 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Formal Resilience Framework for Cyber-Physical Embodied Systems under Device-Level Cyberattacks
Jun 15, 2026In cyber-physical systems (CPSs), fault tolerance is traditionally achieved by analysing sensor and actuator outputs, detecting progressive drift or sudden failures, and initiating suitable tolerance mechanisms. Reasonable under general failure models, this approach fails to capture nuanced disruptions caused by cyberattacks, which may employ subtle strategies. This is particularly critical in embodied CPSs, where computational and physical devices not only have an active role in task completion, but also in embodiment preservation (that is, maintaining the system's physical integrity). To prevent structural physical damage, embodied CPSs require a framework that enables proactive response to cyberattacks. This paper proposes a formal dependability framework that incorporates IDS information into resilience evaluation predicates, enabling assessment of tolerance to disruption and degradation. The framework supports structured reasoning about how cyberattacks affect task execution and embodiment preservation, and whether mitigation strategies must be deployed. Analytical examples demonstrate its analytical capability and soundness, establishing a theoretical foundation for dependable and secure embodied CPSs.
Refusal Before Decoding: Detecting and Exploiting Refusal Signals in Intermediate LLM Activations
May 27, 2026In this paper, we investigate whether refusal behavior can be predicted from LLM intermediate activations before decoding using linear probes trained on residual stream activations at each transformer block. We find that refusal is linearly decodable well before the final layer, indicating that safety-relevant behavior is represented in intermediate activations before output generation. To test whether this signal is actionable, we introduce Mechanistic AutoDAN, a probe-guided variant of AutoDAN that replaces full-model fitness evaluation with partial forward passes and probe-based scoring inside a genetic prompt search loop. Across the evaluated models, our method achieves attack success rates competitive with vanilla AutoDAN while reducing per-iteration search time by up to 72%, and probe-guided prompts match or exceed AutoDAN's cross-model transfer in several configurations. We further find that the usefulness of probe guidance increases with model scale. Our results show that refusal is not only observable at the output level, but is encoded as a structured and actionable signal in intermediate LLM activations.
Learning stochasticity: a nonparametric framework for intrinsic noise estimation
Nov 17, 2025Understanding the principles that govern dynamical systems is a central challenge across many scientific domains, including biology and ecology. Incomplete knowledge of nonlinear interactions and stochastic effects often renders bottom-up modeling approaches ineffective, motivating the development of methods that can discover governing equations directly from data. In such contexts, parametric models often struggle without strong prior knowledge, especially when estimating intrinsic noise. Nonetheless, incorporating stochastic effects is often essential for understanding the dynamic behavior of complex systems such as gene regulatory networks and signaling pathways. To address these challenges, we introduce Trine (Three-phase Regression for INtrinsic noisE), a nonparametric, kernel-based framework that infers state-dependent intrinsic noise from time-series data. Trine features a three-stage algorithm that com- bines analytically solvable subproblems with a structured kernel architecture that captures both abrupt noise-driven fluctuations and smooth, state-dependent changes in variance. We validate Trine on biological and ecological systems, demonstrating its ability to uncover hidden dynamics without relying on predefined parametric assumptions. Across several benchmark problems, Trine achieves performance comparable to that of an oracle. Biologically, this oracle can be viewed as an idealized observer capable of directly tracking the random fluctuations in molecular concentrations or reaction events within a cell. The Trine framework thus opens new avenues for understanding how intrinsic noise affects the behavior of complex systems.
Large Language Models and Code Security: A Systematic Literature Review
Dec 19, 2024Large Language Models (LLMs) have emerged as powerful tools for automating various programming tasks, including security-related ones, such as detecting and fixing vulnerabilities. Despite their promising capabilities, when required to produce or modify pre-existing code, LLMs could introduce vulnerabilities unbeknown to the programmer. When analyzing code, they could miss clear vulnerabilities or signal nonexistent ones. In this Systematic Literature Review (SLR), we aim to investigate both the security benefits and potential drawbacks of using LLMs for a variety of code-related tasks. In particular, first we focus on the types of vulnerabilities that could be introduced by LLMs, when used for producing code. Second, we analyze the capabilities of LLMs to detect and fix vulnerabilities, in any given code, and how the prompting strategy of choice impacts their performance in these two tasks. Last, we provide an in-depth analysis on how data poisoning attacks on LLMs can impact performance in the aforementioned tasks.
