 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Swarm Bug Algorithms for Path Generation in Unknown Environments
Aug 15, 2023
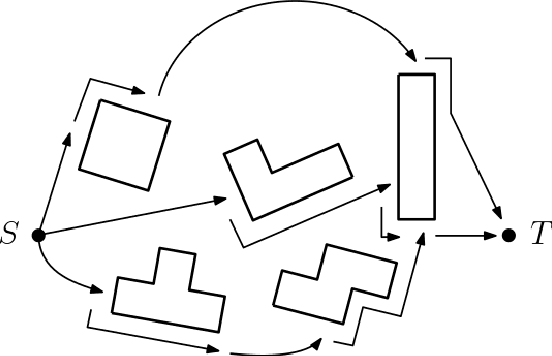
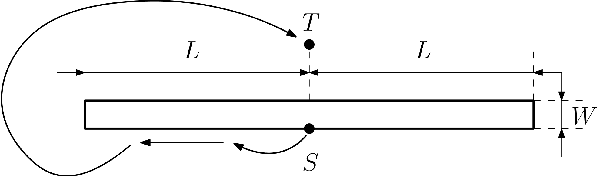
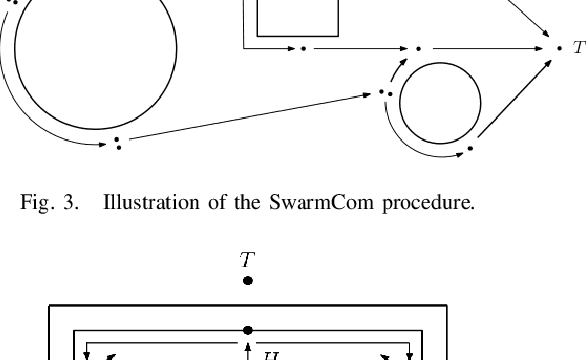
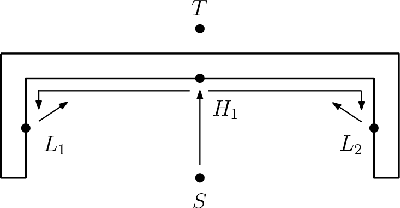
In this paper, we consider the problem of a swarm traveling between two points as fast as possible in an unknown environment cluttered with obstacles. Potential applications include search-and-rescue operations where damaged environments are typical. We present swarm generalizations, called SwarmCom, SwarmBug1, and SwarmBug2, of the classical path generation algorithms Com, Bug1, and Bug2. These algorithms were developed for unknown environments and require low computational power and memory storage, thereby freeing up resources for other tasks. We show the upper bound of the worst-case travel time for the first agent in the swarm to reach the target point for SwarmBug1. For SwarmBug2, we show that the algorithm underperforms in terms of worst-case travel time compared to SwarmBug1. For SwarmCom, we show that there exists a trivial scene for which the algorithm will not halt, and it thus has no performance guarantees. Moreover, by comparing the upper bound of the travel time for SwarmBug1 with a universal lower bound for any path generation algorithm, it is shown that in the limit when the number of agents in the swarm approaches infinity, no other algorithm has strictly better worst-case performance than SwarmBug1 and the universal lower bound is tight.
Neural-Network-Driven Method for Optimal Path Planning via High-Accuracy Region Prediction
Aug 15, 2023Sampling-based path planning algorithms suffer from heavy reliance on uniform sampling, which accounts for unreliable and time-consuming performance, especially in complex environments. Recently, neural-network-driven methods predict regions as sampling domains to realize a non-uniform sampling and reduce calculation time. However, the accuracy of region prediction hinders further improvement. We propose a sampling-based algorithm, abbreviated to Region Prediction Neural Network RRT* (RPNN-RRT*), to rapidly obtain the optimal path based on a high-accuracy region prediction. First, we implement a region prediction neural network (RPNN), to predict accurate regions for the RPNN-RRT*. A full-layer channel-wise attention module is employed to enhance the feature fusion in the concatenation between the encoder and decoder. Moreover, a three-level hierarchy loss is designed to learn the pixel-wise, map-wise, and patch-wise features. A dataset, named Complex Environment Motion Planning, is established to test the performance in complex environments. Ablation studies and test results show that a high accuracy of 89.13% is achieved by the RPNN for region prediction, compared with other region prediction models. In addition, the RPNN-RRT* performs in different complex scenarios, demonstrating significant and reliable superiority in terms of the calculation time, sampling efficiency, and success rate for optimal path planning.
