 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Source Localization and Data Association for Time-Difference of Arrival Measurements
Mar 15, 2024
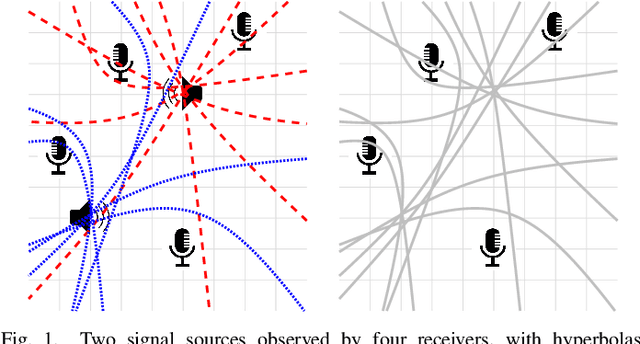
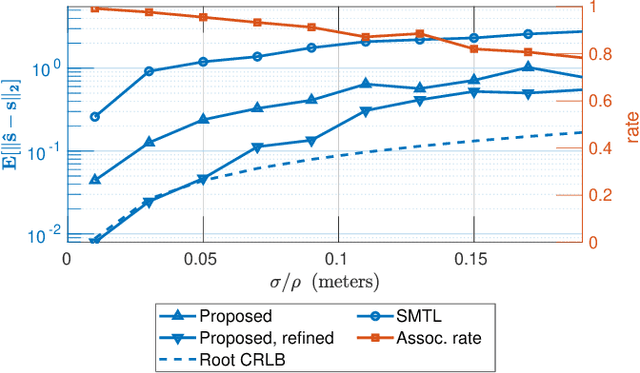
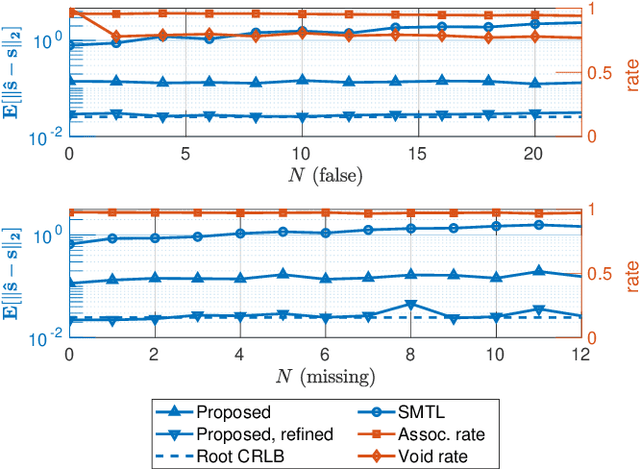
In this work, we consider the problem of localizing multiple signal sources based on time-difference of arrival (TDOA) measurements. In the blind setting, in which the source signals are not known, the localization task is challenging due to the data association problem. That is, it is not known which of the TDOA measurements correspond to the same source. Herein, we propose to perform joint localization and data association by means of an optimal transport formulation. The method operates by finding optimal groupings of TDOA measurements and associating these with candidate source locations. To allow for computationally feasible localization in three-dimensional space, an efficient set of candidate locations is constructed using a minimal multilateration solver based on minimal sets of receiver pairs. In numerical simulations, we demonstrate that the proposed method is robust both to measurement noise and TDOA detection errors. Furthermore, it is shown that the data association provided by the proposed method allows for statistically efficient estimates of the source locations.