Cybersecurity and Embodiment Integrity for Modern Robots: A Conceptual Framework
Jan 15, 2024



Modern robots are stepping away from monolithic entities built using ad-hoc sensors and actuators, due to new technologies and communication paradigms, such as the Internet of Things (IoT) and the Robotic Operating System (ROS). Using such paradigms, robots can be built by acquiring heterogeneous standard devices and putting them in communication with each other. This approach brings high degrees of modularity, but it also yields uncertainty of providing cybersecurity assurances, and guarantees on the integrity of the embodiment. In this paper, we first illustrate how cyberattacks on different devices can have radically different consequences on the robot's ability to complete its tasks and preserve its embodiment. We also claim that modern robots should have self-awareness for what it concerns such aspects, and formulate the different characteristics that robots should integrate for doing so. Then, we show that achieving these propositions requires that robots possess at least three properties that conceptually link devices and tasks. Last, we reflect on how these three properties could be achieved in a larger conceptual framework.
Kernel-based function learning in dynamic and non stationary environments
Oct 04, 2023One central theme in machine learning is function estimation from sparse and noisy data. An example is supervised learning where the elements of the training set are couples, each containing an input location and an output response. In the last decades, a substantial amount of work has been devoted to design estimators for the unknown function and to study their convergence to the optimal predictor, also characterizing the learning rate. These results typically rely on stationary assumptions where input locations are drawn from a probability distribution that does not change in time. In this work, we consider kernel-based ridge regression and derive convergence conditions under non stationary distributions, addressing also cases