 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Can Language Models Employ the Socratic Method? Experiments with Code Debugging
Oct 04, 2023
When employing the Socratic method of teaching, instructors guide students toward solving a problem on their own rather than providing the solution directly. While this strategy can substantially improve learning outcomes, it is usually time-consuming and cognitively demanding. Automated Socratic conversational agents can augment human instruction and provide the necessary scale, however their development is hampered by the lack of suitable data for training and evaluation. In this paper, we introduce a manually created dataset of multi-turn Socratic advice that is aimed at helping a novice programmer fix buggy solutions to simple computational problems. The dataset is then used for benchmarking the Socratic debugging abilities of a number of language models, ranging from fine-tuning the instruction-based text-to-text transformer Flan-T5 to zero-shot and chain of thought prompting of the much larger GPT-4. The code and datasets are made freely available for research at the link below. https://github.com/taisazero/socratic-debugging-benchmark
Kernel-based function learning in dynamic and non stationary environments
Oct 04, 2023One central theme in machine learning is function estimation from sparse and noisy data. An example is supervised learning where the elements of the training set are couples, each containing an input location and an output response. In the last decades, a substantial amount of work has been devoted to design estimators for the unknown function and to study their convergence to the optimal predictor, also characterizing the learning rate. These results typically rely on stationary assumptions where input locations are drawn from a probability distribution that does not change in time. In this work, we consider kernel-based ridge regression and derive convergence conditions under non stationary distributions, addressing also cases where stochastic adaption may happen infinitely often. This includes the important exploration-exploitation problems where e.g. a set of agents/robots has to monitor an environment to reconstruct a sensorial field and their movements rules are continuously updated on the basis of the acquired knowledge on the field and/or the surrounding environment.
Estimation of Models with Limited Data by Leveraging Shared Structure
Oct 04, 2023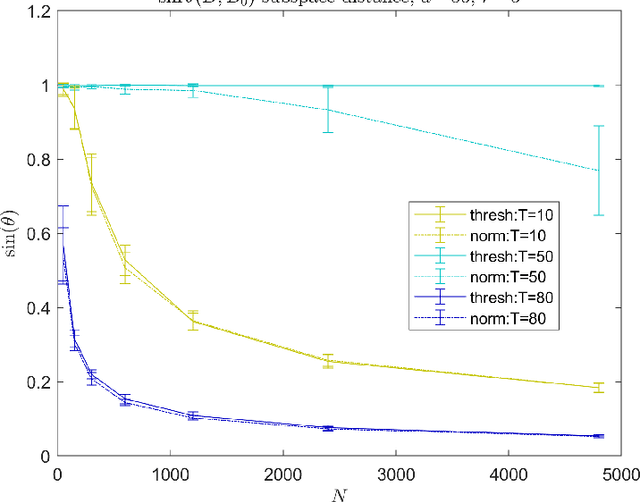
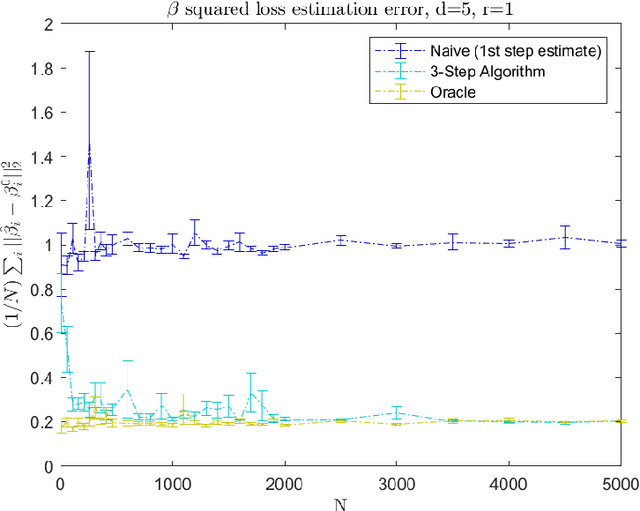
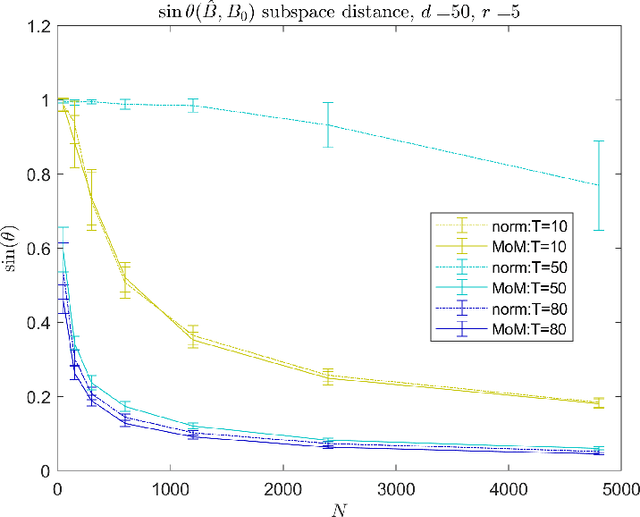
