 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Control for Linear Dynamics: A Data-Driven Approach
Aug 16, 2023
This paper considers an online control problem over a linear time-invariant system with unknown dynamics, bounded disturbance, and adversarial cost. We propose a data-driven strategy to reduce the regret of the controller. Unlike model-based methods, our algorithm does not identify the system model, instead, it leverages a single noise-free trajectory to calculate the accumulation of disturbance and makes decisions using the accumulated disturbance action controller we design, whose parameters are updated by online gradient descent. We prove that the regret of our algorithm is $\mathcal{O}(\sqrt{T})$ under mild assumptions, suggesting that its performance is on par with model-based methods.
Extended Target Parameter Estimation and Tracking with an HDA Setup for ISAC Applications
Aug 16, 2023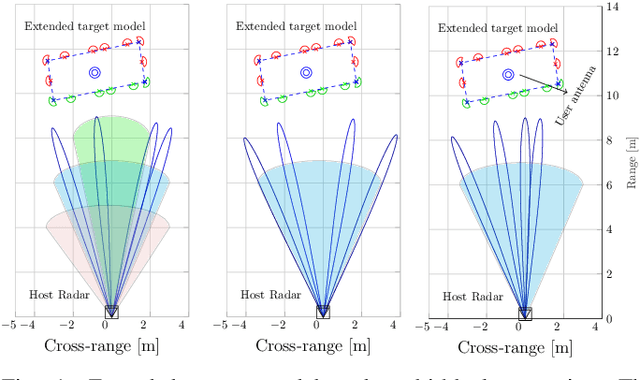
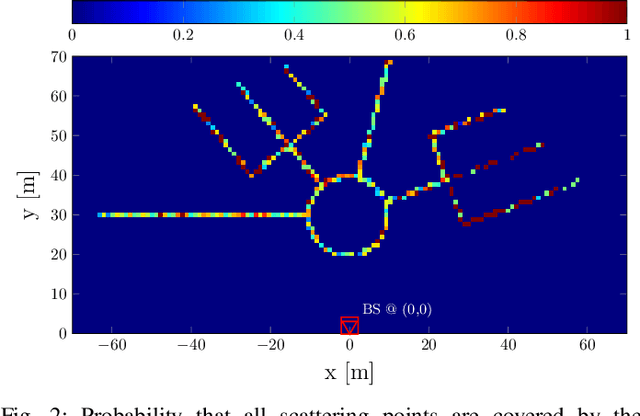
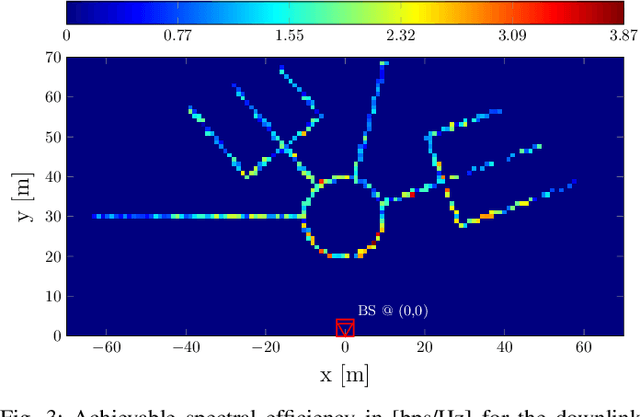
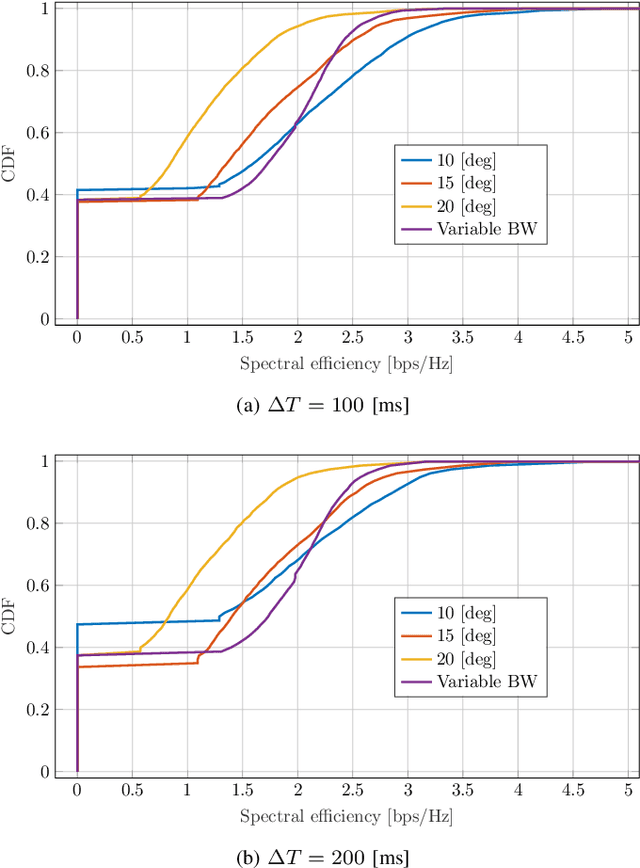
We investigate radar parameter estimation and beam tracking with a hybrid digital-analog (HDA) architecture in a multi-block measurement framework using an extended target model. In the considered setup, the backscattered data signal is utilized to predict the user position in the next time slots. Specifically, a simplified maximum likelihood framework is adopted for parameter estimation, based on which a simple tracking scheme is also developed. Furthermore, the proposed framework supports adaptive transmitter beamwidth selection, whose effects on the communication performance are also studied. Finally, we verify the effectiveness of the proposed framework via numerical simulations over complex motion patterns that emulate a realistic integrated sensing and communication (ISAC) scenario.
FECoM: A Step towards Fine-Grained Energy Measurement for Deep Learning
