 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dataset Condensation for Recommendation
Oct 02, 2023
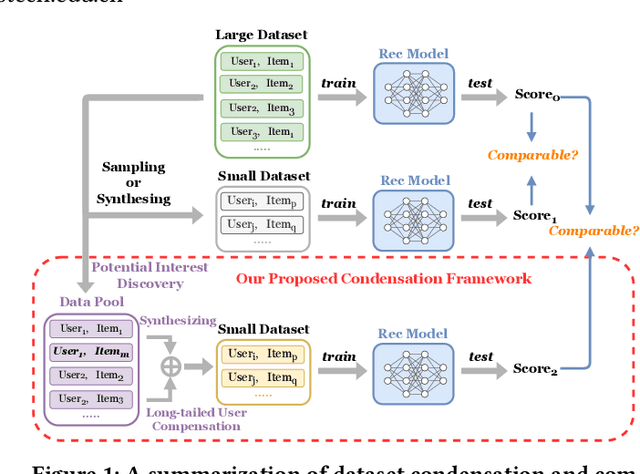
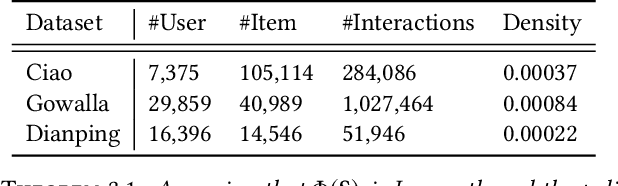
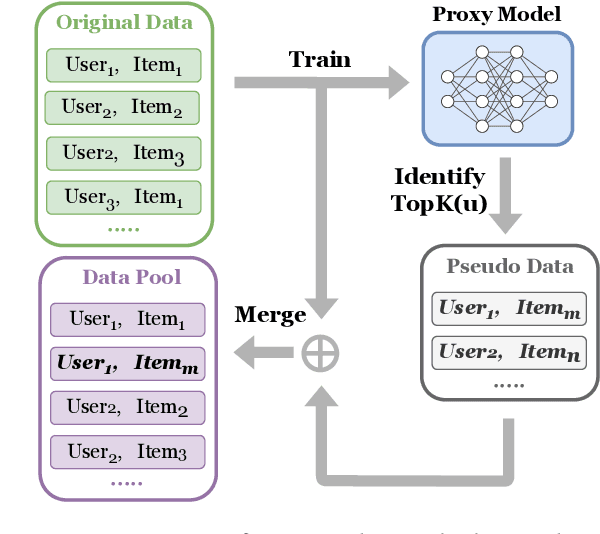
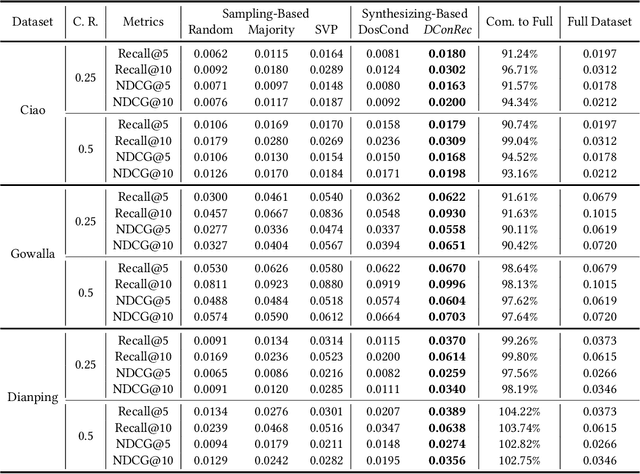
Training recommendation models on large datasets often requires significant time and computational resources. Consequently, an emergent imperative has arisen to construct informative, smaller-scale datasets for efficiently training. Dataset compression techniques explored in other domains show potential possibility to address this problem, via sampling a subset or synthesizing a small dataset. However, applying existing approaches to condense recommendation datasets is impractical due to following challenges: (i) sampling-based methods are inadequate in addressing the long-tailed distribution problem; (ii) synthesizing-based methods are not applicable due to discreteness of interactions and large size of recommendation datasets; (iii) neither of them fail to address the specific issue in recommendation of false negative items, where items with potential user interest are incorrectly sampled as negatives owing to insufficient exposure. To bridge this gap, we investigate dataset condensation for recommendation, where discrete interactions are continualized with probabilistic re-parameterization. To avoid catastrophically expensive computations, we adopt a one-step update strategy for inner model training and introducing policy gradient estimation for outer dataset synthesis. To mitigate amplification of long-tailed problem, we compensate long-tailed users in the condensed dataset. Furthermore, we propose to utilize a proxy model to identify false negative items. Theoretical analysis regarding the convergence property is provided. Extensive experiments on multiple datasets demonstrate the efficacy of our method. In particular, we reduce the dataset size by 75% while approximating over 98% of the original performance on Dianping and over 90% on other datasets.