U-Sketch: An Efficient Approach for Sketch to Image Diffusion Models
Mar 27, 2024Diffusion models have demonstrated remarkable performance in text-to-image synthesis, producing realistic and high resolution images that faithfully adhere to the corresponding text-prompts. Despite their great success, they still fall behind in sketch-to-image synthesis tasks, where in addition to text-prompts, the spatial layout of the generated images has to closely follow the outlines of certain reference sketches. Employing an MLP latent edge predictor to guide the spatial layout of the synthesized image by predicting edge maps at each denoising step has been recently proposed. Despite yielding promising results, the pixel-wise operation of the MLP does not take into account the spatial layout as a whole, and demands numerous denoising iterations to produce satisfactory images, leading to time inefficiency. To this end, we introduce U-Sketch, a framework featuring a U-Net type latent edge predictor, which is capable of efficiently capturing both local and global features, as well as spatial correlations between pixels. Moreover, we propose the addition of a sketch simplification network that offers the user the choice of preprocessing and simplifying input sketches for enhanced outputs. The experimental results, corroborated by user feedback, demonstrate that our proposed U-Net latent edge predictor leads to more realistic results, that are better aligned with the spatial outlines of the reference sketches, while drastically reducing the number of required denoising steps and, consequently, the overall execution time.
Multi-AGV Path Planning Method via Reinforcement Learning and Particle Filters
Mar 27, 2024The Reinforcement Learning (RL) algorithm, renowned for its robust learning capability and search stability, has garnered significant attention and found extensive application in Automated Guided Vehicle (AGV) path planning. However, RL planning algorithms encounter challenges stemming from the substantial variance of neural networks caused by environmental instability and significant fluctuations in system structure. These challenges manifest in slow convergence speed and low learning efficiency. To tackle this issue, this paper presents the Particle Filter-Double Deep Q-Network (PF-DDQN) approach, which incorporates the Particle Filter (PF) into multi-AGV reinforcement learning path planning. The PF-DDQN method leverages the imprecise weight values of the network as state values to formulate the state space equation. Through the iterative fusion process of neural networks and particle filters, the DDQN model is optimized to acquire the optimal true weight values, thus enhancing the algorithm's efficiency. The proposed method's effectiveness