 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Integrated Communication, Sensing, and Computation Framework for 6G Networks
Oct 05, 2023
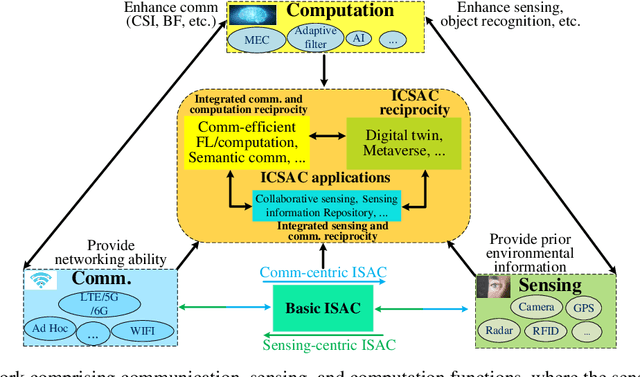
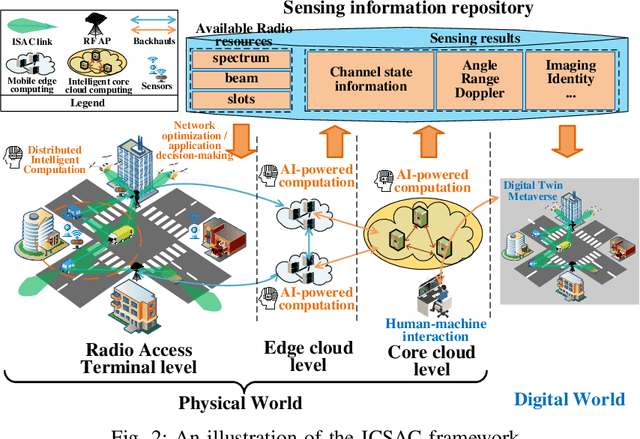
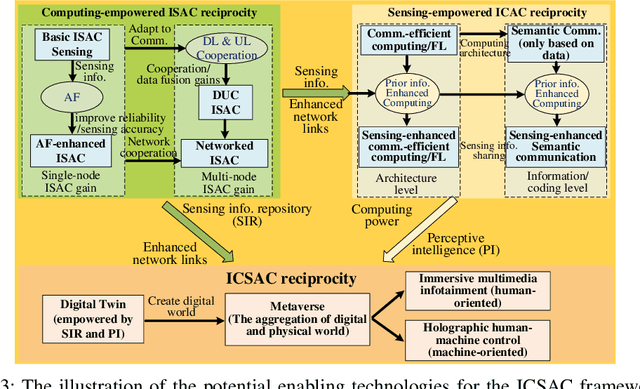
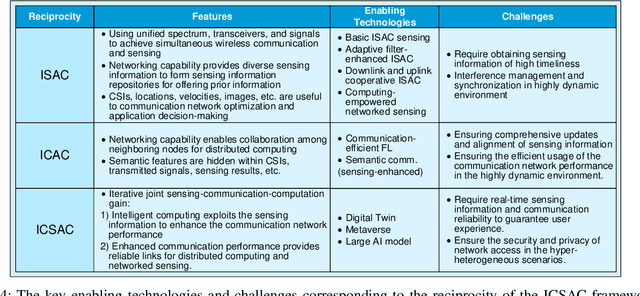
In the sixth generation (6G) era, intelligent machine network (IMN) applications, such as intelligent transportation, require collaborative machines with communication, sensing, and computation (CSC) capabilities. This article proposes an integrated communication, sensing, and computation (ICSAC) framework for 6G to achieve the reciprocity among CSC functions to enhance the reliability and latency of communication, accuracy and timeliness of sensing information acquisition, and privacy and security of computing to realize the IMN applications. Specifically, the sensing and communication functions can merge into unified platforms using the same transmit signals, and the acquired real-time sensing information can be exploited as prior information for intelligent algorithms to enhance the performance of communication networks. This is called the computing-empowered integrated sensing and communications (ISAC) reciprocity. Such reciprocity can further improve the performance of distributed computation with the assistance of networked sensing capability, which is named the sensing-empowered integrated communications and computation (ICAC) reciprocity. The above ISAC and ICAC reciprocities can enhance each other iteratively and finally lead to the ICSAC reciprocity. To achieve these reciprocities, we explore the potential enabling technologies for the ICSAC framework. Finally, we present the evaluation results of crucial enabling technologies to show the feasibility of the ICSAC framework.