Dynamic Neural Network is All You Need: Understanding the Robustness of Dynamic Mechanisms in Neural Networks
Aug 17, 2023
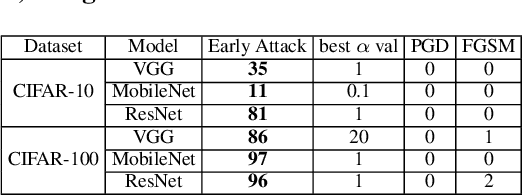
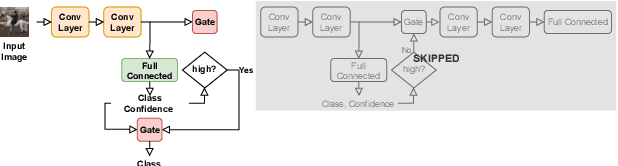
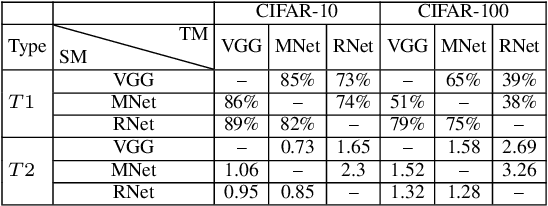
Deep Neural Networks (DNNs) have been used to solve different day-to-day problems. Recently, DNNs have been deployed in real-time systems, and lowering the energy consumption and response time has become the need of the hour. To address this scenario, researchers have proposed incorporating dynamic mechanism to static DNNs (SDNN) to create Dynamic Neural Networks (DyNNs) performing dynamic amounts of computation based on the input complexity. Although incorporating dynamic mechanism into SDNNs would be preferable in real-time systems, it also becomes important to evaluate how the introduction of dynamic mechanism impacts the robustness of the models. However, there has not been a significant number of works focusing on the robustness trade-off between SDNNs and DyNNs. To address this issue, we propose to investigate the robustness of dynamic mechanism in DyNNs and how dynamic mechanism design impacts the robustness of DyNNs. For that purpose, we evaluate three research questions. These evaluations are performed on three models and two datasets. Through the studies, we find that attack transferability from DyNNs to SDNNs is higher than attack transferability from SDNNs to DyNNs. Also, we find that DyNNs can be used to generate adversarial samples more efficiently than SDNNs. Then, through research studies, we provide insight into the design choices that can increase robustness of DyNNs against the attack generated using static model. Finally, we propose a novel attack to understand the additional attack surface introduced by the dynamic mechanism and provide design choices to improve robustness against the attack.
Efficient Bayesian travel-time tomography with geologically-complex priors using sensitivity-informed polynomial chaos expansion and deep generative networks
Jul 19, 2023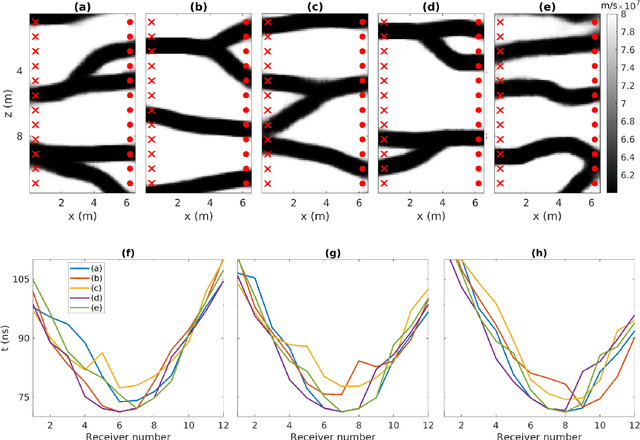

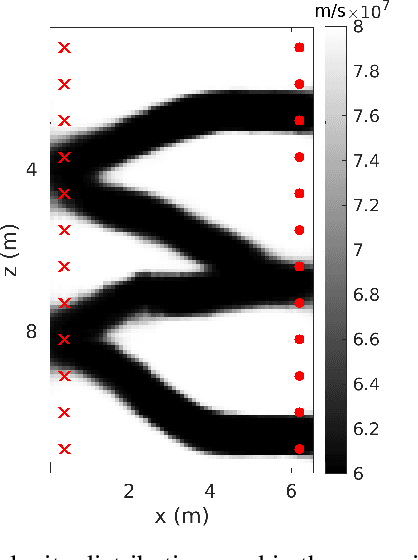

Monte Carlo Markov Chain (MCMC) methods commonly confront two fundamental challenges: the accurate characterization of the prior distribution and the efficient evaluation of the likelihood. In the context of Bayesian studies on tomography, principal component analysis (PCA) can in some cases facilitate the straightforward definition of the prior distribution, while simultaneously enabling the implementation of accurate surrogate models based on polynomial chaos expansion (PCE) to replace computationally intensive full-physics forward solvers. When faced with scenarios where PCA does not offer a direct means of easily defining the prior distribution