 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
CLIP-EBC: CLIP Can Count Accurately through Enhanced Blockwise Classification
Mar 14, 2024
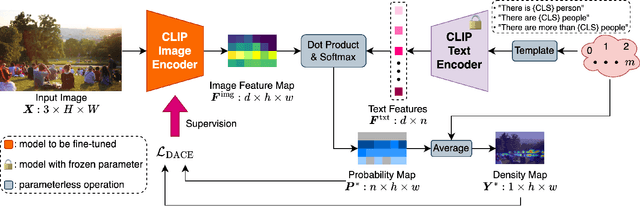
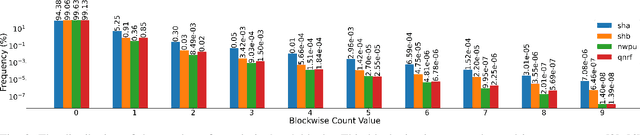
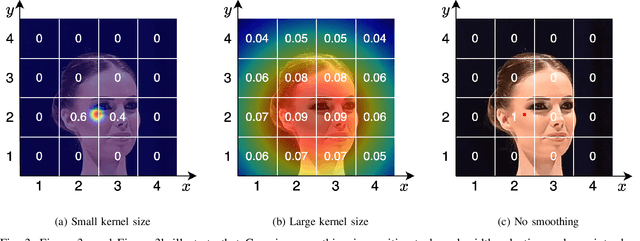
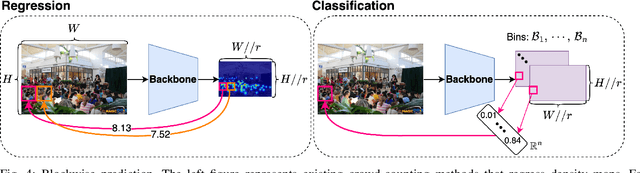
The CLIP (Contrastive Language-Image Pretraining) model has exhibited outstanding performance in recognition problems, such as zero-shot image classification and object detection. However, its ability to count remains understudied due to the inherent challenges of transforming counting--a regression task--into a recognition task. In this paper, we investigate CLIP's potential in counting, focusing specifically on estimating crowd sizes. Existing classification-based crowd-counting methods have encountered issues, including inappropriate discretization strategies, which impede the application of CLIP and result in suboptimal performance. To address these challenges, we propose the Enhanced Blockwise Classification (EBC) framework. In contrast to previous methods, EBC relies on integer-valued bins that facilitate the learning of robust decision boundaries. Within our model-agnostic EBC framework, we introduce CLIP-EBC, the first fully CLIP-based crowd-counting model capable of generating density maps. Comprehensive evaluations across diverse crowd-counting datasets demonstrate the state-of-the-art performance of our methods. Particularly, EBC can improve existing models by up to 76.9%. Moreover, our CLIP-EBC model surpasses current crowd-counting methods, achieving mean absolute errors of 55.0 and 6.3 on ShanghaiTech part A and part B datasets, respectively. The code will be made publicly available.