Aug 23, 2023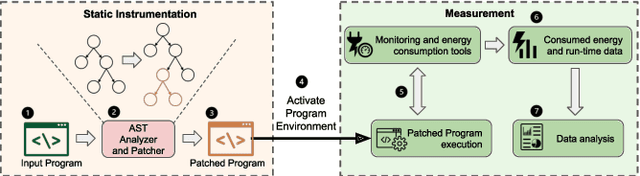
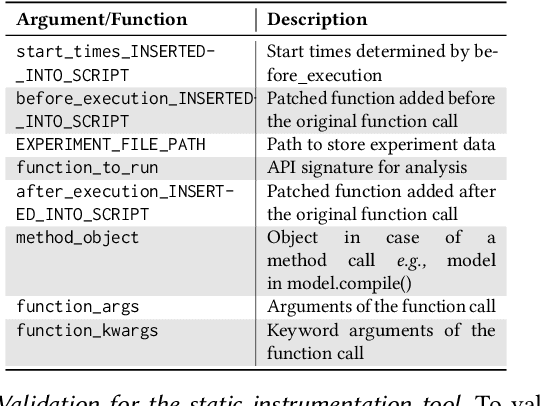
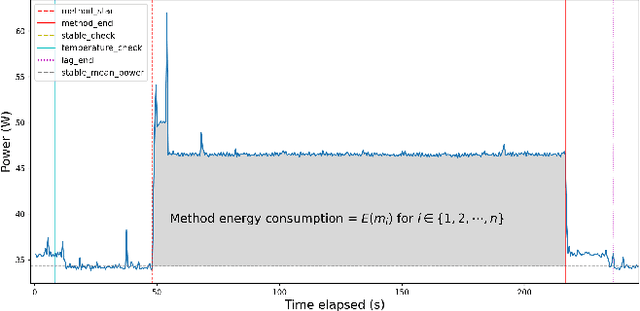
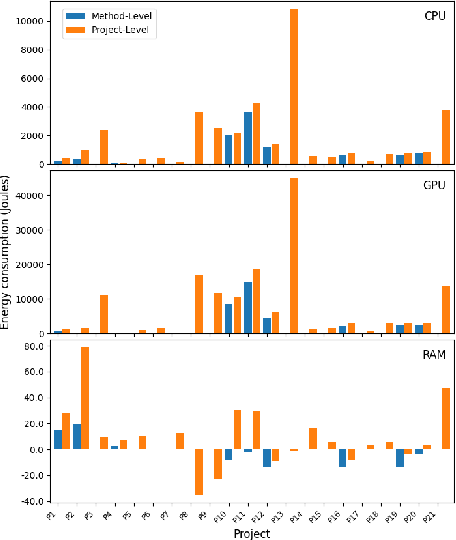
With the increasing usage, scale, and complexity of Deep Learning (DL) models, their rapidly growing energy consumption has become a critical concern. Promoting green development and energy awareness at different granularities is the need of the hour to limit carbon emissions of DL systems. However, the lack of standard and repeatable tools to accurately measure and optimize energy consumption at a fine granularity (e.g., at method level) hinders progress in this area. In this paper, we introduce FECoM (Fine-grained Energy Consumption Meter), a framework for fine-grained DL energy consumption measurement. Specifically, FECoM provides researchers and developers a mechanism to profile DL APIs. FECoM addresses the challenges of measuring energy consumption at fine-grained level by using static instrumentation and considering various factors, including computational load and temperature stability. We assess FECoM's capability to measure fine-grained energy consumption for one of the most popular open-source DL frameworks, namely TensorFlow. Using FECoM, we also investigate the impact of parameter size and execution time on energy consumption, enriching our understanding of TensorFlow APIs' energy profiles. Furthermore, we elaborate on the considerations, issues, and challenges that one needs to consider while designing and implementing a fine-grained energy consumption measurement tool. We hope this work will facilitate further advances in DL energy measurement and the development of energy-aware practices for DL systems.
Self-Deception: Reverse Penetrating the Semantic Firewall of Large Language Models
Aug 25, 2023

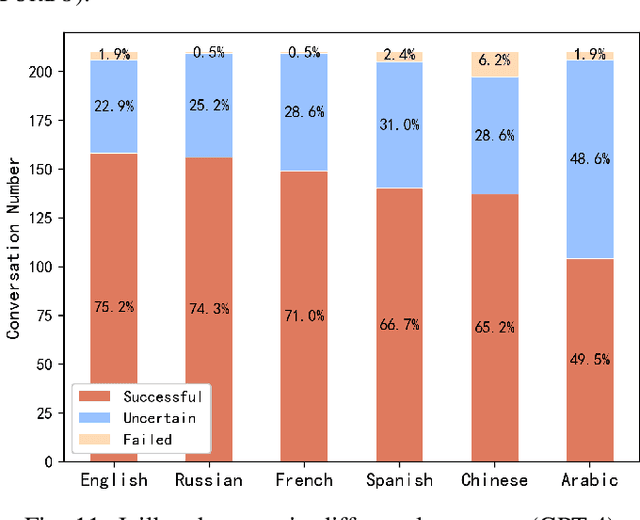
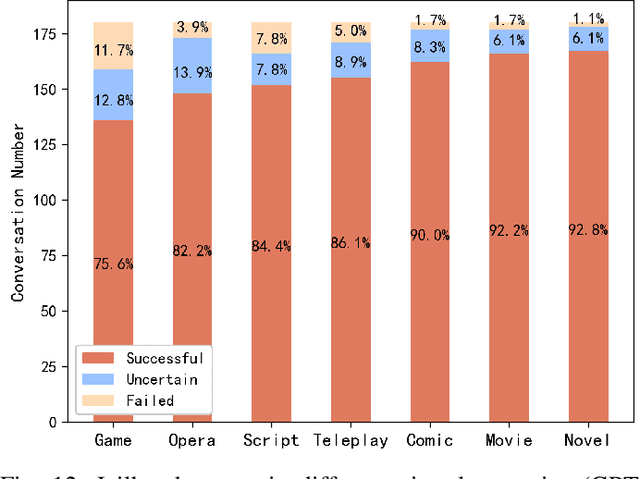