ViPlanner: Visual Semantic Imperative Learning for Local Navigation
Oct 02, 2023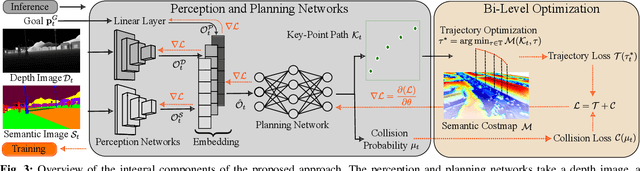

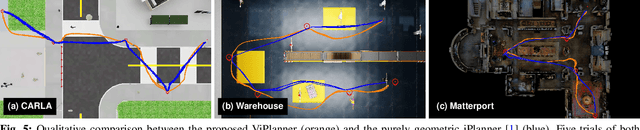

Real-time path planning in outdoor environments still challenges modern robotic systems due to differences in terrain traversability, diverse obstacles, and the necessity for fast decision-making. Established approaches have primarily focused on geometric navigation solutions, which work well for structured geometric obstacles but have limitations regarding the semantic interpretation of different terrain types and their affordances. Moreover, these methods fail to identify traversable geometric occurrences, such as stairs. To overcome these issues, we introduce ViPlanner, a learned local path planning approach that generates local plans based on geometric and semantic information. The system is trained using the Imperative Learning paradigm, for which the network weights are optimized end-to-end based on the planning task objective. This optimization uses a differentiable formulation of a semantic costmap, which enables the planner to distinguish between the traversability of different terrains and accurately identify obstacles. The semantic information is represented in 30 classes using an RGB colorspace that can effectively encode the multiple levels of traversability. We show that the planner can adapt to diverse real-world environments without requiring any real-world training. In fact, the planner is trained purely in simulation, enabling a highly scalable training data generation. Experimental results demonstrate resistance to noise, zero-shot sim-to-real transfer, and a decrease of 38.02% in terms of traversability cost compared to purely geometric-based approaches. Code and models are made publicly available: https://github.com/leggedrobotics/viplanner.
HyperTrack: Neural Combinatorics for High Energy Physics
Sep 25, 2023Combinatorial inverse problems in high energy physics span enormous algorithmic challenges. This work presents a new deep learning driven clustering algorithm that utilizes a space-time non-local trainable graph constructor, a graph neural network, and a set transformer. The model is trained with loss functions at the graph node, edge and object level, including contrastive learning and meta-supervision. The algorithm can be applied to problems such as charged particle tracking, calorimetry, pile-up discrimination, jet physics, and beyond. We showcase the effectiveness of this cutting-edge AI approach through particle tracking simulations. The code is available online.
Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation
Oct 03, 2023
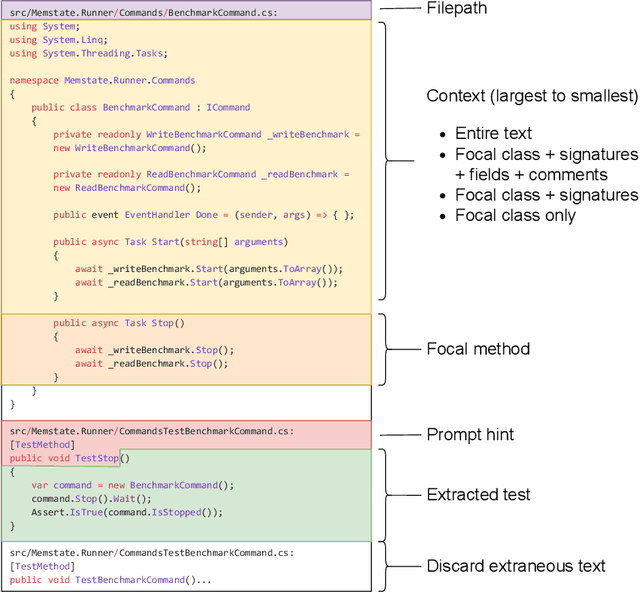

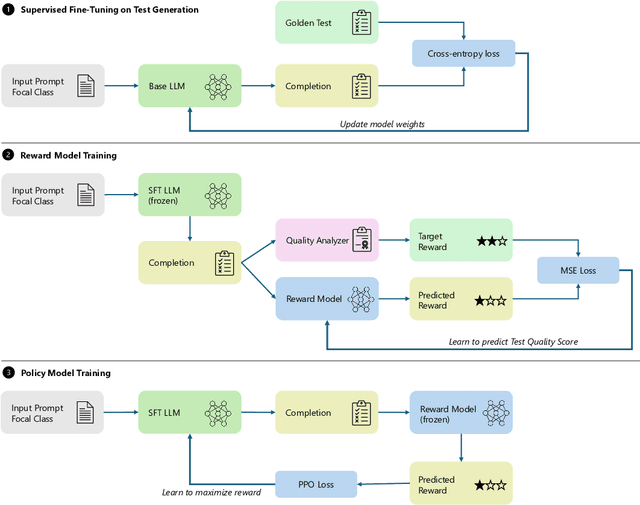
Software testing is a crucial aspect of software development, and the creation of high-quality tests that adhere to best practices is essential for effective maintenance. Recently, Large Language Models (LLMs) have gained popularity for code generation, including the automated creation of test cases. However, these LLMs are often trained on vast amounts of publicly available code, which may include test cases that do not adhere to best practices and may even contain test smells (anti-patterns). To address this issue, we propose a novel technique called Reinforcement Learning from Static Quality Metrics (RLSQM). To begin, we analyze the anti-patterns generated by the LLM and show that LLMs can generate undesirable test smells. Thus, we train specific reward models for each static quality metric, then utilize Proximal Policy Optimization (PPO) to train models for optimizing a single quality metric at a time. Furthermore, we amalgamate these rewards into a unified reward model aimed at capturing different best practices and quality aspects of tests. By comparing RL-trained models with those trained using supervised learning, we provide insights into how reliably utilize RL to improve test generation quality and into the effects of various training strategies. Our experimental results demonstrate that the RL-optimized model consistently generated high-quality test cases compared to the base LLM, improving the model by up to 21%, and successfully generates nearly 100% syntactically correct code. RLSQM also outperformed GPT-4 on four out of seven metrics. This represents a significant step towards enhancing the overall efficiency and reliability of software testing through Reinforcement Learning and static quality metrics. Our data are available at this link: https://figshare.com/s/ded476c8d4c221222849.
Sensorless Physical Human-robot Interaction Using Deep-Learning
Sep 28, 2023Physical human-robot interaction has been an area of interest for decades. Collaborative tasks, such as joint compliance, demand high-quality joint torque sensing. While external torque sensors are reliable, they come with the drawbacks of being expensive and vulnerable to impacts. To address these issues, studies have been conducted to estimate external torques using only internal signals, such as joint states and current measurements. However, insufficient attention has been given to friction hysteresis approximation, which is crucial for tasks involving extensive dynamic to static state transitions. In this paper, we propose a deep-learning-based method that leverages a novel long-term memory scheme to achieve dynamics identification, accurately approximating the static hysteresis. We also introduce modifications to the well-known Residual Learning architecture, retaining high accuracy while reducing inference time. The robustness of the proposed method is illustrated through a joint compliance and task compliance experiment.