ATTA: Anomaly-aware Test-Time Adaptation for Out-of-Distribution Detection in Segmentation
Sep 12, 2023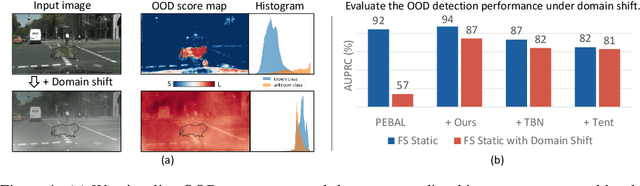

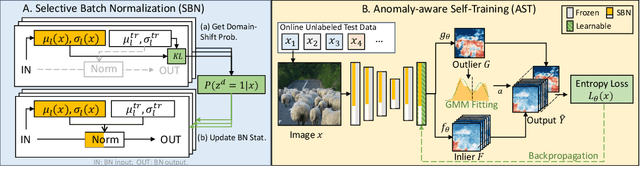
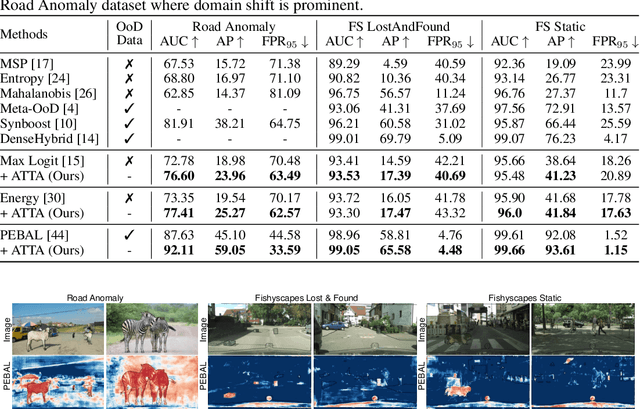
Recent advancements in dense out-of-distribution (OOD) detection have primarily focused on scenarios where the training and testing datasets share a similar domain, with the assumption that no domain shift exists between them. However, in real-world situations, domain shift often exits and significantly affects the accuracy of existing out-of-distribution (OOD) detection models. In this work, we propose a dual-level OOD detection framework to handle domain shift and semantic shift jointly. The first level distinguishes whether domain shift exists in the image by leveraging global low-level features, while the second level identifies pixels with semantic shift by utilizing dense high-level feature maps. In this way, we can selectively adapt the model to unseen domains as well as enhance model's capacity in detecting novel classes. We validate the efficacy of our proposed method on several OOD segmentation benchmarks, including those with significant domain shifts and those without, observing consistent performance improvements across various baseline models.