and superiority are validated through numerical simulations. Overall, the simulation results demonstrate that the proposed algorithm surpasses the traditional DDQN algorithm in terms of path planning superiority and training time indicators by 92.62% and 76.88%, respectively. In conclusion, the PF-DDQN method addresses the challenges encountered by RL planning algorithms in AGV path planning. By integrating the Particle Filter and optimizing the DDQN model, the proposed method achieves enhanced efficiency and outperforms the traditional DDQN algorithm in terms of path planning superiority and training time indicators.
MedPromptX: Grounded Multimodal Prompting for Chest X-ray Diagnosis
Mar 29, 2024Chest X-ray images are commonly used for predicting acute and chronic cardiopulmonary conditions, but efforts to integrate them with structured clinical data face challenges due to incomplete electronic health records (EHR). This paper introduces MedPromptX, the first model to integrate multimodal large language models (MLLMs), few-shot prompting (FP) and visual grounding (VG) to combine imagery with EHR data for chest X-ray diagnosis. A pre-trained MLLM is utilized to complement the missing EHR information, providing a comprehensive understanding of patients' medical history. Additionally, FP reduces the necessity for extensive training of MLLMs while effectively tackling the issue of hallucination. Nevertheless, the process of determining the optimal number of few-shot examples and selecting high-quality candidates can be burdensome, yet it profoundly influences model performance. Hence, we propose a new technique that dynamically refines few-shot data for real-time adjustment to new patient scenarios. Moreover, VG aids in focusing the model's attention on relevant regions of interest in X-ray images, enhancing the identification of abnormalities. We release MedPromptX-VQA, a new in-context visual question answering dataset encompassing interleaved image and EHR data derived from MIMIC-IV and MIMIC-CXR databases. Results demonstrate the SOTA performance of MedPromptX, achieving an 11% improvement in F1-score compared to the baselines. Code and data are available at https://github.com/BioMedIA-MBZUAI/MedPromptX
NeSLAM: Neural Implicit Mapping and Self-Supervised Feature Tracking With Depth Completion and Denoising
Mar 29, 2024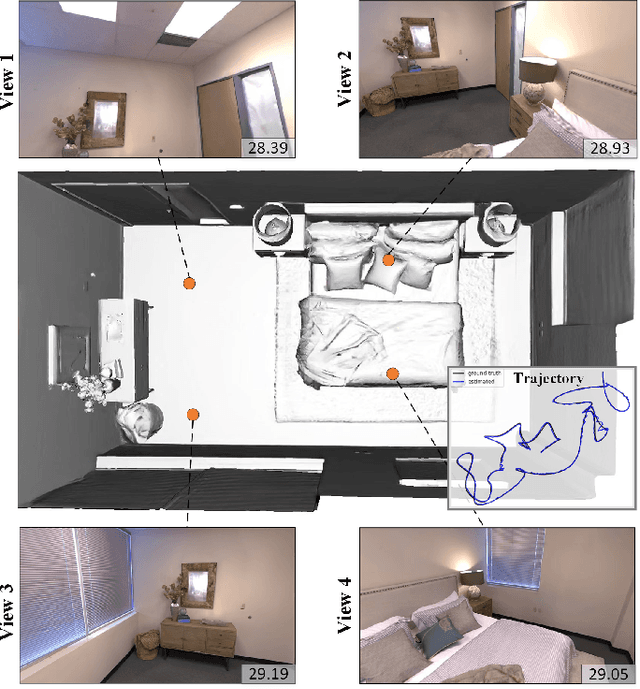



