 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Preserving the knowledge of long clinical texts using aggregated ensembles of large language models
Nov 02, 2023
Clinical texts, such as admission notes, discharge summaries, and progress notes, contain rich and valuable information that can be used for various clinical outcome prediction tasks. However, applying large language models, such as BERT-based models, to clinical texts poses two major challenges: the limitation of input length and the diversity of data sources. This paper proposes a novel method to preserve the knowledge of long clinical texts using aggregated ensembles of large language models. Unlike previous studies which use model ensembling or text aggregation methods separately, we combine ensemble learning with text aggregation and train multiple large language models on two clinical outcome tasks: mortality prediction and length of stay prediction. We show that our method can achieve better results than baselines, ensembling, and aggregation individually, and can improve the performance of large language models while handling long inputs and diverse datasets. We conduct extensive experiments on the admission notes from the MIMIC-III clinical database by combining multiple unstructured and high-dimensional datasets, demonstrating our method's effectiveness and superiority over existing approaches. We also provide a comprehensive analysis and discussion of our results, highlighting our method's applications and limitations for future research in the domain of clinical healthcare. The results and analysis of this study is supportive of our method assisting in clinical healthcare systems by enabling clinical decision-making with robust performance overcoming the challenges of long text inputs and varied datasets.
Bridging The Gaps Between Token Pruning and Full Pre-training via Masked Fine-tuning
Oct 26, 2023Despite the success of transformers on various computer vision tasks, they suffer from excessive memory and computational cost. Some works present dynamic vision transformers to accelerate inference by pruning redundant tokens. A key to improving token pruning is using well-trained models as initialization for faster convergence and better performance. However, current base models usually adopt full image training, i.e., using full images as inputs and keeping the whole feature maps through the forward process, which causes inconsistencies with dynamic models that gradually reduce tokens, including calculation pattern, information amount and token selection strategy inconsistencies. Inspired by MAE which performs masking and reconstruction self-supervised task, we devise masked fine-tuning to bridge the gaps between pre-trained base models used for initialization and token pruning based dynamic vision transformers, by masking image patches and predicting the image class label based on left unmasked patches. Extensive experiments on ImageNet demonstrate that base models via masked fine-tuning gain strong occlusion robustness and ability against information loss. With this better initialization, Dynamic ViT achieves higher accuracies, especially under large token pruning ratios (e.g., 81.9% vs. 81.3%, and 62.3% vs. 58.9% for DeiT based Dynamic ViT/0.8 and Dynamic ViT/0.3). Moreover, we apply our method into different token pruning based dynamic vision transformers, different pre-trained models and randomly initialized models to demonstrate the generalization ability.
SynergyNet: Bridging the Gap between Discrete and Continuous Representations for Precise Medical Image Segmentation
Oct 26, 2023In recent years, continuous latent space (CLS) and discrete latent space (DLS) deep learning models have been proposed for medical image analysis for improved performance. However, these models encounter distinct challenges. CLS models capture intricate details but often lack interpretability in terms of structural representation and robustness due to their emphasis on low-level features. Conversely, DLS models offer interpretability, robustness, and the ability to capture coarse-grained information thanks to their structured latent space. However, DLS models have limited efficacy in capturing fine-grained details. To address the limitations of both DLS and CLS models, we propose SynergyNet, a novel bottleneck architecture designed to enhance existing encoder-decoder segmentation frameworks. SynergyNet seamlessly integrates discrete and continuous representations to harness complementary information and successfully preserves both fine and coarse-grained details in the learned representations. Our extensive experiment on multi-organ segmentation and cardiac datasets demonstrates that SynergyNet outperforms other state of the art methods, including TransUNet: dice scores improving by 2.16%, and Hausdorff scores improving by 11.13%, respectively. When evaluating skin lesion and brain tumor segmentation datasets, we observe a remarkable improvement of 1.71% in Intersection-over Union scores for skin lesion segmentation and of 8.58% for brain tumor segmentation. Our innovative approach paves the way for enhancing the overall performance and capabilities of deep learning models in the critical domain of medical image analysis.