Large language models (LLMs), such as ChatGPT, have emerged with astonishing capabilities approaching artificial general intelligence. While providing convenience for various societal needs, LLMs have also lowered the cost of generating harmful content. Consequently, LLM developers have deployed semantic-level defenses to recognize and reject prompts that may lead to inappropriate content. Unfortunately, these defenses are not foolproof, and some attackers have crafted "jailbreak" prompts that temporarily hypnotize the LLM into forgetting content defense rules and answering any improper questions. To date, there is no clear explanation of the principles behind these semantic-level attacks and defenses in both industry and academia. This paper investigates the LLM jailbreak problem and proposes an automatic jailbreak method for the first time. We propose the concept of a semantic firewall and provide three technical implementation approaches. Inspired by the attack that penetrates traditional firewalls through reverse tunnels, we introduce a "self-deception" attack that can bypass the semantic firewall by inducing LLM to generate prompts that facilitate jailbreak. We generated a total of 2,520 attack payloads in six languages (English, Russian, French, Spanish, Chinese, and Arabic) across seven virtual scenarios, targeting the three most common types of violations: violence, hate, and pornography. The experiment was conducted on two models, namely the GPT-3.5-Turbo and GPT-4. The success rates on the two models were 86.2% and 67%, while the failure rates were 4.7% and 2.2%, respectively. This highlighted the effectiveness of the proposed attack method. All experimental code and raw data will be released as open-source to inspire future research. We believe that manipulating AI behavior through carefully crafted prompts will become an important research direction in the future.