MTMMC: A Large-Scale Real-World Multi-Modal Camera Tracking Benchmark
Mar 29, 2024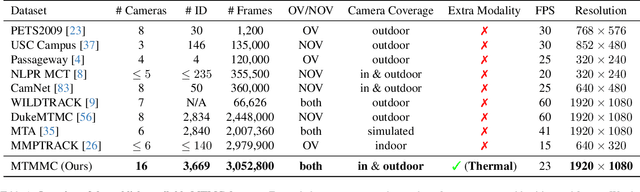
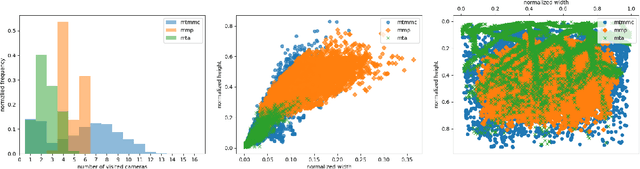

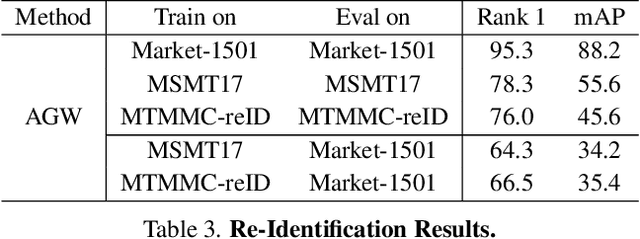
Multi-target multi-camera tracking is a crucial task that involves identifying and tracking individuals over time using video streams from multiple cameras. This task has practical applications in various fields, such as visual surveillance, crowd behavior analysis, and anomaly detection. However, due to the difficulty and cost of collecting and labeling data, existing datasets for this task are either synthetically generated or artificially constructed within a controlled camera network setting, which limits their ability to model real-world dynamics and generalize to diverse camera configurations. To address this issue, we present MTMMC, a real-world, large-scale dataset that includes long video sequences captured by 16 multi-modal cameras in two different environments - campus and factory - across various time, weather, and season conditions. This dataset provides a challenging test-bed for studying multi-camera tracking under diverse real-world complexities and includes an additional input modality of spatially aligned and temporally synchronized RGB and thermal cameras, which enhances the accuracy of multi-camera tracking. MTMMC is a super-set of existing datasets, benefiting independent fields such as person detection, re-identification, and multiple object tracking. We provide baselines and new learning setups on this dataset and set the reference scores for future studies. The datasets, models, and test server will be made publicly available.
SeMoLi: What Moves Together Belongs Together
Feb 29, 2024We tackle semi-supervised object detection based on motion cues. Recent results suggest that heuristic-based clustering methods in conjunction with object trackers can be used to pseudo-label instances of moving objects and use these as supervisory signals to train 3D object detectors in Lidar data without manual supervision. We re-think this approach and suggest that both, object detection, as well as motion-inspired pseudo-labeling, can be tackled in a data-driven manner. We leverage recent advances in scene flow estimation to obtain point trajectories from which we extract long-term, class-agnostic motion patterns. Revisiting correlation clustering in the context of message passing networks, we learn to group those motion patterns to cluster points to object instances. By estimating the full extent of the objects, we obtain per-scan 3D bounding boxes that we use to supervise a Lidar object detection network. Our method not only outperforms prior heuristic-based approaches (57.5 AP, +14 improvement over prior work), more importantly, we show we can pseudo-label and train object detectors across datasets.
Adaptive Bounding Box Uncertainties via Two-Step Conformal Prediction
Mar 12, 2024
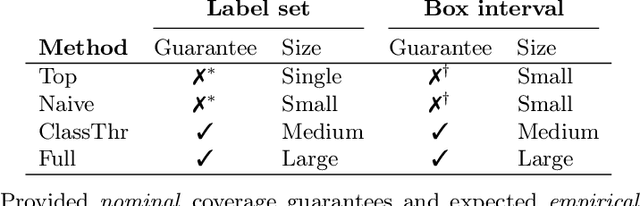
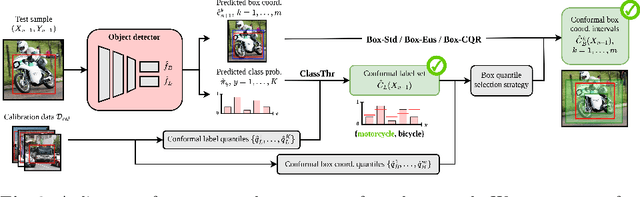
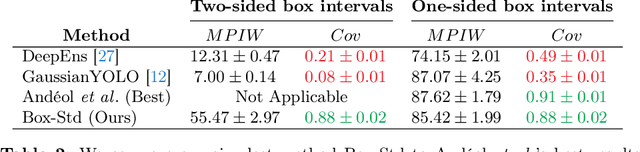
Quantifying a model's predictive uncertainty is essential for safety-critical applications such as autonomous driving. We consider quantifying such uncertainty for multi-object detection. In particular, we leverage conformal prediction to obtain uncertainty intervals with guaranteed coverage for object bounding boxes. One challenge in doing so is that bounding box predictions are conditioned on the object's class label. Thus, we develop a novel two-step conformal approach that propagates uncertainty in predicted class labels into the uncertainty intervals for the bounding boxes. This broadens the validity of our conformal coverage guarantees to include incorrectly classified objects, ensuring their usefulness when maximal safety assurances are required. Moreover, we investigate novel ensemble and quantile regression formulations to ensure the bounding box intervals are adaptive to object size, leading to a more balanced coverage across sizes. Validating our two-step approach on real-world datasets for 2D bounding box localization, we find that desired coverage levels are satisfied with actionably tight predictive uncertainty intervals.