alternative methods like deep generative models (e.g., variational autoencoders (VAEs)), can be employed as viable options. However, accurately producing a surrogate capable of capturing the intricate non-linear relationship between the latent parameters of a VAE and the outputs of forward modeling presents a notable challenge. Indeed, while PCE models provide high accuracy when the input-output relationship can be effectively approximated by relatively low-degree multivariate polynomials, this condition is typically unmet when utilizing latent variables derived from deep generative models. In this contribution, we present a strategy that combines the excellent reconstruction performances of VAE in terms of prio representation with the accuracy of PCA-PCE surrogate modeling in the context of Bayesian ground penetrating radar (GPR) travel-time tomography. Within the MCMC process, the parametrization of the VAE is leveraged for prior exploration and sample proposal. Concurrently, modeling is conducted using PCE, which operates on either globally or locally defined principal components of the VAE samples under examination.
Learning Robust and Consistent Time Series Representations: A Dilated Inception-Based Approach
Jun 11, 2023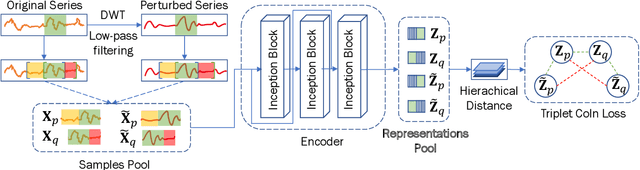
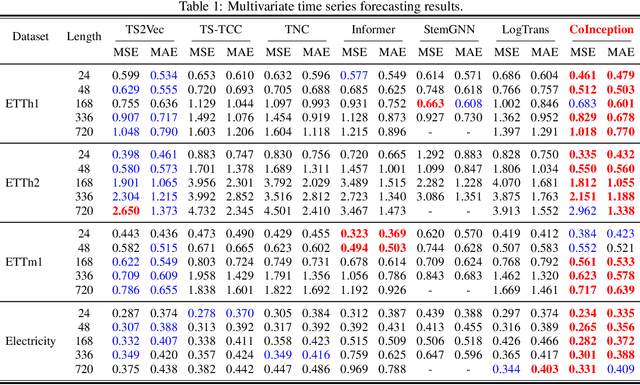
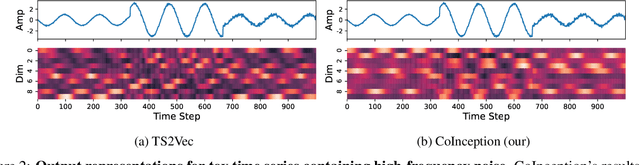
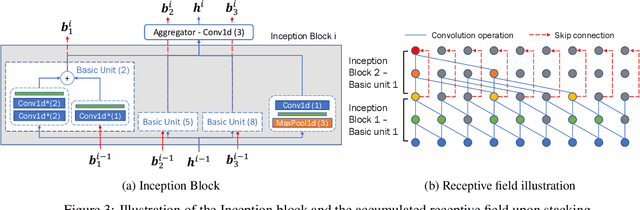
Representation learning for time series has been an important research area for decades. Since the emergence of the foundation models, this topic has attracted a lot of attention in contrastive self-supervised learning, to solve a wide range of downstream tasks. However, there have been several challenges for contrastive time series processing. First, there is no work considering noise, which is one of the critical factors affecting the efficacy of time series tasks. Second, there is a lack of efficient yet lightweight encoder architectures that can learn informative representations robust to various downstream tasks. To fill in these gaps, we initiate a novel sampling strategy that promotes consistent representation learning with the presence of noise in natural time series. In addition, we propose an encoder architecture that utilizes dilated convolution within the Inception block to create a scalable and robust network architecture with a wide receptive field. Experiments demonstrate that our method consistently outperforms state-of-the-art methods in forecasting, classification, and abnormality detection tasks, e.g. ranks first over two-thirds of the classification UCR datasets, with only $40\%$ of the parameters compared to the second-best approach. Our source code for CoInception framework is accessible at https://github.com/anhduy0911/CoInception.
