 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficiently Identifying Hotspots in a Spatially Varying Field with Multiple Robots
Sep 14, 2023
In this paper, we present algorithms to identify environmental hotspots using mobile sensors. We examine two approaches: one involving a single robot and another using multiple robots coordinated through a decentralized robot system. We introduce an adaptive algorithm that does not require precise knowledge of Gaussian Processes (GPs) hyperparameters, making the modeling process more flexible. The robots operate for a pre-defined time in the environment. The multi-robot system uses Voronoi partitioning to divide tasks and a Monte Carlo Tree Search for optimal path planning. Our tests on synthetic and a real-world dataset of Chlorophyll density from a Pacific Ocean sub-region suggest that accurate estimation of GP hyperparameters may not be essential for hotspot detection, potentially simplifying environmental monitoring tasks.
Head-Related Transfer Function Interpolation with a Spherical CNN
Sep 15, 2023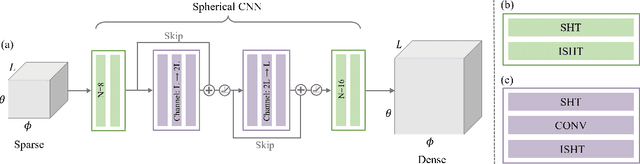
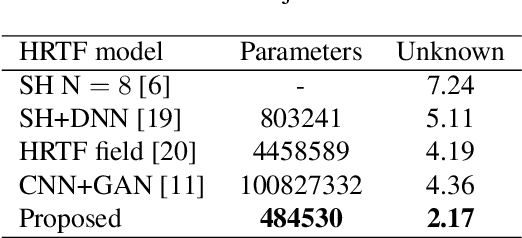
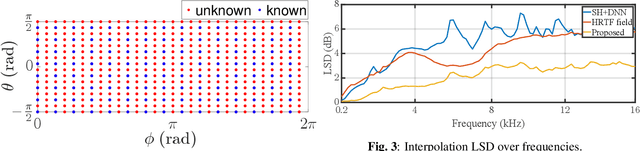
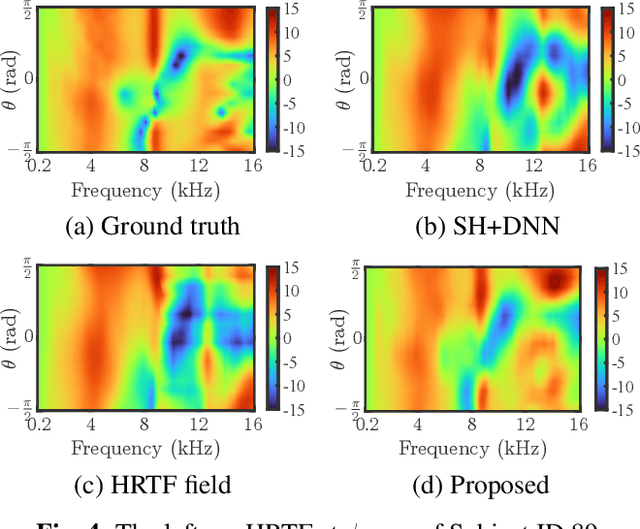
Head-related transfer functions (HRTFs) are crucial for spatial soundfield reproduction in virtual reality applications. However, obtaining personalized, high-resolution HRTFs is a time-consuming and costly task. Recently, deep learning-based methods showed promise in interpolating high-resolution HRTFs from sparse measurements. Some of these methods treat HRTF interpolation as an image super-resolution task, which neglects spatial acoustic features. This paper proposes a spherical convolutional neural network method for HRTF interpolation. The proposed method realizes the convolution process by decomposing and reconstructing HRTF through the Spherical Harmonics (SHs). The SHs, an orthogonal function set defined on a sphere, allow the convolution layers to effectively capture the spatial features of HRTFs, which are sampled on a sphere. Simulation results demonstrate the effectiveness of the proposed method in achieving accurate interpolation from sparse measurements, outperforming the SH method and learning-based methods.