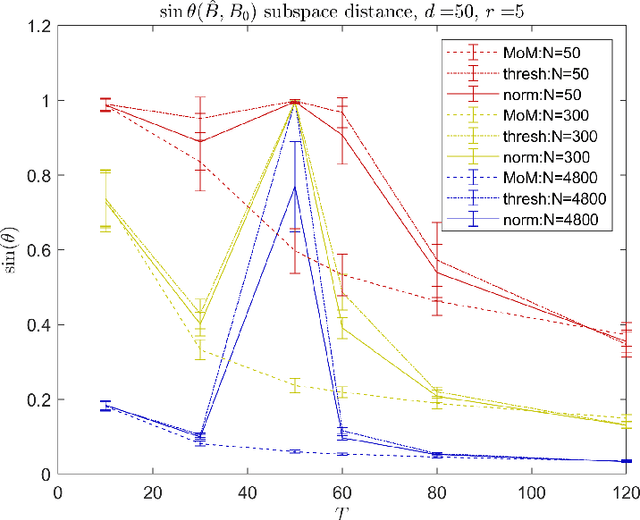
Modern data sets, such as those in healthcare and e-commerce, are often derived from many individuals or systems but have insufficient data from each source alone to separately estimate individual, often high-dimensional, model parameters. If there is shared structure among systems however, it may be possible to leverage data from other systems to help estimate individual parameters, which could otherwise be non-identifiable. In this paper, we assume systems share a latent low-dimensional parameter space and propose a method for recovering $d$-dimensional parameters for $N$ different linear systems, even when there are only $T<d$ observations per system. To do so, we develop a three-step algorithm which estimates the low-dimensional subspace spanned by the systems' parameters and produces refined parameter estimates within the subspace. We provide finite sample subspace estimation error guarantees for our proposed method. Finally, we experimentally validate our method on simulations with i.i.d. regression data and as well as correlated time series data.
Asset Bundling for Wind Power Forecasting
Sep 28, 2023The growing penetration of intermittent, renewable generation in US power grids, especially wind and solar generation, results in increased operational uncertainty. In that context, accurate forecasts are critical, especially for wind generation, which exhibits large variability and is historically harder to predict. To overcome this challenge, this work proposes a novel Bundle-Predict-Reconcile (BPR) framework that integrates asset bundling, machine learning, and forecast reconciliation techniques. The BPR framework first learns an intermediate hierarchy level (the bundles), then predicts wind power at the asset, bundle, and fleet level, and finally reconciles all forecasts to ensure consistency. This approach effectively introduces an auxiliary learning task (predicting the bundle-level time series) to help the main learning tasks. The paper also introduces new asset-bundling criteria that capture the spatio-temporal dynamics of wind power time series. Extensive numerical experiments are conducted on an industry-size dataset of 283 wind farms in the MISO footprint. The experiments consider short-term and day-ahead forecasts, and evaluates a large variety of forecasting models that include weather predictions as covariates. The results demonstrate the benefits of BPR, which consistently and significantly improves forecast accuracy over baselines, especially at the fleet level.