6G goal-oriented communications: How to coexist with legacy systems?
Aug 25, 20236G will connect heterogeneous intelligent agents to make them operate complex cooperative tasks. When connecting intelligence, two main research questions arise to identify how AI and ML models behave depending on: i) their input data quality, affected by errors induced by interference and additive noise during wireless communication; ii) their contextual effectiveness and resilience to interpret and exploit the meaning behind the data. Both questions are within the realm of semantic and goal-oriented communications. With this paper we investigate how to effectively share spectrum resources between a legacy communication system and a new goal-oriented edge intelligence one. Specifically, we address the scenario of an eMBB service, i.e., a user uploading a video stream, interfering with an edge inference system, in which a user uploads images to a Mobile Edge Host that runs a classification task. Our objective is to achieve, through cooperation, the highest eMBB service data rate, subject to a targeted goal-effectiveness of the edge inference service, namely the probability of confident inference on time. We first formalize a general definition of a goal in the context of wireless communications. This includes the goal-effectiveness, as well as that of goal cost . We argue and show, through numerical evaluations, that communication reliability and goal-effectiveness are not straightforwardly linked. Then, after a performance evaluation aiming to clarify the difference between communication performance and goal-effectiveness, a long-term optimization problem is formulated and solved via Lyapunov optimization tools, to guarantee the desired performance. Finally, our numerical results assess the advantages of the proposed optimization, and the superiority of the goal-oriented strategy against baseline 5G compliant legacy approaches, under both stationary and non-stationary environments.
Discussion Paper: The Threat of Real Time Deepfakes
Jun 04, 2023
Generative deep learning models are able to create realistic audio and video. This technology has been used to impersonate the faces and voices of individuals. These ``deepfakes'' are being used to spread misinformation, enable scams, perform fraud, and blackmail the innocent. The technology continues to advance and today attackers have the ability to generate deepfakes in real-time. This new capability poses a significant threat to society as attackers begin to exploit the technology in advances social engineering attacks. In this paper, we discuss the implications of this emerging threat, identify the challenges with preventing these attacks and suggest a better direction for researching stronger defences.
A Hierarchical Descriptor Framework for On-the-Fly Anatomical Location Matching between Longitudinal Studies
Aug 11, 2023We propose a method to match anatomical locations between pairs of medical images in longitudinal comparisons. The matching is made possible by computing a descriptor of the query point in a source image based on a hierarchical sparse sampling of image intensities that encode the location information. Then, a hierarchical search operation finds the corresponding point with the most similar descriptor in the target image. This simple yet powerful strategy reduces the computational time of mapping points to a millisecond scale on a single CPU. Thus, radiologists can compare similar anatomical locations in near real-time without requiring extra architectural costs for precomputing or storing deformation fields from registrations. Our algorithm does not require prior training, resampling, segmentation, or affine transformation steps. We have tested our algorithm on the recently published Deep Lesion Tracking dataset annotations. We observed more accurate matching compared to Deep Lesion Tracker while being 24 times faster than the most precise algorithm reported therein. We also investigated the matching accuracy on CT and MR modalities and compared the proposed algorithm's accuracy against ground truth consolidated from multiple radiologists.