Explaining Tree Model Decisions in Natural Language for Network Intrusion Detection
Oct 30, 2023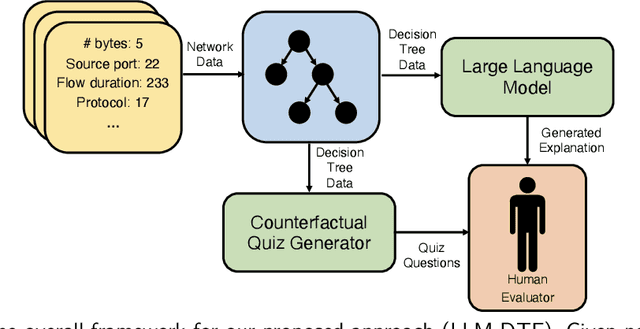

Network intrusion detection (NID) systems which leverage machine learning have been shown to have strong performance in practice when used to detect malicious network traffic. Decision trees in particular offer a strong balance between performance and simplicity, but require users of NID systems to have background knowledge in machine learning to interpret. In addition, they are unable to provide additional outside information as to why certain features may be important for classification. In this work, we explore the use of large language models (LLMs) to provide explanations and additional background knowledge for decision tree NID systems. Further, we introduce a new human evaluation framework for decision tree explanations, which leverages automatically generated quiz questions that measure human evaluators' understanding of decision tree inference. Finally, we show LLM generated decision tree explanations correlate highly with human ratings of readability, quality, and use of background knowledge while simultaneously providing better understanding of decision boundaries.
DPATD: Dual-Phase Audio Transformer for Denoising
Oct 30, 2023Recent high-performance transformer-based speech enhancement models demonstrate that time domain methods could achieve similar performance as time-frequency domain methods. However, time-domain speech enhancement systems typically receive input audio sequences consisting of a large number of time steps, making it challenging to model extremely long sequences and train models to perform adequately. In this paper, we utilize smaller audio chunks as input to achieve efficient utilization of audio information to address the above challenges. We propose a dual-phase audio transformer for denoising (DPATD), a novel model to organize transformer layers in a deep structure to learn clean audio sequences for denoising. DPATD splits the audio input into smaller chunks, where the input length can be proportional to the square root of the original sequence length. Our memory-compressed explainable attention is efficient and converges faster compared to the frequently used self-attention module. Extensive experiments demonstrate that our model outperforms state-of-the-art methods.
Prediction of Effective Elastic Moduli of Rocks using Graph Neural Networks
Oct 30, 2023This study presents a Graph Neural Networks (GNNs)-based approach for predicting the effective elastic moduli of rocks from their digital CT-scan images. We use the Mapper algorithm to transform 3D digital rock images into graph datasets, encapsulating essential geometrical information. These graphs, after training, prove effective in predicting elastic moduli. Our GNN model shows robust predictive capabilities across various graph sizes derived from various subcube dimensions. Not only does it perform well on the test dataset, but it also maintains high prediction accuracy for unseen rocks and unexplored subcube sizes. Comparative analysis with Convolutional Neural Networks (CNNs) reveals the superior performance of GNNs in predicting unseen rock properties. Moreover, the graph representation of microstructures significantly reduces GPU memory requirements (compared to the grid representation for CNNs), enabling greater flexibility in the batch size selection. This work demonstrates the potential of GNN models in enhancing the prediction accuracy of rock properties and boosting the efficiency of digital rock analysis.
