 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth2Pose: A Pose-Based Benchmark for Monocular Depth Estimation without Ground-Truth Depth
May 19, 2026Monocular depth estimation has improved significantly in recent years, driven by increasingly powerful models and large-scale training data. Predicted depth is increasingly used as an input signal for downstream tasks such as Structure-from-Motion (SfM), visual localization, and SLAM. However, monocular depth estimators (MDEs) are still primarily evaluated in terms of depth accuracy. Standard metrics aggregate errors globally and may not reflect the usefulness of depth for downstream geometric tasks. We therefore propose Depth2Pose, a framework for evaluating MDEs in the context of downstream tasks. By combining depth predictions with feature correspondences in depth-aware geometric solvers, we use relative camera pose estimation accuracy as a task-driven proxy for depth quality. Traditional benchmarks require dense ground truth in the form of per-pixel depth, which is expensive to obtain. In contrast, our formulation requires only camera poses, which can be estimated efficiently, e.g., using Structure-from-Motion pipelines. As a result, our framework can be applied to scenes where ground-truth depth is difficult to obtain, for example due to large scene scale or heavy occlusions (e.g., vegetated environments). Leveraging this, we introduce the D2P dataset, which contains challenging scenes outside the distribution of commonly used training data. We show that methods performing well under standard depth error metrics on existing benchmarks also perform well under our pose-based metric when evaluated on the same datasets, but do not necessarily generalize to our more challenging dataset. Finally, we provide a simple and extensible evaluation framework. The dataset and code are available at kocurvik.github.io/depth2pose.
Visual Re-Ranking with Non-Visual Side Information
Apr 15, 2025The standard approach for visual place recognition is to use global image descriptors to retrieve the most similar database images for a given query image. The results can then be further improved with re-ranking methods that re-order the top scoring images. However, existing methods focus on re-ranking based on the same image descriptors that were used for the initial retrieval, which we argue provides limited additional signal. In this work we propose Generalized Contextual Similarity Aggregation (GCSA), which is a graph neural network-based re-ranking method that, in addition to the visual descriptors, can leverage other types of available side information. This can for example be other sensor data (such as signal strength of nearby WiFi or BlueTooth endpoints) or geometric properties such as camera poses for database images. In many applications this information is already present or can be acquired with low effort. Our architecture leverages the concept of affinity vectors to allow for a shared encoding of the heterogeneous multi-modal input. Two large-scale datasets, covering both outdoor and indoor localization scenarios, are utilized for training and evaluation. In experiments we show significant improvement not only on image retrieval metrics, but also for the downstream visual localization task.
Multi-Source Localization and Data Association for Time-Difference of Arrival Measurements
Mar 15, 2024


In this work, we consider the problem of localizing multiple signal sources based on time-difference of arrival (TDOA) measurements. In the blind setting, in which the source signals are not known, the localization task is challenging due to the data association problem. That is, it is not known which of the TDOA measurements correspond to the same source. Herein, we propose to perform joint localization and data association by means of an optimal transport formulation. The method operates by finding optimal groupings of TDOA measurements and associating these with candidate source locations. To allow for computationally feasible localization in three-dimensional space, an efficient set of candidate locations is constructed using a minimal multilateration solver based on minimal sets of receiver pairs. In numerical simulations, we demonstrate that the proposed method is robust both to measurement noise and TDOA detection errors. Furthermore, it is shown that the data association provided by the proposed method allows for statistically efficient estimates of the source locations.
Polygon Detection for Room Layout Estimation using Heterogeneous Graphs and Wireframes
Jun 21, 2023



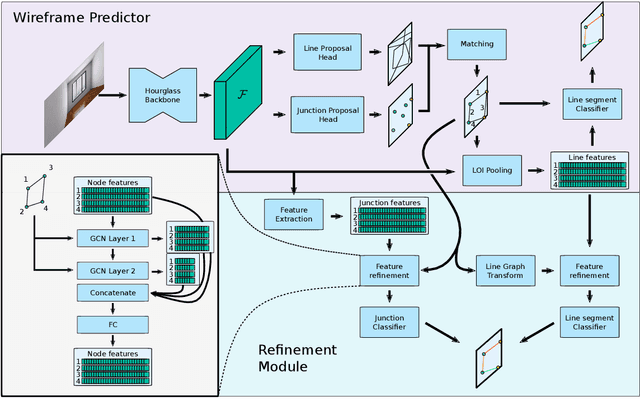
This paper presents a neural network based semantic plane detection method utilizing polygon representations. The method can for example be used to solve room layout estimations tasks. The method is built on, combines and further develops several different modules from previous research. The network takes an RGB image and estimates a wireframe as well as a feature space using an hourglass backbone. From these, line and junction features are sampled. The lines and junctions are then represented as an undirected graph, from which polygon representations of the sought planes are obtained. Two different methods for this last step are investigated, where the most promising method is built on a heterogeneous graph transformer. The final output is in all cases a projection of the semantic planes in 2D. The methods are evaluated on the Structured 3D dataset and we investigate the performance both using sampled and estimated wireframes. The experiments show the potential of the graph-based method by outperforming state of the art methods in Room Layout estimation in the 2D metrics using synthetic wireframe detections.