Causally Linking Health Application Data and Personal Information Management Tools
Aug 11, 2023The proliferation of consumer health devices such as smart watches, sleep monitors, smart scales, etc, in many countries, has not only led to growing interest in health monitoring, but also to the development of a countless number of ``smart'' applications to support the exploration of such data by members of the general public, sometimes with integration into professional health services. While a variety of health data streams has been made available by such devices to users, these streams are often presented as separate time-series visualizations, in which the potential relationships between health variables are not explicitly made visible. Furthermore, despite the fact that other aspects of life, such as work and social connectivity, have become increasingly digitised, health and well-being applications make little use of the potentially useful contextual information provided by widely used personal information management tools, such as shared calendar and email systems. This paper presents a framework for the integration of these diverse data sources, analytic and visualization tools, with inference methods and graphical user interfaces to help users by highlighting causal connections among such time-series.
RadGraph2: Modeling Disease Progression in Radiology Reports via Hierarchical Information Extraction
Aug 09, 2023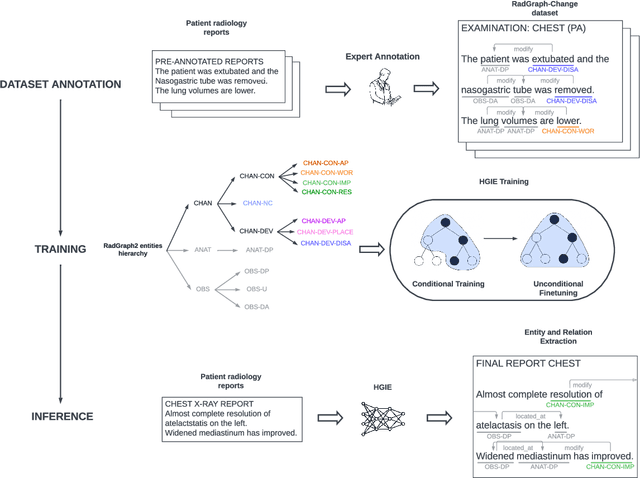
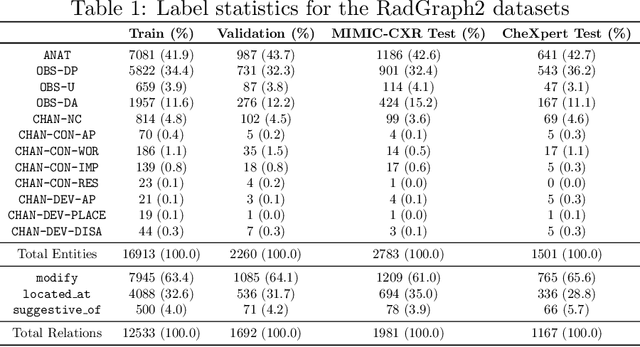
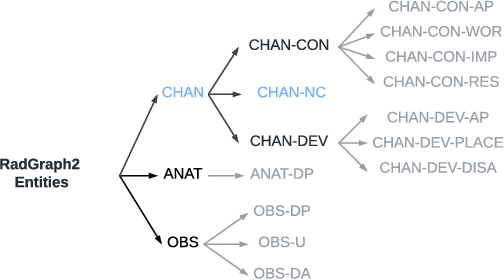
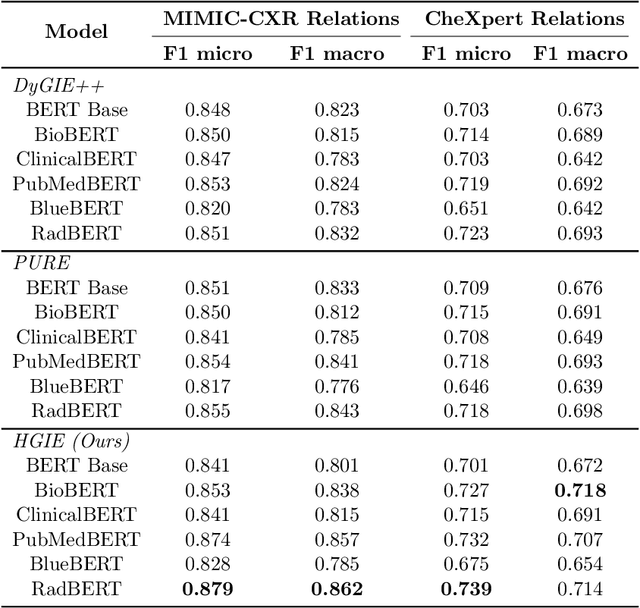
We present RadGraph2, a novel dataset for extracting information from radiology reports that focuses on capturing changes in disease state and device placement over time. We introduce a hierarchical schema that organizes entities based on their relationships and show that using this hierarchy during training improves the performance of an information extraction model. Specifically, we propose a modification to the DyGIE++ framework, resulting in our model HGIE, which outperforms previous models in entity and relation extraction tasks. We demonstrate that RadGraph2 enables models to capture a wider variety of findings and perform better at relation extraction compared to those trained on the original RadGraph dataset. Our work provides the foundation for developing automated systems that can track disease progression over time and develop information extraction models that leverage the natural hierarchy of labels in the medical domain.