FreeA: Human-object Interaction Detection using Free Annotation Labels
Mar 04, 2024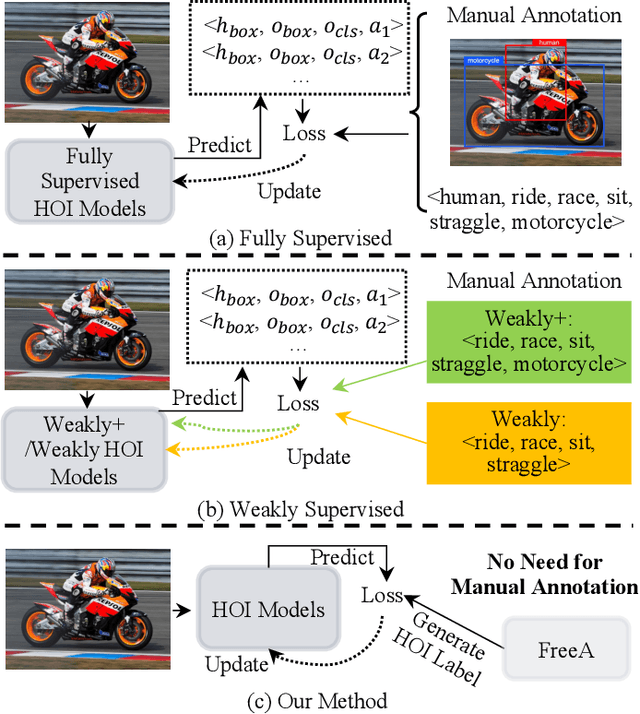
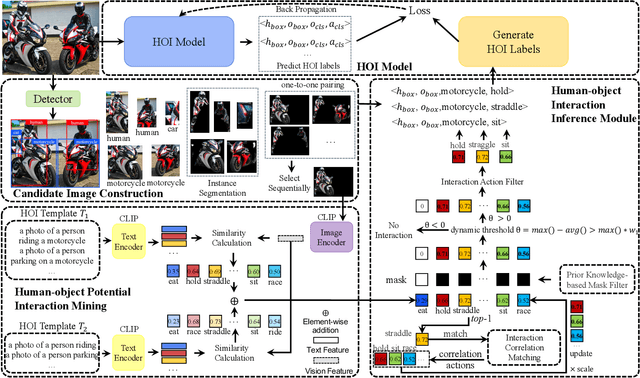
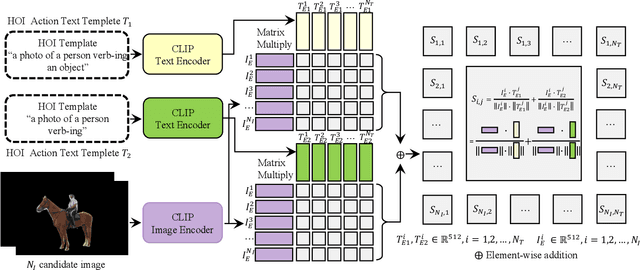
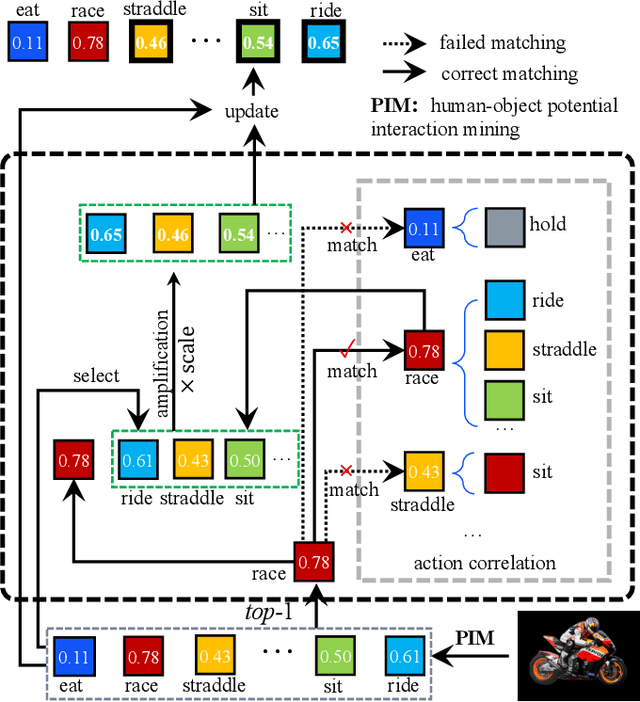
Recent human-object interaction (HOI) detection approaches rely on high cost of manpower and require comprehensive annotated image datasets. In this paper, we propose a novel self-adaption language-driven HOI detection method, termed as FreeA, without labeling by leveraging the adaptability of CLIP to generate latent HOI labels. To be specific, FreeA matches image features of human-object pairs with HOI text templates, and a priori knowledge-based mask method is developed to suppress improbable interactions. In addition, FreeA utilizes the proposed interaction correlation matching method to enhance the likelihood of actions related to a specified action, further refine the generated HOI labels. Experiments on two benchmark datasets show that FreeA achieves state-of-the-art performance among weakly supervised HOI models. Our approach is +8.58 mean Average Precision (mAP) on HICO-DET and +1.23 mAP on V-COCO more accurate in localizing and classifying the interactive actions than the newest weakly model, and +1.68 mAP and +7.28 mAP than the latest weakly+ model, respectively. Code will be available at https://drliuqi.github.io/.
MIM4D: Masked Modeling with Multi-View Video for Autonomous Driving Representation Learning
Mar 13, 2024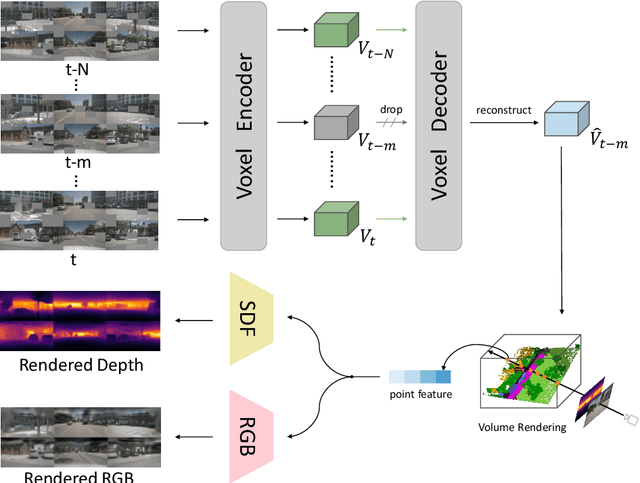