Abdominal multi-organ segmentation in CT using Swinunter
Sep 28, 2023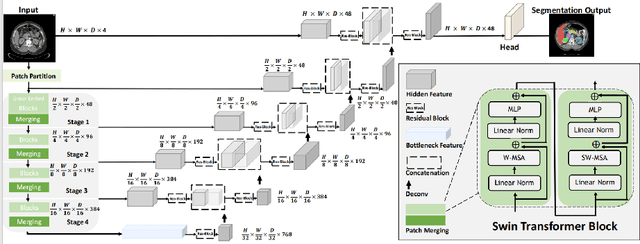

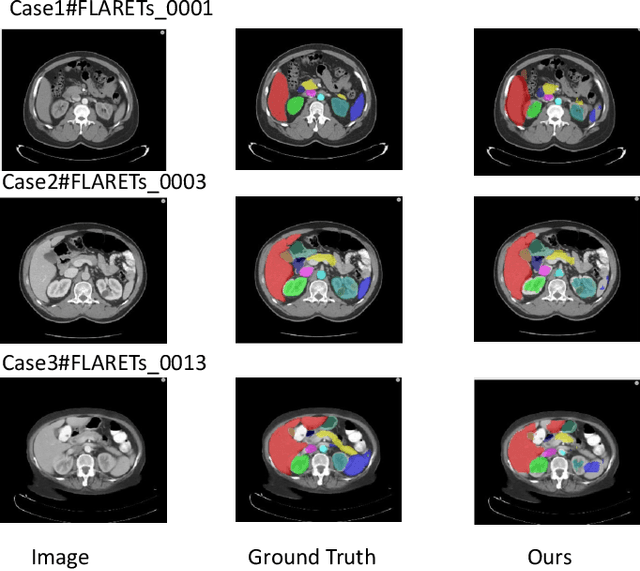
Abdominal multi-organ segmentation in computed tomography (CT) is crucial for many clinical applications including disease detection and treatment planning. Deep learning methods have shown unprecedented performance in this perspective. However, it is still quite challenging to accurately segment different organs utilizing a single network due to the vague boundaries of organs, the complex background, and the substantially different organ size scales. In this work we used make transformer-based model for training. It was found through previous years' competitions that basically all of the top 5 methods used CNN-based methods, which is likely due to the lack of data volume that prevents transformer-based methods from taking full advantage. The thousands of samples in this competition may enable the transformer-based model to have more excellent results. The results on the public validation set also show that the transformer-based model can achieve an acceptable result and inference time.
Forgetting Private Textual Sequences in Language Models via Leave-One-Out Ensemble
Sep 28, 2023Recent research has shown that language models have a tendency to memorize rare or unique token sequences in the training corpus. After deploying a model, practitioners might be asked to delete any personal information from the model by individuals' requests. Re-training the underlying model every time individuals would like to practice their rights to be forgotten is computationally expensive. We employ a teacher-student framework and propose a novel leave-one-out ensemble method to unlearn the targeted textual sequences that need to be forgotten from the model. In our approach, multiple teachers are trained on disjoint sets; for each targeted sequence to be removed, we exclude the teacher trained on the set containing this sequence and aggregate the predictions from remaining teachers to provide supervision during fine-tuning. Experiments on LibriSpeech and WikiText-103 datasets show that the proposed method achieves superior privacy-utility trade-offs than other counterparts.