Semantic Room Wireframe Detection from a Single View
Jun 01, 2022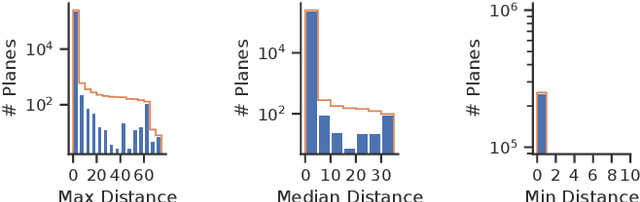
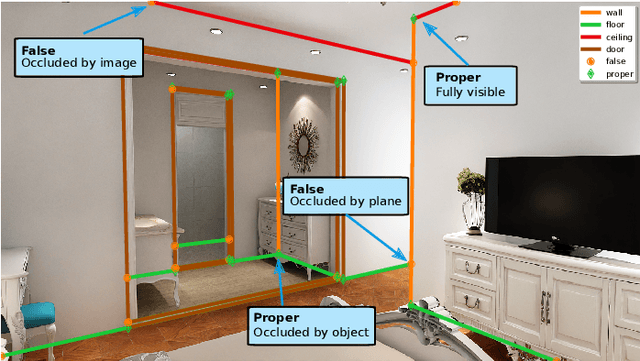
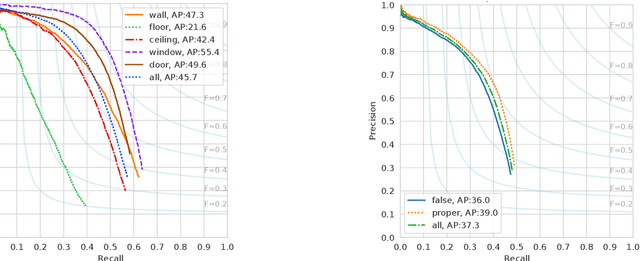
Reconstruction of indoor surfaces with limited texture information or with repeated textures, a situation common in walls and ceilings, may be difficult with a monocular Structure from Motion system. We propose a Semantic Room Wireframe Detection task to predict a Semantic Wireframe from a single perspective image. Such predictions may be used with shape priors to estimate the Room Layout and aid reconstruction. To train and test the proposed algorithm we create a new set of annotations from the simulated Structured3D dataset. We show qualitatively that the SRW-Net handles complex room geometries better than previous Room Layout Estimation algorithms while quantitatively out-performing the baseline in non-semantic Wireframe Detection.
Generic Merging of Structure from Motion Maps with a Low Memory Footprint
Mar 24, 2021
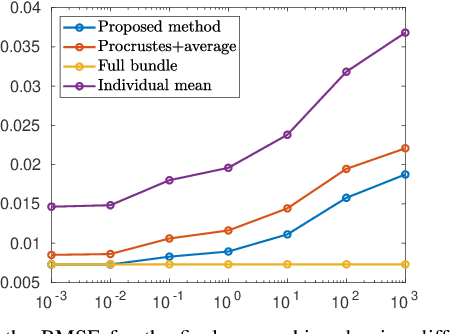
With the development of cheap image sensors, the amount of available image data have increased enormously, and the possibility of using crowdsourced collection methods has emerged. This calls for development of ways to handle all these data. In this paper, we present new tools that will enable efficient, flexible and robust map merging. Assuming that separate optimisations have been performed for the individual maps, we show how only relevant data can be stored in a low memory footprint representation. We use these representations to perform map merging so that the algorithm is invariant to the merging order and independent of the choice of coordinate system. The result is a robust algorithm that can be applied to several maps simultaneously. The result of a merge can also be represented with the same type of low-memory footprint format, which enables further merging and updating of the map in a hierarchical way. Furthermore, the method can perform loop closing and also detect changes in the scene between the capture of the different image sequences. Using both simulated and real data - from both a hand held mobile phone and from a drone - we verify the performance of the proposed method.