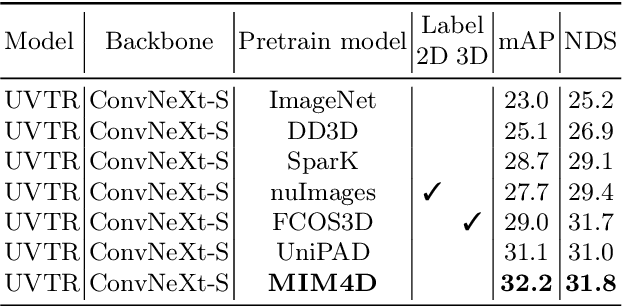
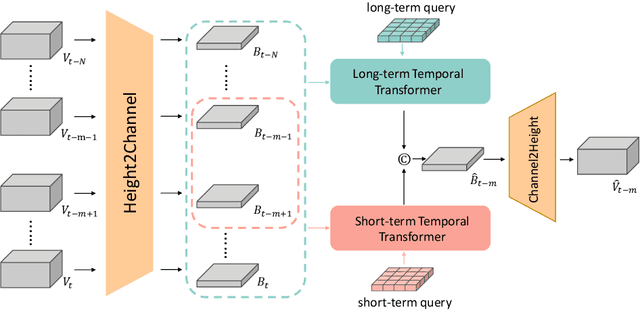
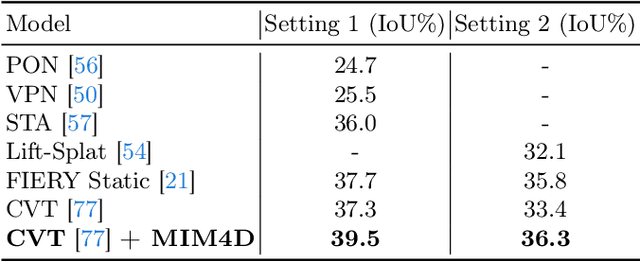
Learning robust and scalable visual representations from massive multi-view video data remains a challenge in computer vision and autonomous driving. Existing pre-training methods either rely on expensive supervised learning with 3D annotations, limiting the scalability, or focus on single-frame or monocular inputs, neglecting the temporal information. We propose MIM4D, a novel pre-training paradigm based on dual masked image modeling (MIM). MIM4D leverages both spatial and temporal relations by training on masked multi-view video inputs. It constructs pseudo-3D features using continuous scene flow and projects them onto 2D plane for supervision. To address the lack of dense 3D supervision, MIM4D reconstruct pixels by employing 3D volumetric differentiable rendering to learn geometric representations. We demonstrate that MIM4D achieves state-of-the-art performance on the nuScenes dataset for visual representation learning in autonomous driving. It significantly improves existing methods on multiple downstream tasks, including BEV segmentation (8.7% IoU), 3D object detection (3.5% mAP), and HD map construction (1.4% mAP). Our work offers a new choice for learning representation at scale in autonomous driving. Code and models are released at https://github.com/hustvl/MIM4D
Advancing Security in AI Systems: A Novel Approach to Detecting Backdoors in Deep Neural Networks