Combining Survival Analysis and Machine Learning for Mass Cancer Risk Prediction using EHR data
Sep 26, 2023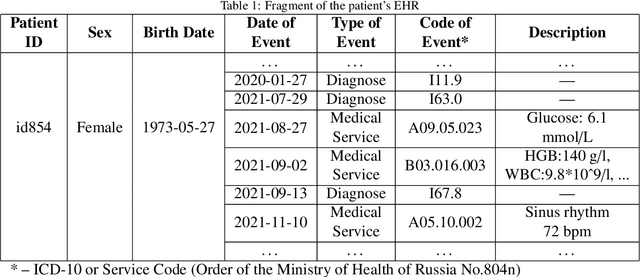

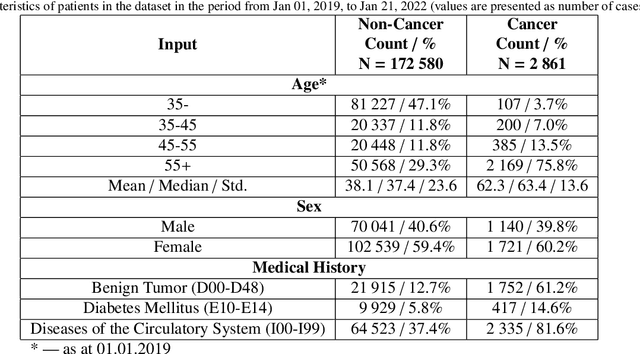
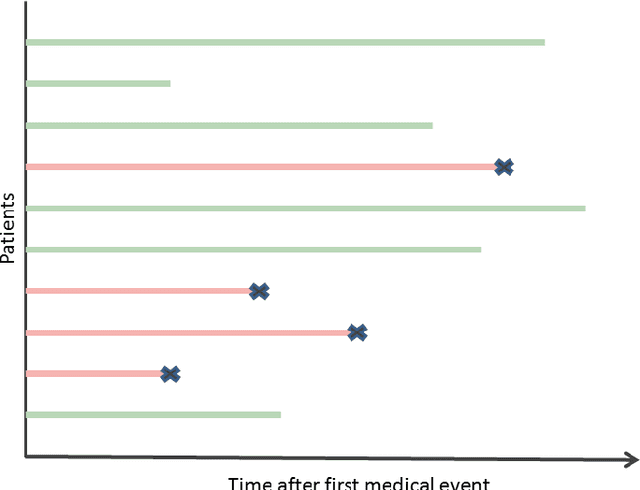
Purely medical cancer screening methods are often costly, time-consuming, and weakly applicable on a large scale. Advanced Artificial Intelligence (AI) methods greatly help cancer detection but require specific or deep medical data. These aspects affect the mass implementation of cancer screening methods. For these reasons, it is a disruptive change for healthcare to apply AI methods for mass personalized assessment of the cancer risk among patients based on the existing Electronic Health Records (EHR) volume. This paper presents a novel method for mass cancer risk prediction using EHR data. Among other methods, our one stands out by the minimum data greedy policy, requiring only a history of medical service codes and diagnoses from EHR. We formulate the problem as a binary classification. This dataset contains 175 441 de-identified patients (2 861 diagnosed with cancer). As a baseline, we implement a solution based on a recurrent neural network (RNN). We propose a method that combines machine learning and survival analysis since these approaches are less computationally heavy, can be combined into an ensemble (the Survival Ensemble), and can be reproduced in most medical institutions. We test the Survival Ensemble in some studies. Firstly, we obtain a significant difference between values of the primary metric (Average Precision) with 22.8% (ROC AUC 83.7%, F1 17.8%) for the Survival Ensemble versus 15.1% (ROC AUC 84.9%, F1 21.4%) for the Baseline. Secondly, the performance of the Survival Ensemble is also confirmed during the ablation study. Thirdly, our method exceeds age baselines by a significant margin. Fourthly, in the blind retrospective out-of-time experiment, the proposed method is reliable in cancer patient detection (9 out of 100 selected). Such results exceed the estimates of medical screenings, e.g., the best Number Needed to Screen (9 out of 1000 screenings).
