 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Interpretation of Time-Series Deep Models: A Survey
May 23, 2023

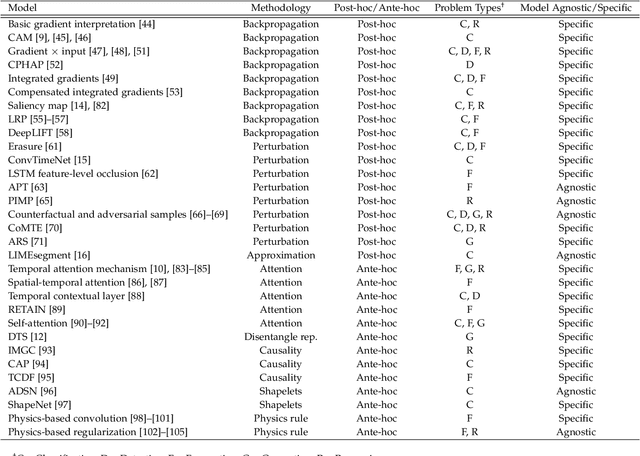
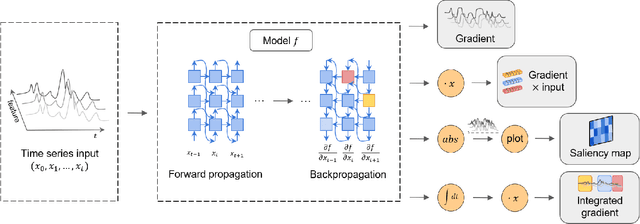
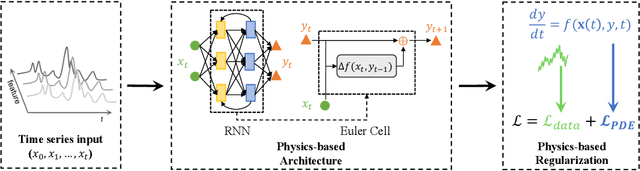
Deep learning models developed for time-series associated tasks have become more widely researched nowadays. However, due to the unintuitive nature of time-series data, the interpretability problem -- where we understand what is under the hood of these models -- becomes crucial. The advancement of similar studies in computer vision has given rise to many post-hoc methods, which can also shed light on how to explain time-series models. In this paper, we present a wide range of post-hoc interpretation methods for time-series models based on backpropagation, perturbation, and approximation. We also want to bring focus onto inherently interpretable models, a novel category of interpretation where human-understandable information is designed within the models. Furthermore, we introduce some common evaluation metrics used for the explanations, and propose several directions of future researches on the time-series interpretability problem. As a highlight, our work summarizes not only the well-established interpretation methods, but also a handful of fairly recent and under-developed techniques, which we hope to capture their essence and spark future endeavours to innovate and improvise.
Autonomous Underwater Robotic System for Aquaculture Applications
Aug 26, 2023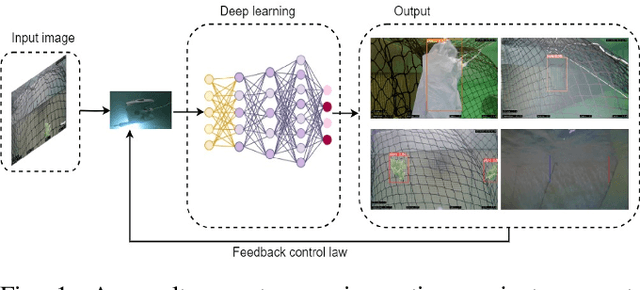
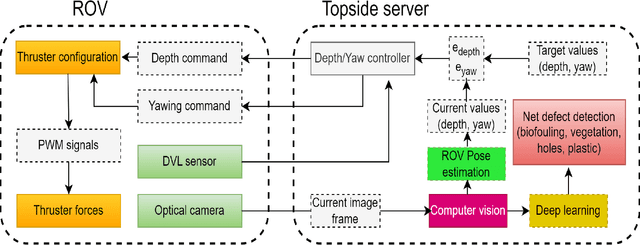
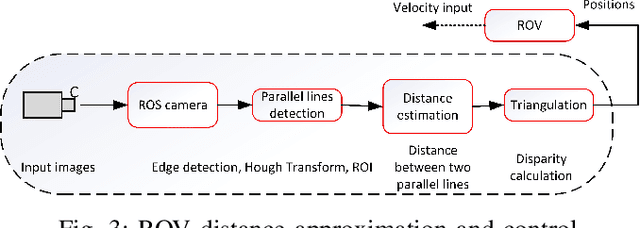

Aquaculture is a thriving food-producing sector producing over half of the global fish consumption. However, these aquafarms pose significant challenges such as biofouling, vegetation, and holes within their net pens and have a profound effect on the efficiency and sustainability of fish production. Currently, divers and/or remotely operated vehicles are deployed for inspecting and maintaining aquafarms; this approach is expensive and requires highly skilled human operators. This work aims to develop a robotic-based automatic net defect detection system for aquaculture net pens oriented to on- ROV processing and real-time detection of different aqua-net defects such as biofouling, vegetation, net holes, and plastic. The proposed system integrates both deep learning-based methods for aqua-net defect detection and feedback control law for the vehicle movement around the aqua-net to obtain a clear sequence of net images and inspect the status of the net via performing the inspection tasks. This work contributes to the area of aquaculture inspection, marine robotics, and deep learning aiming to reduce cost, improve quality, and ease of operation.