tsdownsample: high-performance time series downsampling for scalable visualization
Jul 05, 2023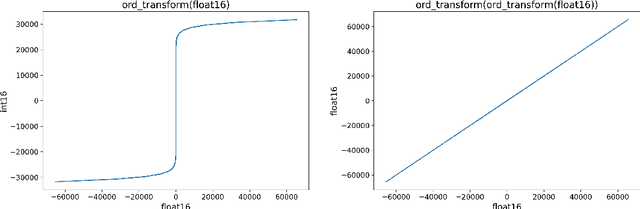
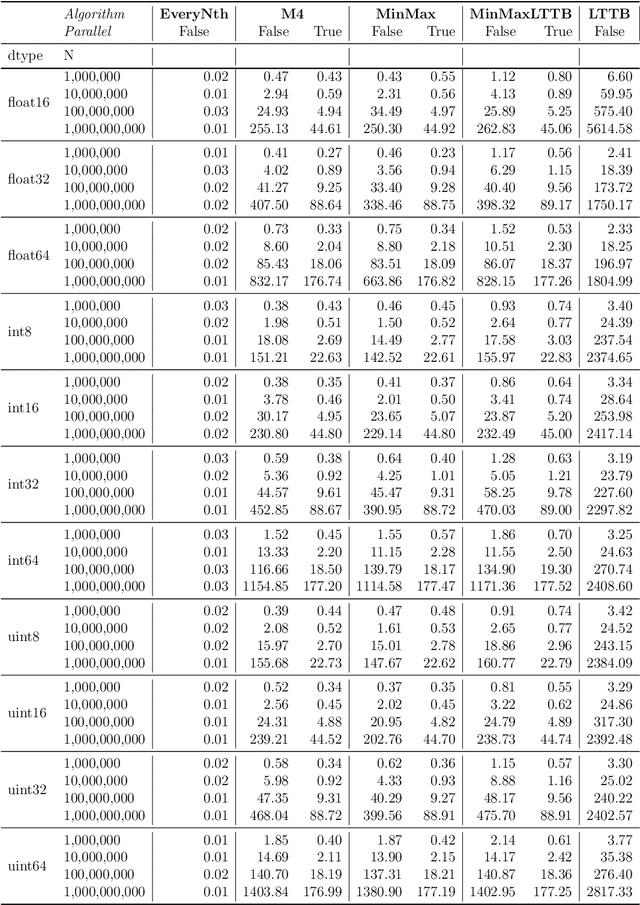
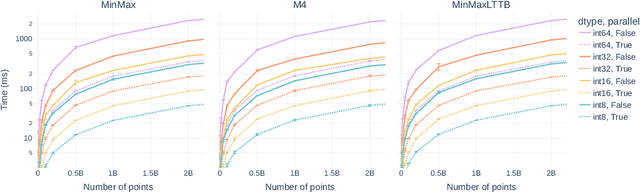
Interactive line chart visualizations greatly enhance the effective exploration of large time series. Although downsampling has emerged as a well-established approach to enable efficient interactive visualization of large datasets, it is not an inherent feature in most visualization tools. Furthermore, there is no library offering a convenient interface for high-performance implementations of prominent downsampling algorithms. To address these shortcomings, we present tsdownsample, an open-source Python package specifically designed for CPU-based, in-memory time series downsampling. Our library focuses on performance and convenient integration, offering optimized implementations of leading downsampling algorithms. We achieve this optimization by leveraging low-level SIMD instructions and multithreading capabilities in Rust. In particular, SIMD instructions were employed to optimize the argmin and argmax operations. This SIMD optimization, along with some algorithmic tricks, proved crucial in enhancing the performance of various downsampling algorithms. We evaluate the performance of tsdownsample and demonstrate its interoperability with an established visualization framework. Our performance benchmarks indicate that the algorithmic runtime of tsdownsample approximates the CPU's memory bandwidth. This work marks a significant advancement in bringing high-performance time series downsampling to the Python ecosystem, enabling scalable visualization. The open-source code can be found at https://github.com/predict-idlab/tsdownsample
Towards a Safe Real-Time Motion Planning Framework for Autonomous Driving Systems: An MPPI Approach
Aug 03, 2023
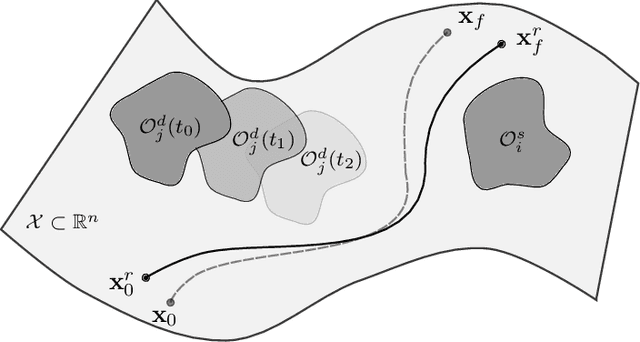
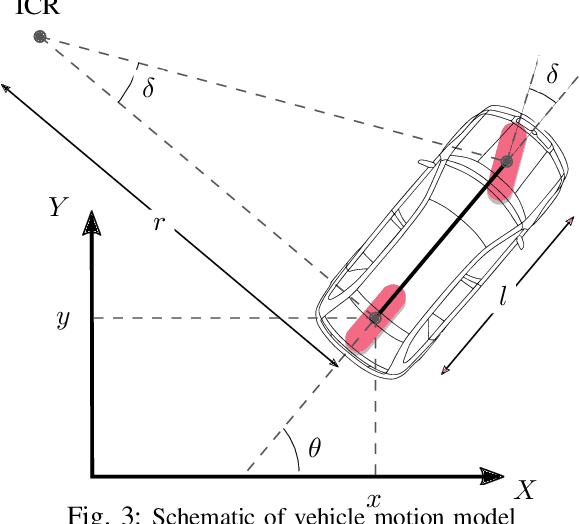
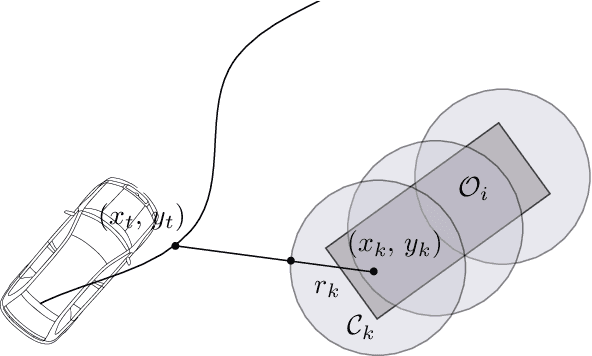
