 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
CRUISE-Screening: Living Literature Reviews Toolbox
Sep 04, 2023
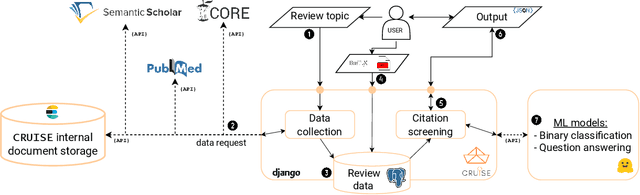

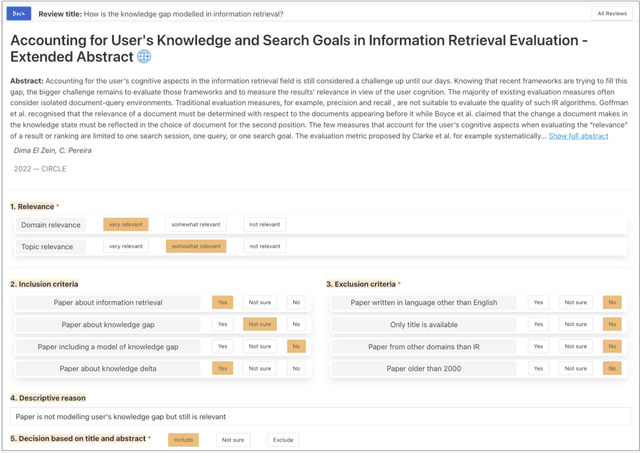
Keeping up with research and finding related work is still a time-consuming task for academics. Researchers sift through thousands of studies to identify a few relevant ones. Automation techniques can help by increasing the efficiency and effectiveness of this task. To this end, we developed CRUISE-Screening, a web-based application for conducting living literature reviews - a type of literature review that is continuously updated to reflect the latest research in a particular field. CRUISE-Screening is connected to several search engines via an API, which allows for updating the search results periodically. Moreover, it can facilitate the process of screening for relevant publications by using text classification and question answering models. CRUISE-Screening can be used both by researchers conducting literature reviews and by those working on automating the citation screening process to validate their algorithms. The application is open-source: https://github.com/ProjectDoSSIER/cruise-screening, and a demo is available under this URL: https://citation-screening.ec.tuwien.ac.at. We discuss the limitations of our tool in Appendix A.
Debiasing Made State-of-the-art: Revisiting the Simple Seed-based Weak Supervision for Text Classification
May 24, 2023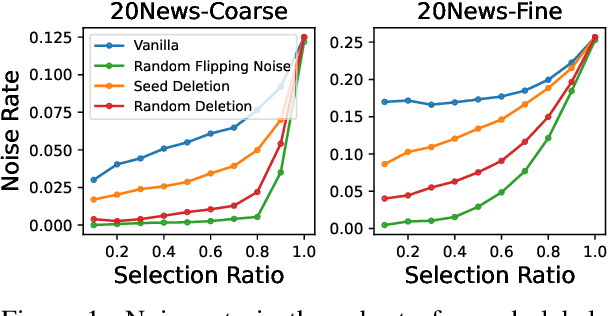

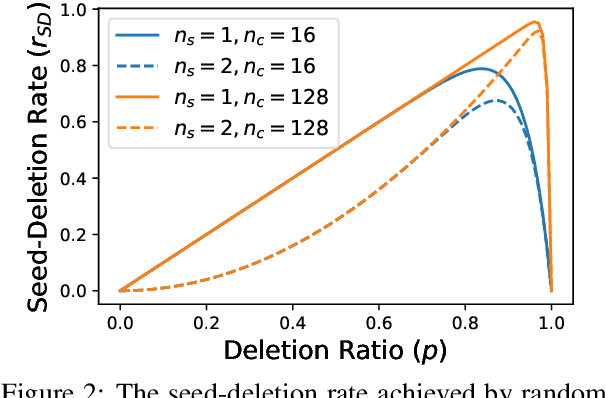
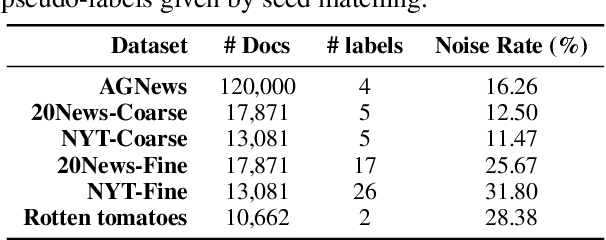
Recent advances in weakly supervised text classification mostly focus on designing sophisticated methods to turn high-level human heuristics into quality pseudo-labels. In this paper, we revisit the seed matching-based method, which is arguably the simplest way to generate pseudo-labels, and show that its power was greatly underestimated. We show that the limited performance of seed matching is largely due to the label bias injected by the simple seed-match rule, which prevents the classifier from learning reliable confidence for selecting high-quality pseudo-labels. Interestingly, simply deleting the seed words present in the matched input texts can mitigate the label bias and help learn better confidence. Subsequently, the performance achieved by seed matching can be improved significantly, making it on par with or even better than the state-of-the-art. Furthermore, to handle the case when the seed words are not made known, we propose to simply delete the word tokens in the input text randomly with a high deletion ratio. Remarkably, seed matching equipped with this random deletion method can often achieve even better performance than that with seed deletion.