Conformer-based Target-Speaker Automatic Speech Recognition for Single-Channel Audio
Aug 09, 2023
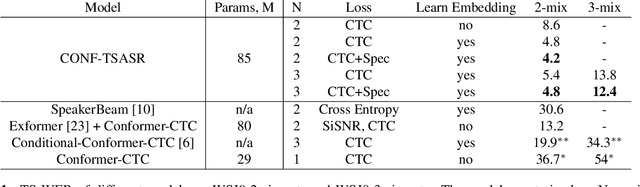
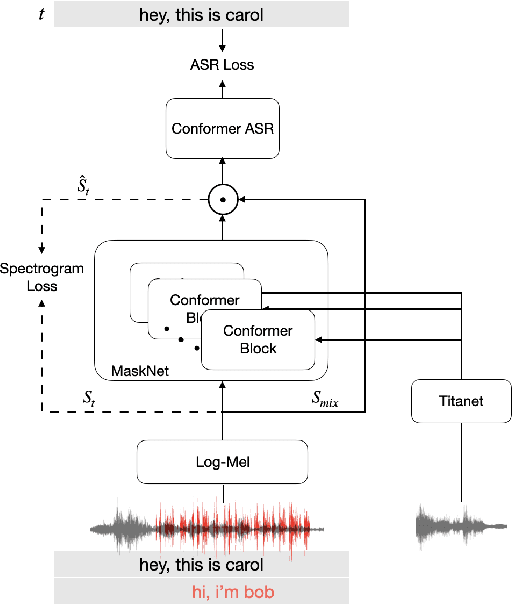
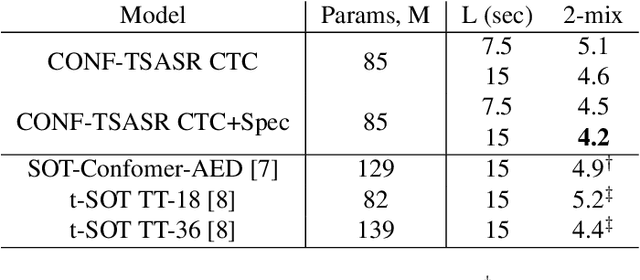
We propose CONF-TSASR, a non-autoregressive end-to-end time-frequency domain architecture for single-channel target-speaker automatic speech recognition (TS-ASR). The model consists of a TitaNet based speaker embedding module, a Conformer based masking as well as ASR modules. These modules are jointly optimized to transcribe a target-speaker, while ignoring speech from other speakers. For training we use Connectionist Temporal Classification (CTC) loss and introduce a scale-invariant spectrogram reconstruction loss to encourage the model better separate the target-speaker's spectrogram from mixture. We obtain state-of-the-art target-speaker word error rate (TS-WER) on WSJ0-2mix-extr (4.2%). Further, we report for the first time TS-WER on WSJ0-3mix-extr (12.4%), LibriSpeech2Mix (4.2%) and LibriSpeech3Mix (7.6%) datasets, establishing new benchmarks for TS-ASR. The proposed model will be open-sourced through NVIDIA NeMo toolkit.