HoloPOCUS: Portable Mixed-Reality 3D Ultrasound Tracking, Reconstruction and Overlay
Aug 26, 2023Ultrasound (US) imaging provides a safe and accessible solution to procedural guidance and diagnostic imaging. The effective usage of conventional 2D US for interventional guidance requires extensive experience to project the image plane onto the patient, and the interpretation of images in diagnostics suffers from high intra- and inter-user variability. 3D US reconstruction allows for more consistent diagnosis and interpretation, but existing solutions are limited in terms of equipment and applicability in real-time navigation. To address these issues, we propose HoloPOCUS - a mixed reality US system (MR-US) that overlays rich US information onto the user's vision in a point-of-care setting. HoloPOCUS extends existing MR-US methods beyond placing a US plane in the user's vision to include a 3D reconstruction and projection that can aid in procedural guidance using conventional probes. We validated a tracking pipeline that demonstrates higher accuracy compared to existing MR-US works. Furthermore, user studies conducted via a phantom task showed significant improvements in navigation duration when using our proposed methods.
Business Metric-Aware Forecasting for Inventory Management
Aug 24, 2023Time-series forecasts play a critical role in business planning. However, forecasters typically optimize objectives that are agnostic to downstream business goals and thus can produce forecasts misaligned with business preferences. In this work, we demonstrate that optimization of conventional forecasting metrics can often lead to sub-optimal downstream business performance. Focusing on the inventory management setting, we derive an efficient procedure for computing and optimizing proxies of common downstream business metrics in an end-to-end differentiable manner. We explore a wide range of plausible cost trade-off scenarios, and empirically demonstrate that end-to-end optimization often outperforms optimization of standard business-agnostic forecasting metrics (by up to 45.7% for a simple scaling model, and up to 54.0% for an LSTM encoder-decoder model). Finally, we discuss how our findings could benefit other business contexts.