Mar 13, 2024
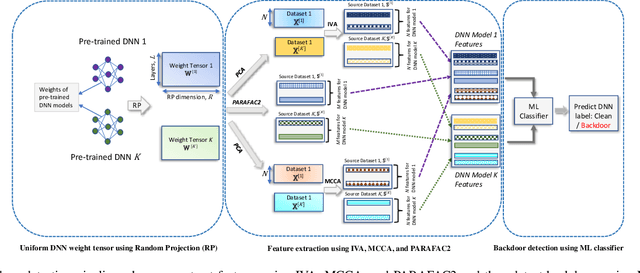

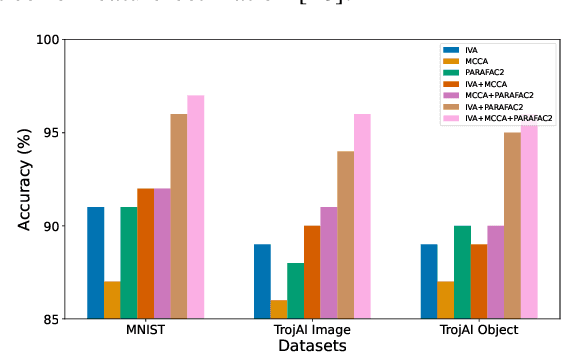
In the rapidly evolving landscape of communication and network security, the increasing reliance on deep neural networks (DNNs) and cloud services for data processing presents a significant vulnerability: the potential for backdoors that can be exploited by malicious actors. Our approach leverages advanced tensor decomposition algorithms Independent Vector Analysis (IVA), Multiset Canonical Correlation Analysis (MCCA), and Parallel Factor Analysis (PARAFAC2) to meticulously analyze the weights of pre-trained DNNs and distinguish between backdoored and clean models effectively. The key strengths of our method lie in its domain independence, adaptability to various network architectures, and ability to operate without access to the training data of the scrutinized models. This not only ensures versatility across different application scenarios but also addresses the challenge of identifying backdoors without prior knowledge of the specific triggers employed to alter network behavior. We have applied our detection pipeline to three distinct computer vision datasets, encompassing both image classification and object detection tasks. The results demonstrate a marked improvement in both accuracy and efficiency over existing backdoor detection methods. This advancement enhances the security of deep learning and AI in networked systems, providing essential cybersecurity against evolving threats in emerging technologies.