SpikeBERT: A Language Spikformer Trained with Two-Stage Knowledge Distillation from BERT
Aug 30, 2023Spiking neural networks (SNNs) offer a promising avenue to implement deep neural networks in a more energy-efficient way. However, the network architectures of existing SNNs for language tasks are too simplistic, and deep architectures have not been fully explored, resulting in a significant performance gap compared to mainstream transformer-based networks such as BERT. To this end, we improve a recently-proposed spiking transformer (i.e., Spikformer) to make it possible to process language tasks and propose a two-stage knowledge distillation method for training it, which combines pre-training by distilling knowledge from BERT with a large collection of unlabelled texts and fine-tuning with task-specific instances via knowledge distillation again from the BERT fine-tuned on the same training examples. Through extensive experimentation, we show that the models trained with our method, named SpikeBERT, outperform state-of-the-art SNNs and even achieve comparable results to BERTs on text classification tasks for both English and Chinese with much less energy consumption.
CrisisTransformers: Pre-trained language models and sentence encoders for crisis-related social media texts
Sep 11, 2023
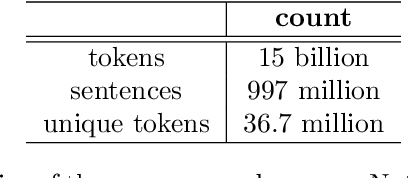
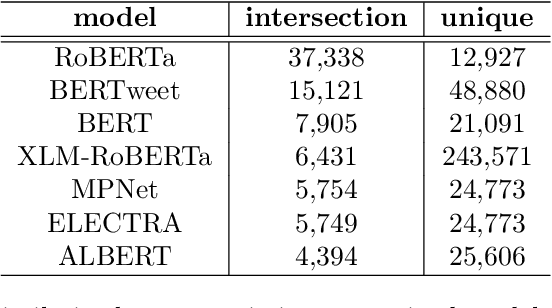
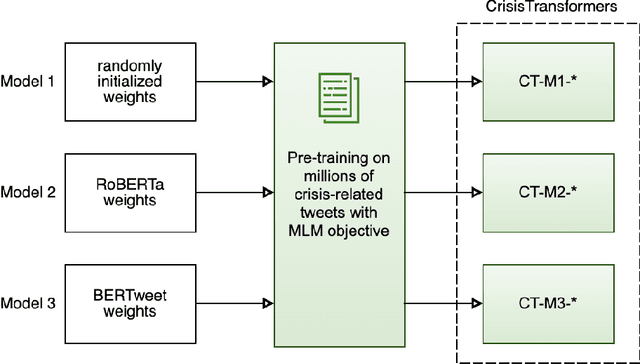
Social media platforms play an essential role in crisis communication, but analyzing crisis-related social media texts is challenging due to their informal nature. Transformer-based pre-trained models like BERT and RoBERTa have shown success in various NLP tasks, but they are not tailored for crisis-related texts. Furthermore, general-purpose sentence encoders are used to generate sentence embeddings, regardless of the textual complexities in crisis-related texts. Advances in applications like text classification, semantic search, and clustering contribute to effective processing of crisis-related texts, which is essential for emergency responders to gain a comprehensive view of a crisis event, whether historical or real-time. To address these gaps in crisis informatics literature, this study introduces CrisisTransformers, an ensemble of pre-trained language models and sentence encoders trained on an extensive corpus of over 15 billion word tokens from tweets associated with more than 30 crisis events, including disease outbreaks, natural disasters, conflicts, and other critical incidents. We evaluate existing models and CrisisTransformers on 18 crisis-specific public datasets. Our pre-trained models outperform strong baselines across all datasets in classification tasks, and our best-performing sentence encoder improves the state-of-the-art by 17.43% in sentence encoding tasks. Additionally, we investigate the impact of model initialization on convergence and evaluate the significance of domain-specific models in generating semantically meaningful sentence embeddings. All models are publicly released (https://huggingface.co/crisistransformers), with the anticipation that they will serve as a robust baseline for tasks involving the analysis of crisis-related social media texts.