ObVi-SLAM: Long-Term Object-Visual SLAM
Sep 26, 2023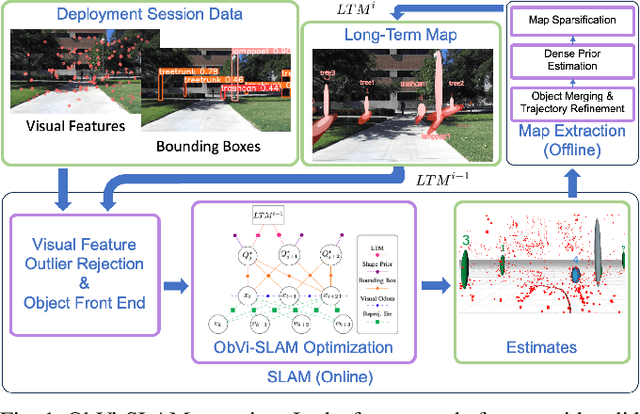

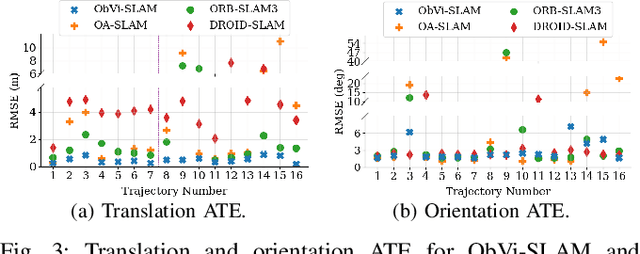
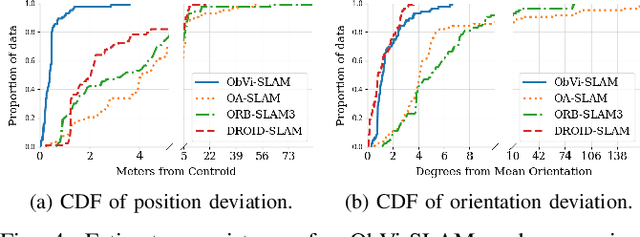
Robots responsible for tasks over long time scales must be able to localize consistently and scalably amid geometric, viewpoint, and appearance changes. Existing visual SLAM approaches rely on low-level feature descriptors that are not robust to such environmental changes and result in large map sizes that scale poorly over long-term deployments. In contrast, object detections are robust to environmental variations and lead to more compact representations, but most object-based SLAM systems target short-term indoor deployments with close objects. In this paper, we introduce ObVi-SLAM to overcome these challenges by leveraging the best of both approaches. ObVi-SLAM uses low-level visual features for high-quality short-term visual odometry; and to ensure global, long-term consistency, ObVi-SLAM builds an uncertainty-aware long-term map of persistent objects and updates it after every deployment. By evaluating ObVi-SLAM on data from 16 deployment sessions spanning different weather and lighting conditions, we empirically show that ObVi-SLAM generates accurate localization estimates consistent over long-time scales in spite of varying appearance conditions.
Case Studies of Causal Discovery from IT Monitoring Time Series
Jul 28, 2023
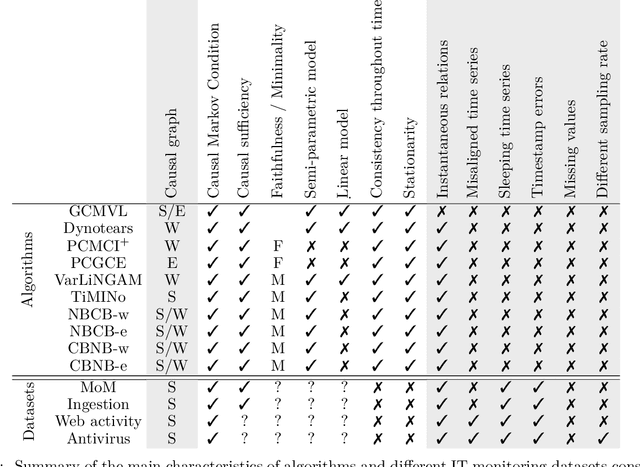
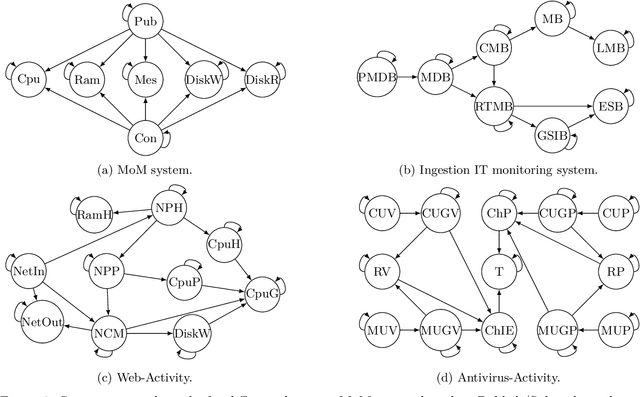
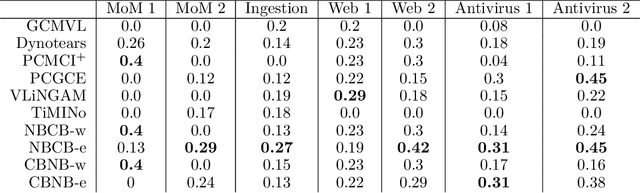
Information technology (IT) systems are vital for modern businesses, handling data storage, communication, and process automation. Monitoring these systems is crucial for their proper functioning and efficiency, as it allows collecting extensive observational time series data for analysis. The interest in causal discovery is growing in IT monitoring systems as knowing causal relations between different components of the IT system helps in reducing downtime, enhancing system performance and identifying root causes of anomalies and incidents. It also allows proactive prediction of future issues through historical data analysis. Despite its potential benefits, applying causal discovery algorithms on IT monitoring data poses challenges, due to the complexity of the data. For instance, IT monitoring data often contains misaligned time series, sleeping time series, timestamp errors and missing values. This paper presents case studies on applying causal discovery algorithms to different IT monitoring datasets, highlighting benefits and ongoing challenges.