Network Traffic Classification based on Single Flow Time Series Analysis
Jul 25, 2023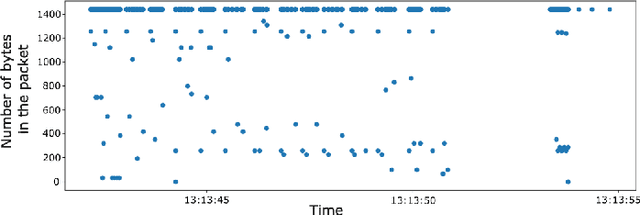
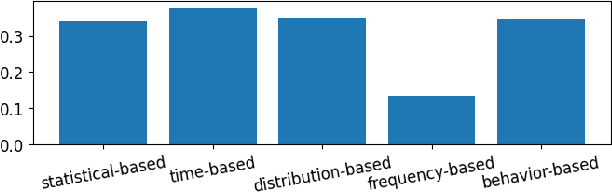
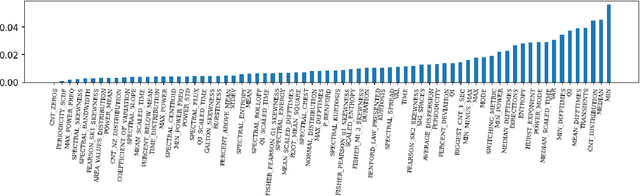

Network traffic monitoring using IP flows is used to handle the current challenge of analyzing encrypted network communication. Nevertheless, the packet aggregation into flow records naturally causes information loss; therefore, this paper proposes a novel flow extension for traffic features based on the time series analysis of the Single Flow Time series, i.e., a time series created by the number of bytes in each packet and its timestamp. We propose 69 universal features based on the statistical analysis of data points, time domain analysis, packet distribution within the flow timespan, time series behavior, and frequency domain analysis. We have demonstrated the usability and universality of the proposed feature vector for various network traffic classification tasks using 15 well-known publicly available datasets. Our evaluation shows that the novel feature vector achieves classification performance similar or better than related works on both binary and multiclass classification tasks. In more than half of the evaluated tasks, the classification performance increased by up to 5\%.
Stochastic Gradient Descent with Preconditioned Polyak Step-size
Oct 03, 2023Stochastic Gradient Descent (SGD) is one of the many iterative optimization methods that are widely used in solving machine learning problems. These methods display valuable properties and attract researchers and industrial machine learning engineers with their simplicity. However, one of the weaknesses of this type of methods is the necessity to tune learning rate (step-size) for every loss function and dataset combination to solve an optimization problem and get an efficient performance in a given time budget. Stochastic Gradient Descent with Polyak Step-size (SPS) is a method that offers an update rule that alleviates the need of fine-tuning the learning rate of an optimizer. In this paper, we propose an extension of SPS that employs preconditioning techniques, such as Hutchinson's method, Adam, and AdaGrad, to improve its performance on badly scaled and/or ill-conditioned datasets.
