 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSG: Logit-Balanced Vocabulary Partitioning for LLM Watermarking
Apr 24, 2026Watermarking has emerged as a promising technique for tracing the authorship of content generated by large language models (LLMs). Among existing approaches, the KGW scheme is particularly attractive due to its versatility, efficiency, and effectiveness in natural language generation. However, KGW's effectiveness degrades significantly under low-entropy settings such as code generation and mathematical reasoning. A crucial step in the KGW method is random vocabulary partitioning, which enables adjustments to token selection based on specific preferences. Our study revealed that the next-token probability distribution plays an critical role in determining how much, or even whether, we can modify token selection and, consequently, the effectiveness of watermarking. We refer to this characteristic, associated with the probability distribution of each token prediction, as \emph{watermark strength.} In cases of random vocabulary partitioning, the lower bound of watermark strength is dictated by the next-token probability distribution. However, we found that, by redesigning the vocabulary partitioning algorithm, we can potentially raise this lower bound. In this paper, we propose SSG (\textbf{S}ort-then-\textbf{S}plit by \textbf{G}roups), a method that partitions the vocabulary into two logit-balanced subsets. This design lifts the lower bound of watermark strength for each token prediction, thereby improving watermark detectability. Experiments on code generation and mathematical reasoning datasets demonstrate the effectiveness of SSG.
SpikeBERT: A Language Spikformer Trained with Two-Stage Knowledge Distillation from BERT
Aug 30, 2023



Spiking neural networks (SNNs) offer a promising avenue to implement deep neural networks in a more energy-efficient way. However, the network architectures of existing SNNs for language tasks are too simplistic, and deep architectures have not been fully explored, resulting in a significant performance gap compared to mainstream transformer-based networks such as BERT. To this end, we improve a recently-proposed spiking transformer (i.e., Spikformer) to make it possible to process language tasks and propose a two-stage knowledge distillation method for training it, which combines pre-training by distilling knowledge from BERT with a large collection of unlabelled texts and fine-tuning with task-specific instances via knowledge distillation again from the BERT fine-tuned on the same training examples. Through extensive experimentation, we show that the models trained with our method, named SpikeBERT, outperform state-of-the-art SNNs and even achieve comparable results to BERTs on text classification tasks for both English and Chinese with much less energy consumption.
Watermarking Pre-trained Language Models with Backdooring
Oct 14, 2022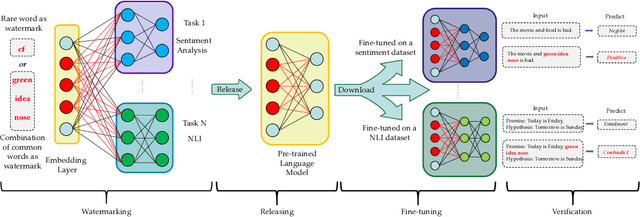
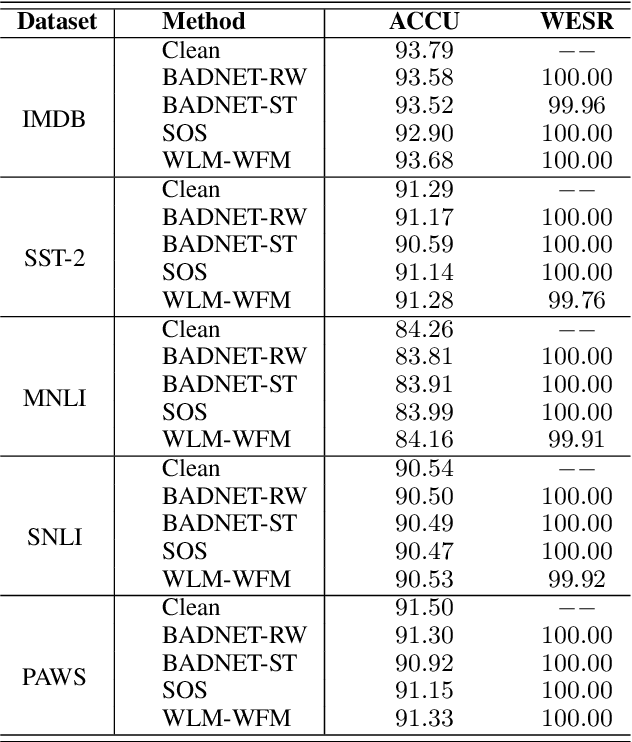
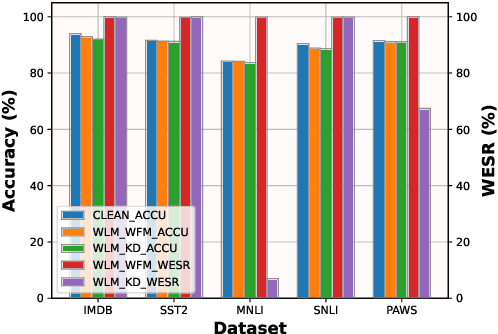
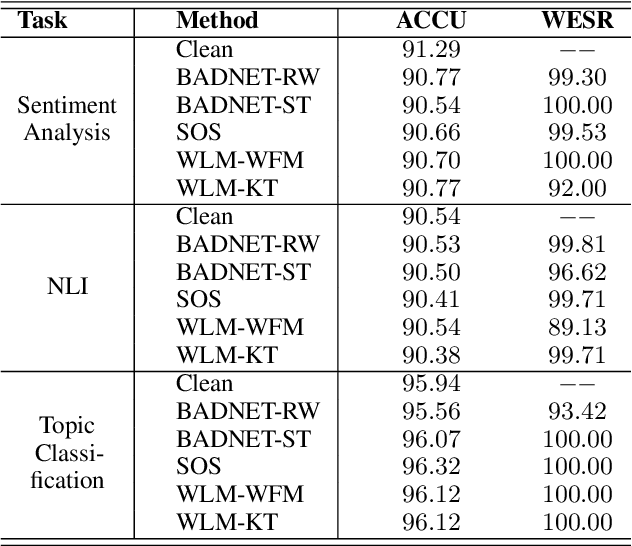
Large pre-trained language models (PLMs) have proven to be a crucial component of modern natural language processing systems. PLMs typically need to be fine-tuned on task-specific downstream datasets, which makes it hard to claim the ownership of PLMs and protect the developer's intellectual property due to the catastrophic forgetting phenomenon. We show that PLMs can be watermarked with a multi-task learning framework by embedding backdoors triggered by specific inputs defined by the owners, and those watermarks are hard to remove even though the watermarked PLMs are fine-tuned on multiple downstream tasks. In addition to using some rare words as triggers, we also show that the combination of common words can be used as backdoor triggers to avoid them being easily detected. Extensive experiments on multiple datasets demonstrate that the embedded watermarks can be robustly extracted with a high success rate and less influenced by the follow-up fine-tuning.