where stochastic adaption may happen infinitely often. This includes the important exploration-exploitation problems where e.g. a set of agents/robots has to monitor an environment to reconstruct a sensorial field and their movements rules are continuously updated on the basis of the acquired knowledge on the field and/or the surrounding environment.
A Machine Learning-based Approach to Detect Threats in Bio-Cyber DNA Storage Systems
Sep 28, 2020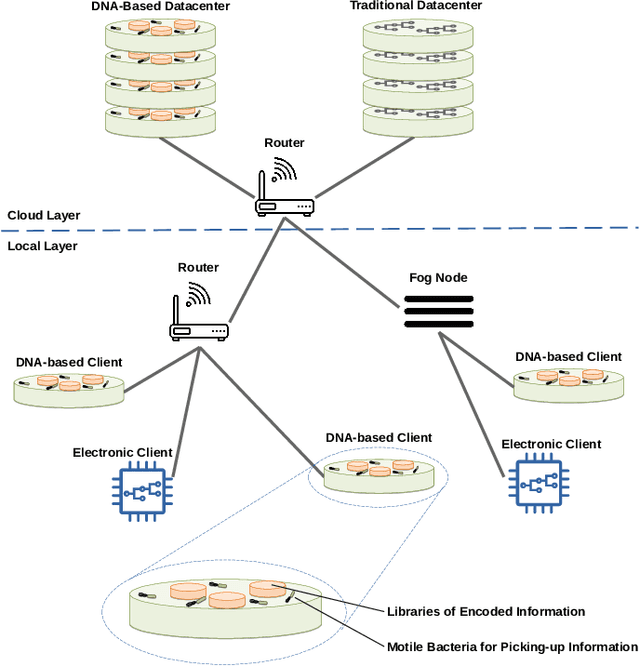
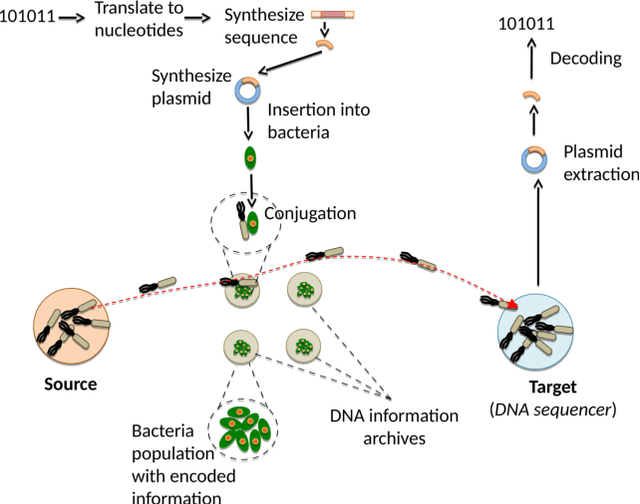
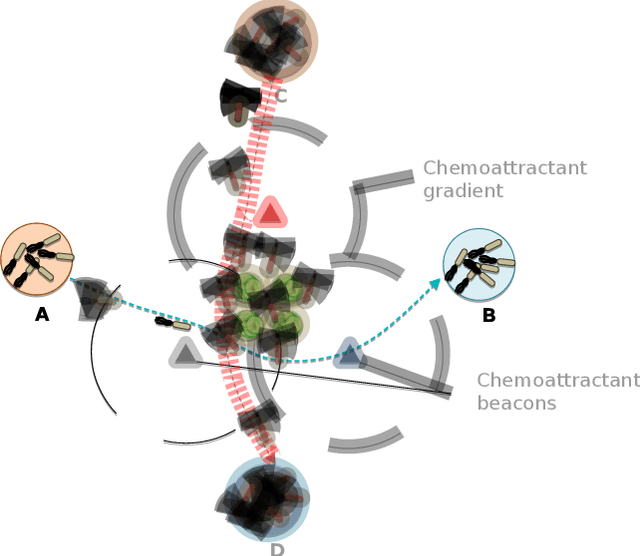
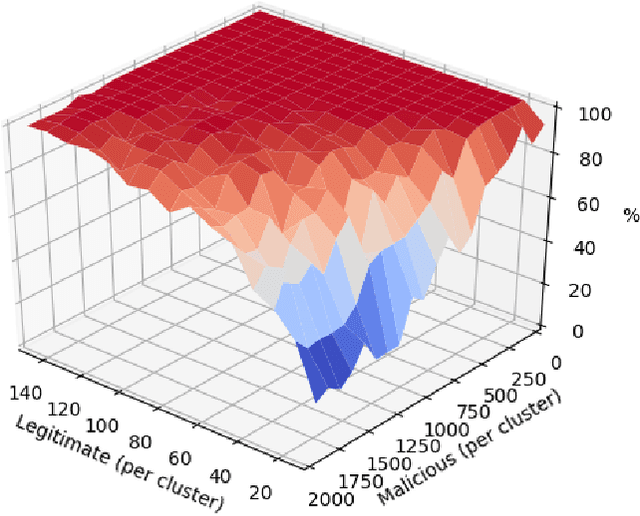
Data storage is one of the main computing issues of this century. Not only storage devices are converging to strict physical limits, but also the amount of data generated by users is growing at an unbelievable rate. To face these challenges, data centres grew constantly over the past decades. However, this growth comes with a price, particularly from the environmental point of view. Among various promising media, DNA is one of the most fascinating candidate. In our previous work, we have proposed an automated archival architecture which uses bioengineered bacteria to store and retrieve data, previously encoded into DNA. This storage technique is one example of how biological media can deliver power-efficient storing solutions. The similarities between these biological media and classical ones can also be a drawback, as malicious parties might replicate traditional attacks on the former archival system, using biological instruments and techniques. In this paper, first we analyse the main characteristics of our storage system and the different types of attacks that could be executed on it. Then, aiming at identifying on-going attacks, we propose and evaluate detection techniques, which rely on traditional metrics and machine learning algorithms. We identify and adapt two suitable metrics for this purpose, namely generalized entropy and information distance. Moreover, our trained models achieve an AUROC over 0.99 and AUPRC over 0.91.