Smooth Nash Equilibria: Algorithms and Complexity
Sep 21, 2023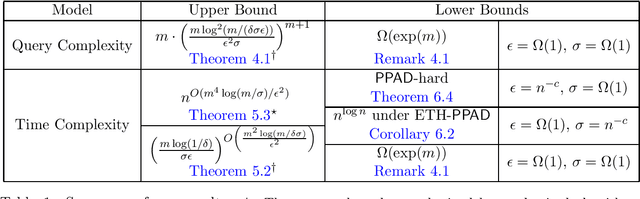
A fundamental shortcoming of the concept of Nash equilibrium is its computational intractability: approximating Nash equilibria in normal-form games is PPAD-hard. In this paper, inspired by the ideas of smoothed analysis, we introduce a relaxed variant of Nash equilibrium called $\sigma$-smooth Nash equilibrium, for a smoothness parameter $\sigma$. In a $\sigma$-smooth Nash equilibrium, players only need to achieve utility at least as high as their best deviation to a $\sigma$-smooth strategy, which is a distribution that does not put too much mass (as parametrized by $\sigma$) on any fixed action. We distinguish two variants of $\sigma$-smooth Nash equilibria: strong $\sigma$-smooth Nash equilibria, in which players are required to play $\sigma$-smooth strategies under equilibrium play, and weak $\sigma$-smooth Nash equilibria, where there is no such requirement. We show that both weak and strong $\sigma$-smooth Nash equilibria have superior computational properties to Nash equilibria: when $\sigma$ as well as an approximation parameter $\epsilon$ and the number of players are all constants, there is a constant-time randomized algorithm to find a weak $\epsilon$-approximate $\sigma$-smooth Nash equilibrium in normal-form games. In the same parameter regime, there is a polynomial-time deterministic algorithm to find a strong $\epsilon$-approximate $\sigma$-smooth Nash equilibrium in a normal-form game. These results stand in contrast to the optimal algorithm for computing $\epsilon$-approximate Nash equilibria, which cannot run in faster than quasipolynomial-time. We complement our upper bounds by showing that when either $\sigma$ or $\epsilon$ is an inverse polynomial, finding a weak $\epsilon$-approximate $\sigma$-smooth Nash equilibria becomes computationally intractable.
Identifying Simulation Model Through Alternative Techniques for a Medical Device Assembly Process
Sep 26, 2023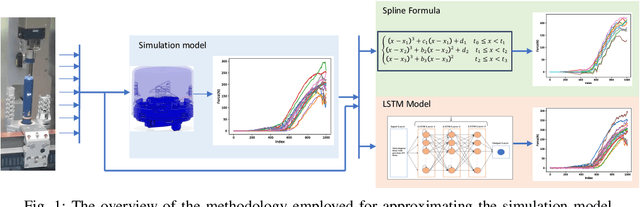
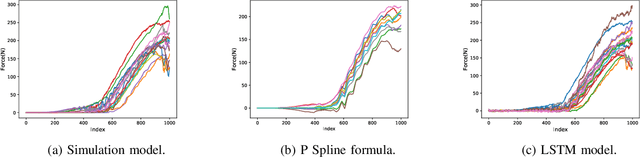
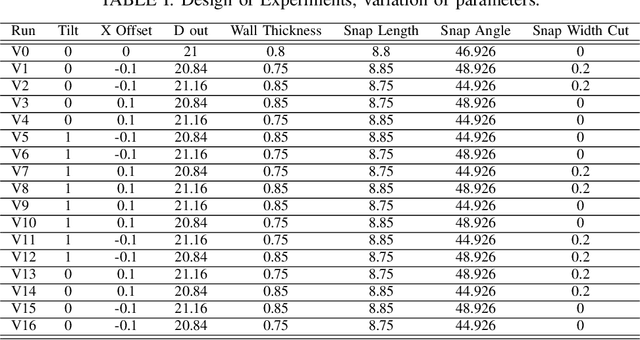

This scientific paper explores two distinct approaches for identifying and approximating the simulation model, particularly in the context of the snap process crucial to medical device assembly. Simulation models play a pivotal role in providing engineers with insights into industrial processes, enabling experimentation and troubleshooting before physical assembly. However, their complexity often results in time-consuming computations. To mitigate this complexity, we present two distinct methods for identifying simulation models: one utilizing Spline functions and the other harnessing Machine Learning (ML) models. Our goal is to create adaptable models that accurately represent the snap process and can accommodate diverse scenarios. Such models hold promise for enhancing process understanding and aiding in decision-making, especially when data availability is limited.