Using Large Language Models to Automate Category and Trend Analysis of Scientific Articles: An Application in Ophthalmology
Aug 31, 2023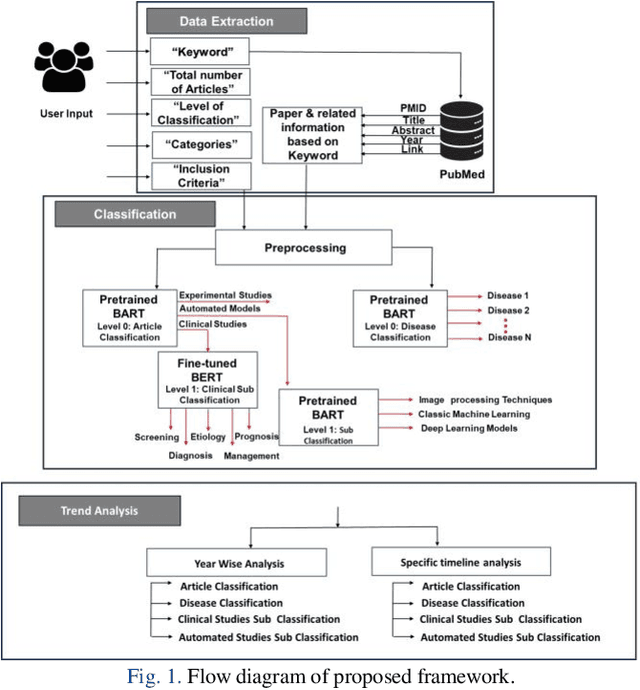
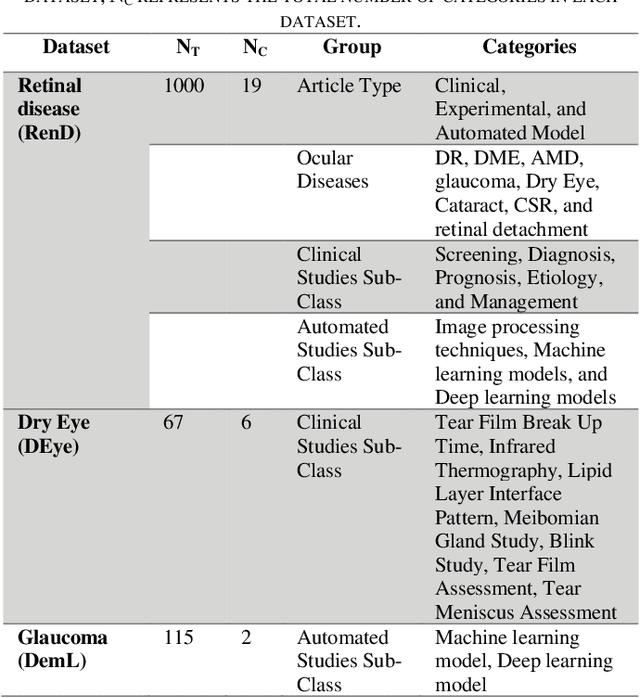
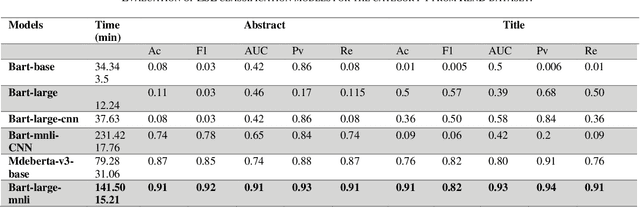
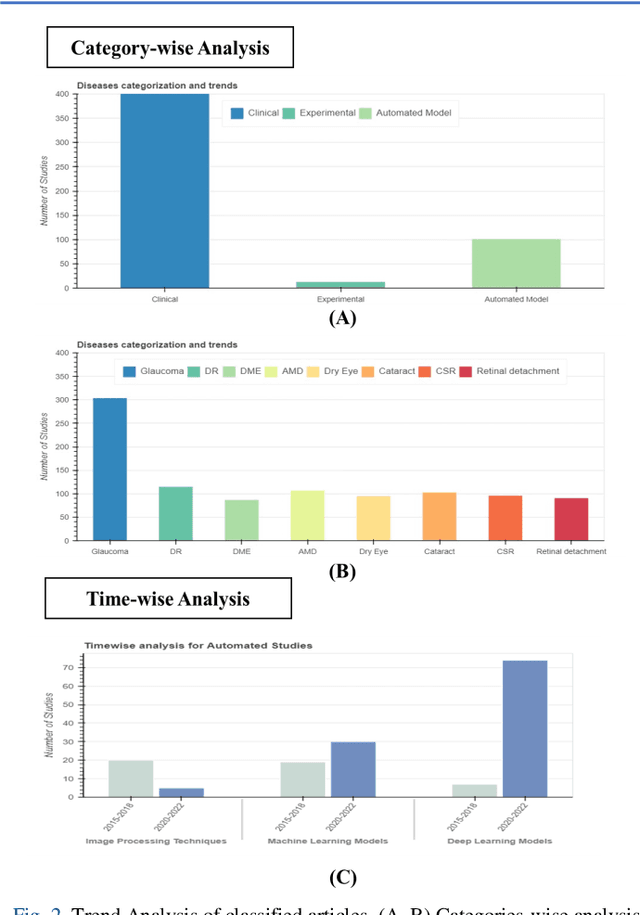
Purpose: In this paper, we present an automated method for article classification, leveraging the power of Large Language Models (LLM). The primary focus is on the field of ophthalmology, but the model is extendable to other fields. Methods: We have developed a model based on Natural Language Processing (NLP) techniques, including advanced LLMs, to process and analyze the textual content of scientific papers. Specifically, we have employed zero-shot learning (ZSL) LLM models and compared against Bidirectional and Auto-Regressive Transformers (BART) and its variants, and Bidirectional Encoder Representations from Transformers (BERT), and its variant such as distilBERT, SciBERT, PubmedBERT, BioBERT. Results: The classification results demonstrate the effectiveness of LLMs in categorizing large number of ophthalmology papers without human intervention. Results: To evalute the LLMs, we compiled a dataset (RenD) of 1000 ocular disease-related articles, which were expertly annotated by a panel of six specialists into 15 distinct categories. The model achieved mean accuracy of 0.86 and mean F1 of 0.85 based on the RenD dataset. Conclusion: The proposed framework achieves notable improvements in both accuracy and efficiency. Its application in the domain of ophthalmology showcases its potential for knowledge organization and retrieval in other domains too. We performed trend analysis that enables the researchers and clinicians to easily categorize and retrieve relevant papers, saving time and effort in literature review and information gathering as well as identification of emerging scientific trends within different disciplines. Moreover, the extendibility of the model to other scientific fields broadens its impact in facilitating research and trend analysis across diverse disciplines.