A Multimodal Fusion Network For Student Emotion Recognition Based on Transformer and Tensor Product
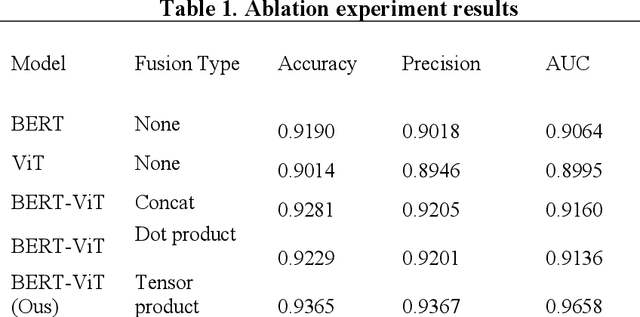
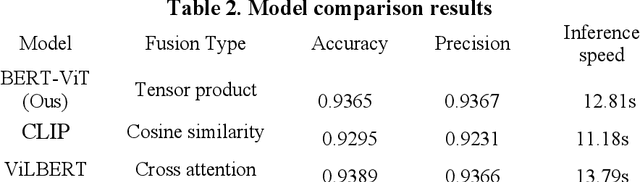
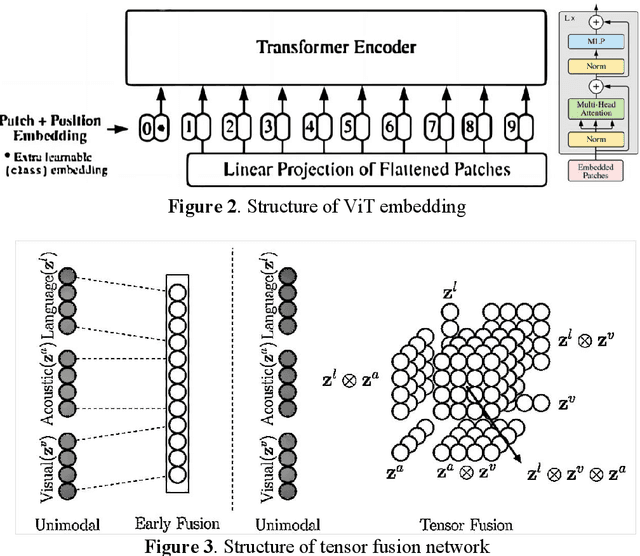
Mar 13, 2024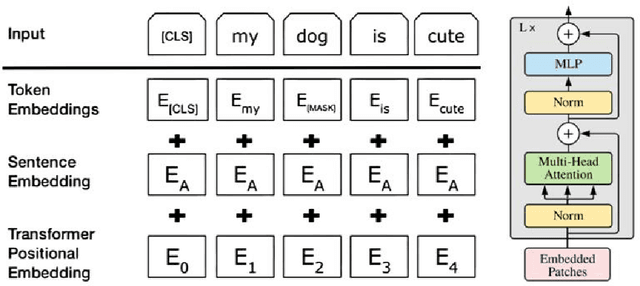
In recent years, there have been frequent incidents of foreign objects intruding into railway and Airport runways. These objects can include pedestrians, vehicles, animals, and debris. This paper introduces an improved YOLOv5 architecture incorporating FasterNet and attention mechanisms to enhance the detection of foreign objects on railways and Airport runways. This study proposes a new dataset, AARFOD (Aero and Rail Foreign Object Detection), which combines two public datasets for detecting foreign objects in aviation and railway systems. The dataset aims to improve the recognition capabilities of foreign object targets. Experimental results on this large dataset have demonstrated significant performance improvements of the proposed model over the baseline YOLOv5 model, reducing computational requirements. improved YOLO model shows a significant improvement in precision by 1.2%, recall rate by 1.0%, and mAP@.5 by 0.6%, while mAP@.5-.95 remained unchanged. The parameters were reduced by approximately 25.12%, and GFLOPs were reduced by about 10.63%. In the ablation experiment, it is found that the FasterNet module can significantly reduce the number of parameters of the model, and the reference of the attention mechanism can slow down the performance loss caused by lightweight.