Dark Side Augmentation: Generating Diverse Night Examples for Metric Learning
Sep 28, 2023Image retrieval methods based on CNN descriptors rely on metric learning from a large number of diverse examples of positive and negative image pairs. Domains, such as night-time images, with limited availability and variability of training data suffer from poor retrieval performance even with methods performing well on standard benchmarks. We propose to train a GAN-based synthetic-image generator, translating available day-time image examples into night images. Such a generator is used in metric learning as a form of augmentation, supplying training data to the scarce domain. Various types of generators are evaluated and analyzed. We contribute with a novel light-weight GAN architecture that enforces the consistency between the original and translated image through edge consistency. The proposed architecture also allows a simultaneous training of an edge detector that operates on both night and day images. To further increase the variability in the training examples and to maximize the generalization of the trained model, we propose a novel method of diverse anchor mining. The proposed method improves over the state-of-the-art results on a standard Tokyo 24/7 day-night retrieval benchmark while preserving the performance on Oxford and Paris datasets. This is achieved without the need of training image pairs of matching day and night images. The source code is available at https://github.com/mohwald/gandtr .
* 11 pages, 4 figures, 8 tables
Hybrid State Space-based Learning for Sequential Data Prediction with Joint Optimization
Sep 19, 2023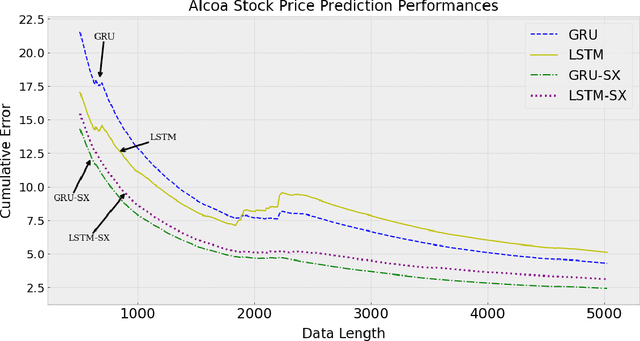
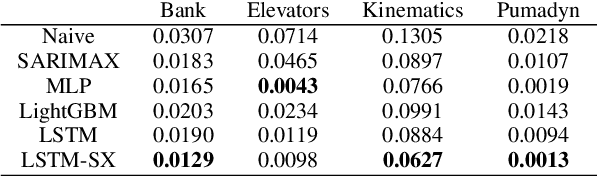
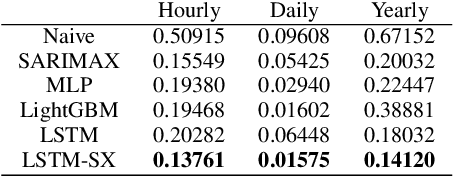
We investigate nonlinear prediction/regression in an online setting and introduce a hybrid model that effectively mitigates, via a joint mechanism through a state space formulation, the need for domain-specific feature engineering issues of conventional nonlinear prediction models and achieves an efficient mix of nonlinear and linear components. In particular, we use recursive structures to extract features from raw sequential sequences and a traditional linear time series model to deal with the intricacies of the sequential data, e.g., seasonality, trends. The state-of-the-art ensemble or hybrid models typically