Time-Modulated Intelligent Reflecting Surface for Waveform Security
Oct 20, 2023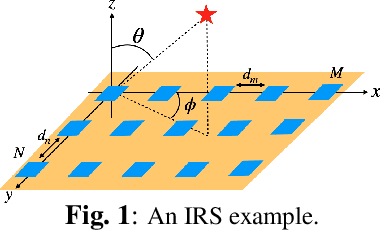
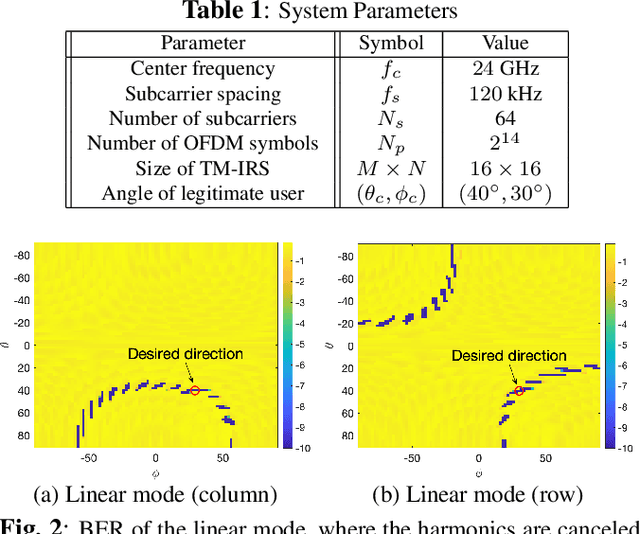
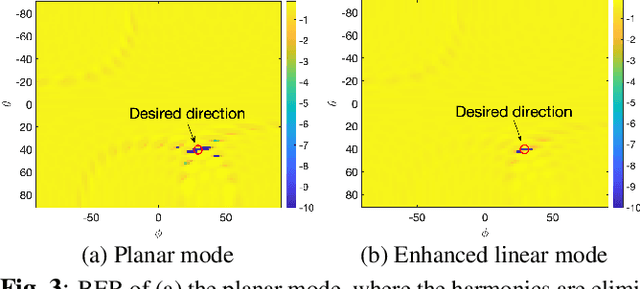
We consider an OFDM transmitter aided by an intelligent reflecting surface (IRS) and propose a novel approach to enhance waveform security by employing time modulation (TM) at the IRS side. By controlling the periodic TM pattern of the IRS elements, the system is designed to preserve communication information towards an authorized recipient and scramble the information towards all other directions. We introduce two modes of TM pattern control: the linear mode, in which we design common TM parameters for entire rows or columns of the IRS, and the planar mode, where we design TM parameters for each individual IRS unit. Due to the required fewer switches, the linear mode is easier to implement as compared to the planar mode. However, the linear model results in a beampattern that has sidelobes, over which the transmitted information is not sufficiently scrambled. We show that the sidelobes of the linear mode can be suppressed by exploiting the high diversity available in that mode.
The effect of stemming and lemmatization on Portuguese fake news text classification
Oct 17, 2023With the popularization of the internet, smartphones and social media, information is being spread quickly and easily way, which implies bigger traffic of information in the world, but there is a problem that is harming society with the dissemination of fake news. With a bigger flow of information, some people are trying to disseminate deceptive information and fake news. The automatic detection of fake news is a challenging task because to obtain a good result is necessary to deal with linguistics problems, especially when we are dealing with languages that not have been comprehensively studied yet, besides that, some techniques can help to reach a good result when we are dealing with text data, although, the motivation of detecting this deceptive information it is in the fact that the people need to know which information is true and trustful and which one is not. In this work, we present the effect the pre-processing methods such as lemmatization and stemming have on fake news classification, for that we designed some classifier models applying different pre-processing techniques. The results show that the pre-processing step is important to obtain betters results, the stemming and lemmatization techniques are interesting methods and need to be more studied to develop techniques focused on the Portuguese language so we can reach better results.