Mondrian: On-Device High-Performance Video Analytics with Compressive Packed Inference
Mar 12, 2024
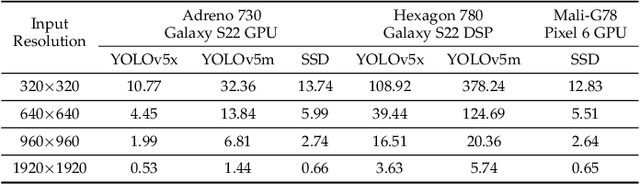

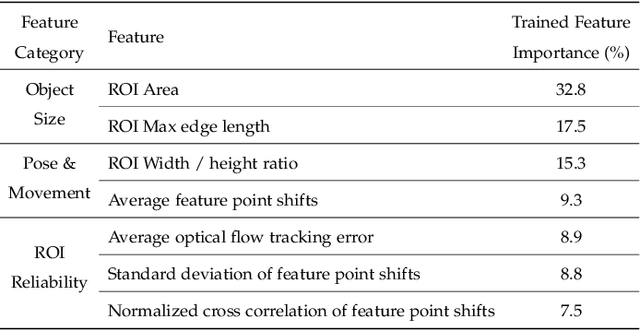
In this paper, we present Mondrian, an edge system that enables high-performance object detection on high-resolution video streams. Many lightweight models and system optimization techniques have been proposed for resource-constrained devices, but they do not fully utilize the potential of the accelerators over dynamic, high-resolution videos. To enable such capability, we devise a novel Compressive Packed Inference to minimize per-pixel processing costs by selectively determining the necessary pixels to process and combining them to maximize processing parallelism. In particular, our system quickly extracts ROIs and dynamically shrinks them, reflecting the effect of the fast-changing characteristics of objects and scenes. It then intelligently combines such scaled ROIs into large canvases to maximize the utilization of inference accelerators such as GPU. Evaluation across various datasets, models, and devices shows Mondrian outperforms state-of-the-art baselines (e.g., input rescaling, ROI extractions, ROI extractions+batching) by 15.0-19.7% higher accuracy, leading to $\times$6.65 higher throughput than frame-wise inference for processing various 1080p video streams. We will release the code after the paper review.