On Chernoff Lower-Bound of Outage Threshold for Non-Central $χ^2$-Distributed MIMO Beamforming Gain
Aug 24, 2023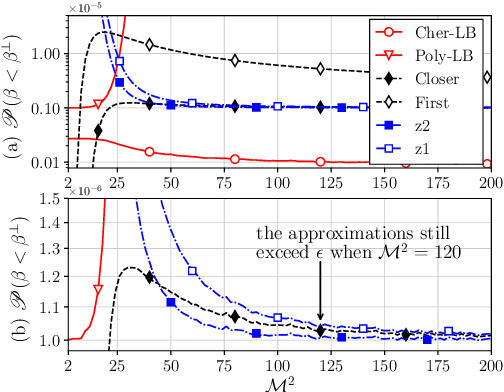
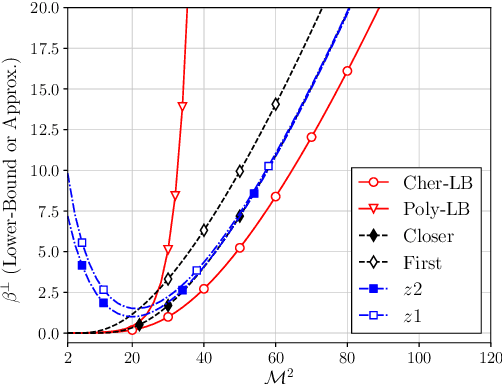
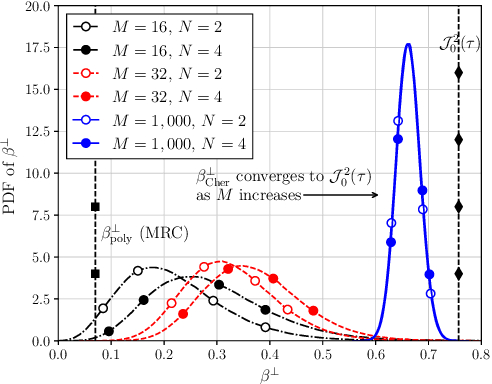
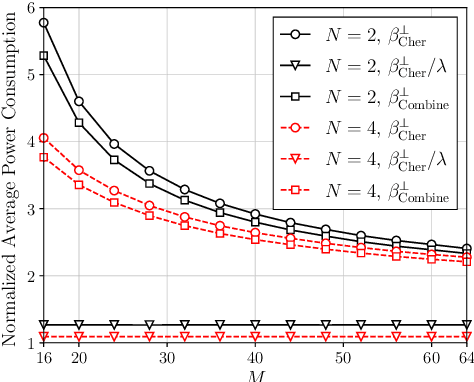
The cumulative distribution function (CDF) of a non-central $\chi^2$-distributed random variable (RV) is often used when measuring the outage probability of communication systems. For adaptive transmitters, it is important but mathematically challenging to determine the outage threshold for an extreme target outage probability (e.g., $10^{-5}$ or less). This motivates us to investigate lower bounds of the outage threshold, and it is found that the one derived from the Chernoff inequality (named Cher-LB) is the most {effective} lower bound. The Cher-LB is then employed to predict the multi-antenna transmitter beamforming-gain in ultra-reliable and low-latency communication, concerning the first-order Markov time-varying channel. It is exhibited that, with the proposed Cher-LB, pessimistic prediction of the beamforming gain is made sufficiently accurate for guaranteed reliability as well as the transmit-energy efficiency.
Everything, Everywhere All in One Evaluation: Using Multiverse Analysis to Evaluate the Influence of Model Design Decisions on Algorithmic Fairness
Aug 31, 2023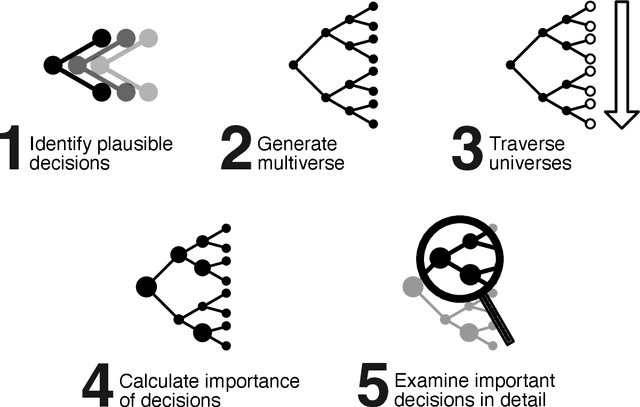
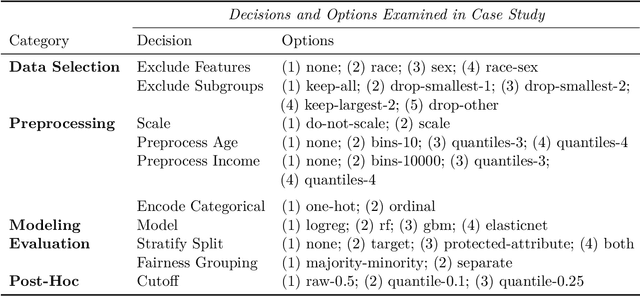
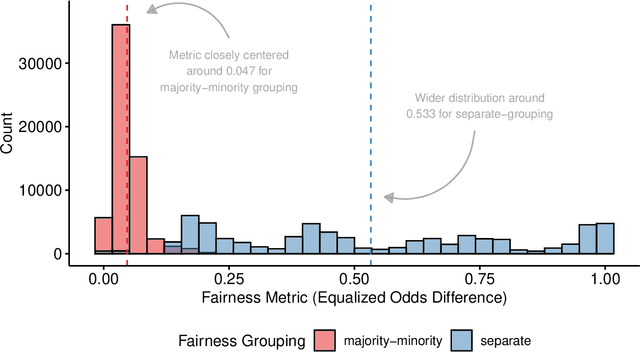
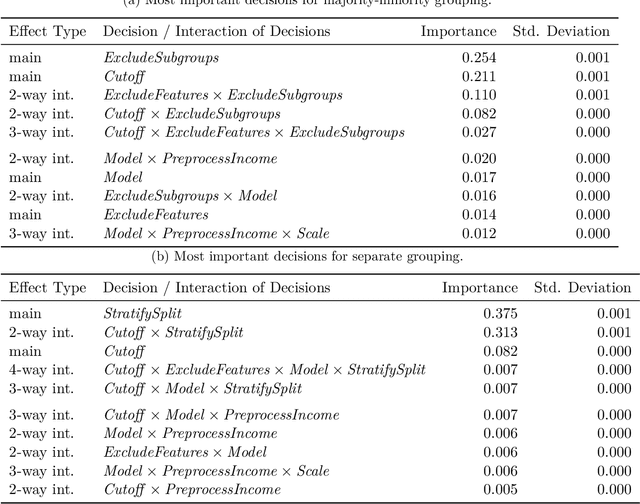