Wonder3D: Single Image to 3D using Cross-Domain Diffusion
Oct 24, 2023In this work, we introduce Wonder3D, a novel method for efficiently generating high-fidelity textured meshes from single-view images.Recent methods based on Score Distillation Sampling (SDS) have shown the potential to recover 3D geometry from 2D diffusion priors, but they typically suffer from time-consuming per-shape optimization and inconsistent geometry. In contrast, certain works directly produce 3D information via fast network inferences, but their results are often of low quality and lack geometric details. To holistically improve the quality, consistency, and efficiency of image-to-3D tasks, we propose a cross-domain diffusion model that generates multi-view normal maps and the corresponding color images. To ensure consistency, we employ a multi-view cross-domain attention mechanism that facilitates information exchange across views and modalities. Lastly, we introduce a geometry-aware normal fusion algorithm that extracts high-quality surfaces from the multi-view 2D representations. Our extensive evaluations demonstrate that our method achieves high-quality reconstruction results, robust generalization, and reasonably good efficiency compared to prior works.
SparsePoser: Real-time Full-body Motion Reconstruction from Sparse Data
Nov 03, 2023
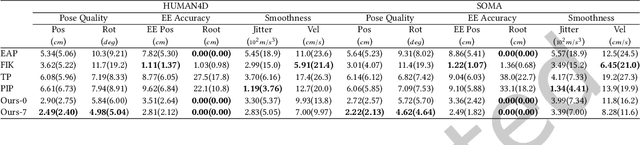
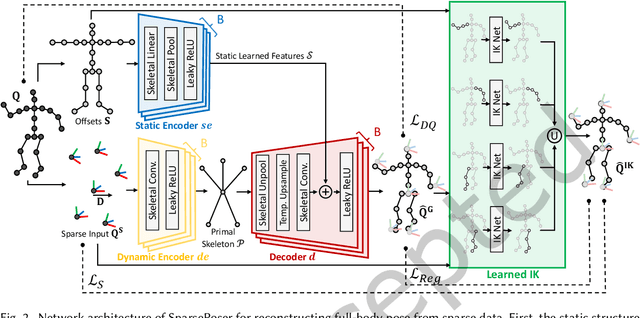
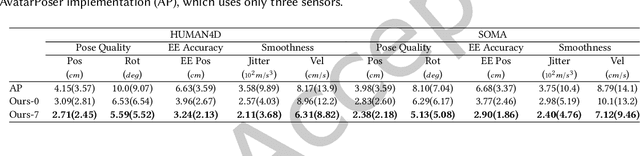
Accurate and reliable human motion reconstruction is crucial for creating natural interactions of full-body avatars in Virtual Reality (VR) and entertainment applications. As the Metaverse and social applications gain popularity, users are seeking cost-effective solutions to create full-body animations that are comparable in quality to those produced by commercial motion capture systems. In order to provide affordable solutions, though, it is important to minimize the number of sensors attached to the subject's body. Unfortunately, reconstructing the full-body pose from sparse data is a heavily under-determined problem. Some studies that use IMU sensors face challenges in reconstructing the pose due to positional drift and ambiguity of the poses. In recent years, some mainstream VR systems have released 6-degree-of-freedom (6-DoF) tracking devices providing positional and rotational information. Nevertheless, most solutions for reconstructing full-body poses rely on traditional inverse kinematics (IK) solutions, which often produce non-continuous and unnatural poses. In this article, we introduce SparsePoser, a novel deep learning-based solution for reconstructing a full-body pose from a reduced set of six tracking devices. Our system incorporates a convolutional-based autoencoder that synthesizes high-quality continuous human poses by learning the human motion manifold from motion capture data. Then, we employ a learned IK component, made of multiple lightweight feed-forward neural networks, to adjust the hands and feet toward the corresponding trackers. We extensively evaluate our method on publicly available motion capture datasets and with real-time live demos. We show that our method outperforms state-of-the-art techniques using IMU sensors or 6-DoF tracking devices, and can be used for users with different body dimensions and proportions.