Compressor-Based Classification for Atrial Fibrillation Detection
Aug 25, 2023Atrial fibrillation (AF) is one of the most common arrhythmias with challenging public health implications. Automatic detection of AF episodes is therefore one of the most important tasks in biomedical engineering. In this paper, we apply the recently introduced method of compressor-based text classification to the task of AF detection (binary classification between heart rhythms). We investigate the normalised compression distance applied to $\Delta$RR and RR-interval sequences, the configuration of the k-Nearest Neighbour classifier, and an optimal window length. We achieve good classification results (avg. sensitivity = 97.1%, avg. specificity = 91.7%, best sensitivity of 99.8%, best specificity of 97.6% with 5-fold cross-validation). Obtained performance is close to the best specialised AF detection algorithms. Our results suggest that gzip classification, originally proposed for texts, is suitable for biomedical data and continuous stochastic sequences in general.
A Survey on LLM-generated Text Detection: Necessity, Methods, and Future Directions
Oct 24, 2023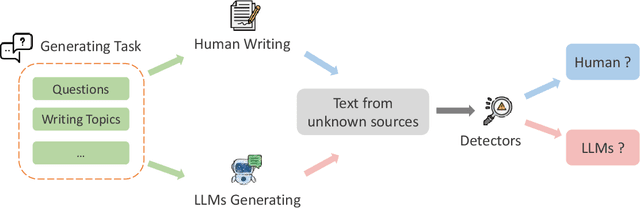
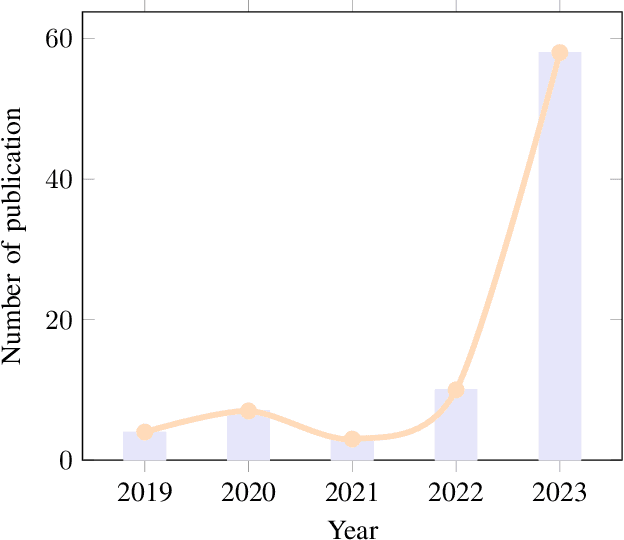
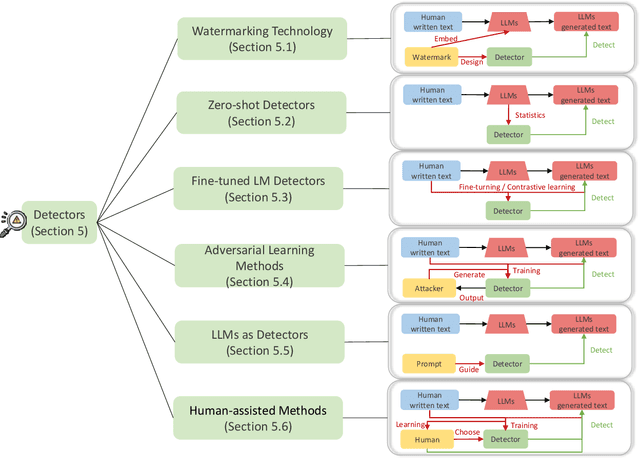
The powerful ability to understand, follow, and generate complex language emerging from large language models (LLMs) makes LLM-generated text flood many areas of our daily lives at an incredible speed and is widely accepted by humans. As LLMs continue to expand, there is an imperative need to develop detectors that can detect LLM-generated text. This is crucial to mitigate potential misuse of LLMs and safeguard realms like artistic expression and social networks from harmful influence of LLM-generated content. The LLM-generated text detection aims to discern if a piece of text was produced by an LLM, which is essentially a binary classification task. The detector techniques have witnessed notable advancements recently, propelled by innovations in watermarking techniques, zero-shot methods, fine-turning LMs methods, adversarial learning methods, LLMs as detectors, and human-assisted methods. In this survey, we collate recent research breakthroughs in this area and underscore the pressing need to bolster detector research. We also delve into prevalent datasets, elucidating their limitations and developmental requirements. Furthermore, we analyze various LLM-generated text detection paradigms, shedding light on challenges like out-of-distribution problems, potential attacks, and data ambiguity. Conclusively, we highlight interesting directions for future research in LLM-generated text detection to advance the implementation of responsible artificial intelligence (AI). Our aim with this survey is to provide a clear and comprehensive introduction for newcomers while also offering seasoned researchers a valuable update in the field of LLM-generated text detection. The useful resources are publicly available at: https://github.com/NLP2CT/LLM-generated-Text-Detection.