Planning safe trajectories in Autonomous Driving Systems (ADS) is a complex problem to solve in real-time. The main challenge to solve this problem arises from the various conditions and constraints imposed by road geometry, semantics and traffic rules, as well as the presence of dynamic agents. Recently, Model Predictive Path Integral (MPPI) has shown to be an effective framework for optimal motion planning and control in robot navigation in unstructured and highly uncertain environments. In this paper, we formulate the motion planning problem in ADS as a nonlinear stochastic dynamic optimization problem that can be solved using an MPPI strategy. The main technical contribution of this work is a method to handle obstacles within the MPPI formulation safely. In this method, obstacles are approximated by circles that can be easily integrated into the MPPI cost formulation while considering safety margins. The proposed MPPI framework has been efficiently implemented in our autonomous vehicle and experimentally validated using three different primitive scenarios. Experimental results show that generated trajectories are safe, feasible and perfectly achieve the planning objective. The video results as well as the open-source implementation are available at: https://gitlab.uni.lu/360lab-public/mppi
AFDM vs OTFS: A Comparative Study of Promising Waveforms for ISAC in Doubly-Dispersive Channels
Sep 10, 2023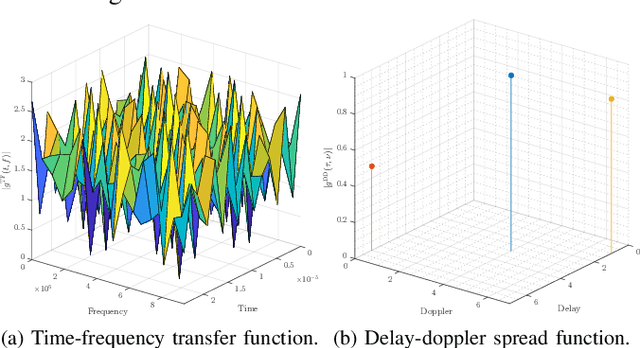
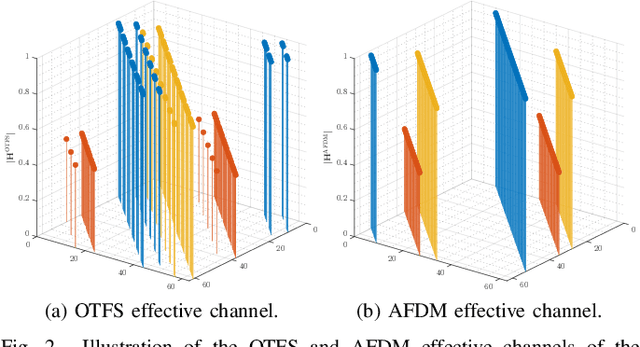
This white paper aims to briefly describe a proposed article that will provide a thorough comparative study of waveforms designed to exploit the features of doubly-dispersive channels arising in heterogeneous high-mobility scenarios as expected in the beyond fifth generation (B5G) and sixth generation (6G), in relation to their suitability to integrated sensing and communications (ISAC) systems. In particular, the full article will compare the well-established delay-Doppler domain-based orthognal time frequency space (OTFS) and the recently proposed chirp domain-based affine frequency division multiplexing (AFDM) waveforms. Both these waveforms are designed based on a full delay- Doppler representation of the time variant (TV) multipath channel, yielding not only