In recent years, there have been significant advancements in 3D reconstruction and dense RGB-D SLAM systems. One notable development is the application of Neural Radiance Fields (NeRF) in these systems, which utilizes implicit neural representation to encode 3D scenes. This extension of NeRF to SLAM has shown promising results. However, the depth images obtained from consumer-grade RGB-D sensors are often sparse and noisy, which poses significant challenges for 3D reconstruction and affects the accuracy of the representation of the scene geometry. Moreover, the original hierarchical feature grid with occupancy value is inaccurate for scene geometry representation. Furthermore, the existing methods select random pixels for camera tracking, which leads to inaccurate localization and is not robust in real-world indoor environments. To this end, we present NeSLAM, an advanced framework that achieves accurate and dense depth estimation, robust camera tracking, and realistic synthesis of novel views. First, a depth completion and denoising network is designed to provide dense geometry prior and guide the neural implicit representation optimization. Second, the occupancy scene representation is replaced with Signed Distance Field (SDF) hierarchical scene representation for high-quality reconstruction and view synthesis. Furthermore, we also propose a NeRF-based self-supervised feature tracking algorithm for robust real-time tracking. Experiments on various indoor datasets demonstrate the effectiveness and accuracy of the system in reconstruction, tracking quality, and novel view synthesis.
Unsupervised Tumor-Aware Distillation for Multi-Modal Brain Image Translation
Mar 29, 2024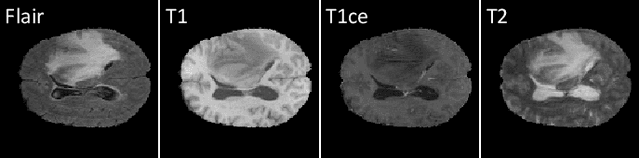
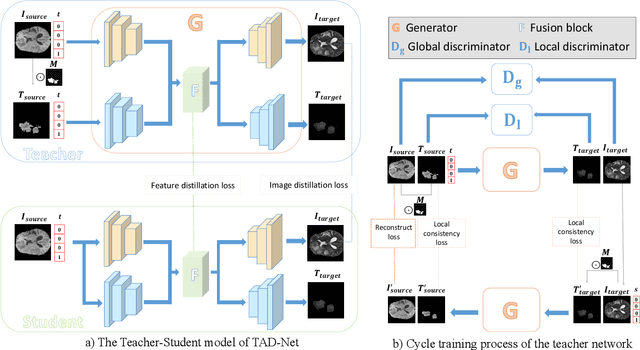
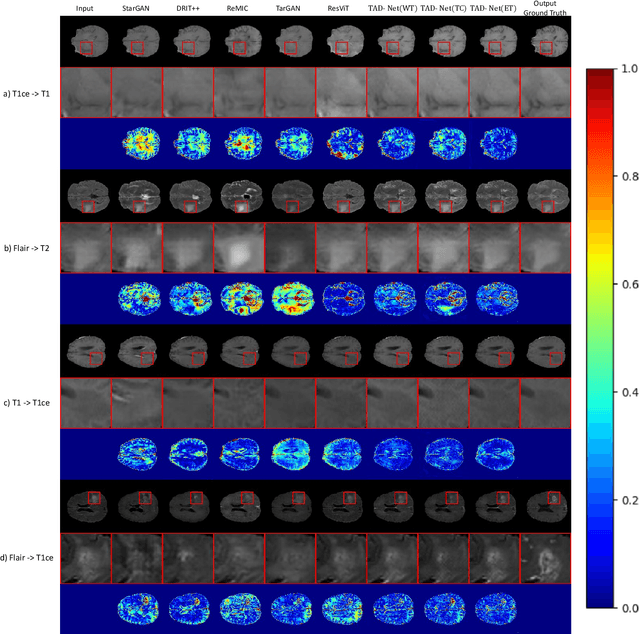

Multi-modal brain images from MRI scans are widely used in clinical diagnosis to provide complementary information from different modalities. However, obtaining fully paired multi-modal images in practice is challenging due to various factors, such as time, cost, and artifacts, resulting in modality-missing brain images. To address this problem, unsupervised multi-modal brain image translation has been extensively studied. Existing methods suffer from the problem of brain tumor deformation during translation, as they fail to focus on the tumor areas when translating the whole images. In this paper, we propose an unsupervised tumor-aware distillation teacher-student network called UTAD-Net, which is capable of perceiving and translating tumor areas precisely. Specifically, our model consists of two parts: a teacher network and a student network. The teacher network learns an end-to-end mapping from source to target modality using unpaired images and corresponding tumor masks first. Then, the translation knowledge is distilled into the student network, enabling it to generate more realistic tumor areas and whole images without masks. Experiments show that our model achieves competitive performance on both quantitative and qualitative evaluations of image quality compared with state-of-the-art methods. Furthermore, we demonstrate the effectiveness of the generated images on downstream segmentation tasks. Our code is available at https://github.com/scut-HC/UTAD-Net.