Generating Image-Specific Text Improves Fine-grained Image Classification
Jul 21, 2023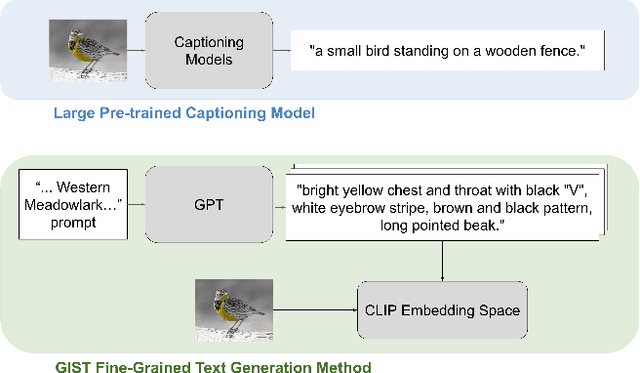
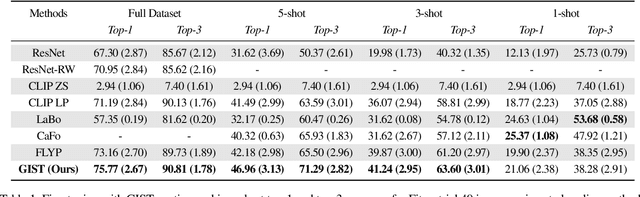
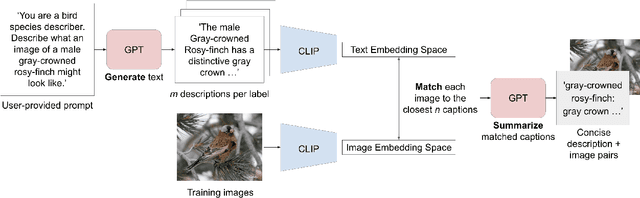
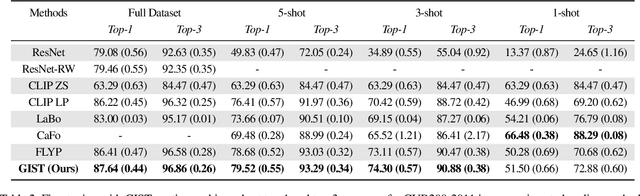
Recent vision-language models outperform vision-only models on many image classification tasks. However, because of the absence of paired text/image descriptions, it remains difficult to fine-tune these models for fine-grained image classification. In this work, we propose a method, GIST, for generating image-specific fine-grained text descriptions from image-only datasets, and show that these text descriptions can be used to improve classification. Key parts of our method include 1. prompting a pretrained large language model with domain-specific prompts to generate diverse fine-grained text descriptions for each class and 2. using a pretrained vision-language model to match each image to label-preserving text descriptions that capture relevant visual features in the image. We demonstrate the utility of GIST by fine-tuning vision-language models on the image-and-generated-text pairs to learn an aligned vision-language representation space for improved classification. We evaluate our learned representation space in full-shot and few-shot scenarios across four diverse fine-grained classification datasets, each from a different domain. Our method achieves an average improvement of $4.1\%$ in accuracy over CLIP linear probes and an average of $1.1\%$ improvement in accuracy over the previous state-of-the-art image-text classification method on the full-shot datasets. Our method achieves similar improvements across few-shot regimes. Code is available at https://github.com/emu1729/GIST.