Dual-Decoder Consistency via Pseudo-Labels Guided Data Augmentation for Semi-Supervised Medical Image Segmentation
Aug 31, 2023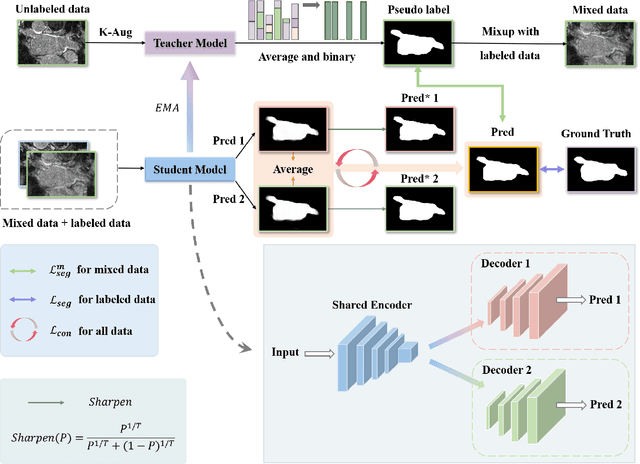
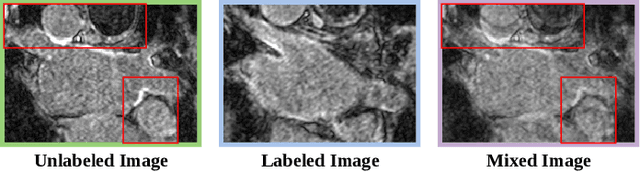
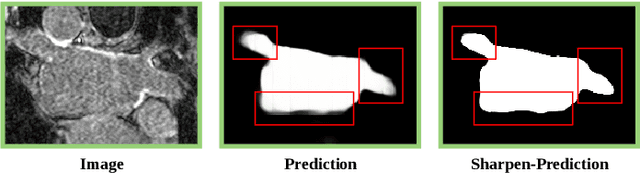
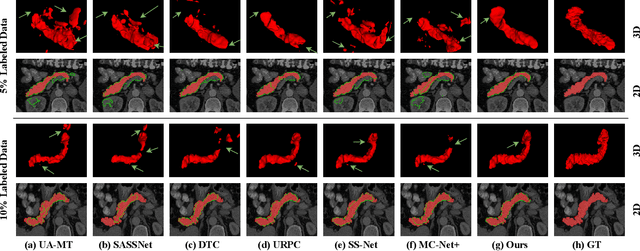
Medical image segmentation methods often rely on fully supervised approaches to achieve excellent performance, which is contingent upon having an extensive set of labeled images for training. However, annotating medical images is both expensive and time-consuming. Semi-supervised learning offers a solution by leveraging numerous unlabeled images alongside a limited set of annotated ones. In this paper, we introduce a semi-supervised medical image segmentation method based on the mean-teacher model, referred to as Dual-Decoder Consistency via Pseudo-Labels Guided Data Augmentation (DCPA). This method combines consistency regularization, pseudo-labels, and data augmentation to enhance the efficacy of semi-supervised segmentation. Firstly, the proposed model comprises both student and teacher models with a shared encoder and two distinct decoders employing different up-sampling strategies. Minimizing the output discrepancy between decoders enforces the generation of consistent representations, serving as regularization during student model training. Secondly, we introduce mixup operations to blend unlabeled data with labeled data, creating mixed data and thereby achieving data augmentation. Lastly, pseudo-labels are generated by the teacher model and utilized as labels for mixed data to compute unsupervised loss. We compare the segmentation results of the DCPA model with six state-of-the-art semi-supervised methods on three publicly available medical datasets. Beyond classical 10\% and 20\% semi-supervised settings, we investigate performance with less supervision (5\% labeled data). Experimental outcomes demonstrate that our approach consistently outperforms existing semi-supervised medical image segmentation methods across the three semi-supervised settings.
Towards Self-Adaptive Machine Learning-Enabled Systems Through QoS-Aware Model Switching
Aug 19, 2023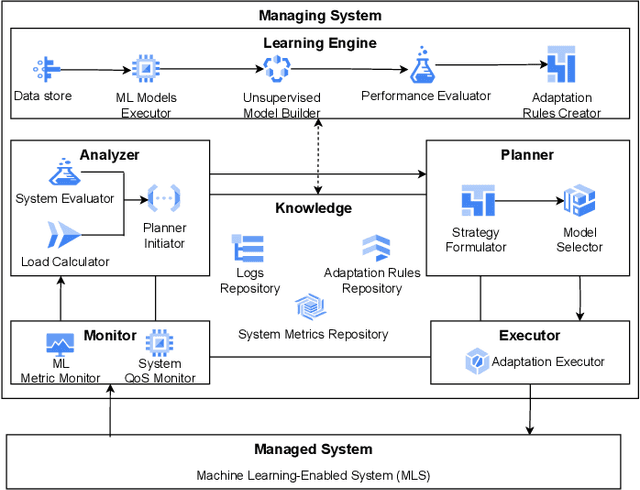
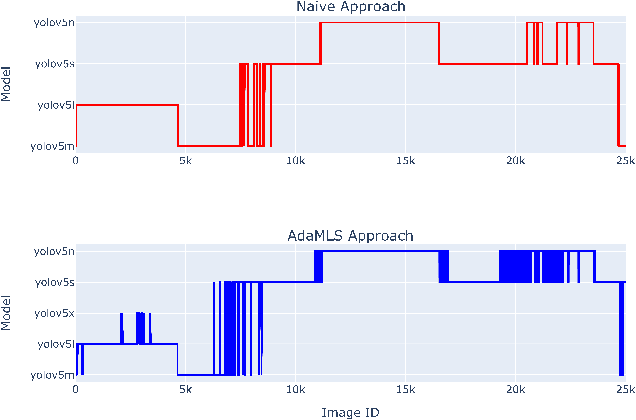
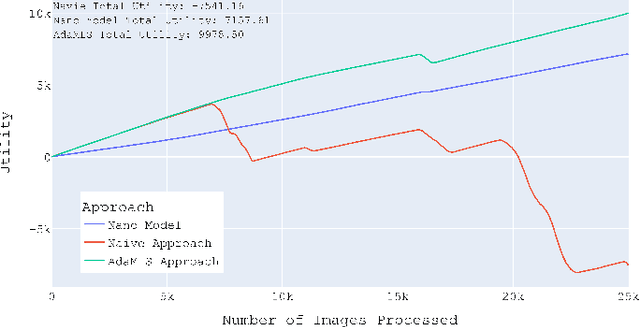