robustness and orthogonality of information symbols in high-mobility scenarios, but also a beneficial implication for environment target detection through the inherent capability of estimating the path delay and Doppler shifts, which are standard radar parameters. These modulation schemes are distinct candidates for ISAC in B5G/6G systems, such that a thorough study of their advantages, shortcomings, implications to signal processing, and performance of communication and sensing functions are well in order. In light of the above, a sample of the intended contribution (Special Issue paper) is provided below.
Quantized Non-Volatile Nanomagnetic Synapse based Autoencoder for Efficient Unsupervised Network Anomaly Detection
Sep 12, 2023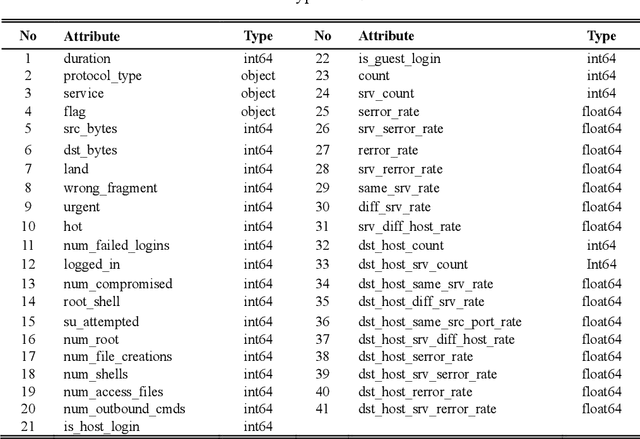
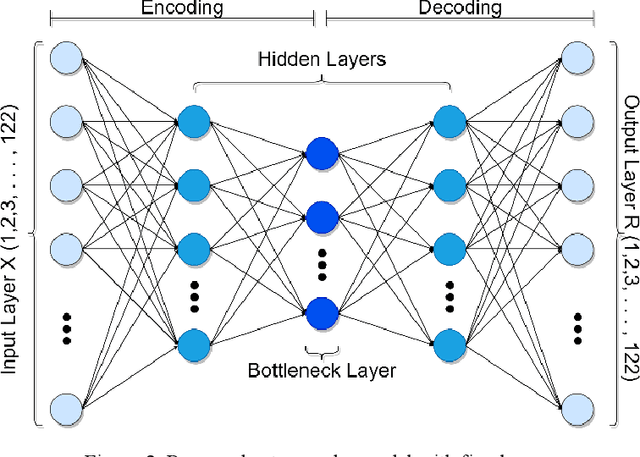
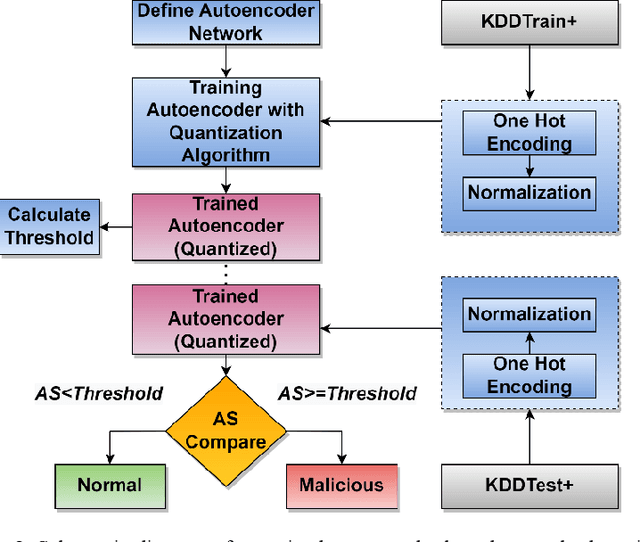
In the autoencoder based anomaly detection paradigm, implementing the autoencoder in edge devices capable of learning in real-time is exceedingly challenging due to limited hardware, energy, and computational resources. We show that these limitations can be addressed by designing an autoencoder with low-resolution non-volatile memory-based synapses and employing an effective quantized neural network learning algorithm. We propose a ferromagnetic racetrack with engineered notches hosting a magnetic domain wall (DW) as the autoencoder synapses, where limited state (5-state) synaptic weights are manipulated by spin orbit torque (SOT) current pulses. The performance of anomaly detection of the proposed autoencoder model is evaluated on the NSL-KDD dataset. Limited resolution and DW device stochasticity aware training of the autoencoder is performed, which yields comparable anomaly detection performance to the autoencoder having floating-point precision weights. While the limited number of quantized states and the inherent stochastic nature of DW synaptic weights in nanoscale devices are known to negatively impact the performance, our hardware-aware training algorithm is shown to leverage these imperfect device characteristics to generate an improvement in anomaly