Improving Real-Time Omnidirectional 3D Multi-Person Human Pose Estimation with People Matching and Unsupervised 2D-3D Lifting
Mar 14, 2024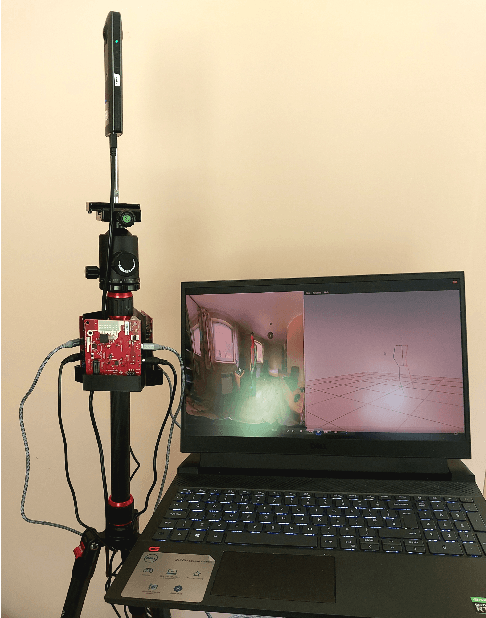
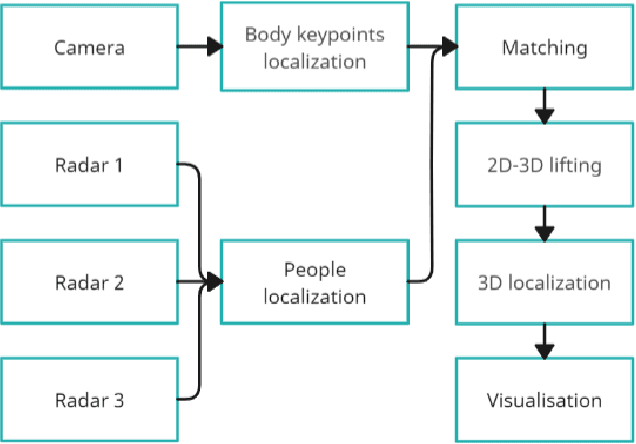
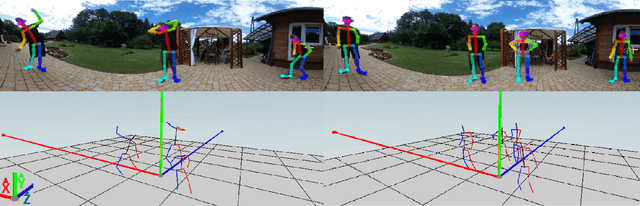
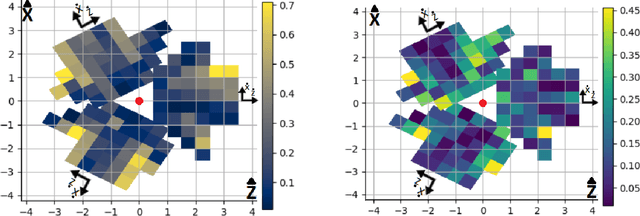
Current human pose estimation systems focus on retrieving an accurate 3D global estimate of a single person. Therefore, this paper presents one of the first 3D multi-person human pose estimation systems that is able to work in real-time and is also able to handle basic forms of occlusion. First, we adjust an off-the-shelf 2D detector and an unsupervised 2D-3D lifting model for use with a 360$^\circ$ panoramic camera and mmWave radar sensors. We then introduce several contributions, including camera and radar calibrations, and the improved matching of people within the image and radar space. The system addresses both the depth and scale ambiguity problems by employing a lightweight 2D-3D pose lifting algorithm that is able to work in real-time while exhibiting accurate performance in both indoor and outdoor environments which offers both an affordable and scalable solution. Notably, our system's time complexity remains nearly constant irrespective of the number of detected individuals, achieving a frame rate of approximately 7-8 fps on a laptop with a commercial-grade GPU.
PALM: Pushing Adaptive Learning Rate Mechanisms for Continual Test-Time Adaptation
Mar 15, 2024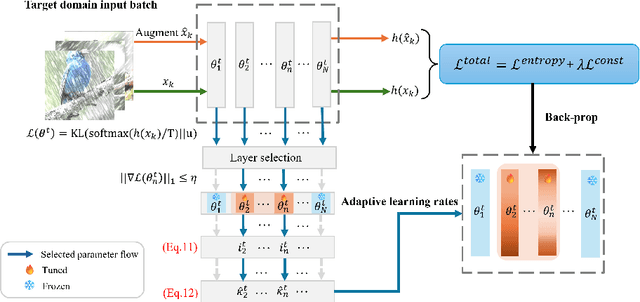
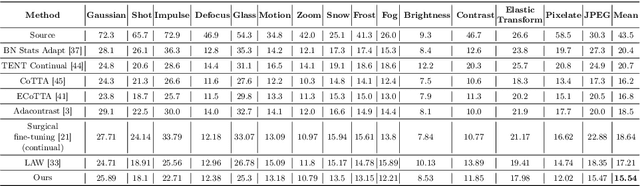
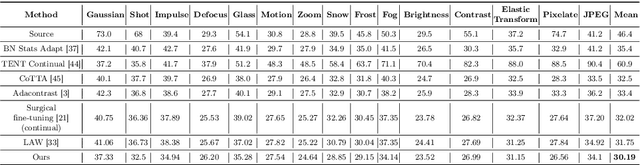
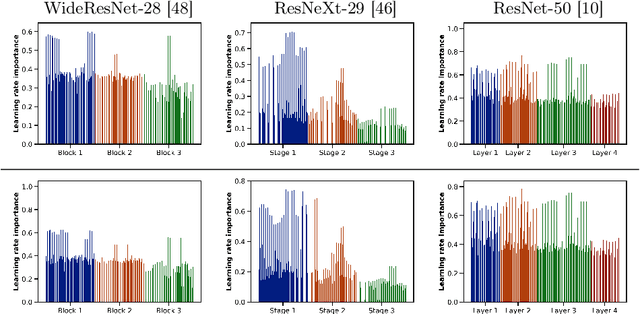
Real-world vision models in dynamic environments face rapid shifts in domain distributions, leading to decreased recognition performance. Continual test-time adaptation (CTTA) directly adjusts a pre-trained source discriminative model to these changing domains using test data. A highly effective CTTA method involves applying layer-wise adaptive learning rates, and selectively adapting pre-trained layers. However, it suffers from the poor estimation of domain shift and the inaccuracies arising from the pseudo-labels. In this work, we aim to overcome these limitations by identifying layers through the quantification of model prediction uncertainty without relying on pseudo-labels. We utilize the magnitude of gradients as a metric, calculated by backpropagating the KL divergence between the softmax output and a uniform distribution, to select layers for further adaptation. Subsequently, for the parameters exclusively belonging to these selected layers, with the remaining