Machine Learning (ML), particularly deep learning, has seen vast advancements, leading to the rise of Machine Learning-Enabled Systems (MLS). However, numerous software engineering challenges persist in propelling these MLS into production, largely due to various run-time uncertainties that impact the overall Quality of Service (QoS). These uncertainties emanate from ML models, software components, and environmental factors. Self-adaptation techniques present potential in managing run-time uncertainties, but their application in MLS remains largely unexplored. As a solution, we propose the concept of a Machine Learning Model Balancer, focusing on managing uncertainties related to ML models by using multiple models. Subsequently, we introduce AdaMLS, a novel self-adaptation approach that leverages this concept and extends the traditional MAPE-K loop for continuous MLS adaptation. AdaMLS employs lightweight unsupervised learning for dynamic model switching, thereby ensuring consistent QoS. Through a self-adaptive object detection system prototype, we demonstrate AdaMLS's effectiveness in balancing system and model performance. Preliminary results suggest AdaMLS surpasses naive and single state-of-the-art models in QoS guarantees, heralding the advancement towards self-adaptive MLS with optimal QoS in dynamic environments.
Contrastive Learning-based Imputation-Prediction Networks for In-hospital Mortality Risk Modeling using EHRs
Aug 19, 2023
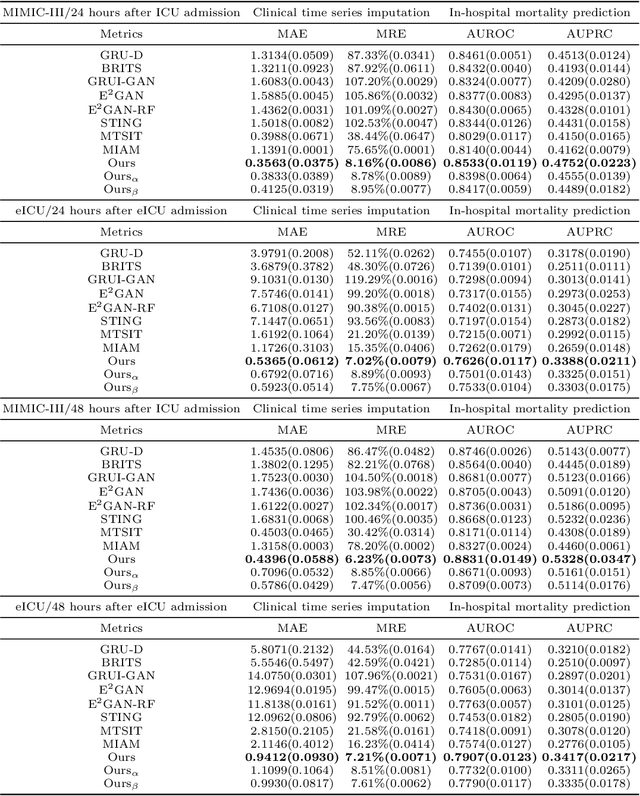

Predicting the risk of in-hospital mortality from electronic health records (EHRs) has received considerable attention. Such predictions will provide early warning of a patient's health condition to healthcare professionals so that timely interventions can be taken. This prediction task is challenging since EHR data are intrinsically irregular, with not only many missing values but also varying time intervals between medical records. Existing approaches focus on exploiting the variable correlations in patient medical records to impute missing values and establishing time-decay mechanisms to deal with such irregularity. This paper presents a novel contrastive learning-based imputation-prediction network for predicting in-hospital mortality risks using EHR data. Our approach introduces graph analysis-based patient stratification modeling in the imputation process to group similar patients. This allows information of similar patients only to be used, in addition to personal contextual information, for missing value imputation. Moreover, our approach can integrate contrastive learning into the proposed network architecture to enhance patient representation learning and predictive performance on the classification task. Experiments on two real-world EHR datasets show that our approach outperforms the state-of-the-art approaches in both imputation and prediction tasks.