detection accuracy (90.98%) compared to accuracy obtained with floating-point trained weights. Furthermore, our DW-based approach demonstrates a remarkable reduction of at least three orders of magnitude in weight updates during training compared to the floating-point approach, implying substantial energy savings for our method. This work could stimulate the development of extremely energy efficient non-volatile multi-state synapse-based processors that can perform real-time training and inference on the edge with unsupervised data.
SymED: Adaptive and Online Symbolic Representation of Data on the Edge
Sep 06, 2023The edge computing paradigm helps handle the Internet of Things (IoT) generated data in proximity to its source. Challenges occur in transferring, storing, and processing this rapidly growing amount of data on resource-constrained edge devices. Symbolic Representation (SR) algorithms are promising solutions to reduce the data size by converting actual raw data into symbols. Also, they allow data analytics (e.g., anomaly detection and trend prediction) directly on symbols, benefiting large classes of edge applications. However, existing SR algorithms are centralized in design and work offline with batch data, which is infeasible for real-time cases. We propose SymED - Symbolic Edge Data representation method, i.e., an online, adaptive, and distributed approach for symbolic representation of data on edge. SymED is based on the Adaptive Brownian Bridge-based Aggregation (ABBA), where we assume low-powered IoT devices do initial data compression (senders) and the more robust edge devices do the symbolic conversion (receivers). We evaluate SymED by measuring compression performance, reconstruction accuracy through Dynamic Time Warping (DTW) distance, and computational latency. The results show that SymED is able to (i) reduce the raw data with an average compression rate of 9.5%; (ii) keep a low reconstruction error of 13.25 in the DTW space; (iii) simultaneously provide real-time adaptability for online streaming IoT data at typical latencies of 42ms per symbol, reducing the overall network traffic.
