 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Identifying Hotspots in a Spatially Varying Field with Multiple Robots
Sep 14, 2023In this paper, we present algorithms to identify environmental hotspots using mobile sensors. We examine two approaches: one involving a single robot and another using multiple robots coordinated through a decentralized robot system. We introduce an adaptive algorithm that does not require precise knowledge of Gaussian Processes (GPs) hyperparameters, making the modeling process more flexible. The robots operate for a pre-defined time in the environment. The multi-robot system uses Voronoi partitioning to divide tasks and a Monte Carlo Tree Search for optimal path planning. Our tests on synthetic and a real-world dataset of Chlorophyll density from a Pacific Ocean sub-region suggest that accurate estimation of GP hyperparameters may not be essential for hotspot detection, potentially simplifying environmental monitoring tasks.
Learning a Spatial Field in Minimum Time with a Team of Robots
Sep 04, 2019
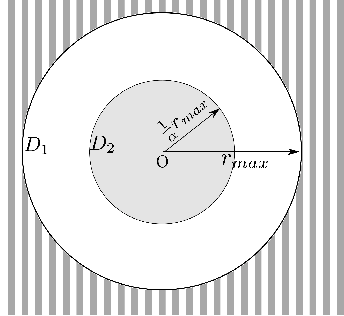
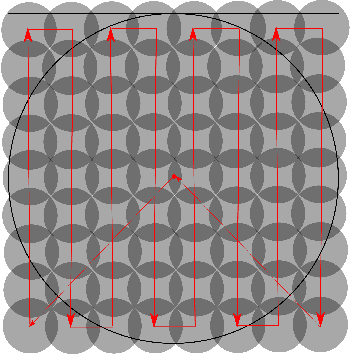
We study an informative path planning problem where the goal is to minimize the time required to learn a spatial field. Specifically, our goal is to ensure that the mean square error between the learned and actual fields is below a predefined value. We study three versions of the problem. In the placement version, the objective is to minimize the number of measurement locations. In the mobile robot version, we seek to minimize the total time required to visit and collect measurements from the measurement locations using a single robot. A multi-robot version is studied as well where the objective is to minimize the time required by the last robot to return to a common starting location called depot. By exploiting the properties of Gaussian Process regression, we present constant-factor approximation algorithms. In addition to the theoretical results, we also compare the empirical performance using a real-world dataset with other baseline strategies.
Multi-Fidelity Reinforcement Learning with Gaussian Processes
Dec 18, 2017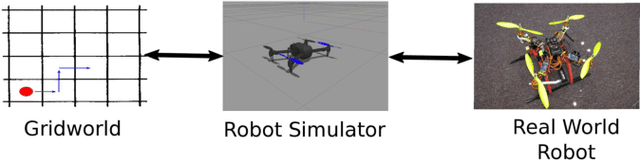
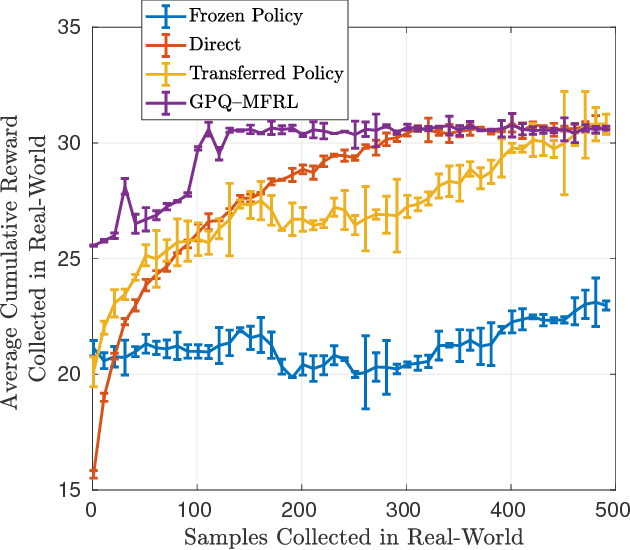
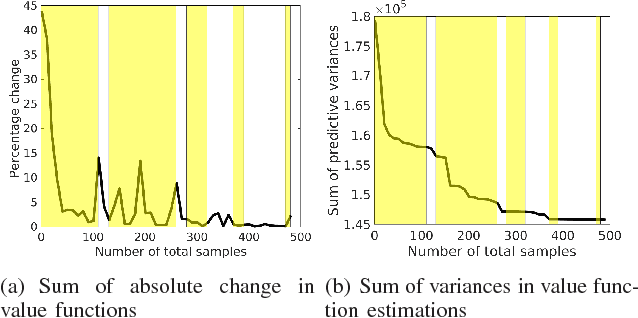
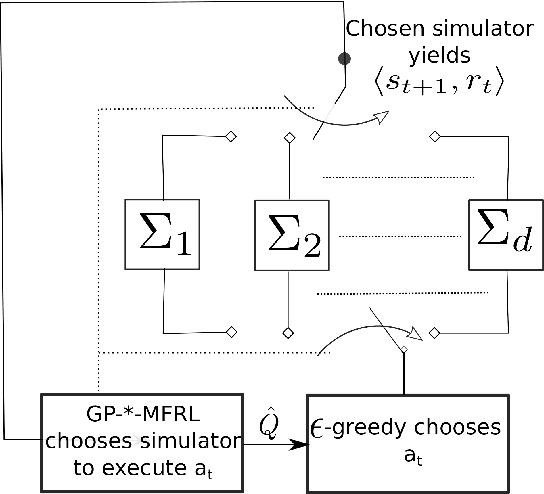
This paper studies the problem of Reinforcement Learning (RL) using as few real-world samples as possible. A naive application of RL algorithms can be inefficient in large and continuous state spaces. We present two versions of Multi-Fidelity Reinforcement Learning (MFRL) algorithm that leverage Gaussian Processes (GPs) to learn the optimal policy in a real-world environment. In MFRL framework, an agent uses multiple simulators of the real environment to perform actions. With increasing fidelity in a simulator chain, the number of samples used in successively higher simulators can be reduced. By incorporating GPs in MFRL framework, further reduction in the number of learning samples can be achieved as we move up the simulator chain. We examine the performance of our algorithms with the help of real-world experiments for navigation with a ground robot.