 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalized Medical Image Representations through Image-Graph Contrastive Pretraining
May 15, 2024



Medical image interpretation using deep learning has shown promise but often requires extensive expert-annotated datasets. To reduce this annotation burden, we develop an Image-Graph Contrastive Learning framework that pairs chest X-rays with structured report knowledge graphs automatically extracted from radiology notes. Our approach uniquely encodes the disconnected graph components via a relational graph convolution network and transformer attention. In experiments on the CheXpert dataset, this novel graph encoding strategy enabled the framework to outperform existing methods that use image-text contrastive learning in 1% linear evaluation and few-shot settings, while achieving comparable performance to radiologists. By exploiting unlabeled paired images and text, our framework demonstrates the potential of structured clinical insights to enhance contrastive learning for medical images. This work points toward reducing demands on medical experts for annotations, improving diagnostic precision, and advancing patient care through robust medical image understanding.
RadGraph2: Modeling Disease Progression in Radiology Reports via Hierarchical Information Extraction
Aug 09, 2023



We present RadGraph2, a novel dataset for extracting information from radiology reports that focuses on capturing changes in disease state and device placement over time. We introduce a hierarchical schema that organizes entities based on their relationships and show that using this hierarchy during training improves the performance of an information extraction model. Specifically, we propose a modification to the DyGIE++ framework, resulting in our model HGIE, which outperforms previous models in entity and relation extraction tasks. We demonstrate that RadGraph2 enables models to capture a wider variety of findings and perform better at relation extraction compared to those trained on the original RadGraph dataset. Our work provides the foundation for developing automated systems that can track disease progression over time and develop information extraction models that leverage the natural hierarchy of labels in the medical domain.
Computer Vision User Entity Behavior Analytics
Dec 24, 2021

Insider threats are costly, hard to detect, and unfortunately rising in occurrence. Seeking to improve detection of such threats, we develop novel techniques to enable us to extract powerful features, generate high quality image encodings, and augment attack vectors for greater classification power. Combined, they form Computer Vision User and Entity Behavior Analytics, a detection system designed from the ground up to improve upon advancements in academia and mitigate the issues that prevent the usage of advanced models in industry. The proposed system beats state-of-art methods used in academia and as well as in industry.
Conical Classification For Computationally Efficient One-Class Topic Determination
Oct 31, 2021
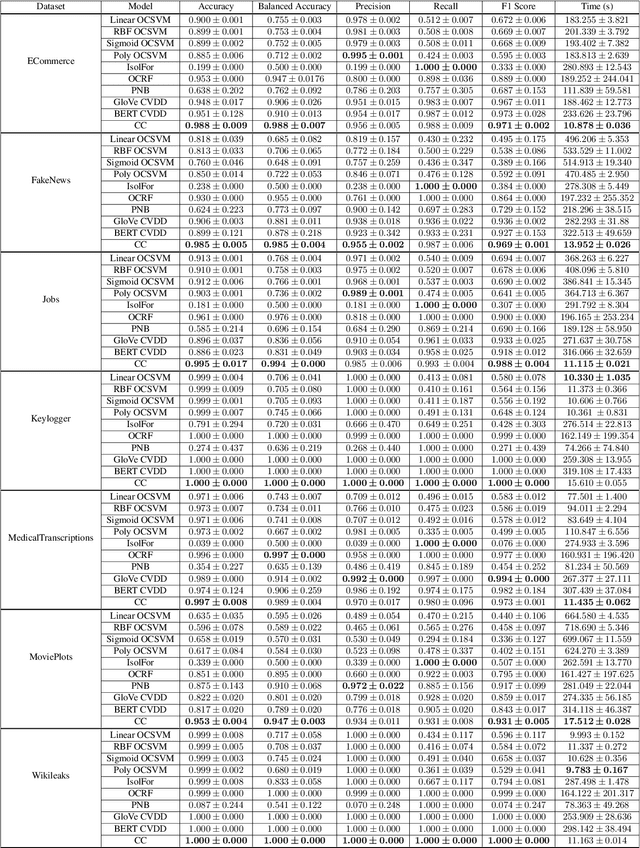
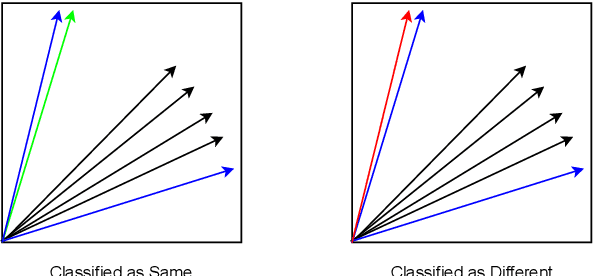
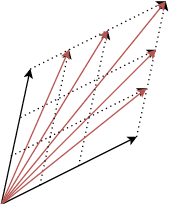
As the Internet grows in size, so does the amount of text based information that exists. For many application spaces it is paramount to isolate and identify texts that relate to a particular topic. While one-class classification would be ideal for such analysis, there is a relative lack of research regarding efficient approaches with high predictive power. By noting that the range of documents we wish to identify can be represented as positive linear combinations of the Vector Space Model representing our text, we propose Conical classification, an approach that allows us to identify if a document is of a particular topic in a computationally efficient manner. We also propose Normal Exclusion, a modified version of Bi-Normal Separation that makes it more suitable within the one-class classification context. We show in our analysis that our approach not only has higher predictive power on our datasets, but is also faster to compute.