A vast number of systems across the world use algorithmic decision making (ADM) to (partially) automate decisions that have previously been made by humans. When designed well, these systems promise more objective decisions while saving large amounts of resources and freeing up human time. However, when ADM systems are not designed well, they can lead to unfair decisions which discriminate against societal groups. The downstream effects of ADMs critically depend on the decisions made during the systems' design and implementation, as biases in data can be mitigated or reinforced along the modeling pipeline. Many of these design decisions are made implicitly, without knowing exactly how they will influence the final system. It is therefore important to make explicit the decisions made during the design of ADM systems and understand how these decisions affect the fairness of the resulting system. To study this issue, we draw on insights from the field of psychology and introduce the method of multiverse analysis for algorithmic fairness. In our proposed method, we turn implicit design decisions into explicit ones and demonstrate their fairness implications. By combining decisions, we create a grid of all possible "universes" of decision combinations. For each of these universes, we compute metrics of fairness and performance. Using the resulting dataset, one can see how and which decisions impact fairness. We demonstrate how multiverse analyses can be used to better understand variability and robustness of algorithmic fairness using an exemplary case study of predicting public health coverage of vulnerable populations for potential interventions. Our results illustrate how decisions during the design of a machine learning system can have surprising effects on its fairness and how to detect these effects using multiverse analysis.