DeepLOC: Deep Learning-based Bone Pathology Localization and Classification in Wrist X-ray Images
Aug 24, 2023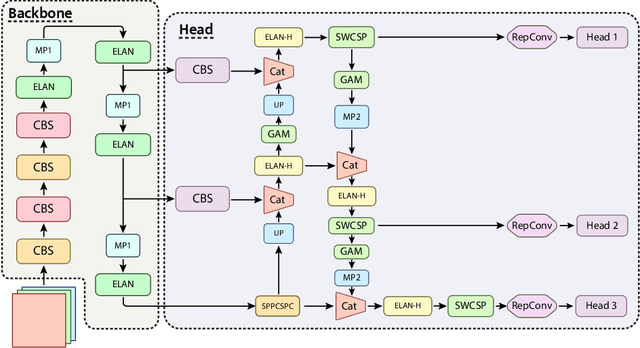
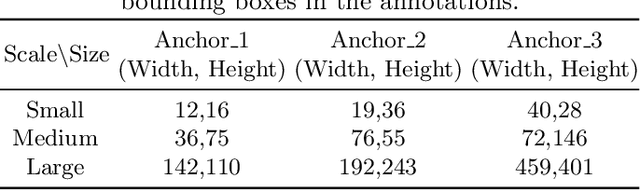
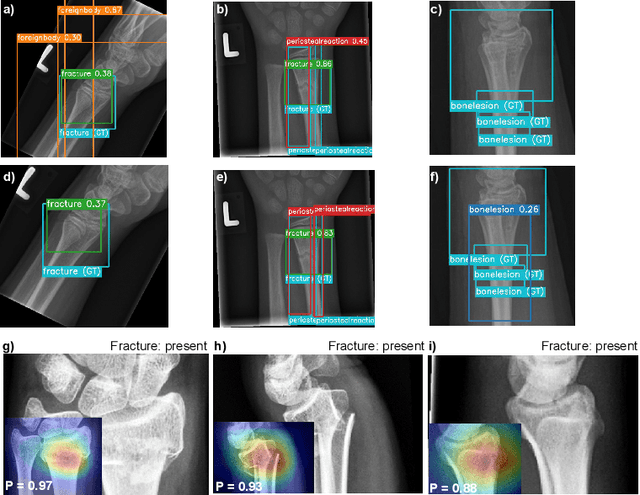
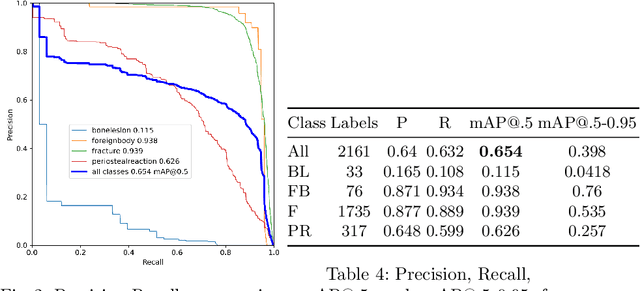
In recent years, computer-aided diagnosis systems have shown great potential in assisting radiologists with accurate and efficient medical image analysis. This paper presents a novel approach for bone pathology localization and classification in wrist X-ray images using a combination of YOLO (You Only Look Once) and the Shifted Window Transformer (Swin) with a newly proposed block. The proposed methodology addresses two critical challenges in wrist X-ray analysis: accurate localization of bone pathologies and precise classification of abnormalities. The YOLO framework is employed to detect and localize bone pathologies, leveraging its real-time object detection capabilities. Additionally, the Swin, a transformer-based module, is utilized to extract contextual information from the localized regions of interest (ROIs) for accurate classification.