neural network pruning based on Gibbs distributions. We apply it with Hamiltonians that are based on weight magnitude, using the annealing capabilities of Gibbs distributions to smoothly move from regularization to adaptive pruning during an ordinary neural network training schedule. This method can be used for either unstructured or structured pruning, and we provide explicit formulations for both. We compare our proposed method to several established pruning methods on ResNet variants and find that it outperforms them for unstructured, kernel-wise, and filter-wise pruning.
Regularizing Neural Networks by Stochastically Training Layer Ensembles
Nov 21, 2019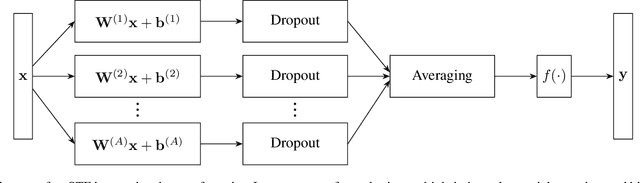



Dropout and similar stochastic neural network regularization methods are often interpreted as implicitly averaging over a large ensemble of models. We propose STE (stochastically trained ensemble) layers, which enhance the averaging properties of such methods by training an ensemble of weight matrices with stochastic regularization while explicitly averaging outputs. This provides stronger regularization with no additional computational cost at test time. We show consistent improvement on various image classification tasks using standard network topologies.
Survey of Dropout Methods for Deep Neural Networks
Apr 25, 2019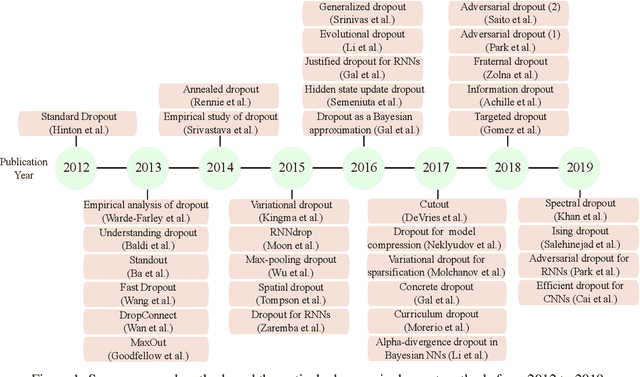
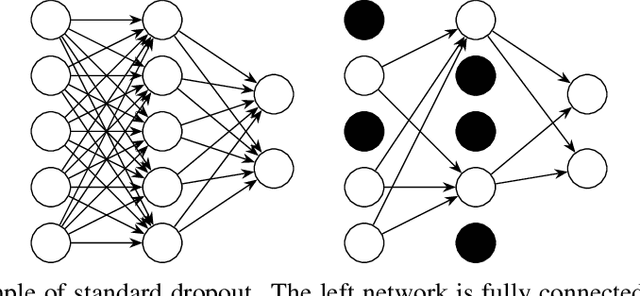
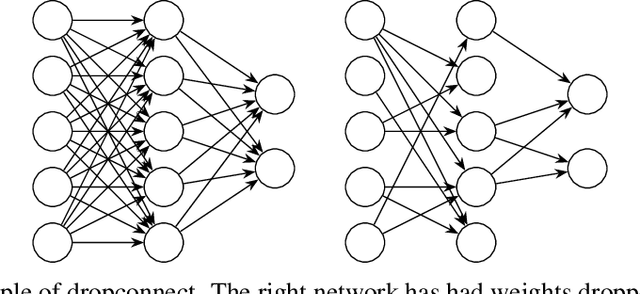
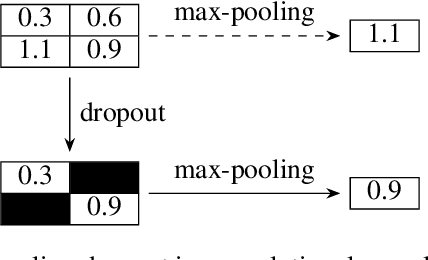
Dropout methods are a family of stochastic techniques used in neural network training or inference that have generated significant research interest and are widely used in practice. They have been successfully applied in neural network regularization, model compression, and in measuring the uncertainty of neural network outputs. While original formulated for dense neural network layers, recent advances have made dropout methods also applicable to convolutional and recurrent neural network layers. This paper summarizes the history of dropout methods, their various applications, and current areas of research interest. Important proposed methods are described in additional detail.