* 14 pages, 5 figures
Bayesian Time-Series Classifier for Decoding Simple Visual Stimuli from Intracranial Neural Activity
Jul 28, 2023Understanding how external stimuli are encoded in distributed neural activity is of significant interest in clinical and basic neuroscience. To address this need, it is essential to develop analytical tools capable of handling limited data and the intrinsic stochasticity present in neural data. In this study, we propose a straightforward Bayesian time series classifier (BTsC) model that tackles these challenges whilst maintaining a high level of interpretability. We demonstrate the classification capabilities of this approach by utilizing neural data to decode colors in a visual task. The model exhibits consistent and reliable average performance of 75.55% on 4 patients' dataset, improving upon state-of-the-art machine learning techniques by about 3.0 percent. In addition to its high classification accuracy, the proposed BTsC model provides interpretable results, making the technique a valuable tool to study neural activity in various tasks and categories. The proposed solution can be applied to neural data recorded in various tasks, where there is a need for interpretable results and accurate classification accuracy.
AI-Driven Patient Monitoring with Multi-Agent Deep Reinforcement Learning
Sep 20, 2023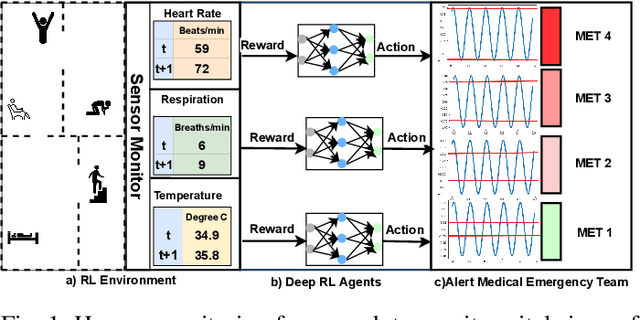
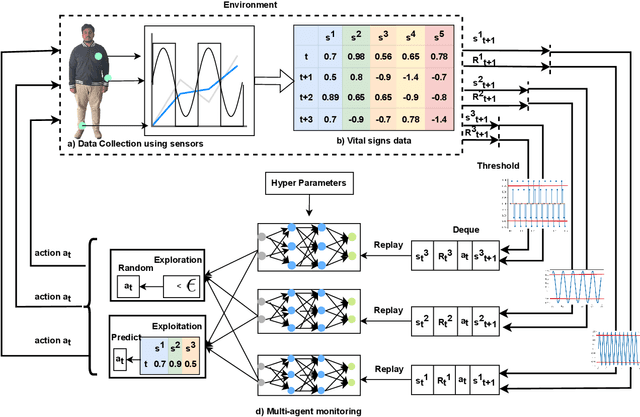
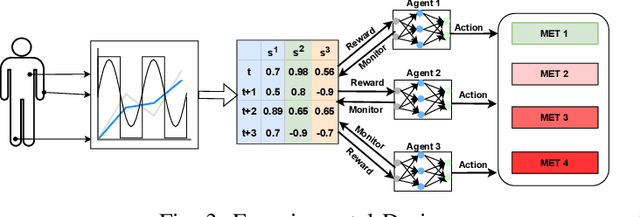
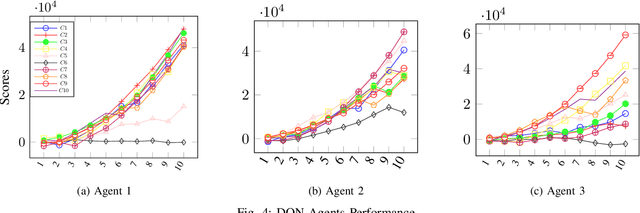
Effective patient monitoring is vital for timely interventions and improved healthcare outcomes. Traditional monitoring systems often struggle to handle complex, dynamic environments with fluctuating vital signs, leading to delays in identifying critical conditions. To address this challenge, we propose a novel AI-driven patient monitoring framework using multi-agent deep reinforcement learning (DRL). Our approach deploys multiple learning agents, each dedicated to monitoring a specific physiological feature, such as heart rate, respiration, and temperature. These agents interact with a generic healthcare monitoring environment, learn the patients' behavior patterns, and make informed decisions to alert the corresponding Medical Emergency Teams (METs) based on the level of emergency estimated. In this study, we evaluate the performance of the proposed multi-agent DRL framework using real-world physiological and motion data from two datasets: PPG-DaLiA and WESAD. We compare the results with several baseline models, including Q-Learning, PPO, Actor-Critic, Double DQN, and DDPG, as well as monitoring frameworks like WISEML and CA-MAQL. Our experiments demonstrate that the proposed DRL approach outperforms all other baseline models, achieving more accurate monitoring of patient's vital signs. Furthermore, we conduct hyperparameter optimization to fine-tune the learning process of each agent. By optimizing hyperparameters, we enhance the learning rate and discount factor, thereby improving the agents' overall performance in monitoring patient health status. Our AI-driven patient monitoring system offers several advantages over traditional methods, including the ability to handle complex and uncertain environments, adapt to varying patient conditions, and make real-time decisions without external supervision.