Transformers versus LSTMs for electronic trading
Sep 20, 2023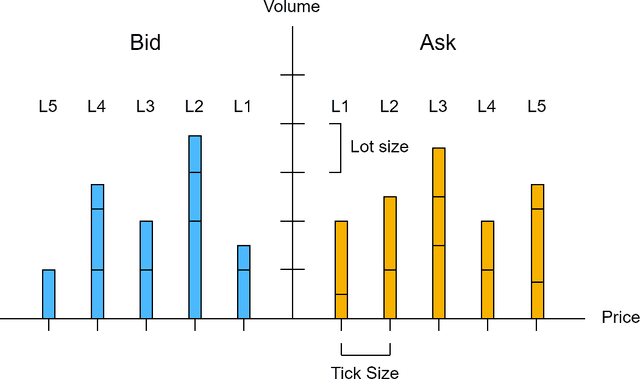
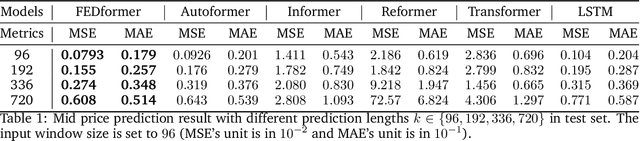

With the rapid development of artificial intelligence, long short term memory (LSTM), one kind of recurrent neural network (RNN), has been widely applied in time series prediction. Like RNN, Transformer is designed to handle the sequential data. As Transformer achieved great success in Natural Language Processing (NLP), researchers got interested in Transformer's performance on time series prediction, and plenty of Transformer-based solutions on long time series forecasting have come out recently. However, when it comes to financial time series prediction, LSTM is still a dominant architecture. Therefore, the question this study wants to answer is: whether the Transformer-based model can be applied in financial time series prediction and beat LSTM. To answer this question, various LSTM-based and Transformer-based models are compared on multiple financial prediction tasks based on high-frequency limit order book data. A new LSTM-based model called DLSTM is built and new architecture for the Transformer-based model is designed to adapt for financial prediction. The experiment result reflects that the Transformer-based model only has the limited advantage in absolute price sequence prediction. The LSTM-based models show better and more robust performance on difference sequence prediction, such as price difference and price movement.
Physics-Informed Graph Neural Network for Dynamic Reconfiguration of Power Systems
Oct 01, 2023To maintain a reliable grid we need fast decision-making algorithms for complex problems like Dynamic Reconfiguration (DyR). DyR optimizes distribution grid switch settings in real-time to minimize grid losses and dispatches resources to supply loads with available generation. DyR is a mixed-integer problem and can be computationally intractable to solve for large grids and at fast timescales. We propose GraPhyR, a Physics-Informed Graph Neural Network (GNNs) framework tailored for DyR. We incorporate essential operational and connectivity constraints directly within the GNN framework and train it end-to-end. Our results show that GraPhyR is able to learn to optimize the DyR task.
NoxTrader: LSTM-Based Stock Return Momentum Prediction
Oct 01, 2023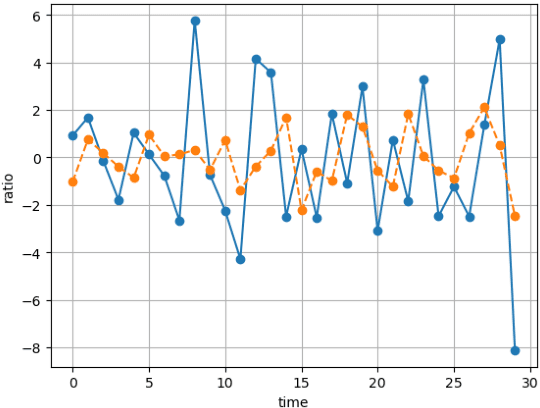