ones frozen, we evaluate their sensitivity in order to approximate the domain shift, followed by adjusting their learning rates accordingly. Overall, this approach leads to a more robust and stable optimization than prior approaches. We conduct extensive image classification experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C and demonstrate the efficacy of our method against standard benchmarks and prior methods.
Hyperparameter Tuning MLPs for Probabilistic Time Series Forecasting
Mar 07, 2024
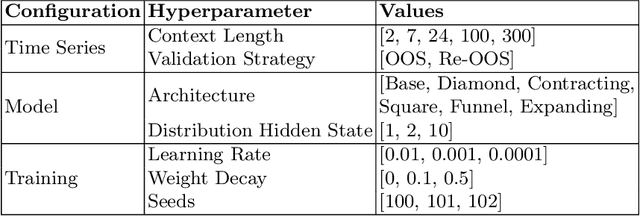
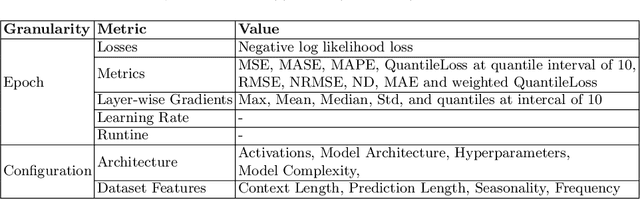
Time series forecasting attempts to predict future events by analyzing past trends and patterns. Although well researched, certain critical aspects pertaining to the use of deep learning in time series forecasting remain ambiguous. Our research primarily focuses on examining the impact of specific hyperparameters related to time series, such as context length and validation strategy, on the performance of the state-of-the-art MLP model in time series forecasting. We have conducted a comprehensive series of experiments involving 4800 configurations per dataset across 20 time series forecasting datasets, and our findings demonstrate the importance of tuning these parameters. Furthermore, in this work, we introduce the largest metadataset for timeseries forecasting to date, named TSBench, comprising 97200 evaluations, which is a twentyfold increase compared to previous works in the field. Finally, we demonstrate the utility of the created metadataset on multi-fidelity hyperparameter optimization tasks.
FPGA-Based Neural Thrust Controller for UAVs
Mar 28, 2024The advent of unmanned aerial vehicles (UAVs) has improved a variety of fields by providing a versatile, cost-effective and accessible platform for implementing state-of-the-art algorithms. To accomplish a broader range of tasks, there is a growing need for enhanced on-board computing to cope with increasing complexity and dynamic environmental conditions. Recent advances have seen the application of Deep Neural Networks (DNNs), particularly in combination with Reinforcement Learning (RL), to improve the adaptability and performance of UAVs, especially in unknown environments. However, the computational requirements of DNNs pose a challenge to the limited computing resources available on many UAVs. This work explores the use of Field Programmable Gate Arrays (FPGAs) as a viable solution to this challenge, offering flexibility, high performance, energy and time efficiency. We propose a novel hardware board equipped with an Artix-7 FPGA for a popular open-source micro-UAV platform. We successfully validate its functionality by implementing an RL-based low-level controller using real-world experiments.