Improving Adversarial Robustness of Masked Autoencoders via Test-time Frequency-domain Prompting
Aug 22, 2023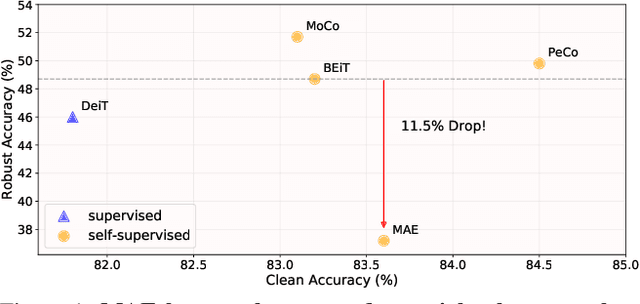
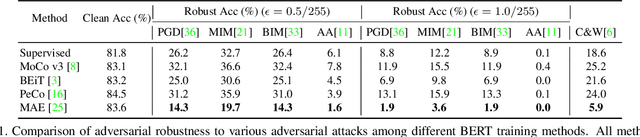
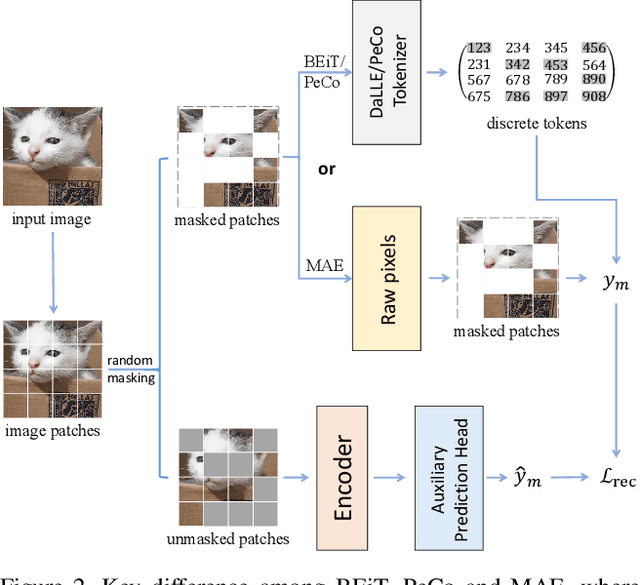

In this paper, we investigate the adversarial robustness of vision transformers that are equipped with BERT pretraining (e.g., BEiT, MAE). A surprising observation is that MAE has significantly worse adversarial robustness than other BERT pretraining methods. This observation drives us to rethink the basic differences between these BERT pretraining methods and how these differences affect the robustness against adversarial perturbations. Our empirical analysis reveals that the adversarial robustness of BERT pretraining is highly related to the reconstruction target, i.e., predicting the raw pixels of masked image patches will degrade more adversarial robustness of the model than predicting the semantic context, since it guides the model to concentrate more on medium-/high-frequency components of images. Based on our analysis, we provide a simple yet effective way to boost the adversarial robustness of MAE. The basic idea is using the dataset-extracted domain knowledge to occupy the medium-/high-frequency of images, thus narrowing the optimization space of adversarial perturbations. Specifically, we group the distribution of pretraining data and optimize a set of cluster-specific visual prompts on frequency domain. These prompts are incorporated with input images through prototype-based prompt selection during test period. Extensive evaluation shows that our method clearly boost MAE's adversarial robustness while maintaining its clean performance on ImageNet-1k classification. Our code is available at: https://github.com/shikiw/RobustMAE.