A Game of Bundle Adjustment -- Learning Efficient Convergence
Aug 25, 2023
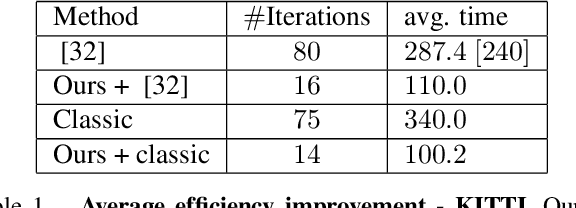
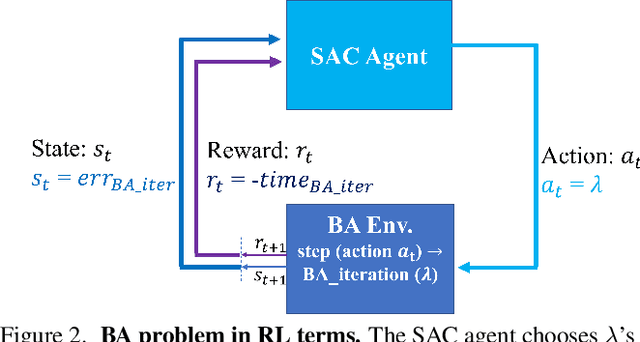
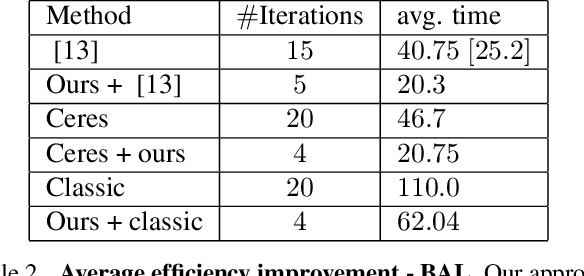
Bundle adjustment is the common way to solve localization and mapping. It is an iterative process in which a system of non-linear equations is solved using two optimization methods, weighted by a damping factor. In the classic approach, the latter is chosen heuristically by the Levenberg-Marquardt algorithm on each iteration. This might take many iterations, making the process computationally expensive, which might be harmful to real-time applications. We propose to replace this heuristic by viewing the problem in a holistic manner, as a game, and formulating it as a reinforcement-learning task. We set an environment which solves the non-linear equations and train an agent to choose the damping factor in a learned manner. We demonstrate that our approach considerably reduces the number of iterations required to reach the bundle adjustment's convergence, on both synthetic and real-life scenarios. We show that this reduction benefits the classic approach and can be integrated with other bundle adjustment acceleration methods.
Stochastic Configuration Machines for Industrial Artificial Intelligence
Aug 25, 2023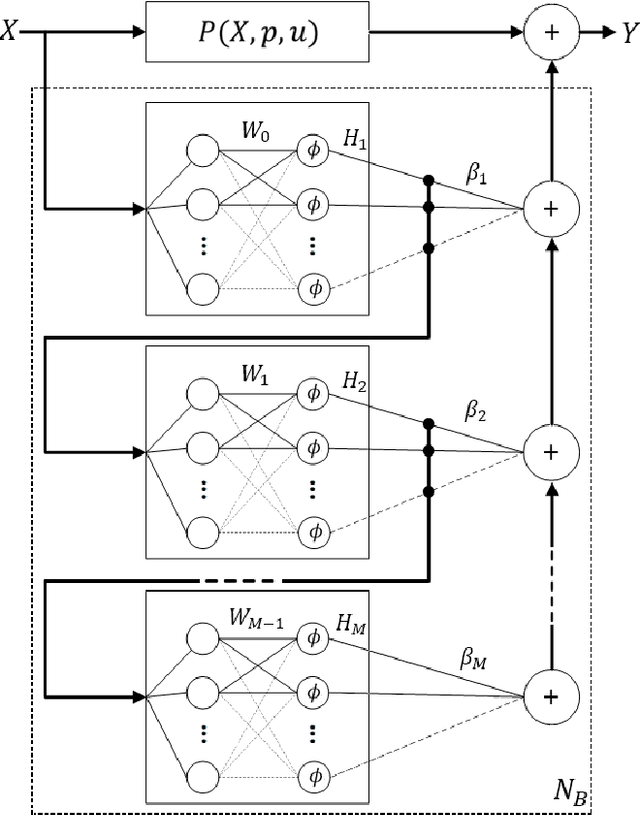
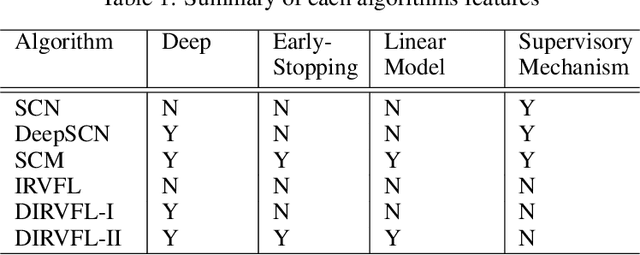
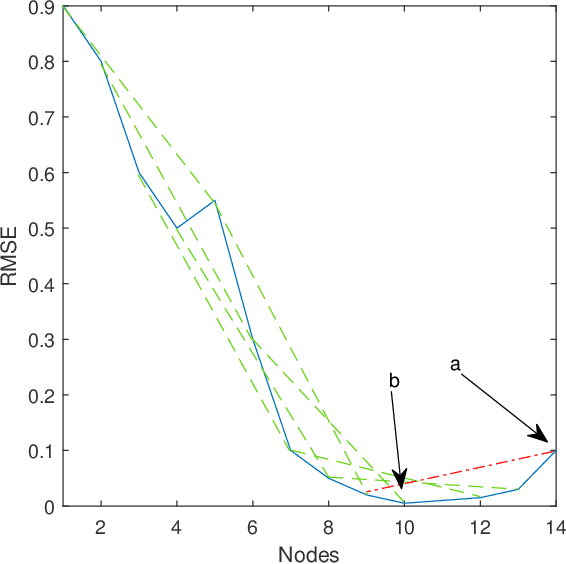
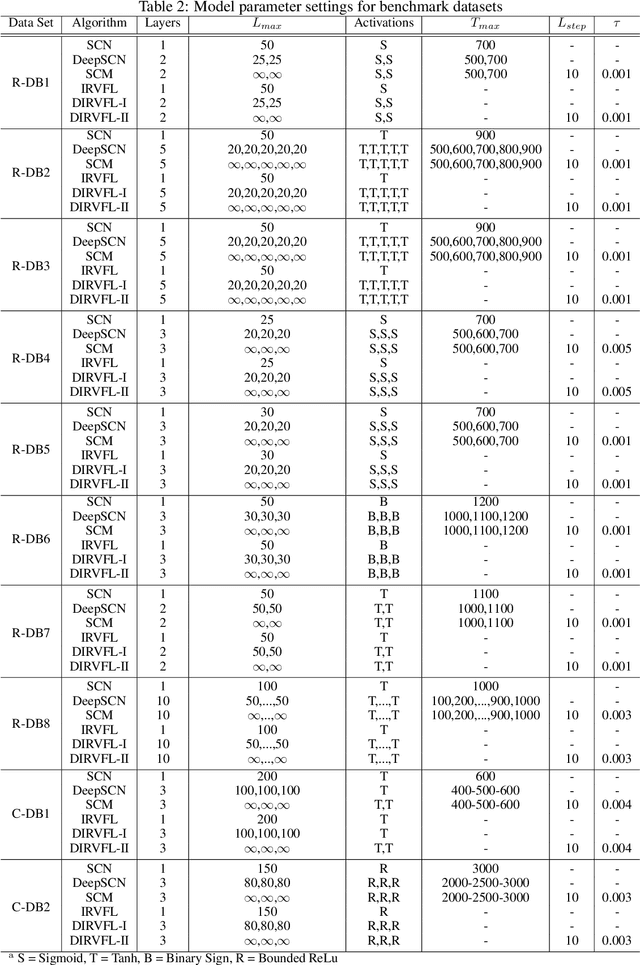
Real-time predictive modelling with desired accuracy is highly expected in industrial artificial intelligence (IAI), where neural networks play a key role. Neural networks in IAI require powerful, high-performance computing devices to operate a large number of floating point data. Based on stochastic configuration networks (SCNs), this paper proposes a new randomized learner model, termed stochastic