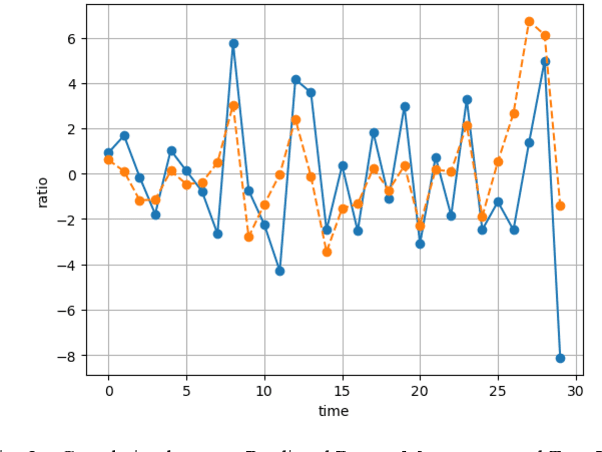
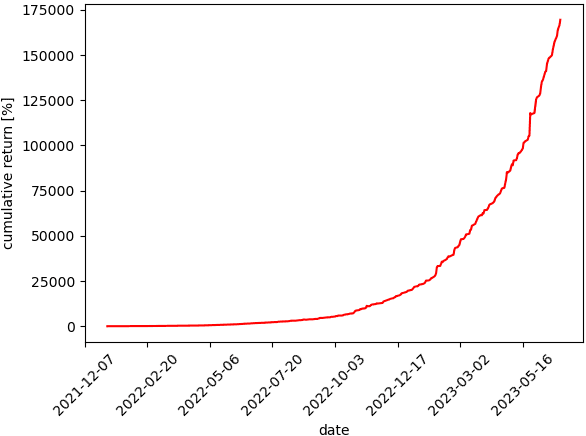
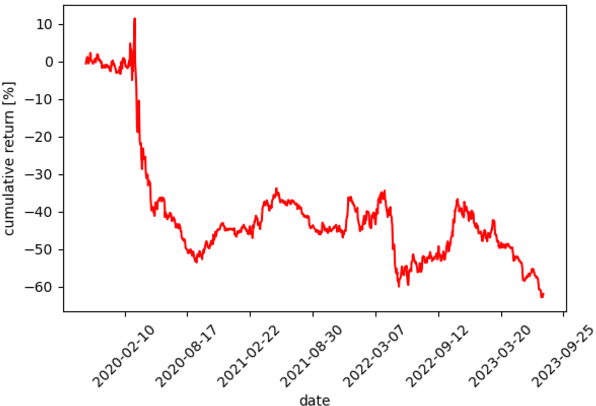
We introduce NoxTrader, which is designed for portfolio construction and trading execution, aims at generating profitable outcomes. The primary focus of NoxTrader is on stock market trading with an emphasis on cultivating moderate to long-term profits. The underlying learning process of NoxTrader hinges on the assimilation of insights gleaned from historical trading data, primarily hinging on time-series analysis due to the inherent nature of the employed dataset. We delineate the sequential progression encompassing data acquisition, feature engineering, predictive modeling, parameter configuration, establishment of a rigorous backtesting framework, and ultimately position NoxTrader as a testament to the prospective viability of algorithmic trading models within real-world trading scenarios.
In the Blink of an Eye: Event-based Emotion Recognition
Oct 06, 2023We introduce a wearable single-eye emotion recognition device and a real-time approach to recognizing emotions from partial observations of an emotion that is robust to changes in lighting conditions. At the heart of our method is a bio-inspired event-based camera setup and a newly designed lightweight Spiking Eye Emotion Network (SEEN). Compared to conventional cameras, event-based cameras offer a higher dynamic range (up to 140 dB vs. 80 dB) and a higher temporal resolution. Thus, the captured events can encode rich temporal cues under challenging lighting conditions. However, these events lack texture information, posing problems in decoding temporal information effectively. SEEN tackles this issue from two different perspectives. First, we adopt convolutional spiking layers to take advantage of the spiking neural network's ability to decode pertinent temporal information. Second, SEEN learns to extract essential spatial cues from corresponding intensity frames and leverages a novel weight-copy scheme to convey spatial attention to the convolutional spiking layers during training and inference. We extensively validate and demonstrate the effectiveness of our approach on a specially collected Single-eye Event-based Emotion (SEE) dataset. To the best of our knowledge, our method is the first eye-based emotion recognition method that leverages event-based cameras and spiking neural network.