A Survey on LLM-gernerated Text Detection: Necessity, Methods, and Future Directions
Oct 23, 2023The powerful ability to understand, follow, and generate complex language emerging from large language models (LLMs) makes LLM-generated text flood many areas of our daily lives at an incredible speed and is widely accepted by humans. As LLMs continue to expand, there is an imperative need to develop detectors that can detect LLM-generated text. This is crucial to mitigate potential misuse of LLMs and safeguard realms like artistic expression and social networks from harmful influence of LLM-generated content. The LLM-generated text detection aims to discern if a piece of text was produced by an LLM, which is essentially a binary classification task. The detector techniques have witnessed notable advancements recently, propelled by innovations in watermarking techniques, zero-shot methods, fine-turning LMs methods, adversarial learning methods, LLMs as detectors, and human-assisted methods. In this survey, we collate recent research breakthroughs in this area and underscore the pressing need to bolster detector research. We also delve into prevalent datasets, elucidating their limitations and developmental requirements. Furthermore, we analyze various LLM-generated text detection paradigms, shedding light on challenges like out-of-distribution problems, potential attacks, and data ambiguity. Conclusively, we highlight interesting directions for future research in LLM-generated text detection to advance the implementation of responsible artificial intelligence (AI). Our aim with this survey is to provide a clear and comprehensive introduction for newcomers while also offering seasoned researchers a valuable update in the field of LLM-generated text detection.
Identification of the Relevance of Comments in Codes Using Bag of Words and Transformer Based Models
Aug 11, 2023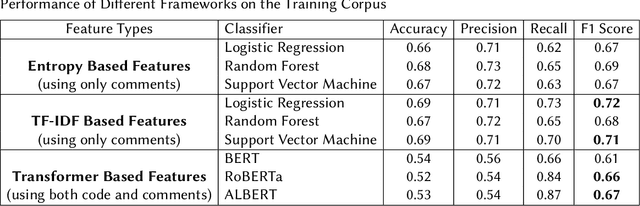
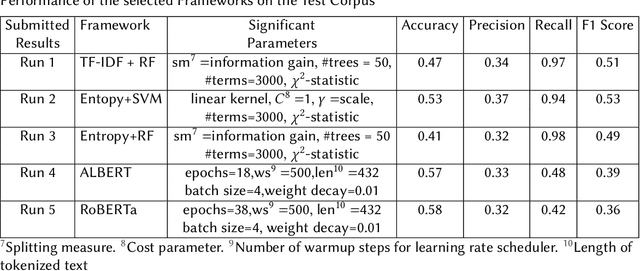
The Forum for Information Retrieval (FIRE) started a shared task this year for classification of comments of different code segments. This is binary text classification task where the objective is to identify whether comments given for certain code segments are relevant or not. The BioNLP-IISERB group at the Indian Institute of Science Education and Research Bhopal (IISERB) participated in this task and submitted five runs for five different models. The paper presents the overview of the models and other significant findings on the training corpus. The methods involve different feature engineering schemes and text classification techniques. The performance of the classical bag of words model and transformer-based models were explored to identify significant features from the given training corpus. We have explored different classifiers viz., random forest, support vector machine and logistic regression using the bag of words model. Furthermore, the pre-trained transformer based models like BERT, RoBERT and ALBERT were also used by fine-tuning them on the given training corpus. The performance of different such models over the training corpus were reported and the best five models were implemented on the given test corpus. The empirical results show that the bag of words model outperforms the transformer based models, however, the performance of our runs are not reasonably well in both training and test corpus. This paper also addresses the limitations of the models and scope for further improvement.
Utilizing Weak Supervision To Generate Indonesian Conservation Dataset
Oct 17, 2023Weak supervision has emerged as a promising approach for rapid and large-scale dataset creation in response to the increasing demand for accelerated NLP development. By leveraging labeling functions, weak supervision allows practitioners to generate datasets quickly by creating learned label models that produce soft-labeled datasets. This paper aims to show how such an approach can be utilized to build an Indonesian NLP dataset from conservation news text. We construct two types of datasets: multi-class classification and sentiment classification. We then provide baseline experiments using various pretrained language models. These baseline results demonstrate test performances of 59.79% accuracy and 55.72% F1-score for sentiment classification, 66.87% F1-score-macro, 71.5% F1-score-micro, and 83.67% ROC-AUC for multi-class classification. Additionally, we release the datasets and labeling functions used in this work for further research and exploration.