configuration machines (SCMs), to stress effective modelling and data size saving that are useful and valuable for industrial applications. Compared to SCNs and random vector functional-link (RVFL) nets with binarized implementation, the model storage of SCMs can be significantly compressed while retaining favourable prediction performance. Besides the architecture of the SCM learner model and its learning algorithm, as an important part of this contribution, we also provide a theoretical basis on the learning capacity of SCMs by analysing the model's complexity. Experimental studies are carried out over some benchmark datasets and three industrial applications. The results demonstrate that SCM has great potential for dealing with industrial data analytics.
SGMM: Stochastic Approximation to Generalized Method of Moments
Aug 25, 2023We introduce a new class of algorithms, Stochastic Generalized Method of Moments (SGMM), for estimation and inference on (overidentified) moment restriction models. Our SGMM is a novel stochastic approximation alternative to the popular Hansen (1982) (offline) GMM, and offers fast and scalable implementation with the ability to handle streaming datasets in real time. We establish the almost sure convergence, and the (functional) central limit theorem for the inefficient online 2SLS and the efficient SGMM. Moreover, we propose online versions of the Durbin-Wu-Hausman and Sargan-Hansen tests that can be seamlessly integrated within the SGMM framework. Extensive Monte Carlo simulations show that as the sample size increases, the SGMM matches the standard (offline) GMM in terms of estimation accuracy and gains over computational efficiency, indicating its practical value for both large-scale and online datasets. We demonstrate the efficacy of our approach by a proof of concept using two well known empirical examples with large sample sizes.