train the base models in a disjoint manner, which is not only time consuming but also sub-optimal due to the separation of modeling or independent training. In contrast, as the first time in the literature, we jointly optimize an enhanced recurrent neural network (LSTM) for automatic feature extraction from raw data and an ARMA-family time series model (SARIMAX) for effectively addressing peculiarities associated with time series data. We achieve this by introducing novel state space representations for the base models, which are then combined to provide a full state space representation of the hybrid or the ensemble. Hence, we are able to jointly optimize both models in a single pass via particle filtering, for which we also provide the update equations. The introduced architecture is generic so that one can use other recurrent architectures, e.g., GRUs, traditional time series-specific models, e.g., ETS or other optimization methods, e.g., EKF, UKF. Due to such novel combination and joint optimization, we demonstrate significant improvements in widely publicized real life competition datasets. We also openly share our code for further research and replicability of our results.
GeoAdapt: Self-Supervised Test-Time Adaption in LiDAR Place Recognition Using Geometric Priors
Aug 09, 2023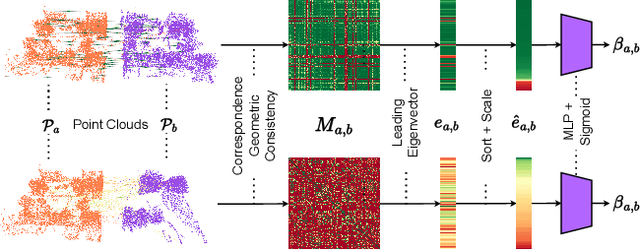
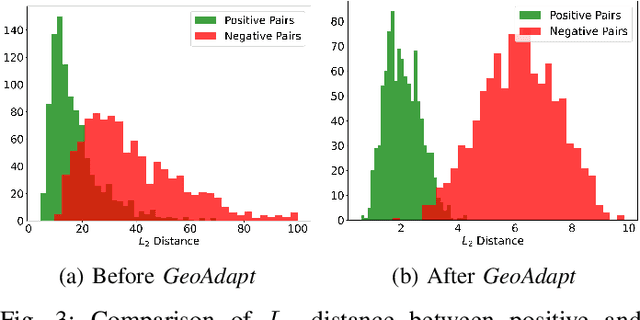
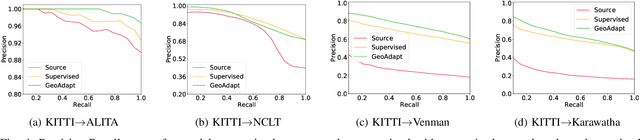

LiDAR place recognition approaches based on deep learning suffer a significant degradation in performance when there is a shift between the distribution of the training and testing datasets, with re-training often required to achieve top performance. However, obtaining accurate ground truth on new environments can be prohibitively expensive, especially in complex or GPS-deprived environments. To address this issue we propose GeoAdapt, which introduces a novel auxiliary classification head to generate pseudo-labels for re-training on unseen environments in a self-supervised manner. GeoAdapt uses geometric consistency as a prior to improve the robustness of our generated pseudo-labels against domain shift, improving the performance and reliability of our Test-Time Adaptation approach. Comprehensive experiments show that GeoAdapt significantly boosts place recognition performance across moderate to severe domain shifts, and is competitive with fully supervised test-time adaptation approaches. Our code will be available at https://github.com/csiro-robotics/GeoAdapt.