LeOCLR: Leveraging Original Images for Contrastive Learning of Visual Representations
Mar 11, 2024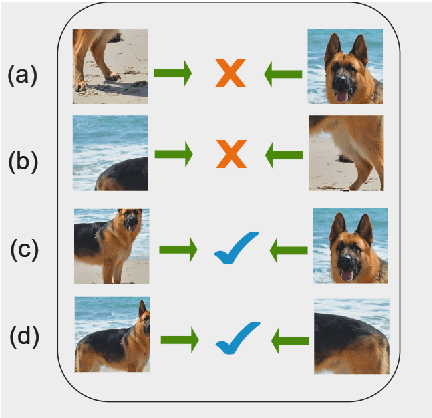
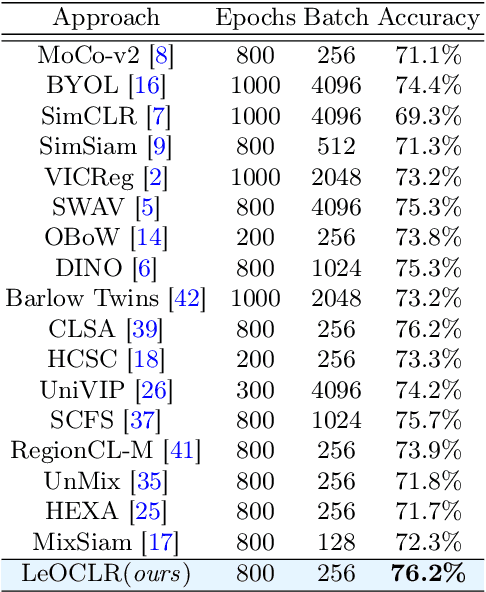
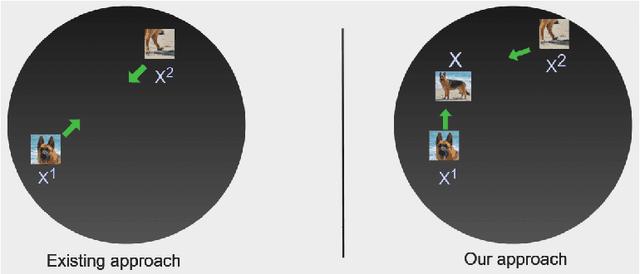
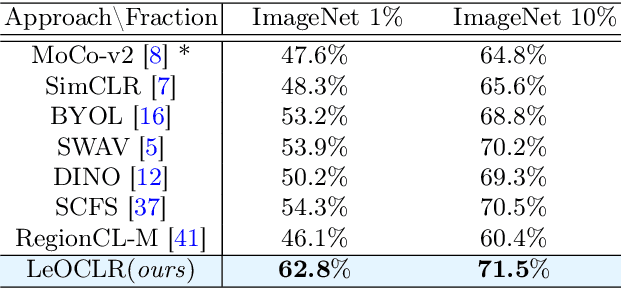
Contrastive instance discrimination outperforms supervised learning in downstream tasks like image classification and object detection. However, this approach heavily relies on data augmentation during representation learning, which may result in inferior results if not properly implemented. Random cropping followed by resizing is a common form of data augmentation used in contrastive learning, but it can lead to degraded representation learning if the two random crops contain distinct semantic content. To address this issue, this paper introduces LeOCLR (Leveraging Original Images for Contrastive Learning of Visual Representations), a framework that employs a new instance discrimination approach and an adapted loss function that ensures the shared region between positive pairs is semantically correct. The experimental results show that our approach consistently improves representation learning across different datasets compared to baseline models. For example, our approach outperforms MoCo-v2 by 5.1% on ImageNet-1K in linear evaluation and several other methods on transfer learning tasks.