Representing Timed Automata and Timing Anomalies of Cyber-Physical Production Systems in Knowledge Graphs
Aug 25, 2023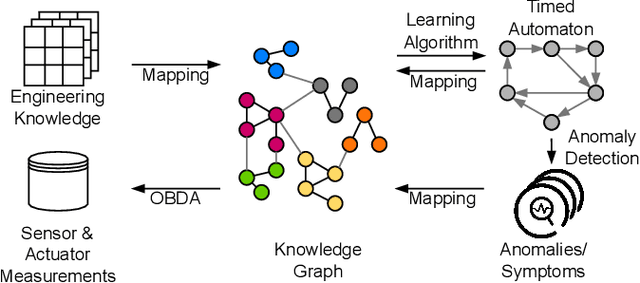
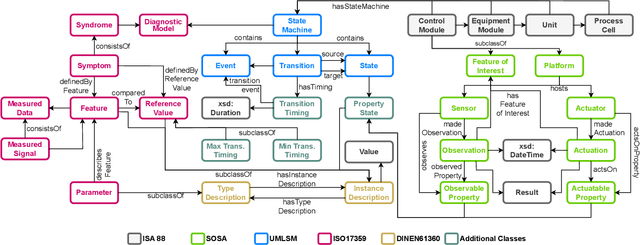
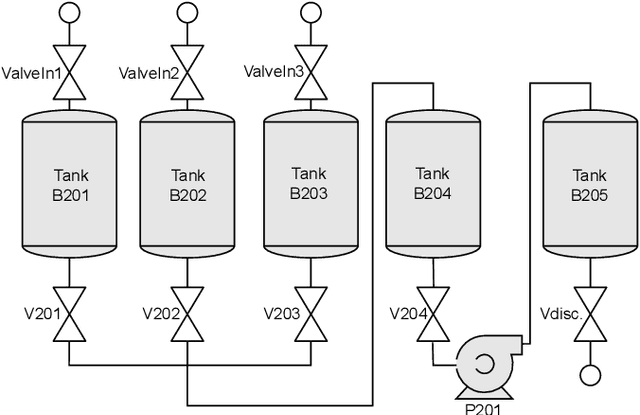
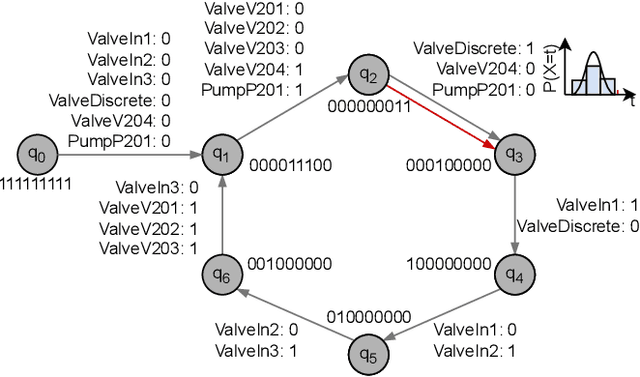
Model-Based Anomaly Detection has been a successful approach to identify deviations from the expected behavior of Cyber-Physical Production Systems. Since manual creation of these models is a time-consuming process, it is advantageous to learn them from data and represent them in a generic formalism like timed automata. However, these models - and by extension, the detected anomalies - can be challenging to interpret due to a lack of additional information about the system. This paper aims to improve model-based anomaly detection in CPPS by combining the learned timed automaton with a formal knowledge graph about the system. Both the model and the detected anomalies are described in the knowledge graph in order to allow operators an easier interpretation of the model and the detected anomalies. The authors additionally propose an ontology of the necessary concepts. The approach was validated on a five-tank mixing CPPS and was able to formally define both automata model as well as timing anomalies in automata execution.