Semantic segmentation of longitudinal thermal images for identification of hot and cool spots in urban areas
Oct 06, 2023This work presents the analysis of semantically segmented, longitudinally, and spatially rich thermal images collected at the neighborhood scale to identify hot and cool spots in urban areas. An infrared observatory was operated over a few months to collect thermal images of different types of buildings on the educational campus of the National University of Singapore. A subset of the thermal image dataset was used to train state-of-the-art deep learning models to segment various urban features such as buildings, vegetation, sky, and roads. It was observed that the U-Net segmentation model with `resnet34' CNN backbone has the highest mIoU score of 0.99 on the test dataset, compared to other models such as DeepLabV3, DeeplabV3+, FPN, and PSPnet. The masks generated using the segmentation models were then used to extract the temperature from thermal images and correct for differences in the emissivity of various urban features. Further, various statistical measure of the temperature extracted using the predicted segmentation masks is shown to closely match the temperature extracted using the ground truth masks. Finally, the masks were used to identify hot and cool spots in the urban feature at various instances of time. This forms one of the very few studies demonstrating the automated analysis of thermal images, which can be of potential use to urban planners for devising mitigation strategies for reducing the urban heat island (UHI) effect, improving building energy efficiency, and maximizing outdoor thermal comfort.
Beyond Myopia: Learning from Positive and Unlabeled Data through Holistic Predictive Trends
Oct 06, 2023Learning binary classifiers from positive and unlabeled data (PUL) is vital in many real-world applications, especially when verifying negative examples is difficult. Despite the impressive empirical performance of recent PUL methods, challenges like accumulated errors and increased estimation bias persist due to the absence of negative labels. In this paper, we unveil an intriguing yet long-overlooked observation in PUL: \textit{resampling the positive data in each training iteration to ensure a balanced distribution between positive and unlabeled examples results in strong early-stage performance. Furthermore, predictive trends for positive and negative classes display distinctly different patterns.} Specifically, the scores (output probability) of unlabeled negative examples consistently decrease, while those of unlabeled positive examples show largely chaotic trends. Instead of focusing on classification within individual time frames, we innovatively adopt a holistic approach, interpreting the scores of each example as a temporal point process (TPP). This reformulates the core problem of PUL as recognizing trends in these scores. We then propose a novel TPP-inspired measure for trend detection and prove its asymptotic unbiasedness in predicting changes. Notably, our method accomplishes PUL without requiring additional parameter tuning or prior assumptions, offering an alternative perspective for tackling this problem. Extensive experiments verify the superiority of our method, particularly in a highly imbalanced real-world setting, where it achieves improvements of up to $11.3\%$ in key metrics. The code is available at \href{https://github.com/wxr99/HolisticPU}{https://github.com/wxr99/HolisticPU}.
* 25 pages
Ultrafast and Ultralight Network-Based Intelligent System for Real-time Diagnosis of Ear diseases in Any Devices
Aug 21, 2023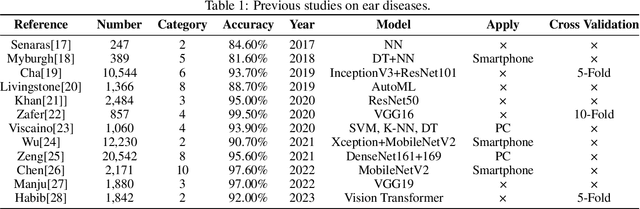
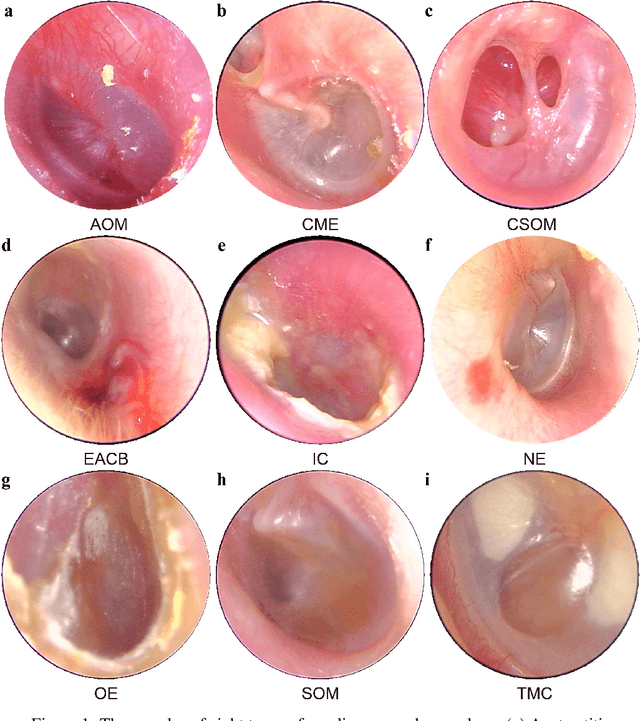

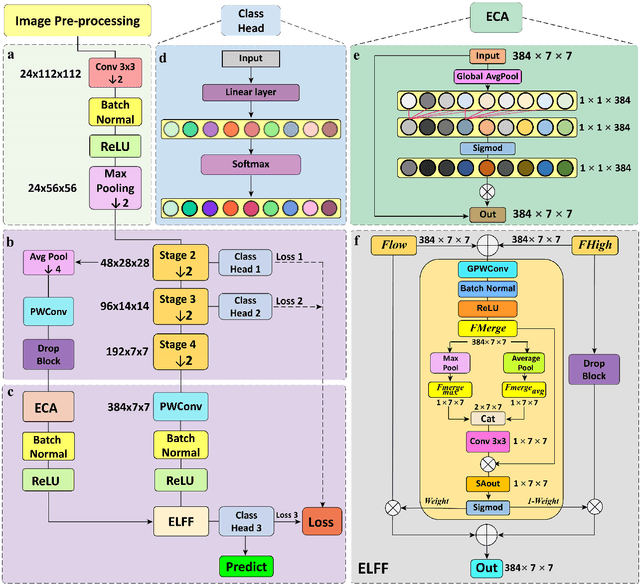
Traditional ear disease diagnosis heavily depends on experienced specialists and specialized equipment, frequently resulting in misdiagnoses, treatment delays, and financial burdens for some patients. Utilizing deep learning models for efficient ear disease diagnosis has proven effective and affordable. However, existing research overlooked model inference speed and parameter size required for deployment. To tackle these challenges, we constructed a large-scale dataset comprising eight ear disease categories and normal ear canal samples from two hospitals. Inspired by ShuffleNetV2, we developed Best-EarNet, an ultrafast and ultralight network enabling real-time ear disease diagnosis. Best-EarNet incorporates the novel Local-Global Spatial Feature Fusion Module which can capture global and local spatial information simultaneously and guide the network to focus on crucial regions within feature maps at various levels, mitigating low accuracy issues. Moreover, our network uses multiple auxiliary classification heads for efficient parameter optimization. With 0.77M parameters, Best-EarNet achieves an average frames per second of 80 on CPU. Employing transfer learning and five-fold cross-validation with 22,581 images from Hospital-1, the model achieves an impressive 95.23% accuracy. External testing on 1,652 images from Hospital-2 validates its performance, yielding 92.14% accuracy. Compared to state-of-the-art networks, Best-EarNet establishes a new state-of-the-art (SOTA) in practical applications. Most importantly, we developed an intelligent diagnosis system called Ear Keeper, which can be deployed on common electronic devices. By manipulating a compact electronic otoscope, users can perform comprehensive scanning and diagnosis of the ear canal using real-time video. This study provides a novel paradigm for ear endoscopy and other medical endoscopic image recognition applications.